






这里我们使用spark作为数据引擎,在此基础上实现我们的大数据应用。
一、spark的安装
首先需要安装的就是java环境,安装特定的spark版本需要特定的java版本,可从spark源码中的pom文件中查看java版本要求,安装好java环境之后进入spark官网(http://spark.apache.org/downloads.html),直接下载。spark不依赖hadoop,但是如果你已经安装了一个hadoop集群或者安装好的hdfs,那就下载对应的版本。
下载完成之后解压,tar -xf XXX (本文以linux环境演示) ,x是解压,f是指定要解压的文件的名字。
二、shell的使用
spark带有交互式的shell,可以作即时数据分析。执行./bin/spark-shell就可以打开,我在启动的时候遇到过Caused by: java.net.UnknownHostException错误,原因是linux的主机名没有在/etc/hosts中,hostname查看主机名,然后ping hostname看通不通,不通的话就会出现上述的错误,在/etc/hosts中假如主机名即可。修复错误之后正常启动。得到如下图。
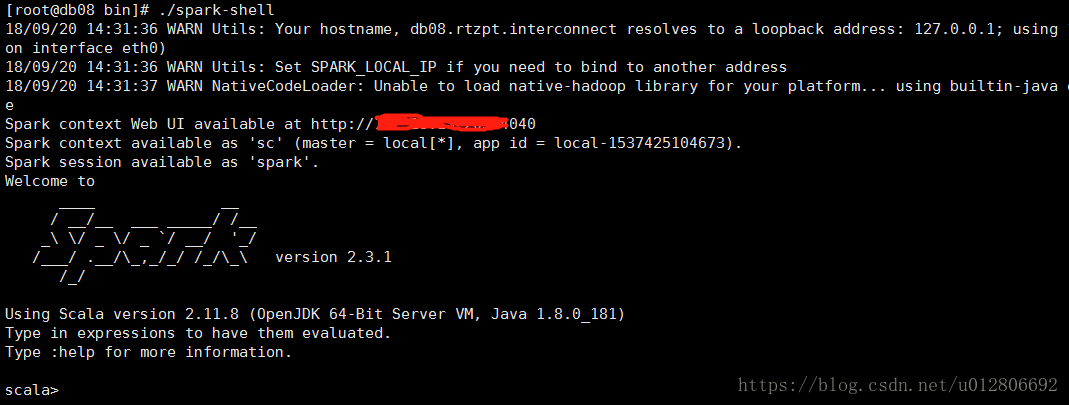
会发现信息还是挺多的,提示的内容中也说了可以调整日志级别为warn,到conf目录下,复制log4j.properties.template一份在conf下为log4j.properties,修改log4j.rootCategory=INFO, console为log4j.rootCategory=WARN, console
启动之后就可以开始做一些简单的计算任务了,

这里的sc不用声名,shell启动时就已经创建了这个SparkContext对象来用于访问spark。














 889
889











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









