







(一).只用2GB内存在20亿个整数中找到出现次数最多的数
【题目】有一个包含20亿个全是32位整数的大文件,在其中找到出现次数最多的数。
【分析】通过哈希表对20亿个整数进行词频统计。哈希表的key是32位的整数,value最坏打算是20亿个(4B)所以一条<k,v>记录是8B。
最多20亿条记录,需要的内存远超于2GB!一条记录需要8B存储,当哈希表的记录数为2亿个时,至少需要1.6GB的内存!
【解决方法】把包含20亿个整数的大文件通过哈希函数分流为16小文件,根据哈希函数的基本性质,相同的整数必将被分配到同一小文件中,并且只要哈希函数足够优秀,得到哈希值均匀,那么所有小文件最坏打算也不超过2亿个整数,这时候在符合内存要求的情况下通过哈希表进行词频统计,最终将每个小文件出现最多的词频进行比较,最终得出总的结论。


(三).40亿个非负数整数中找到没出现的数
【题目】32位无符号整数范围0~4294967295,现在有一个正好包含40亿个整数的文件,所以整个范围中必然有没有出现的数。可以使用最多1GB的内存,怎么找到所有没出想过的数。
【分析】如果用哈希表存储,40亿条记录,40亿*4B 约等于16GB!所以考虑用bitmap模型!2^32位 =512MB,符合内存要求!当出现7000时,在arr[7000]处赋值为1,以此类推,将40亿个整数遍历处理! 当处理完成之后,在遍历一次,arr[i]==0的下标即为没有出现过数的值!
【题目】内存限制为10MB,但是只用找到一个没有出现过的数即可。
【分析】考虑512/64 =8MB,8MB符合内存要求。所以将2^32个分为64个区间。由题目可知必然有区间计数不足2^32/64。
如何找出计数不足的区间呢? 通过取模方法,遍历40亿个整数,将整数落在某个区间上对计数变量加一,最终遍历完后随意取出一个区间进行关注。假设文件a中的数据个数不足2^32/64个,那么这里面必然有没出现的。
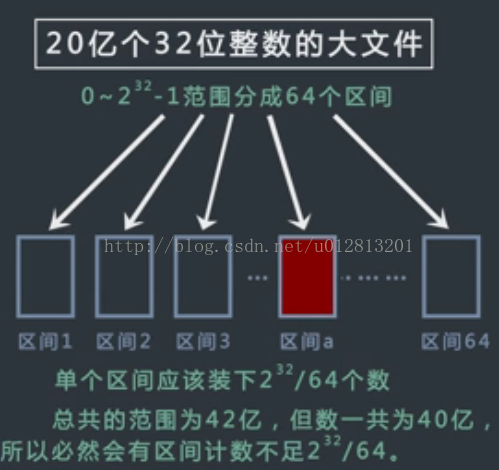
再遍历40亿个数,对这40亿个数只关注落在取出区间的整数。并且用bitmap统计出区间内的数出现的情况。
总结:
(1)根据内存限制决定区间大小,32位无符号整数2^32=42亿个,哈希表存储的话2^32位=512MB。
(2)而允许区间为10MB,所以要对数据hash分块,512/64=8<10,所以要分成64块。
(四).找到100亿个URL中重复的URL
【题目】有一个包含100亿个URL的大文件,假设每个URL占用64B,请找出其中所有重复的URL。
【分析】bitmap使用于给定范围,这样可以固定bit类型数组的大小!此题URL不能固定范围,所以使用哈希函数的分流功能。哈希函数有一个重要性质:同一个输入值将产生同一个哈希值,最终在哈希表中的分布地址也必然相同,利用该性质,我们常常在处理大数据问题时由于空间不够,把大文件通过哈希函数分配到机器,或者通过哈希函数把大文件划分成小文件,一直划分,直到划分的结果满足资源限制的要求。
(四).百亿词频统计
【补充题目】某搜索公司一天的搜索词汇是海量的(百亿级数据量),请设计出一种每天最热top100词汇的可行方法
【分析】先用哈希函数把百亿数据分流到不同服务器中,如果分流到的数据过大,继续把大文件通过哈希函数分流为子文件。在子文件中用哈希表统计每种词及其词频。遍历哈希表时使用大小为100的最小堆来选出每个小文件的Top100(整体未排序),再将每个小文件词频的最小堆排序,得到每台机器的Top100。再用每台机器的Top100进行外排序,最终求得整个百亿数据量的top100。
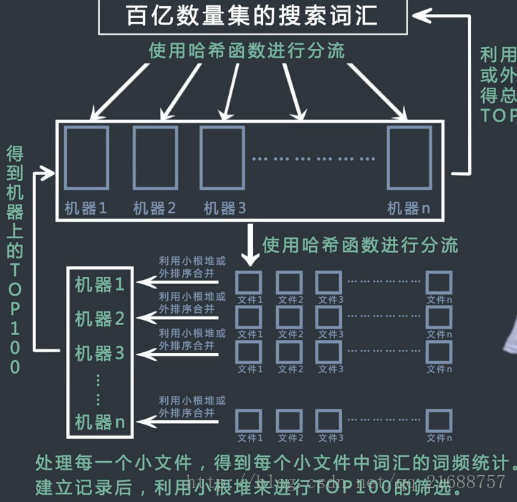
【注意】对于Top100来说,除了哈希函数和哈希表做词频统计外,还常用堆结构和外排序的手段进行处理。
用最小堆:起初前100个条数据建立最小堆,堆顶肯定是词频最低的那条,第101条记录过来时和堆顶比较,如果比堆顶小直接pass,反之替换堆顶,重新维持最小堆性质。也就是说堆顶为截止当前位置,词频第100位的那条记录,新记录只要和堆顶比较即可。
(五).40亿个非负整数中找到出现俩次的数
【分析】bitmap模型变形,申请一个2^32 *2长度的bit数组进行操作。
【补充题目】可以使用最多10MB的内存,怎么找到这40亿个整数的中位数!
【分析】用分区间的方式进行处理,长度为2MB的无符号整数数组占用内存空间为8MB。所以将区间数量定义为2^32/2M ,向上取整为2148个区间。
遍历40亿个整数,对每个整数进行遍历,得到每个区间的整数个数(不需要进行词频统计)!假设0~k-1的区间为19.998亿,加上k区间的话肯定就超过20亿,所以中位数在k区间上!
申请2MB长度的数组(占用内存为8MB),遍历40亿整数对K区间的数进行词频统计,最后在区间k上找到第0.002亿个数即可。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









