







 本文详细介绍了Java HashMap的数据结构、构造方法、哈希计算、put和get操作,以及扩容和解决冲突的策略。HashMap基于数组+链表+红黑树实现,其容量必须为2的幂,通过哈希值的位运算快速定位元素位置,减少冲突。在put时,若键值对已存在,将更新值;当节点数达到树化阈值时,链表会转换为红黑树。通过对源码的分析,揭示了HashMap高效运作的秘密。
本文详细介绍了Java HashMap的数据结构、构造方法、哈希计算、put和get操作,以及扩容和解决冲突的策略。HashMap基于数组+链表+红黑树实现,其容量必须为2的幂,通过哈希值的位运算快速定位元素位置,减少冲突。在put时,若键值对已存在,将更新值;当节点数达到树化阈值时,链表会转换为红黑树。通过对源码的分析,揭示了HashMap高效运作的秘密。
让我们在IDEA中打开HashMap源码,开始往下看。
HashMap 继承自AbstractMap,实现了Map接口。


HashMap类中定义了很多的默认值,比如默认初始容量,最大容量,加载因子等。

HashMap底层基于数组+链表+红黑树。HashMap存储的是键值对,将每个键值对保存到Node对象中,然后再把Node对象存到Node数组中。
我们先看HashMap的构造方法。
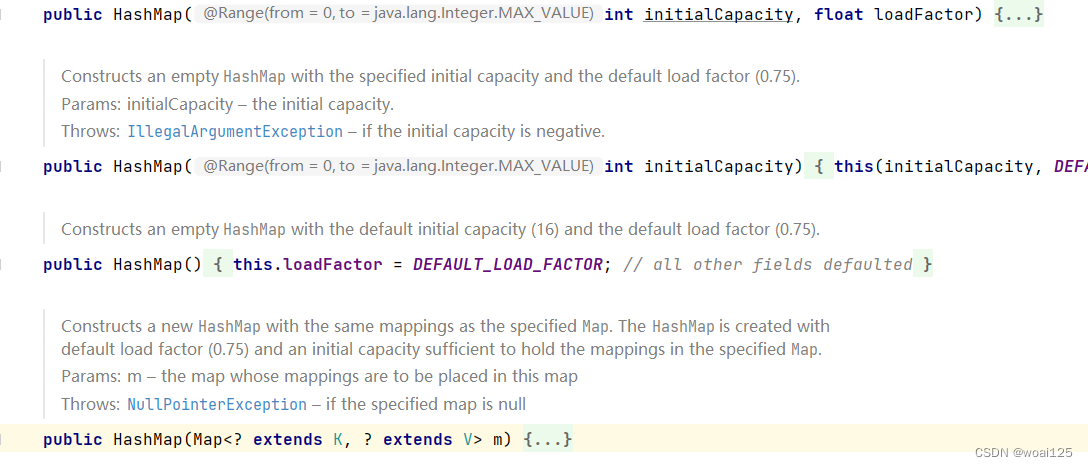
HashMap有多个重载的构造方法,从这些方法我们可以看到,HashMap允许我们自定义初始容量和加载因子。但是这两者都不是任意定义的,我们看一下方法中的判断逻辑。

初始容量在(0,MAXIMUM_CAPACITY]之间,加载因子需要大于0。然后,就会做一个简单的赋值操作,但是并不会初始化table数组,table数组上面的注释也说得很清楚,在第一次使用时初始化,所以HashMap是懒加载的。这里有一个threshold,指的是下一次扩容的阈值,也就是当存入节点==threshold时,要执行扩容操作。但是这个值又是我们的第一次初始化数组的大小。
tableSizeFor
threshold并不是直接赋值为我们定义的容量值,而是又调用了tableSizeFor方法。 这个方法会返回一个大于等于你指定的容量的最小的2的幂。也就是说HashMap的数组容量,总是2的N次方。
这个方法会返回一个大于等于你指定的容量的最小的2的幂。也就是说HashMap的数组容量,总是2的N次方。
-1 的二进制是11111111 11111111 11111111 11111111
cap-1是为了处理cap恰好为2的幂的情况。Integer.numberOfLeadingZeros会返回数字转为2进制数以后,为1的最高位前面0的位数。举个例子,如果我们传入的cap是16,那么16-1为15,15的二进制数是1111,那么前面的0一共有28位,将-1右移28位,得到00000000 00000000 00000000 00001111。在加1,得到10000,也就是16。
为什么容量总得是2的幂呢?是为了能够和key的Hash值做&运算,从而快速得出node在table数组中的index。知道了数组的长度,想要知道对象存在哪个位置,很容易想到用hashcode % 数组长度。但是在计算机中,位运算比乘除效率更高。长度为2的n次方的数转换为2进制后,为...0...1...0...。只有一位是1,其它都是0。那么减一以后呢,...0...111...第一个1之前的高位都为0,之后的低位都为1,在和hash值做&操作就能够得到[0,n-1]之间的数值了。比如n为16,那么15 & hash为:
00000000 00000000 00000000 00001111
& 01010101 01010101 00101010 10111110(任意hash值)
最终的结果只跟低四位有关,范围为[0,15]。
现在我们来看HashMap的put方法。
put

这里计算了key的hash值。
hash
看下hash方法

key为null,返回0。所以hashmap允许null key。不为null,调用Object.hashCode方法得到hash值,然后将hash值右移16位和原来的hash值做异或操作,得到最终的ha
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









