








1.给你一个1G的数据文件。分别有id,name,mark,source四个字段,按照mark分组,id排序,手写一个MapReduce?其中有几个Mapper?
在map端对mark排序,在reduce端对id分组。
@Override
public int compareTo(GroupBean o) {
int result = this.mark.compareTo(o.mark);
if (result == 0) return Integer.compare(this.id,o.id);
else
return result;
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
GroupBean aBean = (GroupBean) a;
GroupBean bBean = (GroupBean) b;
int result;
if (aBean.getMark() > bBean. getMark()) { result = 1;
} else if (aBean. getMark() < bBean. getMark()) { result = -1;
} else {result = 0;
}
return result;
}
2)几个mapper
(1)1024m/128m=8块
2.你是如何解决Hadoop数据倾斜的问题的,能举个例子吗?
「性能优化」和「数据倾斜」,如果在面试前不好好准备,那就准备在面试时吃亏吧~其实掌握的多了,很多方法都有相通的地方。
1)提前在map进行combine,减少传输的数据量
在Mapper加上combiner相当于提前进行reduce,即把一个Mapper中的相同key进行了聚合,减少shuffle过程中传输的数据量,以及Reducer端的计算量。
如果导致数据倾斜的key 大量分布在不同的mapper的时候,这种方法就不是很有效了
2)数据倾斜的key 大量分布在不同的mapper
在这种情况,大致有如下几种方法:
「局部聚合加全局聚合」
第一次在map阶段对那些导致了数据倾斜的key 加上1到n的随机前缀,这样本来相同的key 也会被分到多个Reducer 中进行局部聚合,数量就会大大降低。
第二次mapreduce,去掉key的随机前缀,进行全局聚合。
「思想」:二次mr,第一次将key随机散列到不同 reducer 进行处理达到负载均衡目的。第二次再根据去掉key的随机前缀,按原key进行reduce处理。
这个方法进行两次mapreduce,性能稍差
「增加Reducer,提升并行度」
JobConf.setNumReduceTasks(int)
「实现自定义分区」
根据数据分布情况,自定义散列函数,将key均匀分配到不同Reducer
3.讲一讲Yarn 调度流程
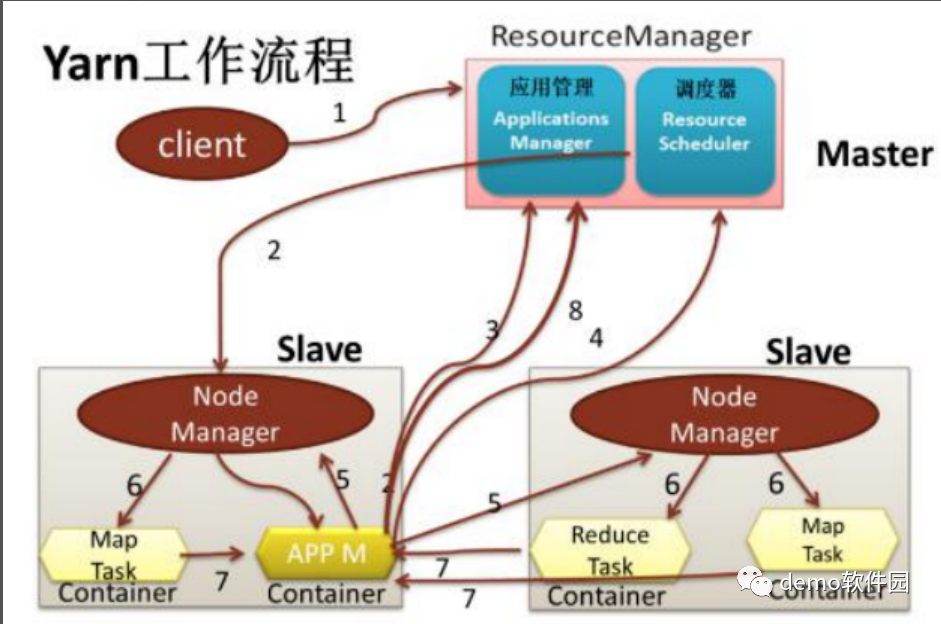
1)client向RM提交应用程序,其中包括启动该应用的ApplicationMaster的必须信息,例如ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等
2)ResourceManager启动一个container用于运行ApplicationMaster
3)启动中的ApplicationMaster向ResourceManager注册自己,启动成功后与RM保持心跳
4)ApplicationMaster向ResourceManager发送请求,申请相应数目的container
5)申请成功的container,由ApplicationMaster进行初始化。container的启动信息初始化后,AM与对应的NodeManager通信,要求NM启动container
6)NM启动container
7)container运行期间,ApplicationMaster对container进行监控。container通过RPC协议向对应的AM汇报自己的进度和状态等信息
8)应用运行结束后,ApplicationMaster向ResourceManager注销自己,并允许属于它的container被收回















 514
514











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









