








1.怎么处理Hadoop宕机的问题的?
如果MR造成系统宕机。此时要控制Yarn同时运行的任务数,和每个任务申请的最大内存。调整参数:yarn.scheduler.maximum-allocation-mb(单个任务可申请的最多物理内存量,默认是8192MB)。
如果写入文件过量造成NameNode宕机。那么调高Kafka的存储大小,控制从Kafka到HDFS的写入速度。高峰期的时候用Kafka进行缓存,高峰期过去数据同步会自动跟上。
2.你了解过哪些Hadoop的参数优化?
「Hadoop参数调优」有以下几种:
在hdfs-site.xml文件中配置多目录,最好提前配置好,否则更改目录需要重新启动集群
NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作dfs.namenode.handler.count=20 * log2(Cluster Size)
比如集群规模为10台时,此参数设置为60
l 1)编辑日志存储路径dfs.namenode.edits.dir设置与镜像文件存储路径dfs.namenode.name.dir尽量分开,达到最低写入延迟
l 2)服务器节点上YARN可使用的物理内存总量,默认是8192(MB),注意,如果你的节点内存资源不够8GB,则需要调减小这个值,而YARN不会智能的探测节点的物理内存总量
l 3)单个任务可申请的最多物理内存量,默认是8192(MB)
3.什么是Yarn HA?
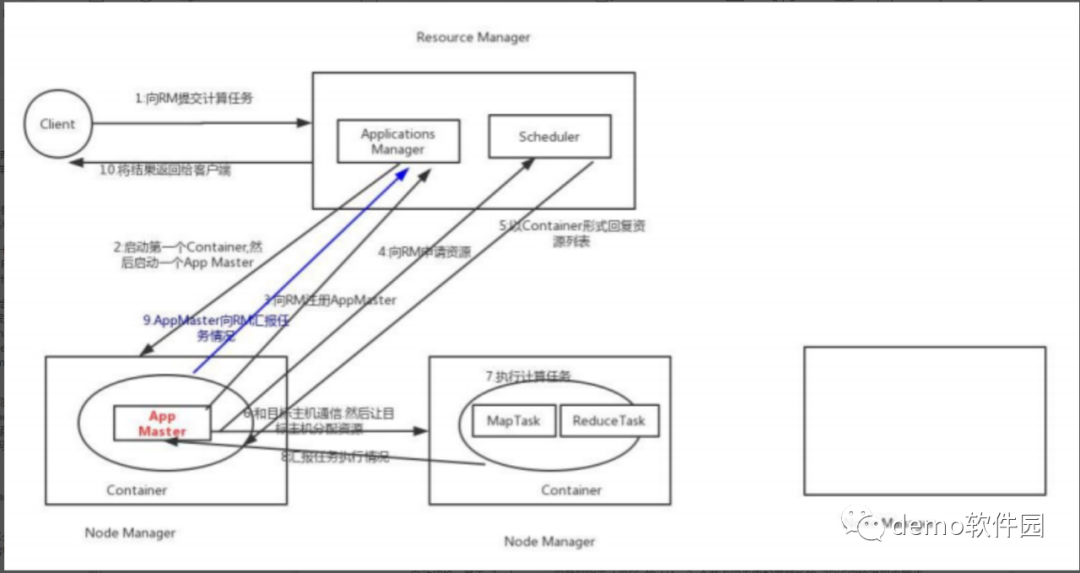
Hadoop 2.4.0版本开始,Yarn 实现了 ResourceManager HA
由于资源使用情况和 NodeManager 信息都可以通过 NodeManager 的心跳机制重新构建出来,因此只需要对 ApplicationMaster 相关的信息进行持久化存储即可。
在一个典型的 HA 集群中,两台独立的机器被配置成 ResourceManger。在任意时间,有且只允许一个活动的 ResourceManger,另外一个备用。切换分为两种方式:
手动切换:在自动恢复不可用时,管理员可用手动切换状态,或是从 Active 到 Standby,或是从 Standby 到Active。
自动切换:基于 Zookeeper,但是区别于 HDFS 的 HA,2 个节点间无需配置额外的 ZFKC守护进程来同步数据。
4.简述Hadoop1与Hadoop2 的架构异同。
加入了yarn解决了资源调度的问题。
加入了对zookeeper的支持实现比较可靠的高可用。
5.为什么会产生yarn,它解决了什么问题,有什么优势?
Yarn最主要的功能就是解决运行的用户程序与yarn框架完全解耦。
Yarn上可以运行各种类型的分布式运算程序(mapreduce只是其中的一种),比如mapreduce、storm程序,spark程序……















 1709
1709











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









