






1、Complex Video Reasoning and Robustness Evaluation Suite for Video-LMMs
中文标题:视频 LMM 的复杂视频推理和鲁棒性评估套件


简介:最近,大型语言模型(LLMs)的进展已经推动了视频大型多模型(Video-LMMs)的发展,这些模型可以处理各种视频理解任务。这些模型在机器人、AI助手、医学成像和自动驾驶等实际应用中具有潜力。视频-LMMs在我们日常生活中的广泛应用凸显了确保和评估它们在复杂的实际环境中能够类推和交互,具有稳健表现的重要性。然而,现有的视频-LMMs基准主要关注一般视频理解能力,忽略了对它们在复杂视频中推理能力和在用户提示作为文本查询的情况下模型的鲁棒性进行评估。本文介绍了复杂视频推理和鲁棒性评估套件(CVRR-ES),这是一个全面评估Video-LMMs在11个不同的真实世界视频维度上表现的新基准。我们评估了9个最近的模型,包括开源和闭源变体,并发现大多数Video-LMMs,特别是开源模型,在处理复杂视频时都存在鲁棒性和推理方面的困难。基于我们的分析,我们开发了一种无需训练的双步上下文提示(DSCP)技术,以提高现有Video-LMMs的性能。我们的研究结果为构建具有先进的稳健性和推理能力的下一代以人为中心的AI系统提供了有价值的见解。我们的数据集和代码可在https://mbzuai-oryx.github.io/CVRR-Evaluation-Suite/上公开获取。
2、Language-Image Models with 3D Understanding
中文标题:具有 3D 理解能力的语言图像模型


简介:多模态大语言模型(MLLM)展示了在各种二维视觉和语言任务中令人惊叹的能力。我们将MLLM的感知能力扩展到了三维空间中的图像理解和推理。为此,我们首先创建了一个名为LV3D的大规模预训练数据集,将多个现有的二维和三维识别数据集结合起来,并采用了一种常见的任务形式:多轮问答。接下来,我们引入了一种名为Cube-LLM的全新MLLM模型,并在LV3D上进行了预训练。我们的研究结果表明,纯数据扩展可以在没有针对三维特定架构设计或训练目标的情况下产生强大的三维感知能力。Cube-LLM表现出类似LLM的一些有趣特性:(1)Cube-LLM可以应用链式思维提示,从二维上下文信息中提升对三维的理解能力;(2)Cube-LLM可以遵循复杂和多样化的指令,并适应多样化的输入和输出格式;(3)Cube-LLM可以通过视觉提示,例如2D框或一组专家提供的候选3D框进行操作。我们在室外基准测试中的实验结果显示,Cube-LLM在Talk2Car数据集的3D基础推理方面相较于现有基线提高了21.3个AP-BEV点,在DriveLM数据集的复杂推理方面提高了17.7个点。Cube-LLM在一般的MLLM基准测试中也展现出竞争力,例如在refCOCO的2D基础推理平均得分为87.0,在VQAv2、GQA、SQA、POPE等视觉问答基准测试中用于复杂推理。我们的项目可在https://janghyuncho.github.io/Cube-LLM获取。
3、An Empty Room is All We Want: Automatic Defurnishing of Indoor Panoramas
中文标题:我们想要的就是一个空房间:室内全景图的自动整理

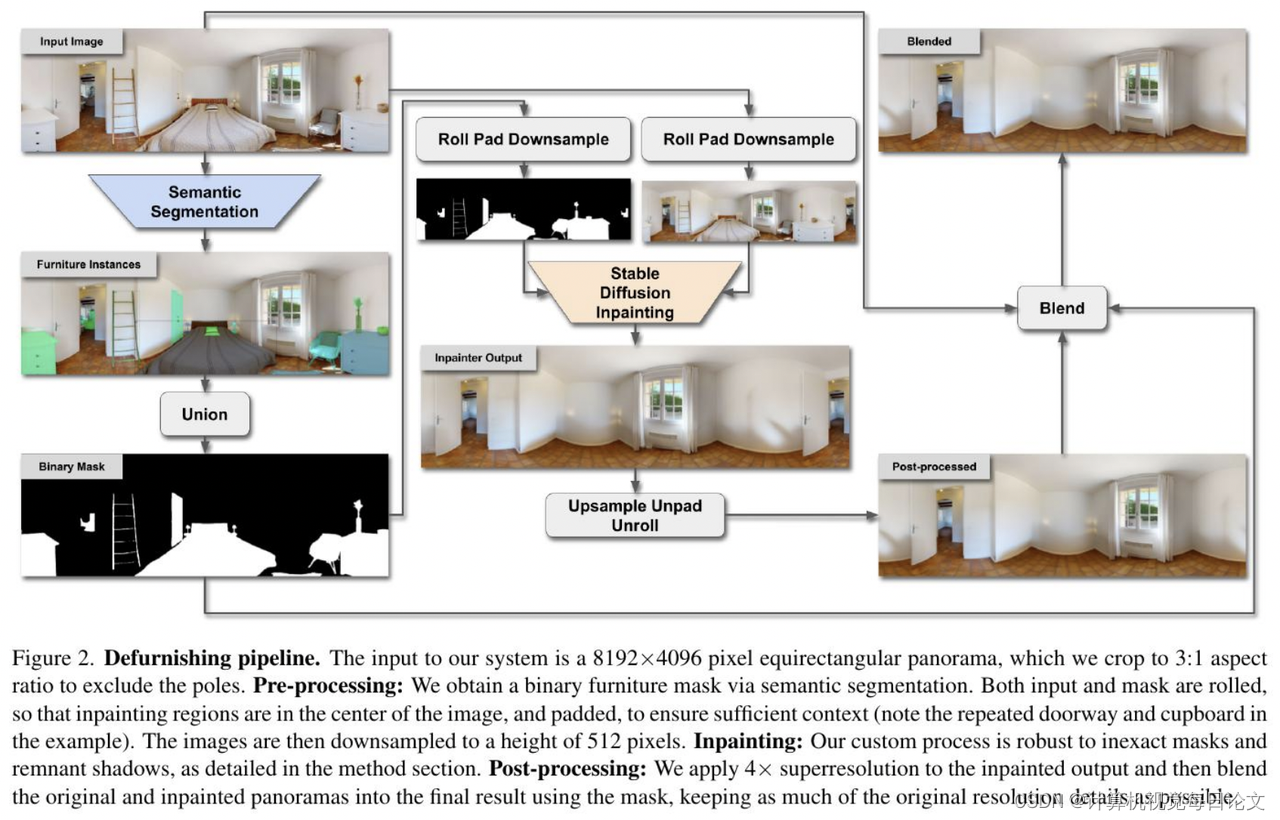
简介:我们提出了一种流程,利用稳定扩散方法来改善填补细节的结果,尤其在去除室内全景图像中的家具项目方面表现出了显著的效果。具体而言,我们详细阐述了如何通过增加上下文信息、对特定领域的模型进行微调以及改进图像混合技术来生成高保真度的填补结果,而无需依赖于房间布局估计。我们展示了相对于其他家具去除技术的定性和定量改进效果。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









