







1. LoRA原理
LoRA(Low-Rank Adaptation)是一种针对大型语言模型的微调技术,旨在降低微调过程中的计算和内存需求。其核心思想是通过引入低秩矩阵来近似原始模型的全秩矩阵,从而减少参数数量和计算复杂度。
在LoRA中,原始模型的全秩矩阵被分解为低秩矩阵的乘积。具体来说,对于一个全秩矩阵W,LoRA将其分解为两个低秩矩阵A和B的乘积,即W ≈ A * B。其中,A和B的秩远小于W的秩,从而显著减少了参数数量。

上图为 LoRA 的实现原理,其实现流程为:
- 在原始预训练语言模型旁边增加一个旁路,做降维再升维的操作来模拟内在秩;
- 用随机高斯分布初始化 A,用零矩阵初始化B,训练时固定预训练模型的参数,只训练矩阵 A 与矩阵 B ;
- 训练完成后,将 B 矩阵与 A 矩阵相乘后合并预训练模型参数作为微调后的模型参数。
公式表示为:

其中,W是原始的权重矩阵,A是一个尺寸为dr的矩阵,B是一个尺寸为rd’的矩阵,r是低秩矩阵的秩。通过这种分解,原始矩阵W的更新仅由A和B的乘积决定。进一步地,LoRA引入了一个缩放因子α,使得更新公式为:

代码表示如下:
scaling = alpha / r
weight = weight + scaling * (lora_B @ lora_A)
2. 参数设置
那么在实际使用的时候,我们如何确定lora参数?这些参数的变化对实验结果产生什么影响?模型具体哪些部分参数需要使用lora?等等这些问题,我们应该如何应对?
下面我们先以 基于 PEFT 的 LORA 微调为例,介绍下 LORA 究竟包含哪些主要的参数:
PEFT(Parameter-Efficient Fine-Tuning) 库是一个用于高效微调大规模预训练模型的工具,旨在减少训练时的计算和存储成本,同时保持模型性能。它通过引入LoRA、Adapter等技术,使得只需调整部分参数即可实现有效的微调。
LoraConfig 是peft库中的一个配置类,用于设置LoRA相关的超参数,如低秩矩阵的秩、缩放因子等,它帮助用户定制LoRA微调的细节,优化训练过程的效率和效果。
基于 LoraConfig 类设置 lora 微调参数的示例代码如下:
from peft import LoraConfig, TaskType
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
target_modules=['up_proj', 'gate_proj', 'q_proj', 'o_proj', 'down_proj', 'v_proj', 'k_proj'],
task_type=TaskType.CAUSAL_LM,
inference_mode=False # 训练模式
)
从上面的代码可以看出,LORA微调的核心参数包括:
target_modulesrlora_alphalora_dropout
下面我们来一一进行讲解。
2.1 target_modules
target_modules 是 LoRA(Low-Rank Adaptation)中的关键参数,用于指定模型中需要插入低秩矩阵调整的模块。 LoRA 的核心思想是通过对预训练模型中的特定层进行低秩矩阵插入,实现参数高效微调而无需修改原始权重。
对于语言模型,通常选择影响权重更新较大的模块,例如q_proj和k_proj(负责查询和键的变换),v_proj(值的变换),以及o_proj(输出投影)等。这些模块主要集中在自注意力和前馈网络中,通过插入的低秩矩阵调整这些模块的权重,使模型在保持原始能力的同时适应新任务,极大减少微调的计算和存储开销。
比如,LLaMa的默认模块名为[q_proj, v_proj],我们也可以自行指定为:[q_proj,k_proj,v_proj,o_proj]。
这里,为了搞清楚具体哪些层会参与lora微调,我们使用 deepseek 观察模型每一层具体都是什么:
# 查看模型层的代码如下
# 本文使用的是大模型的通用对话功能,因此导入AutoModelForCausalLM查看
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(model_name)
print(model)
具体模型结构如下:
LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(102400, 4096)
(layers): ModuleList(
(0-29): 30 x LlamaDecoderLayer(
(self_attn): LlamaSdpaAttention(
(q_proj): Linear(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear(in_features=4096, out_features=4096, bias=False)
(v_proj): Linear(in_features=4096, out_features=4096, bias=False)
(o_proj): Linear(in_features=4096, out_features=4096, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP(
(gate_proj): Linear(in_features=4096, out_features=11008, bias=False)
(up_proj): Linear(in_features=4096, out_features=11008, bias=False)
(down_proj): Linear(in_features=11008, out_features=4096, bias=False)
(act_fn): SiLU()
)
(input_layernorm): LlamaRMSNorm((4096,), eps=1e-06)
(post_attention_layernorm): LlamaRMSNorm((4096,), eps=1e-06)
)
)
(norm): LlamaRMSNorm((4096,), eps=1e-06)
(rotary_emb): LlamaRotaryEmbedding()
)
(lm_head): Linear(in_features=4096, out_features=102400, bias=False)
)
可以看到deepseek模型也是采取的Llama模型结构,那么具体哪些层会参与lora微调呢?下面将详细介绍:
(1)Attention层
- Self-attention层: 这些层通常对模型性能影响较大。LoRA会被应用于自注意力的查询(q_proj)、键(k_proj)、值(v_proj)和输出(o_proj)投影矩阵。这些矩阵包含了大量的可训练参数,因此是LoRA微调的理想目标。
- LlamaSdpaAttention中的矩阵:
q_proj: 查询投影k_proj: 键投影v_proj: 值投影o_proj: 输出投影
- Rotary Embedding:虽然在一些实现中会对嵌入进行微调,但通常LoRA不会直接用于rotary_emb,因为它通常是固定的。
(2)MLP层 - MLP层中的Gate、Up和Down投影
gate_proj:控制门投影up_proj:上升投影down_proj:下降投影- MLP层的Gate、Up和Down投影通常涉及大量的可训练参数,因此对这些投影进行LoRA微调,可以在不显著增加计算负担的情况下优化模型表现。通过低秩适应,LoRA能够在减少参数量的同时,增强模型对复杂模式的适应能力。这些曾在处理非线性变换时起到重要作用,通常也是LoRA微调的目标。
(3)LayerNorm层
RMSNorm: 在Llama中使用的是LlamaRMSNorm(Root Mean Square Layer Normalization),它与标准的LayerNorm不同,但也可以通过LoRA微调。虽然这部分常常不会进行微调,但如果需要微调,通常会集中在注意力层和MLP层上。
(4)Embedding层
embed_tokens:如果对词嵌入有需要进行微调,LoRA也可以应用于嵌入矩阵。尤其在词汇量较大的情况下,嵌入矩阵的参数量非常庞大,这样进行LoRA微调也可以获得一定的性能提升。
(5)线性层(lm_head)
lm_head:在模型输出时,lm_head是从隐藏层到词汇表的最后一层线性转换。通常,LoRA不会直接应用于输出层,但在某些微调场景下,可以将LoRA应用于该层以调整模型输出。
【总结】: 一般来说,LoRA微调会集中在以下层:
- Attention层的查询、键、值和输出投影(q_proj, k_proj, v_proj, o_proj)
- MLP层的gate_proj、up_proj 和 down_proj
- 可能在某些场景下微调embed_tokens和lm_head 通过这种方式,LoRA能够有效减少参数量和计算成本,同时保持微调的效果。
2.2 r、alpha、dropout
在模型微调的过程中,r、alpha和dropout是常见的超参数,用于优化模型训练和提升其泛化能力。
r:通常用于LoRA(Low-Rank Adaptation)方法中,表示 低秩矩阵的秩值 。r决定了微调时使用的低秩矩阵的维度,较小的r可以减少参数数量,从而提高训练效率,但可能牺牲一定的模型表现。较小的r(例如 8-32)适用于较小模型或需要较低资源的情况,而较大的r(例如 64-128)适用于更大规模的模型。alpha:是LoRA中的一个超参数,用来 控制低秩矩阵的 缩放因子 。通过调整alpha,可以平衡低秩矩阵的影响,使模型能够在微调过程中保持足够的表达能力。16-32 是比较常见的选择,较大的alpha值通常会增加模型的表达能力,但也可能增加训练难度。Dropout:是一种正则化技术,通过 在训练过程中随机丢弃神经网络中的部分神经元来防止过拟合。dropout率控制丢弃的概率,较高的dropout率有助于减少模型的复杂度,从而提升其在新数据上的泛化能力。对于大多数任务,0.2-0.3 是比较常见的取值,较低的dropout值(如 0.1)适合于较小的模型,而较高的dropout值(如 0.4-0.5)适合于较大的网络,尤其是在防止过拟合时。
【总结】:
- r:通常选择 8-128,根据任务和模型规模调整。
- alpha:常见值在 16-64,推荐 16-32。
- Dropout:常见值在 0.1-0.5,推荐 0.2-0.3。
2.3 Lora参数的设置经验
Lora参数的设置经验参考博客:
(1)如何选择合适的 rank 值?
没有任何好的启发式方法来选择一个好的r,这是一个需要为每个LLM和每个数据集探索的超参数。
- 太大的r可能会导致更多的过拟合
- 小的r可能无法在数据集中捕获各种任务
总体来说,数据集中的任务越多样化,r 就应该越大。例如,如果我只想要一个执行基本2位算术的模型,那么一个很小的r可能已经足够了。
(2)rank 和 alpha 的设置经验
Choosing
alphaas two timesris a common rule of thumb when using LoRA for LLMs, but I was curious if this still holds for larger r values.
将alpha设置为r的两倍是一种常见的经验法则,即 alpha = 2*rank。
然而,这条规则对于较大的r值也不一定适用。在模型和数据集的这种特定组合中,其中 r=256 且 alpha=128(0.5 倍缩放)性能甚至更好。如下图所示:
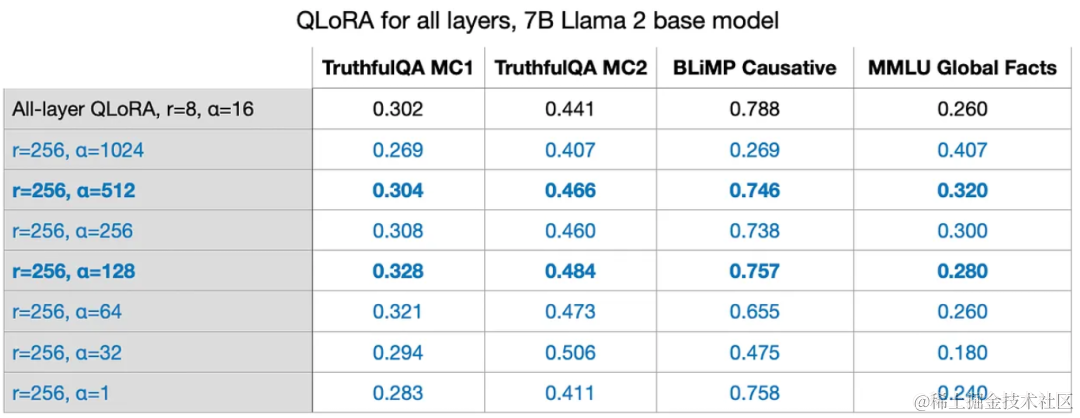
(3)dropout 的设置经验
一般设置为 0.05 或者 0.1 都可以。
(4)如何避免过拟合?
通常,较大的 rank 会导致更多的过拟合,因为它决定了可训练参数的数量。我们如果使用小模型微调时,使用的 rank 值可以选择 {8,16,32}之类的。
如果一个模型存在过拟合问题,可以减小 r 或增加数据集大小来避免过拟合。此外,也可以尝试在AdamW或SGD优化器中增加权重衰减率,也可以考虑增加LoRA层的dropout值。

















 1633
1633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









