









一、预备知识
1.序列化例子
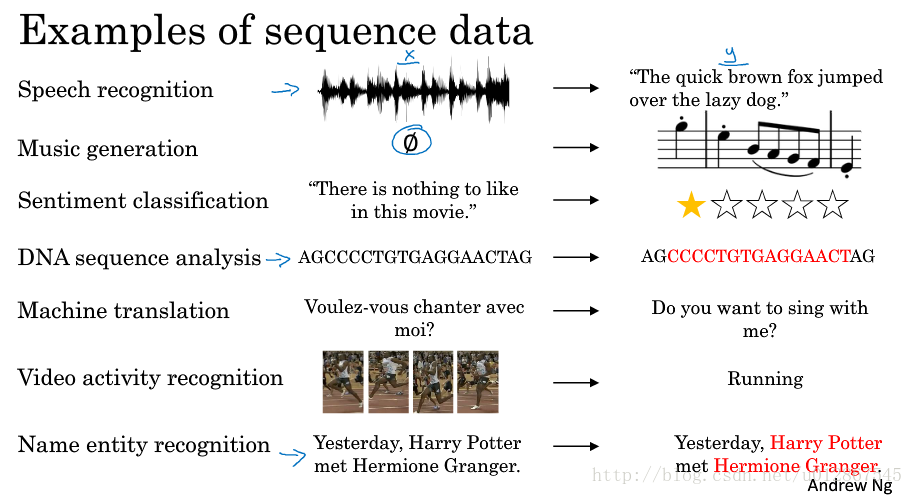
序列模型可以应用的例子有:语音识别、音乐生成、情感分类、DNA序列分析、机器翻译、视频行为识别、命名实体识别。
2.数学符号

如上图所示:x是一行句子。
- x<t> x < t > 表示第t个输入数据,索引不同的位置,如 x<1> x < 1 > 表示Harry, y<t> y < t > 同理
- Tx T x 表示输入序列的长度,这里 Tx=9 T x = 9 , Ty T y 同理
- x(i)<t> x ( i ) < t > 表示第i个训练样本的第t个元素
- Tix T x i 表示第i个训练样本的输入序列长度, Tiy T y i 同理
3.词汇表示

有一种表示法叫one-hot法,可以用来表示词汇。
one-hot法:
1. 我们需要对常用的词汇建立一个vocabulary表,30000~50000大小的词典比较常见,当然在一些大公司还会更大,本例中的大小为10000。
2. 假如Harry在词汇表中的位置为4075,那么我们就用一个维度为(n,1)的向量来表示
x<1>
x
<
1
>
,其中在索引为4075的位置上值为1,其余为0。因为只有一个地方为1,所以叫one-hot。
3. 因为词汇表的组成是常用词汇,我们经常在词汇表中用< unk >来表示不认识的词汇。
二、循环神经网络
1.为什么不用标准的网络
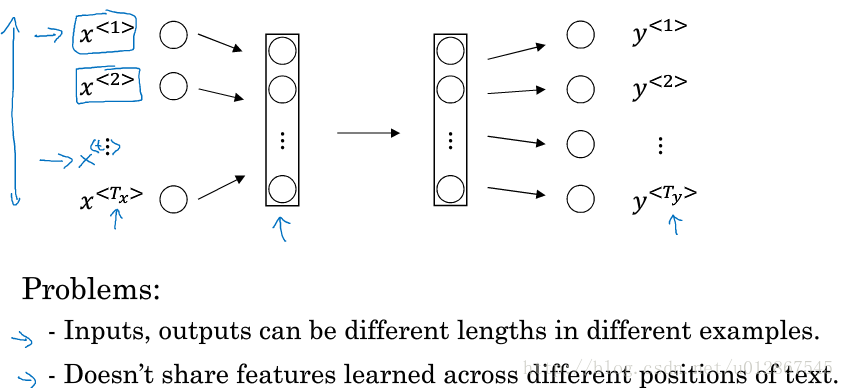
因为使用如上图所示的标准网络会存在2个问题:
- 在不同的例子中,输入、输出有可能不同。
- 不能够共享从文本不同位置学到的特征参数。(如 x<1> x < 1 > 表示Harry,我们判断出它是主语,这时我们希望能通过共享特征,从而让后面出现Harry的时候能很快就判断出也是主语)
2.RNN的模型
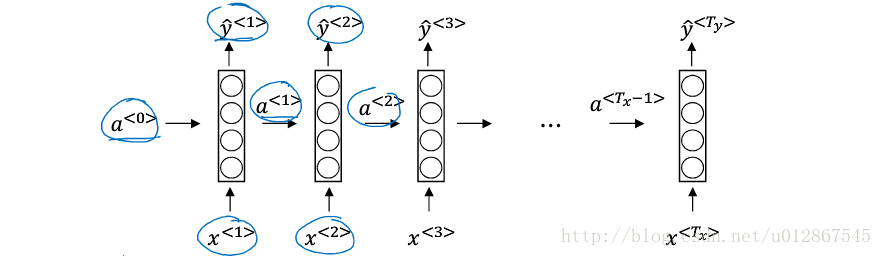
上图所示即为RNN基础模型。
3.前向传播
- 这里的 Wax W a x 中的a表示计算某个a类型的量,x表示要乘以某个x类型的量。 Waa,Wya W a a , W y a 同理。
- 其中计算 a<t> a < t > 的激活函数常用tanh,有时也会用ReLU;计算 y^<t> y ^ < t > 的激活函数常用为sigmoid,softmax,这取决于你需要怎样的输出。
公式简写
- 其中 Wa=[Waa⋮Wax] W a = [ W a a ⋮ W a x ] , [a<t−1>,x<t>]=[a<t−1>x<t>] [ a < t − 1 > , x < t > ] = [ a < t − 1 > x < t > ] ,2者相乘刚好就是 a<t> a < t > 。
- 这样的做法可以减少下标,可以给更负责的情况腾出更多的下标表示。
4.反向传播
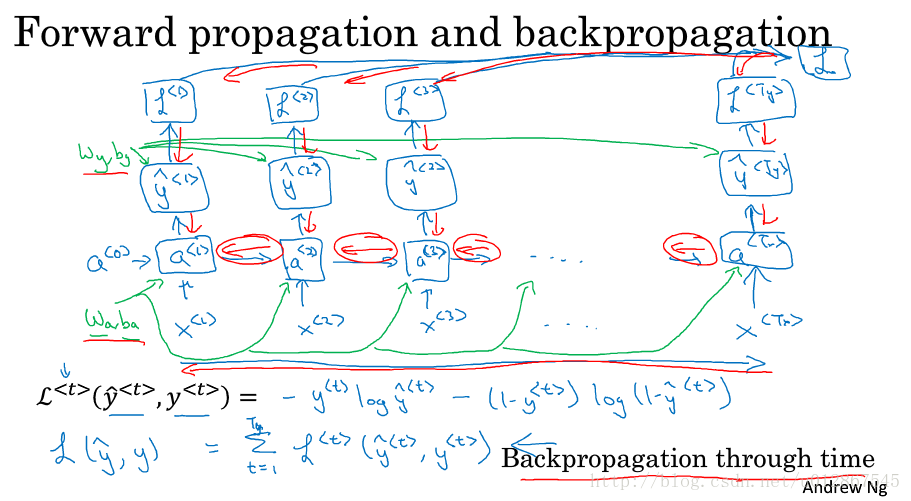
如上图所示:前向传播是通过
x<1>,a<0>
x
<
1
>
,
a
<
0
>
计算出
a<1>,y^<1>
a
<
1
>
,
y
^
<
1
>
,再由
x<2>,a<1>
x
<
2
>
,
a
<
1
>
计算出
a<2>,y^<2>
a
<
2
>
,
y
^
<
2
>
,以此类推到
a<Tx>,y^<Ty>
a
<
T
x
>
,
y
^
<
T
y
>
。同时,还可以计算出t时刻的损失函数
L<t>(y^<t>,y<t>)
L
<
t
>
(
y
^
<
t
>
,
y
<
t
>
)
,累计求和就可以得到总的损失函数
L(y^,y)
L
(
y
^
,
y
)
,再逆向就可以推导出
Wy,by,Wa,ba
W
y
,
b
y
,
W
a
,
b
a
,从而更新参数。
5.不同类型的RNN
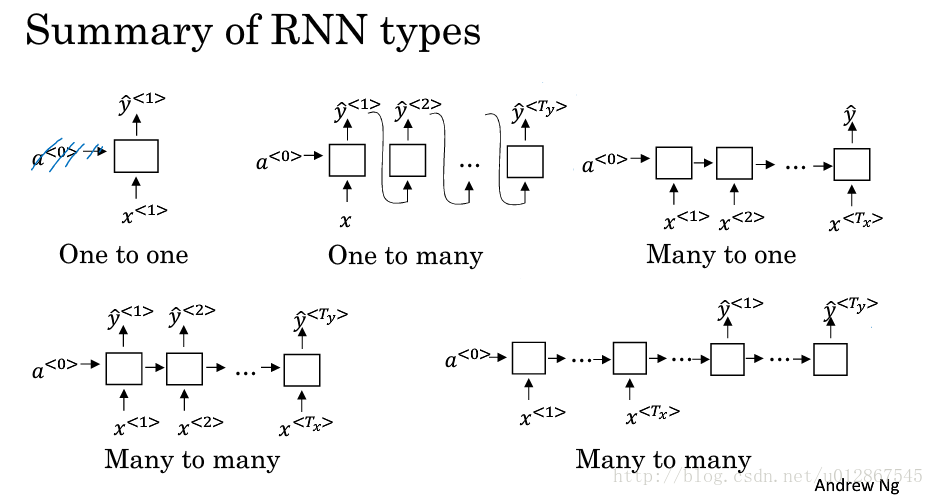
- 一对一
- 一对多(生成音乐,会将 y^<t> y ^ < t > 喂给下一个时间步)
- 多对一(情感分析等等)
- 多对多( Tx=Ty T x = T y )
- 多对多( Tx≠Ty T x ≠ T y )
三、语言模型和采样
1.语言模型

语言模型就是当你说了2句听起来很相似的话的时候,如上图所示语句中的pair和pear。你需要判断哪句话的概率更高一些。
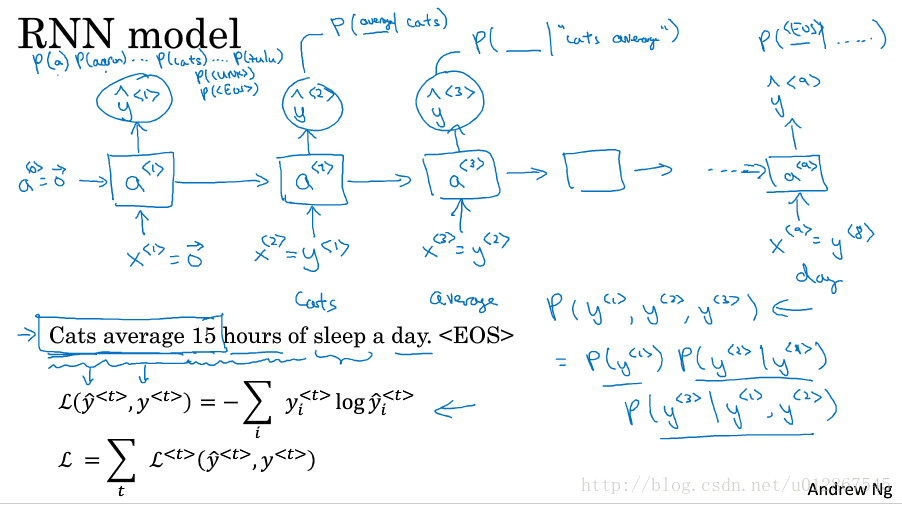
如上图所示,
y^<1>
y
^
<
1
>
即为我们语料库中各个单词作为第一个词的概率,比如说我们得到了Cats的概率最高,这时我们就把Cats也就是
y<1>
y
<
1
>
作为第二个的输入,也就是
x<2>
x
<
2
>
,然后去计算
y^<2>
y
^
<
2
>
的最大概率是哪个(在选定Cats作为第一词的条件下),即P(average|cats),以此类推。
2.采样
对一个新序列进行采样的用意是我们想知道这个模型到底学到了什么。
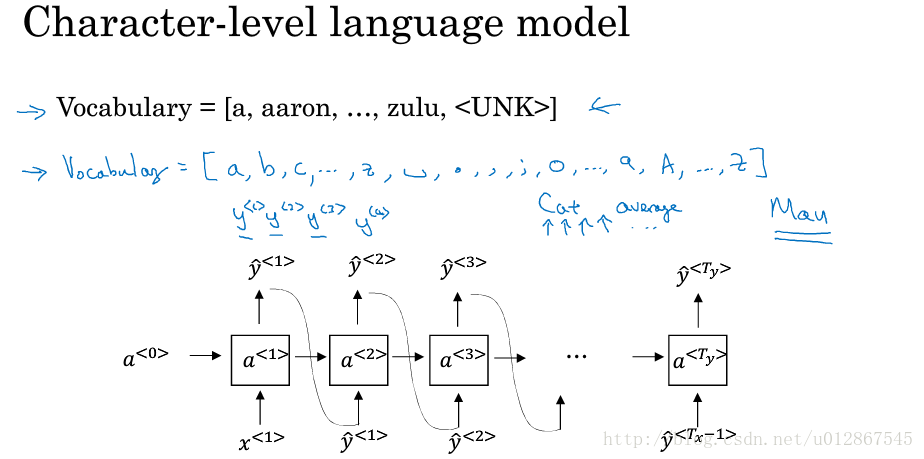
整个模型和上面所说的语言模型时一致的,唯一不同的是
y^<1>−y^<Ty>
y
^
<
1
>
−
y
^
<
T
y
>
是随机选取的。
如一个新序列可能会生成一条新闻或者莎士比亚风格的文章。

四、梯度消失及解决措施
1.梯度消失
有这么一个问题:
- The cat was full.
- The cats were full.
RNN可以很好的根据cat和cats判断出是was还是were,当上2句变成下面2句时。
- The cat,which ……,was full.
- The cats,which ……,were full.
尽管在理论上,RNN可以捕获长距离依赖。 但在实际中,根据谱半径(spectralradius)的不同,RNN将会遇到两个问题:梯度爆炸和梯度消失。梯度爆炸会影响训练的收敛,甚至导致网络不收敛;而梯度消失会使网络学习长期依赖的难度增加。这两者相比, 梯度爆炸相对比较好处理,可以用梯度裁剪来解决,即大于某个阈值时,缩放梯度向量,使得它不会太大;而如何缓解梯度消失是RNN及几乎其他所有深度学习方法研究的关键所在。而GRU和LSTM是这其中2个做的比较不错的方法。
2.GRU
GRU:Gated Recurrent Unit/门控循环单元
简化版本
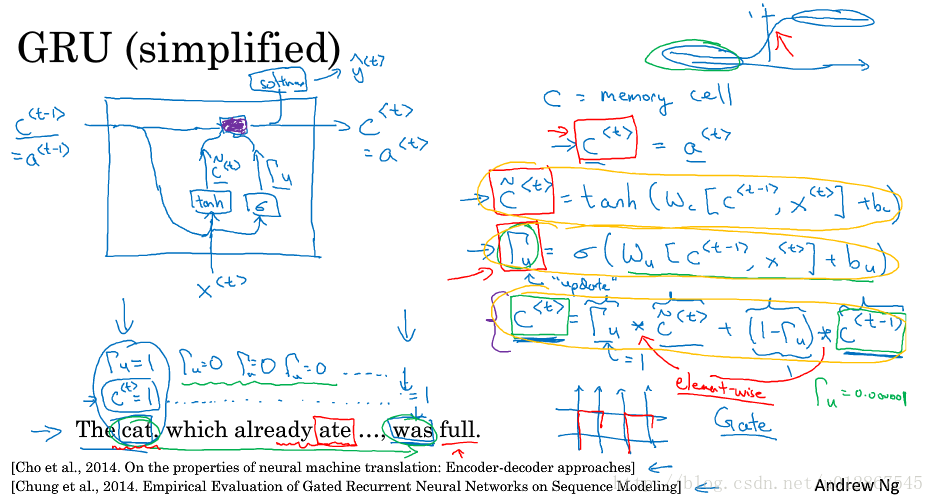
Γu Γ u :更新门,主要是用来控制 c<t> c < t > 是否更新,也就是是否要忽略当前词的影响,比如The cat对整体意思的表达比较重要,因此我们设置 Γu Γ u 为1;反之,which不是那么重要,我们就设置 其为0.这里的0,1只是举例,真实情况是0~1之间的值。
c˜<t> c ~ < t > :候选值,作为替代 c<t> c < t > 的候选值。
c<t> c < t > :记忆细胞,提供了一种记忆的能力,根据前两个的值决定,当更新门为1时,代表要更新,那么最终它的值就是候选值;如果不更新,那么它的值就是前一个记忆细胞 c<t−1> c < t − 1 > 的值。拿上图的例子举例,假设c有2个值,1和0,1代表是单数,0代表是复数,cat的 Γu Γ u 为1,代表要更新,更新它的值为1,代表它是单数,后面的which、already……等词的 Γu Γ u 为0,代表不更新,这样这些词的 c<t> c < t > 都为1,记住的都是cat的值。到was的时候,根据这个值它就能判断前面是单数,因此是was而不是were。
完整版本
完整版本相比简化版多了一个 Γr Γ r 以及在 c˜<t> c ~ < t > 有些许变动。
Γr Γ r :重置门,决定了候选激活时,是否放弃以前的激活。也就是用于控制前一时刻激活单元对当前词的影响。如果不重要,即从当前词开始表述了新的意思,与上文无关,那么可以开启重置。
3.LSTM
LSTM相比于GRU多了一个遗忘门
Γf
Γ
f
和输出门
Γo
Γ
o
。
Γf
Γ
f
:遗忘门,遗忘门起到的作用和GRU的重置门
Γr
Γ
r
是差不多的。
Γo
Γ
o
:输出门,输出门的目的是从记忆单元
c<t>
c
<
t
>
产生激活单元
a<t>
a
<
t
>
。并不是
c<t>
c
<
t
>
中的全部信息都和
a<t>
a
<
t
>
有关,它可能包含了很多对
a<t>
a
<
t
>
无用的信息,因此, 输出门的作用就是判断
c<t>
c
<
t
>
中哪些部分是对
a<t>
a
<
t
>
有用的。
下面放一张GRU和LSTM对比图:
五、双向RNN和深层RNN
1.Bidirectional RNN
如上图所示,第一句的Teddy是人名,第二句的Teddy Roosevelt是人名。在第一句的情况,之前的RNN考虑可以搞定;而第二句的情况在判定Teddy是否是人名的时候,不仅要考虑前面的信息,还要考虑后面的Roosevelt,双向RNN就可以解决这个问题。
双向RNN的结构如上图所示,在原先RNN的基础上(紫色),增加了反向的激活单元(绿色),在正向计算出
a⃗ <1>,a⃗ <2>,a⃗ <3>,a⃗ <4>
a
→
<
1
>
,
a
→
<
2
>
,
a
→
<
3
>
,
a
→
<
4
>
后,紧接着反向计算反向的
a<1>,a<2>,a<3>,a<4>
a
<
1
>
,
a
<
2
>
,
a
<
3
>
,
a
<
4
>
,由2者共同计算出预测值,公式为:
y^<t>=g(Wy[a⃗ <t>,a<t>]+by)
y
^
<
t
>
=
g
(
W
y
[
a
→
<
t
>
,
a
<
t
>
]
+
b
y
)
2.Deep RNNs
深层RNN的常用结构如上图所示,水平连接的有3层,然后你还可以在
x<1>……x<t>
x
<
1
>
…
…
x
<
t
>
的每一列,只添加垂直的很多单元来计算预测值,而不水平连接。结构还是相对清晰明了的,计算
a[i]<t>
a
[
i
]
<
t
>
的公式为:
a[i]<t>=g(W[i]a[a[i]<t−1>,a[i−1]<t>]+b[i]a)
a
[
i
]
<
t
>
=
g
(
W
a
[
i
]
[
a
[
i
]
<
t
−
1
>
,
a
[
i
−
1
]
<
t
>
]
+
b
a
[
i
]
)















 573
573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









