





第二章 高级的HTML解析
当米切朗基罗被问到他如何能雕刻艺术品作为他的大卫,他的著名句据说是:“这是很容易的。你只要把那块看起来不像大卫的石头砍掉就可以了。”
虽然网页抓取与大理石雕刻在大多数其他方面,我们必须采取相似的态度时,提取我们寻求复杂的Web页面的信息。有许多技术来清除的内容,不像我们正在寻找的内容,直到我们到达我们正在寻找的信息。在这一章中,我们将分析复杂的HTML页面,看看只提取信息,我们正在寻找。
你并不总是需要一把锤子
它可以是很有诱惑力,当面对一个棘手的问题标签,马上使用多行语句来提取你的信息。然而,记住,分层的技术在这一节中使用鲁莽的放弃可能会导致代码,是难以调试,脆弱的,或两者都。在开始之前,让我们来看看一些方法可以完全避免需要先进的HTML解析!
让我们说你有一些目标内容。也许这是一个名字,统计,或文本块。也许是埋葬20个标签在没有有用的标记或HTML属性的HTML更深深的被发现。让我们说你潜入并写一些像以下几行代码尝试提取:
bsObj.findAll("table")[4].findAll("tr")[2].find("td").findAll("div")[1].find("a")
那看起来不太好。除了增加以上代码的美学,即使是最轻微的改变网站的网站管理员可能会打破你的网络刮刀。那么你的选择是什么呢?
十三
•找“打印本页”的链接,或者一个移动版本的网站具有更好的格式化的HTML(更多的展示自己作为一个移动设备和12章接收移动网站版本)。
•寻找隐藏在一个JavaScript文件的信息。记住,你可能需要检查为进口的JavaScript文件来做这个。例如,我曾经收集街道地址(随纬度和经度)在一个整齐的格式化阵列寻找在嵌入式谷歌地图显示针尖在每个地址的JavaScript的网站。
这是更常见的网页标题,但信息可能会提供在网页本身的URL。
如果你正在寻找的信息是这个网站的独特的一些原因,你是出于运气。如果不是,尝试其他来源的想法,你可以得到这个信息从。是否有相同的数据的另一个网站?是这个网站显示的数据,它从另一个网站刮或汇总?
特别是当面临着埋葬或不良格式化的数据,重要的是不要只是开始挖掘。深呼吸,思考替代品。如果你确定没有改变土著人的存在,本章的其余部分是给你的。
一份beautifulsoup
在1章中,我们看了BeautifulSoup一眼,安装和运行,以及选择对象的一次。在这一节中,我们将讨论通过属性搜索标签,使用标签的列表,并解析树导航。
几乎每一个网站你遇到包含样式表。虽然你可能认为一层风格的网站,是专门为浏览器和人的解释可能是一个坏事情,CSS的出现实际上是网络铲运机的福音。CSS是HTML元素,否则可能会为了风格不同有相同的标记的分化。也就是说,一些标签可能看起来像这样:
<span class="green"></span>而其他人看起:
<span class="red"></span>网络铲运机可以很容易区分这两种不同的标签,根据其类;例如,他们可能使用BeautifulSoup攫取所有的红色文字但绿色的文本没有。因为CSS属性依赖于这些识别风格的网站适当,你几乎可以保证,这些class和id属性将在最现代的网站很丰富。
让我们创建一个示例Web刮板刮页位于HTTP:/ / www.pythonscraping.com/pages/warandpeace.html。
在这个页面上,故事中的人物所说的台词都是红色的,而人物的名字本身是绿色的。你可以看到span标签,并引用适当的CSS类,在以下的页面的源代码示例:
“Heavens! what a virulent attack!” replied
the prince, not in the least disconcerted
by this reception.
我们可以抓取整个网页和应用程序相似的使用1章创建beautifulsoup对象:
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.pythonscraping.com/pages/warandpeace.html") bsObj = BeautifulSoup(html)使用BeautifulSoup对象,我们可以使用所有功能提取Python列表专有名词的选择只有文字在<span class="green"></ span>标签(findAll是一个非常灵活的功能,我们将使用大量在本书的后面):
nameList = bsObj.findAll("span", {"class":"green"})
for name in nameList:
print(name.get_text())当运行时,它应该列出所有在文本中的专有名词,在战争和和平中出现的顺序。那么这里发生了什么?以前,我们称之为bsobj.tagname为了得到这个标签页上的第一次出现。现在,我们称bsObj.findAll(tagName, tagAttributes)为了让页面上的所有标签的列表,而不是第一个。
获得名单后,程序遍历列表中的所有名字,name.get_text()为了分离内容的标签。
何时.get_text()以及何时保存标签
.get_text() 除去所有的Tags从你正在处理的文档并返回一个字符串包含文本。例如,如果你是一个大的包含很多链接、文本块的工作段,和其他标签,所有这些将被剥夺,你将留下一个未标记的文本块。
记住,它更容易找到你正在寻找一个beautifulsoup对象比文本块。打电话。get_text()始终应该是你做的最后一件事,立即打印之前,存储,或操纵你的最终数据。在一般情况下,你应该尽量保持文档的标签结构尽可能长。
BeautifulSoup()和findall()
BeautifulSoup()和findall()是两个功能你最会用的。利用它们,你可以很容易地过滤HTML页面找到所需的标签列表,或一个单一的标签,基于他们的各种属性。
两功能非常相似,证明了他们的定义,BeautifulSoup文档:
“`
findAll(tag, attributes, recursive, text, limit, keywords) find(tag, attributes, recursive, text, keywords)
在所有的可能性中,95%的时间里,你会发现自己只需要使用前两个参数:标签和属性。然而,让我们更详细地看一看所有的论点。
标签参数是一个我们之前见过你可以通过一个标签或Python列表字符串标签名称字符串名称。例如,以下将返回一个文档中的所有标题标签的列表:(注释1:如果你想得到一个列表中的所有h<some_level> 标签中的文档,有文书‐这代码来完成同样的事情更简洁的方式。我们会在接近这些类型的问题中出现的部分‐beautifulsoup和正则表达式的其他方式看。).findAll({“h1”,”h2”,”h3”,”h4”,”h5”,”h6”})
属性参数采用Python字典属性和匹配包含这些属性的任何一个标签。例如,下面的函数将返回的绿色和红色的span标签在HTML文档:
。.findAll(“span”, {“class”:”green”, “class”:”red”})
递归参数是一个布尔值。如何深入到文档中你想去吗?如果递归设置为true,findAll 功能寻找children,和children’s children,因为匹配你的参数标签。如果它是错误的,它将只看在您的文档中的顶级标签。默认情况下,所有作品递归(复发性设置为true);它离开这通常是一个好主意,除非你真的知道你需要做什么和性能是一个问题。
文本参数是不寻常的,它匹配的基础上的标签的文本内容,而不是标签本身的属性。例如,如果我们想找的次数“王子”被包围在示例网页标签,我们可以取代我们的。下面的行在前面的例子中findall()功能:nameList = bsObj.findAll(text=”the prince”)
print(len(nameList))
输出的结果是“7”。
当然,仅仅是限制的说法,使用FindAll方法;发现相当于相同的所有电话,并限制1。如果您只感兴趣从页面中检索第一个X项目,您可能会设置此设置。但是,要注意,这会给你在页面上的第一个项目,他们发生的顺序,不一定是你想要的第一个项目。
关键字参数允许您选择包含特定属性的标签。例如:allText = bsObj.findAll(id=”text”)
print(allText[0].get_text())
一个警告的关键字参数
在某些情况下,关键字参数可以是非常有帮助的。然而,这在技术上是冗余作为beautifulsoup特征。记住,任何可以做的关键词也可以使用的技术,我们将在这一章中讨论完成(见正则表达式和lambda表达式)。
例如,下面的两行是相同的:bsObj.findAll(id=”text”) bsObj.findAll(“”, {“id”:”text”})
此外,你也可以偶尔碰到使用关键字的问题,尤其是在寻找他们的阶级属性的元素,因为类是Python中的关键字。即,类是Python的一个保留字不能用作变量或参数名称(没有关系到BeautifulSoup。findall()关键字参数,前面讨论过的)。(注释2:Python语言参考提供了一个完整的保护关键词列表。)举个例子,如果你尝试下面的句子,你会得到一个语法错误由于类使用不规范:bsObj.findAll(class=”green”)
相反,你可以用BeautifulSoup的有些笨拙的解决方案,其中包括添加下划线:bsObj.findAll(class_=”green”)
或者,可以在引号中封装类:bsObj.findAll(“”, {“class”:”green”}
在这一点上,你可能会问自己,“但等等,我已经知道如何通过属性传递到函数在字典列表中的标签列表?”
回想过往的标签列表来。findall()通过属性列表作为一个”或“滤波器(即,它选择一个列表中的所有标签,或标签或是TAG3 TAG1…)。如果你有一个冗长的标签列表,你可以结束了很多你不想要的东西。关键字参数允许您添加一个额外的“和”过滤器。
其他beautifulsoup对象
到目前为止,在这本书中,你看到BeautifulSoup库两种类型的对象:bsObj.div.h1
beautifulsoup对象
在上面的代码示例为bsobj
标签对象
在列表或单独通过电话找到和一个 beautifulsoup对象所有检索,或向下钻取,如:
然而,有两个在库中的对象,虽然不太常用,仍然是重要的了解:
NavigableString对象
用于表示文本的标签,而不是标签本身(有些功能‐进行操作,而产生的,navigablestrings,而不是标签对象)。
评论的对象
用于查找在注释标签的HTML注释,<!像这一个- >
这四个对象是唯一的对象,你会遇到(截至发稿时间)在BeautifulSoup图书馆。
导航树
FindAll功能负责的基础上找到他们的名字和属性标签。但是,如果你需要找到一个标签,根据它的位置在文档中?这就是树导航的方便。在1章,我们看到在一个方向航行beautifulsoup树:
bsobj.tag.subtag.anothersubtag
现在让我们在航行,看对面,和对角通过HTML树用我们的高度可疑的在线购物网站http://www.pythonscraping.com/pages/ page3.html例如页面抓取(见图2-1):
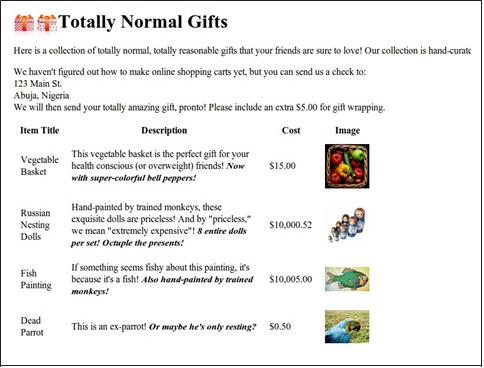
Figure 2-1. Screenshot from http://www.pythonscraping.com/pages/page3.html
The HTML for this page, mapped out as a tree (with some tags omitted for brevity), looks like:
• html
— body
— div.wrapper
— h1
— div.content
— table#giftList
— tr
— th
— th
— th
— th
— tr.gift#gift1
— td
— td
Another Serving of BeautifulSoup | 19
— span.excitingNote
— td
— td
— img
— ...table rows continue...
— div.footer
We will use this same HTML structure as an example in the next few sections.
Dealing with children and other descendants
In computer science and some branches of mathematics, you often hear about horri‐ ble things done to children: moving them, storing them, removing them, and even killing them. Fortunately, in BeautifulSoup, children are treated differently.
In the BeautifulSoup library, as well as many other libraries, there is a distinction drawn between children and descendants: much like in a human family tree, children are always exactly one tag below a parent, whereas descendants can be at any level in the tree below a parent. For example, the tr tags are children of the table tag, whereas tr, th, td, img, and span are all descendants of the table tag (at least in our example page). All children are descendants, but not all descendants are children.
In general, BeautifulSoup functions will always deal with the descendants of the cur‐ rent tag selected. For instance, bsObj.body.h1 selects the first h1 tag that is a descendant of the body tag. It will not find tags located outside of the body.
Similarly, bsObj.div.findAll("img") will find the first div tag in the document, then retrieve a list of all img tags that are descendants of that div tag.
If you want to find only descendants that are children, you can use the .children tag:
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.pythonscraping.com/pages/page3.html") bsObj = BeautifulSoup(html)
for child in bsObj.find("table",{"id":"giftList"}).children:
print(child)
此代码会打印出在giftlist表产品排列表。如果你是它的children()功能使用descendants()函数编写,大约两打标签会被发现在桌子上印刷,包括img标签,span标签,和个人的TD标签。区分儿童和后裔是绝对重要的!
20 | 2章:先进的HTML解析
对待兄弟姐妹
next_siblings() BeautifulSoup功能使平凡的表收集数据,特别是那些有标题行:
从urllib.request进口urlopen
从进口beautifulsoup BS4
HTML = urlopen(“HTTP:/ / www.pythonscraping网站/网页/第三页。html”)bsobj = BeautifulSoup(HTML)
兄弟姐妹在bsobj。找到(“表”,{“id”:“giftlist”})。tr.next_siblings:
打印(兄弟姐妹)
此代码的输出将从产品表中打印所有行的产品,除了第一个标题行以外的所有行。为什么标题行被跳过?原因有两个:第一,对象不能是自己的兄弟姐妹。任何时候你得到一个对象的兄弟姐妹,对象本身将不会被包含在列表中。第二,这个函数调用的下一个兄弟姐妹。如果我们选择的列表,中间一排为例,称next_siblings它,只有随后(下)兄弟姐妹会回来。因此,通过选择标题行和调用next_siblings,我们可以选择表中的所有行,而不选择‐的标题行本身。
选择特定的
注意,上面的代码会一样好,如果我们选择bsobj.table.tr甚至只是bsobj.tr为了选择表格的第一行。然而,在代码中,我经历了所有的麻烦,写一切在一个较长的形式:
bsobj。找到(“表”,{“id”:“giftlist TR”})。
即使它看起来像在页面上只有一个表(或其他目标标签),它很容易错过的东西。此外,页面布局改变所有的时间。什么是第一次在页面上的第一个,可能有一天是第二个或第三个标签,在页面上发现的类型。让你的刀更强大,最好是尽可能的做出选择时,特定的标签。利用标记属性时,他们是可用。
作为next_siblings补充的previous_siblings功能通常可以帮助如果有容易选择的标签在一列兄弟标签结束,你想得到的。
而且,当然,有next_sibling和previous_sibling功能,执行几乎相同的功能next_siblings和previous_siblings,除非他们返回一个单一的标签,而不是他们的列表。
一份| beautifulsoup 21
和你父母打交道
当你的页面,你可能会发现,你需要找到的标签的父母不那么频繁比你需要找到他们的孩子或兄弟姐妹。通常,当我们看他们的爬行目标HTML页面,我们开始寻找在标签顶部的层,然后找出如何钻我们到我们想要的确切数据块。偶尔,然而,你可以在奇数的情况下需要beautifulsoup母发现功能,发现自己和父母。父母。例如:
从urllib.request进口urlopen
从进口beautifulsoup BS4
HTML = urlopen(“HTTP:/ / www.pythonscraping网站/网页/第三页。html”)bsobj = BeautifulSoup(HTML)打印(bsobj。找到(“IMG”,{“src”:“/图片/礼品/ img1 .jpg”
})。父母。previous_sibling get_text())。
此代码将打印出来的对象表示的图像的位置/图片/礼品/ img1.jpg价格(在这种情况下,价格是“15美元”)。
这项工作如何?下面的图表示的POR‐的HTML页面,我们正在与树结构,编号的步骤:
•> <tr>
- < td >
- < td >
- < td >(3)
“15美元”(4)
S<TD>(2)
- <img src=“/图片/礼品/ img1 .jpg”>(1)
1。图像标签,src=“/图片/礼品/ img1 .jpg”是第一选择
2。我们选择这个标签的父(在这种情况下,<公司>标签)。
3。我们选择< td >标签的previous_sibling(在这种情况下,包含产品的美元价值< <td>标签)。
4,我们选择在该标签内的文本,“15美元”
正则表达式
正如旧的计算机科学的笑话所说:“让我们说你有一个问题,你决定用正则表达式来解决它。嗯,现在你有两个问题。”
不幸的是,正则表达式(通常简称regex)经常被教导使用随机的符号串在一起的大桌子,看起来像一大堆废话。这会把人们赶走,后来他们进入劳动力写需要‐较少复杂的搜索和过滤功能,当所有他们需要的首先是一一行的正则表达式!
幸运的是,正则表达式是不是所有的困难起来,并迅速运行,可以很容易地通过寻找和尝试一些简单的例子。
Regular expressions are so called because they are used to identify regular strings; that is, they can definitively say, “Yes, this string you’ve given me follows the rules, and I’ll return it,” or “This string does not follow the rules, and I’ll discard it.” This can be exceptionally handy for quickly scanning large documents to look for strings that look like phone numbers or email addresses.
Notice that I used the phrase regular string. What is a regular string? It’s any string that can be generated by a series of linear rules,3 such as:
1. Write the letter “a” at least once.
2. Append to this the letter “b” exactly five times.
3. Append to this the letter “c” any even number of times.
4. Optionally, write the letter “d” at the end.
Strings that follow these rules are: “aaaabbbbbccccd,” “aabbbbbcc,” and so on (there are an infinite number of variations).
Regular expressions are merely a shorthand way of expressing these sets of rules. For instance, here’s the regular expression for the series of steps just described:
aa*bbbbb(cc)*(d | )
This string might seem a little daunting at first, but it becomes clearer when we break it down into its components:
aa*
The letter a is written, followed by a* (read as a star) which means “any number of a’s, including 0 of them.” In this way, we can guarantee that the letter a is writ‐ ten at least once.
bbbbb
No special effects here—just five b’s in a row.
3 You might be asking yourself, “Are there ‘irregular’ expressions?” Nonregular expressions are beyond the scope of this book, but they encompass strings such as “write a prime number of a’s, followed by exactly twice that number of b’s” or “write a palindrome.” It’s impossible to identify strings of this type with a regular expression. Fortunately, I’ve never been in a situation where my web scraper needed to identify these kinds of strings.
Regular Expressions | 23
(cc)*
Any even number of things can be grouped into pairs, so in order to enforce this rule about even things, you can write two c’s, surround them in parentheses, and write an asterisk after it, meaning that you can have any number of pairs of c’s (note that this can mean 0 pairs, as well).
(d | )
Adding a bar in the middle of two expressions means that it can be “this thing or that thing.” In this case, we are saying “add a d followed by a space or just add a space without a d.” In this way we can guarantee that there is, at most, one d, fol‐ lowed by a space, completing the string.
Experimenting with RegEx
When learning how to write regular expressions, it’s critical to play around with them and get a feel for how they work.
If you don’t feel like firing up a code editor, writing a few lines, and running your program in order to see if a regular expression works as expected, you can go to a website such as RegexPal and test your regular expressions on the fly.
One classic example of regular expressions can be found in the practice of identifying email addresses. Although the exact rules governing email addresses vary slightly from mail server to mail server, we can create a few general rules. The corresponding regular expression for each of these rules is shown in the second column:
Rule 1
The first part of an email address contains at least one of the following: uppercase letters, lowercase letters, the numbers 0-9, periods (.), plus signs (+), or underscores (_). [A-Za-z0-9\._+]+
The regular expression shorthand is pretty smart. For example, it knows that “A-Z” means “any uppercase letter, A through Z.” By putting all these possible sequences and symbols in brackets (as opposed to parentheses) we are saying “this symbol can be any one of these things we’ve listed in the brackets.” Note also that the + sign means “these characters can occur as many times as they want to, but must occur at least once.”
Rule 2
After this, the email address contains the @ symbol. @
This is fairly straightforward: the @ symbol must occur in the middle, and it must occur exactly once.
24 | Chapter 2: Advanced HTML Parsing
Rule 3
The email address then must contain at least one uppercase or lowercase letter. [A-Za-z]+
We may use only letters in the first part of the domain name, after the @ symbol. Also, there must be at least one character.
Rule 4
This is followed by a period (.). \.
You must include a period (.) before the domain name.
Rule 5
Finally, the email address ends with com, org, edu, or net (in reality, there are many possible top-level domains, but, these four should suffice for the sake of example). (com|org|edu|net)
This lists the possible sequences of letters that can occur after the period in the second part of an email address.
By concatenating all of the rules, we arrive at the regular expression:
[A-Za-z0-9\._+]+@[A-Za-z]+\.(com|org|edu|net)
When attempting to write any regular expression from scratch, it’s best to first make a list of steps that concretely outlines what your target string looks like. Pay attention to edge cases. For instance, if you’re identifying phone numbers, are you considering country codes and extensions?.
Table 2-1 lists some commonly used regular expression symbols, with a brief explana‐ tion and example. This list is by no means complete, and as mentioned before, you might encounter slight variations from language to language. However, these 12 sym‐ bols are the most commonly used regular expressions in Python, and can be used to find and collect most any string type.
Table 2-1. Commonly used regular expression symbols
Symbol(s) Meaning Example Example Matches
* Matches the preceding character, subexpression, or bracketed character, 0 or more times a*b* aaaaaaaa, aaabbbbb, bbbbbb
+ Matches the preceding character, subexpression, or bracketed character, 1 or more times a+b+ aaaaaaaab, aaabbbbb, abbbbbb
Regular Expressions | 25
[] Matches any character within the brackets (i.e., “Pick any one of these things”) [A-Z]* APPLE, CAPITALS, QWERTY
() A grouped subexpression (these are evaluated first, in the “order of operations” of regular expressions) (a*b)* aaabaab, abaaab, ababaaaaab
{m, n} Matches the preceding character, subexpression, or bracketed character between m and n times (inclusive) a{2,3}b{2,3} aabbb, aaabbb, aabb
[^] Matches any single character that is not in the brackets [^A-Z]* apple, lowercase, qwerty
| Matches any character, string of characters, or subexpression, separated by the “I” (note that this is a vertical bar, or “pipe,” not a capital “i”) b(a|i|e)d bad, bid, bed
. Matches any single character (including symbols, numbers, a space, etc.) b.d bad, bzd, b$d, b d
^ Indicates that a character or subexpression occurs at the beginning of a string ^a apple, asdf, a
\ An escape character (this allows you to use “special” characters as their literal meaning) \. \| \\ . | \
$ Often used at the end of a regular expression, it means “match this up to the end of the string.” Without it, every regular expression has a defacto “.*” at the end of it, accepting strings where only the first part of the string matches. This can be thougt of as analogous to the ^ symbol. [A-Z]*[a-z]*$ ABCabc, zzzyx, Bob
?! “Does not contain.” This odd pairing of symbols, immediately preceding a character (or regular expression), indicates that that character should not be found in that specific place in the larger string. This can be tricky to use; after all, the character might be found in a different part of the string. If trying to eliminate a character entirely, use in conjunction with a ^ and $ at either end. ^((?![A-Z]).)*$ no-caps-here,
$ymb0ls a4e f!ne
Regular Expressions: Not Always Regular!
The standard version of regular expressions (the one we are cover‐ ing in this book, and that is used by Python and BeautifulSoup) is based on syntax used by Perl. Most modern programming lan‐ guages use this or one very similar to it. Be aware, however, that if you are using regular expressions in another language, you might encounter problems. Even some modern languages, such as Java, have slight differences in the way they handle regular expressions. When in doubt, read the docs!
26 | Chapter 2: Advanced HTML Parsing
Regular Expressions and BeautifulSoup
If the previous section on regular expressions seemed a little disjointed from the mis‐ sion of this book, here’s where it all ties together. BeautifulSoup and regular expres‐ sions go hand in hand when it comes to scraping the Web. In fact, most functions that take in a string argument (e.g., find(id="aTagIdHere")) will also take in a regu‐ lar expression just as well.
Let’s take a look at some examples, scraping the page found at http://www.python‐ scraping.com/pages/page3.html.
Notice that there are many product images on the site—they take the following form:
<img src="../img/gifts/img3.jpg">
If we wanted to grab URLs to all of the product images, it might seem fairly straight‐ forward at first: just grab all the image tags using .findAll("img"), right? But there’s a problem. In addition to the obvious “extra” images (e.g., logos), modern websites often have hidden images, blank images used for spacing and aligning elements, and other random image tags you might not be aware of. Certainly, you can’t count on the only images on the page being product images.
Let’s also assume that the layout of the page might change, or that, for whatever rea‐ son, we don’t want to depend on the position of the image in the page in order to find the correct tag. This might be the case when you are trying to grab specific elements or pieces of data that are scattered randomly throughout a website. For instance, there might be a featured product image in a special layout at the top of some pages, but not others.
The solution is to look for something identifying about the tag itself. In this case, we can look at the file path of the product images:
from urllib.request import urlopenfrom bs4
import BeautifulSoupimport re
html = urlopen("http://www.pythonscraping.com/pages/page3.html") bsObj = BeautifulSoup(html)
images = bsObj.findAll("img", {"src":re.compile("\.\.\/img\/gifts/img.*\.jpg")})
for image in images:
print(image["src"])
This prints out only the relative image paths that start with ../img/gifts/img and end in .jpg, the output of which is the following:
../img/gifts/img1.jpg
../img/gifts/img2.jpg
../img/gifts/img3.jpg
../img/gifts/img4.jpg
../img/gifts/img6.jpg
Regular Expressions and BeautifulSoup | 27
A regular expression can be inserted as any argument in a BeautifulSoup expression, allowing you a great deal of flexibility in finding target elements.
Accessing Attributes
So far, we’ve looked at how to access and filter tags and access content within them. However, very often in web scraping you’re not looking for the content of a tag; you’re looking for its attributes. This becomes especially useful for tags such as <a>, where the URL it is pointing to is contained within the href attribute, or the <img> tag, where the target image is contained within the src attribute.
With tag objects, a Python list of attributes can be automatically accessed by calling:
myTag.attrs
Keep in mind that this literally returns a Python dictionary object, which makes retrieval and manipulation of these attributes trivial. The source location for an image, for example, can be found using the following line:
myImgTag.attrs['src']
Lambda Expressions
If you have a formal education in computer science, you probably learned about lambda expressions once in school and then never used them again. If you don’t, they might be unfamiliar to you (or familiar only as “that thing I’ve been meaning to learn at some point”). In this section, we won’t go deeply into these extremely useful func‐ tions, but we will look at a few examples of how they can be useful in web scraping.
Essentially, a lambda expression is a function that is passed into another function as a variable; that is, instead of defining a function as f(x, y), you may define a function as f(g(x), y), or even f(g(x), h(x)).
BeautifulSoup allows us to pass certain types of functions as parameters into the fin dAll function. The only restriction is that these functions must take a tag object as an argument and return a boolean. Every tag object that BeautifulSoup encounters is evaluated in this function, and tags that evaluate to “true” are returned while the rest are discarded.
For example, the following retrieves all tags that have exactly two attributes:
soup.findAll(lambda tag: len(tag.attrs) == 2)
That is, it will find tags such as the following:
<div class="body" id="content"></div>
<span style="color:red" class="title"></span>
28 | Chapter 2: Advanced HTML Parsing
Using lambda functions in BeautifulSoup, selectors can act as a great substitute for writing a regular expression, if you’re comfortable with writing a little code.
Beyond BeautifulSoup
Although BeautifulSoup is used throughout this book (and is one of the most popu‐ lar HTML libraries available for Python), keep in mind that it’s not the only option. If BeautifulSoup does not meet your needs, check out these other widely used libraries:
lxml
This library is used for parsing both HTML and XML documents, and is known for being very low level and heavily based on C. Although it takes a while to learn (a steep learning curve actually means you learn it very fast), it is very fast at parsing most HTML documents.
HTML Parser
This is Python’s built-in parsing library. Because it requires no installation (other than, obviously, having Python installed in the first place), it can be extremely convenient to use.
Beyond BeautifulSoup | 29
第二章 HTML网页解析
BeautifulSoup包中有两个重要的方法:find()(找第一个)和findAll()(找所有)。它们可以有很多参数,但是绝大多数情况下只需要使用两个就行了。
find(tag,attributes)和 findAll(tag,attributes)
例如
[python]代码片nameList = bsObj.findAll(“span”, {“class”:”green”})
nameList = bsObj.find(“span”, {“class”:”green”})
即获得span标签下,属性class为green的内容。当然我们还可以同时获得class为red的内容,代码如下
[python] 代码片nameList = bsObj.findAll(“span”, {“class”:”green”,”class”:”red”})
nameList = bsObj.find(“span”, {“class”:”green”,”class”:”red”})
如果要获得各个tag下的某个属性内容,可以使用以下方法:
[python] 代码片bsObj.findAll(“”, {“id”:”text”})
即把tag省略来代表所有tag。后面还可以对标签的兄弟姐妹进行操作。
除了BeautifulSoup对象,还有NavigableString对象和The Common对象比较重要,在这里不做细讲。
正则表达式此处略去,详情可参考本人另一篇博客《正则表达式入门(python)》。使用以下代码作为示例:
[python]代码片from urllib.request
import urlopenfrom bs4
import BeautifulSoupimport re
html = urlopen(“http://www.pythonscraping.com/pages/page3.html“)
bsObj = BeautifulSoup(html)
images = bsObj.findAll(“img”, {“src”:re.compile(“..\/img\/gifts/img.*.jpg”)})
for image in images:
print(image[“src”])
“`
示例表示的是找出网页中的所有图片路径。















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









