







2.1 不是一直都要用锤子
如果直接HTML标签中的信息,网站管理员对网站稍微修改之后,爬虫就会失效,那么该怎么做呢?
- 寻找“打印此页”的链接,或者接受网站移动版
- 寻找隐藏在JavaScripy文件里的信息。
- 虽然网页标题经常会用到,但是这个信息也许可以从网页的URL链接里获取
- 寻找其他数据源
2.2 再端一碗BeautifulSoup
Spider可以通过CSS中的Class属性来抓取,如所有红色文字
from urllib.request import urlopen
from bs4 import BeautifulSoup
try:
html = urlopen("http://www.pythonscraping.com/pages/warandpeace.html")
except HTTPError as e:
print(e)
else:
bsObj = BeautifulSoup(html)
nameList = bsObj.findAll("span", {"class":"green"})
for name in nameList:
print(name.get_text())
name.get_text()会把你正在处理的HTML文档中所有的标签都清除,然后返回一个只包含文字的字符串。
BeautifulSoup里的 find()和findAll()可能是最常用的两个函数,可以通过标签的不同属性轻松地过滤HTML页面,查找需要的标签组或单个标签。
BeautifulSoup里的 find()和findAll()可能是最常用的两个函数,可以通过标签的不同属性轻松地过滤HTML页面,查找需要的标签组或单个标签。
findAll(tag, attributes, recursive, text, limit, keywords)
find(tag, attributes, recursive, text, keywords)
其他BeautifulSoup对象:BeeutifulSoup对象、标签Tag对象、NavigableString对象(表示标签里的文字)、Comment对象(查找HTML文档的注释标签)
导航树:通过标签在文档中的位置来查找标签,如bsObj.tag.subTag.anotherSubTag
http://www.pythonscraping.com/pages/page3.html
(1)处理子标签和其他后代标签:bsObj.div.findAll("img")会找出文档中第一个div标签,然后获取这个div后代里所有的img标签列表
只想找出子标签,可以用.children标签:
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.pythonscraping.com/pages/page3.html")
bsObj = BeautifulSoup(html)
for child in bsObj.find("table",{"id":"giftList"}).children:
print(child)from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.pythonscraping.com/pages/page3.html")
bsObj = BeautifulSoup(html)
for sibling in bsObj.find("table",{"id":"giftList"}).tr.next_siblings:
print(sibling)print(bsObj.find("img",{"src":"../img/gifts/img1.jpg"}).parent.previous_sibling.get_text())2.3 正则表达式
regex经常被嘲笑是一堆随机符号的混合物,看着毫无意义,这种印象让人对其避而远之,然后费尽心思写一堆没必要又复杂的查找和过滤函数,其实他们真正需要的就是一行正则表达式。
https://www.regexpal.com/在线测试正则表达式
识别邮箱地址[A-Za-z0-9\._+]+@[A-Za-z]+\.(com|org|edu|net)
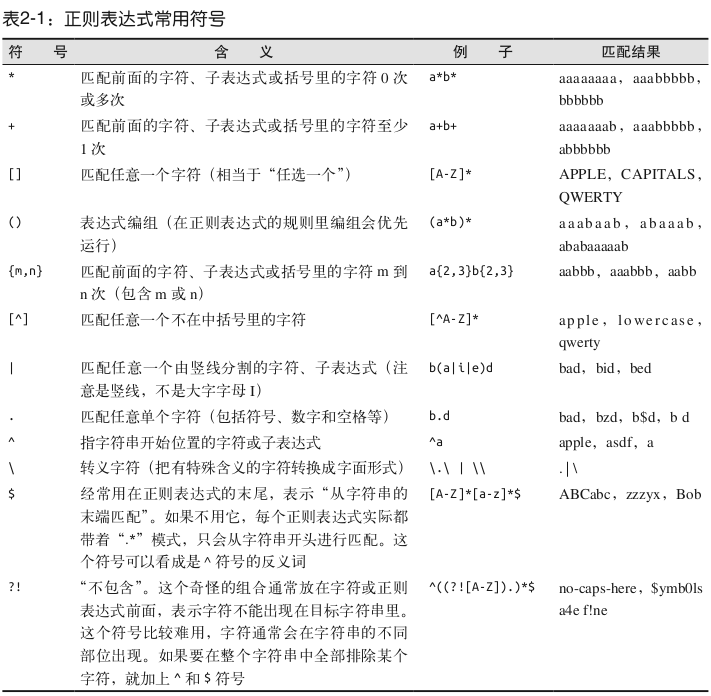
2.4 正则表达式和BeautifulSoup
都是以../img/gifts/img开头,以.jpg结尾
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
html = urlopen("http://www.pythonscraping.com/pages/page3.html")
bsObj = BeautifulSoup(html)
images = bsObj.findAll("img",{"src":re.compile("\.\.\/img\/gifts\/img.*\.jpg")})
for image in images:
print(image["src"])
../img/gifts/img1.jpg
../img/gifts/img2.jpg
../img/gifts/img3.jpg
../img/gifts/img4.jpg
../img/gifts/img6.jpg
2.5 获取属性
经常不需要查找标签的内容,而是需要查找标签属性,比如标签<a>指向的URL链接包含在href属性中
myTag.attrs是一个Python字典对象,可以获取和操作这些属性。
myTag.attrs["src"]
2.6 Lambda表达式
Lambda表达式本质上就是一个函数,可以作为其他函数的变量使用;也就是说,一个函数不是定义成f(x, y),而是定义成f( g(x), y), 或f( g(x), h(x) )的形式。
BS允许我们把特定函数类型当作findAll函数的参数。唯一的限制条件是这些函数必须把一个标签作为参数且返回结果是布尔类型。
如 soup.findAll(lambda tag: len(tag.attrs) == 2)
会找出下面的标签:
<div class="body" id="content"></div>
<span style="color:red" class="title"></span>
2.7 超越BeautifulSoup
BeautifulSooup是Python里最受欢迎的HTML解析库之一,但不是唯一
lxml:底层用C语言写的,速度非常快
HTML parser:Python自带的解析库















 286
286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









