







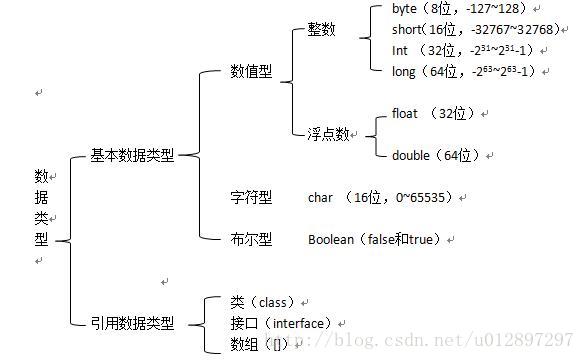
Java语言基础组成
1、关键字:被Java语言赋予了特殊含义的单词,关键字中所有字母都是小写。
2、注释:单行注释,多行注释,文档注释。
3、标识符:在程序中自定义的一些名称。
由26个英文字母大小写,数字:0-9符号:_ $组成
定义合法标识符规则:
1, 数字不可以开头。
2,不可以使用关键字。
Java中严格区分大小写。
注意:在起名字的时,为了提高阅读性,要尽量有意义。
main不是关键字,但是被JVM所识别。
Java中严格区分大小写。
Java中的名称规范:
包名:多单词组成时所有字母都小写。xxxyyyzzz
类名接口名:多单词组成时,所有单词的首字母大写。XxxYyyZzz
变量名和函数名:多单词组成时,第一个单词首字母小写,第二个单词开始每个单词首字母大写。xxxYyyZzz
常量名:所有字母都大写。多单词时每个单词用下划线连接。XXX_YYY_ZZZ
4、常量:表示不能改变的数值。
(1)Java中常量的分类:
1,整数常量。所有整数
2,小数常量。所有小数
3,布尔型常量。较为特有,只有两个数值。true false。
4,字符常量。将一个数字字母或者符号用单引号( ' ' )标识。
5,字符串常量。将一个或者多个字符用双引号标识。
6,null常量。只有一个数值就是:null.
(2)整数常量表现形式:二进制,八进制,十进制,十六进制(要会进制间的转换)
(3)负数的二进制表现形式:对应的正数二进制取反加1
如-6:
6:0000-0000 0000-0000 0000-0000 0000-0110
取反:1111-1111 1111-1111 1111-1111 1111-1001
加1 :1111-1111 1111-1111 1111-1111 1111-1010,即-6
负数的最高位是1,正数的最高位是0.
拓展:关于补码、原码
1、在计算机系统中,数值一律用补码来表示(存储)。 主要原因:使用补码,可以将符号位和其它位统一处理;同时,减法也可按加法来处理。另外,两个用补 码表示的数相加时,如果最高位(符号位)有进位,则进位被舍弃。 2、补码与原码的转换过程几乎是相同的。
1)正数的补码与原码相同。
【例1】+9的补码是00001001。(备注:这个+9的补码说的是用8位的2进制来表示补码的,补码表示方式很多,还有16位二进制补码表示形式,以及32位二进制补码表示形式,64位进制补码表示形式等。)
2)负数的补码等于其绝对值的原码各位取反,然后整个数加1的数值。
同一个数字在不同的补码表示形式里头,是不同的。比方说-15的补码,在8位二进制里头是11110001,然而在16位二进制补码表示的情况下,就成了1111111111110001。在这篇补码概述里头涉及的补码转换默认把一个数转换成8位二进制的补码形式,每一种补码表示形式都只能表示有限的数字。
【例2】求-7的补码。
因为给定数是负数,则符号位为“1”。
后七位:-7的原码(10000111)→按位取反(11111000)(负数符号位不变)→加1(11111001)
所以-7的补码是11111001。
注:数0的补码表示是唯一的:
+0的补码=+0的反码=+0的原码=00000000
-0的补码=11111111+1=00000000(mod 2的8次方)
应用
已知一个数的补码,求原码的操作分两种情况:
⑴如果补码的符号位为“0”,表示是一个正数,其原码就是补码。
⑵如果补码的符号位为“1”,表示是一个负数,那么求给定的这个补码的补码就是要求的原码。
【例3】已知一个补码为11111001,则原码是10000111(-7)。
因为符号位为“1”,表示是一个负数,所以该位不变,仍为“1”。
其余七位1111001取反后为0000110;
再加1,所以是10000111。
5、变量:内存中的一个存储区域,该区域有自己的名称(变量名)和类型(数据类型),该区域的数据可以在同一类型范围内不断变化 。
将不确定的数据进行存储,也就是在内存中开辟一个空间。
开辟空间就是通过明确数据类型、变量名称、数据来完成。
(1)Java语言是强类型语言,对于每一种数据都定义了明确的具体数据类型,在内存总分配了不同大小的内存空间
(2)整数默认:int 小数默认:double
定义float类型数据时,后面要加f。
一个汉字占16位,可以认为是char类型。
定义的基本数据类型在Java中都是带符号的,boolean和char不带符号。
(3)自动类型转换(也叫隐式类型转换)
强制类型转换(也叫显式类型转换)
表达式的数据类型自动提升:
所有的byte型、short型和char的值将被提升到int型。
如果一个操作数是long型,计算结果就是long型;
如果一个操作数是float型,计算结果就是float型;
如果一个操作数是double型,计算结果就是double型。
(两个byte运算、两个short、两个char都会先提升成int型。)

/*拓展:关于Unicode编码
问题:char a='\U000d';为什么会编译失败
最佳答案:这是java编译器的一个缺陷,
你不能使用 Unicode的换行,斜杠等字符,至于为什么,举个例子:
public static void main(String[] args) {
if ( false == true ) { //these characters are magic: \u000a\u007d\u007b
System.out.println("false is true!");
}
}
你可以运行上面的方法,会输出 false is true!
java在编译时会先将Unicode字符进行 呈现(或翻译),然后再进行编译 ,上面的方法会变成
public static void main(String[] args) {
if ( false == true ) { //these characters are magic:
}{
System.out.println("false is true!");
}
}
再来看你的代码
char a='\U000d';
会变成:
char a='
';
这样就会产生语法错误。这就是原因了
下面的代码是可以通过编译的
char c=' ';\u000d;
可以这样理解,代码中的 Unicode并不能理解为单纯的 字符或字符串,他们本身就是你的代码
如:
System.out.println("Unicode print ");
这一行代码你可以写成
\u0053\u0079\u0073\u0074\u0065\u006d\u002e\u006f\u0075\u0074\u002e\u0070\u0072\u0069\u006e\u0074\u006c\u006e\u0028\u0022\u0055\u006e\u0069\u0063\u006f\u0064\u0065\u0020\u0070\u0072\u0069\u006e\u0074\u0020\u0022\u0029\u003b\u0020
其实都是一样的,只是书写和查看都很不方便 。
建议不要在代码中书写Unicode形式的字符,很容易产生奇怪的错误,而且不方便查看和修改
*/6、运算符
(1)算数运算符

算术运算符的注意问题:
如果对负数取模,可以把模数负号忽略不记,如:5%-2=1。但被模数是负数就另当别论。
对于除号“/”,它的整数除和小数除是有区别的:整数之间做除法时,只保留整数部分而舍弃小数部分。
“+”除字符串相加功能外,还能把非字符串转换成字符串,字符串数据和任何数据
使用“+”号相连结果都是字符串。
1%5=1;-1%5=-1;-1%-5=-1——就是说余数的符号只看被除数。
转义字符:通过\来转变后面字符的含义
\n:转行
\b:退格
\r:按下回车键
\t:制表符,Tab键
Linux里,换行由一个字符表示\n
Windows里,换行符由两个字符表示\r\n
(2)赋值符:= , +=,-=, *=, /=, %=
short s = 3;
s=s+2;//编译报错,两次运算,先加法再赋值
s+=2;//编译通过,一次运算,只有赋值。内部有自动转换动作,赋值时自动完成了强制转换操作。
//例子
byte a=123,b=0;
a+=134;//257 被强转为byte类型,为1.
b=a;
System.out.println(a); //结果为1.
System.out.println(b);
(3)比较运算符
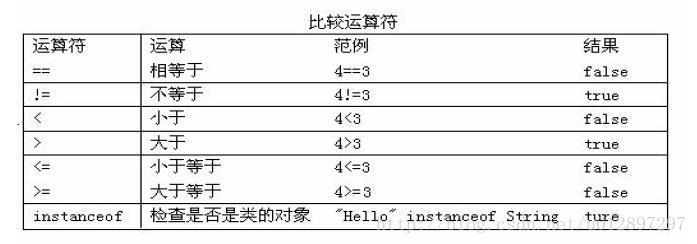
注1:比较运算符的结果都是boolean型,也就是要么是true,要么是false。
注2:比较运算符“==”不能误写成“=”。
(4)逻辑运算符
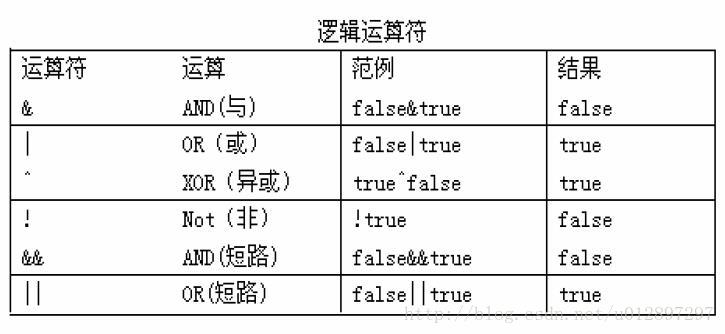
逻辑运算符用于连接布尔型表达式,在Java中不可以写成3<x<6,应该写成x>3 & x<6 。
“&”和“&&”的区别:
单&时,左边无论真假,右边都进行运算;
双&时,如果左边为真,右边参与运算,如果左边为假,那么右边不参与运算。
“|”和“||”的区别同理,双或时,左边为真,右边不参与运算。
异或( ^ )与或( | )的不同之处是:当左右都为true时,结果为false。
(5)位运算符

位运算是直接对二进制进行运算。做运算时,位运算的运算速度最快。
<<:空位补0,被移除的高位丢弃,空缺位补0。
>>:被移位的二进制最高位是0,右移后,空缺位补0;最高位是1,空缺位补1。
>>>:被移位二进制最高位无论是0或者是1,空缺位都用0补。
&:二进制位进行&运算,只有1&1时结果是1,否则是0;
|:二进制位进行| 运算,只有0 | 0时结果是0,否则是1;
^:任何相同二进制位进行^ 运算,结果是0;1^1=0 , 0^0=0不相同二进制位^ 运算结果是1。1^0=1 , 0^1=1
反码:正数取反加1就是对应的负数,负数减1取反就是对应的正数。
负数的原码是符号位不变,其他位取反加1.
异或:一个数异或同一个数偶数次,结果还是那个数。比如7^2^2=7。
拓展:关于移位
1.<<:没有溢出时,相当于乘以2的移位数次方。
正数溢出就是指最高位的1移动到符号位开始。负数溢出就是指高位第一个0移动到符号位开始。
比如4,二进制是0000-00000000-0000 0000-0000 0000-0100,移动29位之前都是符合以上规律
2.>>:对于正整数而言,相当于除以2的移位次方取商。
对于负数:负数能被2的右移的位数次方整除的话可能也是符合的,如果不能被其整除的话貌似就是负数除以2的右移位数次方再减1可以了
注意: 如果对 char、byte 或者short 类型的数值进行移位处理,那么在移位进行之前,它们会自动转换为int,并且得到的结果也是一个int 类型的值。而右侧操作数,作为真正移位的位数,只有其二进制表示中的低5 位才有用。这样可防止我们移位超过int 型值所具有的位数。(译注:因为2 的5 次方为32,而int 型值只有32 位)。若对一个long 类型的数值进行处理,最后得到的结果也是long。此时只会用到右侧操作数的低6 位,以防止移位超过long 型数值具有的位数。
比如,1>>21,首先对21的低五位取模,得到21,再移位,移动21位
1>>32,首先对32的低五位取模,得0,即移动的位数为0位。
练习:
1.最有效率的方式算出2乘以8等于几?2<<3;
2.对两个整数变量的值进行互换
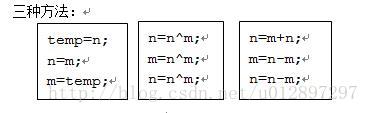
(6):三元运算符
格式: (条件表达式)?表达式1:表达式2;
如果条件为true,运算后的结果是表达式1;
如果条件为false,运算后的结果是表达式2;
拓展:
(1)假如表达式1和表达式2具有相同的类型,那么整个条件运算符结果的类型就是这个类型。
(2)假如一个表达式的类型是T,T是byte或short或char,另一个表达式的类型是int类型的常量表达式,而且这个常量表达式的值是可以用类型T表示的(也就是说,常量表达式的值是在类型T的取值范围之内),那么整个条件运算符结果的类型就是T。
(3)除以上情况外,假如表达式1和表达式2的类型不同,那么将进行类型提升,整个条件运算符结果的类型就是提升后的类型
7、流程控制语句
(1)判断语句
If语句:条件表达式无论写成什么样子,只看最终的结构是否是true 或者false;
If-else语句的简写格式:变量=(条件表达式)?表达式1:表达式2;即三运算符。三元运算符的好处就是能简写if-else代码,弊端就是因为是一个运算符,所以运算完必须要有一个结果。
(2)选择结构
switch语句特点:
1、switch语句选择的类型只有四种:byte,short,int ,char。
2、case之间与default没有顺序。先执行第一个case,没有匹配的case执行default。
3、结束switch语句的两种情况:遇到break,执行到switch语句结束。
4、如果匹配的case或者default没有对应的break,那么程序会继续向下执行,运行可以执行的语句,直到遇到break或者switch结尾结束。case语句不能重复。
关于if和switch:两个语句很像,如果判断的具体数值不多,而且符合byte,short,int ,char这四种类型,虽然两个语句都可以用,建议使用switch语句,因为效率较高。对区间判断,结果是boolean类型的判断,使用if语句。If的适用范围更广。
//实例
int x=2;
switch (x)
{
default:
System.out.println('a');
case 3:
System.out.println('b');
case 4:
System.out.println('c');
break;
case 5:
System.out.println('d');
break;
}//结果为a b c
/*解析:执行顺序是 case 3—case 4—case 5—default(输出a,由于没有break或者大括号,所以继续向下执行)—case 3(输出 b)—case 4(输出c,此时遇到break,跳出switch语句)
*/(3)循环结构
代表语句:while , do while , for
do while特点是条件无论是否满足,循环体至少被执行一次。
do
{//执行语句
}while(条件表达式);//do-while语句中while后面要加分号
while(条件表达式)//后不能加分号,否则可能是无限循环
{//执行语句
}
for循环的格式:
for(初始化表达式;循环条件表达式;循环后的操作表达式)
{
执行语句;
}
注意
1,for里面的连个表达式运行的顺序,初始化表达式只读一次,判断循环条件,为假就立即跳出循环,为真就执行循环体,然后再执行循环后的操作表达式,接着继续判断循环条件,重复找个过程,直到条件不满足为止。
2,while与for可以互换,区别在于for为了循环而定义的变量在for循环结束就是在内存中释放。而while循环使用的变量在循环结束后还可以继续使用。变量有自己的作用域,对于for而言,如果用于控制循环的变量定义在for语句中,那么该变量只在for语句中有效。for语句执行完毕,该变量在内存中被自动释放。
3,最简单无限循环格式:while(true), for(;;),无限循环存在的原因是并不知道循环多少次,而是根据某些条件,来控制循环。
4,for中的循环条件表达式必须是boolean类型,如果空着,就默认表达式恒为真。
//实例
int i=0;
for(System.out.print('a');i<2;System.out.print('c'))
{
System.out.print('d');
i++;
}//运行结果是adcdc
//用for嵌套循环打印乘法表:
public class Test {
public static void main(String[] args)
{
chengFa(9);
}
public static void chengFa(int a)
{
for(int i=1;i<=a;i++)//控制行数
{
for(int j=1;j<=i;j++)//控制列数
System.out.print(j+"*"+i+"="+j*i+"\t");
System.out.println();
}
}
}
注意:关于循环
循环中的循环条件表达语句都可以用true。但是不能用false,因为没意义,执行不到下面的语句,会编译失败。而且也都不能用0和1,只能是boolean类型。
(4)break和continue语句
break(跳出), continue(继续)
break语句:应用范围:选择结构和循环结构。
continue语句:应用于循环结构。
注:
a,这两个语句离开应用范围,存在是没有意义的。
b,这个两个语句单独存在下面都不可以有语句,因为执行不到。如果有,就回编译失败。
c,continue语句是结束本次循环继续下次循环。
d,标号(只能用于循环,标号名称要符合标识符的格式,用冒号与循环隔开)的出现,可以让这两个语句作用于指定的范围。
//实例
//break用法:
for(int x=0;x<4;x++)
{
for(int y=0;y<4;y++)
{System.out.print(y);
break;//break用于跳出当前所在循环
}
}//执行结果为0000
one:for(int x=0;x<4;x++)
{for(int y=0;y<4;)
{y++;
System.out.print(y);
break one;//break跳出外层循环
}
}//执行结果为0
//Continue 用法:
for(int x=0;x<4;x++)
{for(int y=0;y<9;y++)
{if(y%2==0)
continue;//当y是偶数时,继续执行内循环
System.out.print(y);
}
}//执行结果为1357135713571357
one:for(int x=0;x<4;x++)
{for(int y=0;y<2;y++)
{
if(x%2!=0)
{System.out.print("x"+x);
continue one;//x是偶数时,结束内循环继续执行外循环 }}
}//执行结果为x1x3
8、函数
函数就是定义在类中的具有特定功能的一段独立小程序。函数也称为方法。(把代码中相同的部分抽取出来封装成一个独立的功能,Java中对功能的定义是通过函数的形式来体现的,函数只有被调用时才会执行,函数放在类里。)
函数的格式:

返回值类型:函数运行后的结果的数据类型。
参数类型:是形式参数的数据类型。
形式参数:是一个变量,用于存储调用函数时传递给函数的实际参数。
实际参数:传递给形式参数的具体数值。
return:用于结束函数。
返回值:该值会返回给调用者。
函数的特点:
1.定义函数可以将功能代码进行封装
2.便于对该功能进行复用
3.函数只有被调用才会被执行
4.函数的出现提高了代码的复用性
5.对于函数没有具体返回值的情况,返回值类型用关键 字void表示,那么该函数中的return语句如果在最后一行可以省略不写。
注意:
函数中只能调用函数,不可以在函数内部定义函数。
定义函数时,函数的结果应该返回给调用者,交由调用者处理。
函数之间是平级,不可以哪个函数包含哪个函数,只能调用,放在类中,各函数间定义无顺序之分,系统会自动执行main函数
定义函数:明确要定义的功能最后的结果是什么,即明确返回值类型。
明确在定义该功能的过程中,是否需要未知内容参与运算,即明确参数列表
函数的重载(overload):在同一个类中,允许存在一个以上的同名函数,只要它们的参数个数或者参数类型不同即可。(与返回值类型无关,只看参数列表。)
当定义的功能相同,但参与运算的位置内容不同(即参数列表),那么这时就可以定义相同的函数名称以表示其功能,方便于阅读,优化了程序设计。
void show(int a,int b,int c)
{}
boolean show(int a,int b,int c)
{return false;}
/*上述二者没有重载,而且不允许二者在同一个类中出现,因为假如调用show函数,系统将不知道调用哪一个。编译出错。
*/9、数组
同一种类型数据的集合。其实数组就是一个容器。可以自动给数组中的元素从0开始编号,方便操作这些元素。
格式1:
元素类型[] 数组名= new 元素类型[元素个数或数组长度(必须写)];
示例:int[] arr = newint[5];
格式2:
元素类型[] 数组名= new 元素类型[]{元素,元素,……};
int[] arr = newint[]{3,5,1,7};
int[] arr ={3,5,1,7};
数组操作常见问题
1.数组脚标越界异常(ArrayIndexOutOfBoundsException)
int[] arr = new int[2];
System.out.println(arr[3]);
访问到了数组中的不存在的脚标时发生。
该代码在编译时没有错误,运行时出现错误提示:数组角标越界异常。所以,只有在运行时才会建立数组,编译只检查语法错误。
2.空指针异常(NullPointerException)
int[] arr = null;
System.out.println(arr[0]);
arr引用没有指向实体,却在操作实体中的元素时。
该代码在编译时没有错误,运行时出现错误提示:空指针异常
内存结构
Java程序在运行时,需要在内存中的分配空间。为了提高运算效率,有对空间进行了不同区域的划分,因为每一片区域都有特定的处理数据方式和内存管理方式。
*栈内存
用于存储局部变量,当数据使用完,所占空间会自动释放。
*堆内存
数组和对象,通过new建立的实例都存放在堆内存中。
每一个实体都有内存地址值
实体中的变量都有默认初始化值
实体不再被使用,会在不确定的时间内被垃圾回收器回收
*还有方法区,本地方法区,寄存器
内存实例:
1.栈内存
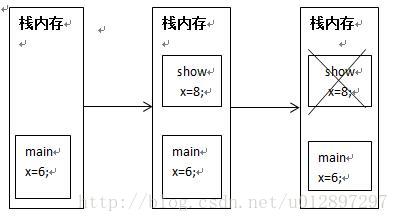
解释:有主函数main函数和show函数,两个函数中都有变量x,主函数运行时,会在栈中开辟一个空间,当调用show函数时,也会在栈中开辟一个空间,当show函数执行完毕,为show开辟的空间就会自动消失
局部变量都在栈中(定义在方法中的变量,方法的参数,for循环中的变量)
2,堆内存
(1) int[] x=newint[3];
首先,当读到赋值号左边时,栈内存会定义一个x,开辟一个空间。如图:

然后,new出来的东西都存放在堆内存中,是实体。因此,读赋值号右边时会在堆内存开辟一个空间,用于存放数组,这个空间有存放位置,假设该数组的起始位置为0X0078,即地址值。数组定义了长度,所以会分为三个小区域。如图:
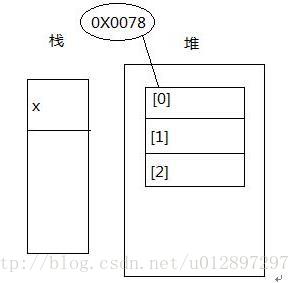
再然后,这个地址值会赋给栈中的x,因此x指向了该数组。如图:

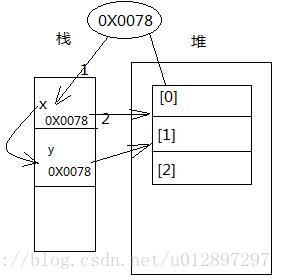
(2)
int[]x=newint[3];
int[]y=x;
y[1]=89;
x=null;首先,执行第一行代码,定义了一个长度为3的数组。
然后执行第二行代码,在栈内存中开辟了一个空间存放y,将x的值赋给了y,即数组地址值赋给了y,于是,y也指向了该数组。如图:
然后执行第三行代码,堆里的实体都有默认初始化值,该数组的初始化值都是0.当执行代码时x[1]变成了89。当执行第四行代码时,x指向空,即x不再指向该数组。此时,该数组还没有变成垃圾,因为变量y还指向该数组。假如,还有一行代码为y=null,那么该数组彻底没有被引用了,就变成了垃圾,会被Java的垃圾回收机制不定时被清除,释放堆内存的空间。如图:
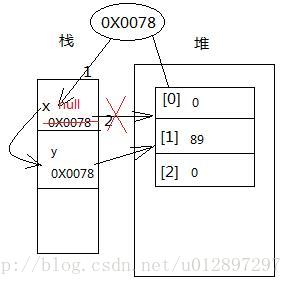
综上所述:
1,new出来的实体(数组和对象)在堆内存中,堆内存中存放的就是实体。
2,堆内存中的每个实体都有一个存放位置,用地址标识数据存放的位置,数组存放时有一个起始位置,将这个值赋给x(x在栈中),此时x指向了该数组,或引用了该数组。
3,堆内存中的实体是用于封装数据的,而堆内存中的实体中的数据都有默认初始化值,如:int—0,double—0.0,boolean—false。
4,若不想x指向这个数组,那就用x=null。只有引用数据类型才能用null.
5,int[]x=newint[3];
System.out.println(x);
这个代码的运行结果是[I@60e128([代表一维数组,I代表int类型,60e128代表内存地址)
数组的操作
1、获取最值(通常用到遍历)
int[]x={99,2,-1,0,34,3,87};
int max=x[0];//max是数组中的数值
for(int i=1;i<x.length;i++)//遍历
{if(max<x[i])
max=x[i];
}
System.out.println(max);
//或者:
int[]x={99,2,-1,0,34,3,87};
int max=0;//max是角标
for(int i=1;i<x.length;i++)
{if(x[max]<x[i])
max=i;
}
System.out.println(x[max]);
2、排序
选择排序:选择一个固定的位置跟其他位置比
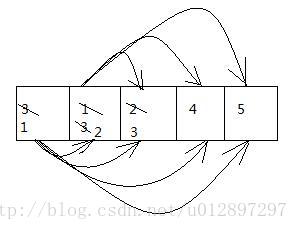
就是先拿0角标位跟其他位置比较换位,再是1角标位跟1之后的角标位比较换位,再是2角标位跟2之后的角标位比较换位。。。依次下去。。。
for(int i=0;i<x.length-1;i++)
{for(int j=i+1;j<x.length;j++)
{if(x[i]>x[j])
{//换位;
}}}
冒泡排序:相邻的两个元素进行比较,符合条件就换位
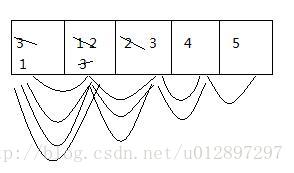
0角标和1角标比;1和2比;2和3比。。这就这样循环,每次都减少一次比较
for(int i=0;i<x.length-1;i++)
{for(int j=0;j<x.length-1-i;j++)
{if(x[j]>x[j+1])
{//换位;
}}}
选择排序特点:内循环结束一次,最值出现在0角标位
冒泡排序特点:内循环结束一次,最值出现在末角标位
排序中换位功能代码抽取:
public staticvoidchenge(int[]arr,inta,intb)
{int temp=arr[a];
arr[a]=arr[b];
arr[b]=temp;}3,折半查找:能提高效率,但必须是有序数组
//法一:
public static int halfSearch(int[] arr,int key)
{
int min,max,mid;
min = 0;
max = arr.length-1;
mid = (max+min)/2;
while(arr[mid]!=key)
{if(key>arr[mid])
min = mid + 1;
else if(key<arr[mid])
max = mid - 1;
if(min>max)
return -1;
mid = (max+min)/2;
}
return mid;
}
//法二:
public static int halfSearch_2(int[] arr,int key)
{int min = 0,max = arr.length-1,mid;
while(min<=max)
{mid = (max+min)>>1;
if(key>arr[mid])
min = mid + 1;
else if(key<arr[mid])
max = mid - 1;
else
return mid;
}return -1;
}
//将一个元素插入到一个有序数组中,求插入位置
public static int getIndex_2(int[] arr,int key)
{int min = 0,max = arr.length-1,mid;
while(min<=max)
{mid = (max+min)>>1;
if(key>arr[mid])
min = mid + 1;
else if(key<arr[mid])
max = mid - 1;
else
return mid;
}
return min;
二维数组
格式1:int[][] arr = new int[3][2];
定义了名称为arr的二维数组,二维数组中有3个一维数组,每一个一维数组中有2个元素,一维数组的名称分别为arr[0], arr[1], arr[2],给第一个一维数组1脚标位赋值为78写法是:arr[0][1] =78;
格式2:int[][] arr = new int[3][];
二维数组中有3个一维数组,每个一维数组都是默认初始化值null,可以对这个三个一维数组分别进行初始化
arr[0] = new int[3];
arr[1] = new int[1];
arr[2] = new int[2];格式3:int[][] arr= {{3,8,2},{2,7},{9,0,1,6}};
定义一个名称为arr的二维数组,二维数组中的有三个一维数组,每一个一维数组中具体元素也都已初始化
第一个一维数组arr[0] = {3,8,2};
第二个一维数组arr[1] = {2,7};
第三个一维数组arr[2] = {9,0,1,6};
第三个一维数组的长度表示方式:arr[2].length;
Java中多维数组的声明和初始化应按照从高维到地维的顺序进行。
int[][] arr =newint[3][2];
System.out.println(arr);
System.out.println(arr[0]);//结果为[[I@60e128 [I@5e1077(一个二维和一个一维)
二维数组内存:
int[][] arr = new int[3][];
arr[0] = new int[3];
arr[1] = new int[1];
arr[2] = new int[2];当运行第一行代码时,可以认为是数据类型为一维数组的一维数组。在栈内存中开辟了一个空间,用来存储变量arr,在堆内存中开辟了一个空间,用来存储数组,因为没有初始化所以默认初始化为null。数组的地址值赋给arr,arr指向该数组,如图:

当执行到第二行代码时,会在堆内存中再开辟一个空间,分为3个区域,默认初始化值为0,并将首地址值赋给二维数组中的第一个数组[0],数组中第一个引用就指向了这个长度为3的数组。第三、四行代码同理。如图:
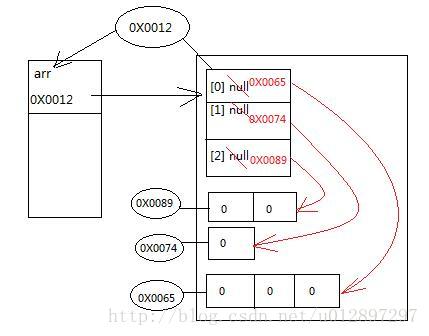















 9978
9978

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









