






本章的目的是帮助您以一种在ARM架构上编译高效的方式编写C代码。我们将通过许多小例子来展示编译器如何将C源代码转换为ARM汇编代码。一旦您了解了这个转换过程,就能够区分快速的C代码和慢速的C代码。这些技术同样适用于C++,但在这些例子中我们将专注于纯C。
我们首先概述C编译器和优化,这将让您了解C编译器在优化代码时面临的问题。通过理解这些问题,您可以编写更高效的源代码,提高速度并减小代码大小。下面的小节按主题进行分组。
第5.2节和第5.3节介绍了如何优化基本的C循环。这些节以数据包校验和作为简单的示例来说明相关思想。第5.4节和第5.5节介绍了如何优化整个C函数体,包括编译器如何在函数内分配寄存器以及如何减少函数调用的开销。
第5.6节到第5.9节探讨了与内存相关的问题,包括处理指针以及如何高效地压缩数据和访问内存。第5.10节到第5.12节介绍了通常不直接由ARM指令支持的基本操作。您可以使用内联函数和汇编语言来添加自己的基本操作。
最后一节总结了在将C代码从其他架构移植到ARM架构时可能遇到的问题。
5.1 Overview of C Compilers and Optimization
本章假设您熟悉C语言并具有一定的汇编程序设计知识。后者并非必需,但对于跟踪编译器输出示例很有用。有关ARM汇编语法的详细信息,请参见第三章或附录A。
优化代码需要时间并降低源代码的可读性。通常,只有经常执行且对性能至关重要的函数值得优化。我们建议您使用大多数ARM模拟器中都有的性能分析工具来查找这些经常执行的函数。使用源代码注释来记录不明显的优化以帮助可维护性。
C编译器必须按照字面意义将您的C函数转换为汇编语言,以便其适用于所有可能的输入。实际上,许多输入组合是不可能的或不会发生的。让我们从一个例子开始,看看编译器面临的问题。memclr函数清除地址为data的N个字节的内存。
void memclr(char *data, int N)
{
for (; N>0; N--)
{
*data=0;
data++;
}
}无论编译器有多先进,它都不知道N在输入时是否可能为0。因此,在循环的第一次迭代之前,编译器需要显式地测试这种情况。
编译器不知道data数组指针是否是四字节对齐的。如果它是四字节对齐的,则编译器可以使用int存储而不是char存储一次清除四个字节。编译器也不知道N是否是四的倍数。如果N是四的倍数,则编译器可以重复循环体四次或一次存储四个字节。
编译器必须保守,并假设N的所有可能值以及data的所有可能对齐方式。第5.3节详细讨论了这些具体点。
要编写高效的C代码,您必须了解C编译器必须保守的区域,C编译器正在映射的处理器架构的限制,以及特定C编译器的限制。
本章大部分内容涵盖了上述前两点,并适用于任何ARM C编译器。第三点将非常依赖于编译器供应商和编译器版本。您需要查看编译器的文档或自己进行实验。
为了使我们的示例具体化,我们使用以下特定的C编译器进行了测试:
■ ARM Developer Suite版本1.1 (ADS1.1) 的 armcc。您可以直接从ARM许可该编译器或其后续版本。
■ arm-elf-gcc 版本2.95.2。这是GNU C编译器(gcc)的ARM目标,可以免费获取。
我们使用来自ADS1.1的armcc来生成本书中示例的汇编输出。以下简短的脚本演示了如何在C文件test.c上调用armcc。您可以使用此脚本来复现我们的示例。
armcc -Otime -c -o test.o test.c
fromelf -text/c test.o > test.txt
默认情况下,armcc开启了全部优化(-O2命令行开关)。-Otime开关针对执行效率进行优化,而不是空间优化,主要影响for和while循环的布局。如果您使用gcc编译器,则以下简短的脚本将生成类似的汇编输出列表:
arm-elf-gcc -O2 -fomit-frame-pointer -c -o test.o test.c
arm-elf-objdump -d test.o > test.txt
默认情况下,GNU编译器关闭了全部优化。-fomit-frame-pointer开关会阻止GNU编译器维护帧指针寄存器。帧指针有助于通过指向存储在堆栈帧上的局部变量来调试查看。然而,它们在维护方面效率低下,并且不应该在对性能至关重要的代码中使用。
5.2 Basic C Data Types
让我们首先看一下ARM编译器如何处理基本的C数据类型。我们将会发现,某些类型在用于局部变量时更为高效。在加载和存储每种类型的数据时,也存在着不同的寻址模式。
ARM处理器拥有32位寄存器和32位数据处理操作。ARM架构是一种RISC(精简指令集计算机)加载/存储架构。换句话说,在对数据进行操作之前,您必须将其从内存加载到寄存器中。没有直接操作内存中的算术或逻辑指令。
早期版本的ARM架构(ARMv1到ARMv3)提供了对加载和存储无符号8位和无符号或有符号32位值的硬件支持。
//ARMv8现在支持64位寄存器了吧?
//是的,ARMv8架构引入了64位寄存器,使得ARM处理器能够处理更大范围的数据和更复杂的计算任务。ARMv8架构是一个64位的RISC架构,提供了对64位数据的原生支持,同时还能够向下兼容32位指令集。这使得ARMv8处理器在处理大规模数据和高性能计算方面表现出色。

这些架构用于在ARM7TDMI之前的处理器上。表5.1显示了按照ARM架构可用的加载/存储指令类别。
在表5.1中,对8位或16位值进行加载操作时,在写入ARM寄存器之前会将该值扩展为32位。无符号值会进行零扩展,有符号值会进行符号扩展。这意味着将加载的值强制转换为int类型不会产生额外的指令。类似地,存储8位或16位值时,会选择寄存器的最低8位或16位。将int类型强制转换为较小类型在存储过程中也不会增加额外的指令。
从ARMv4架构开始,通过新增的指令,ARMv4及以上版本的架构直接支持有符号8位和16位的加载和存储。由于这些指令是后来添加的,因此其支持的寻址模式不如早期的ARMv4指令多。(有关不同寻址模式的详细信息,请参见第3.3节。)我们将在第5.2.1节的示例checksum_v3中看到这种影响。
最后,ARMv5增加了对64位加载和存储的指令支持。这在ARM9E和后续的核心中可用。
在ARMv4之前,ARM处理器在处理有符号8位或任何16位值时效果不佳。因此,ARM C编译器将char定义为无符号8位值,而不是像许多其他编译器那样定义为有符号8位值。

编译器armcc和gcc在ARM目标上使用表5.2中的数据类型映射。值得注意的是char类型的特殊情况,当你将代码从另一种处理器架构移植时,可能会遇到问题。常见的示例是将char类型变量i用作循环计数器,并使用循环继续条件i ≥ 0。由于对于ARM编译器来说,i是无符号的,因此循环永远不会终止。幸运的是,armcc在这种情况下会产生一个警告:unsigned comparison with 0。编译器还提供了一个覆盖开关来将char定义为有符号类型。例如,gcc的命令行选项-fsigned-char将char定义为有符号类型。以下命令行选项-armcc的-zc将产生相同的效果。
在本书的其余部分,我们假设您正在使用ARMv4处理器或更高版本。这包括ARM7TDMI和所有后续处理器。
5.2.1 Local Variable Types
基于ARMv4的处理器可以高效地加载和存储8位、16位和32位数据。然而,大部分ARM数据处理操作仅支持32位。因此,应在可能的情况下使用32位数据类型int或long作为本地变量类型。即使您正在处理8位或16位值,也应避免使用char和short作为本地变量类型。唯一的例外是当您想要出现环绕效果时。如果需要形如255 + 1 = 0的模运算,则使用char类型。
为了了解本地变量类型的影响,我们可以考虑一个简单的例子。我们将详细介绍一种校验和函数,该函数对数据包中的值进行求和。大多数通信协议(如TCP/IP)都有校验和或循环冗余校验(CRC)例程,以检查数据包中的错误。
以下代码计算一个包含64个字的数据包的校验和。它展示了为什么应避免在本地变量中使用char。
int checksum_v1(int *data)
{
char i;
int sum = 0;
for (i = 0; i < 64; i++)
{
sum += data[i];
}
return sum;
}乍一看,将i声明为char类型似乎是有效的。您可能认为char类型在ARM寄存器空间或堆栈空间上使用的空间比int类型少。然而,在ARM上,这两种假设都是错误的。所有ARM寄存器都是32位,并且所有堆栈条目至少是32位。此外,为了确切实现i++操作,编译器必须考虑i等于255的情况。任何尝试递增255都应该得到答案0。
请考虑此函数的编译器输出。我们已添加标签和注释以使汇编代码更清晰。
checksum_v1
MOV r2,r0
; r2 = data
MOV r0,#0
; sum = 0
MOV r1,#0
;i=0
checksum_v1_loop
LDR r3,[r2,r1,LSL #2] ; r3 = data[i]
ADD r1,r1,#1
; r1 = i+1
AND r1,r1,#0xff ; i = (char)r1
CMP r1,#0x40
; compare i, 64
ADD r0,r3,r0
; sum += r3
BCC checksum_v1_loop ; if (i<64) loop
MOV pc,r14
; return sum现在来将这与将i声明为无符号整数(unsigned int)的编译器输出进行比较。
checksum_v2
MOV r2,r0
; r2 = data
MOV r0,#0
; sum = 0
MOV r1,#0
;i=0
checksum_v2_loop
LDR r3,[r2,r1,LSL #2] ; r3 = data[i]
ADD r1,r1,#1
; r1++
CMP r1,#0x40
; compare i, 64
ADD r0,r3,r0
; sum += r3
BCC checksum_v2_loop ; if (i<64) goto loop
MOV pc,r14
; return sum在第一种情况下,编译器会插入额外的AND指令,将i缩小到0到255的范围,然后再与64进行比较。而在第二种情况下,这个指令会消失。
接下来,假设数据包包含16位值并且我们需要一个16位的校验和。下面的C代码可能会让人心动:
short checksum_v3(short *data)
{
unsigned int i;
short sum = 0;
for (i = 0; i < 64; i++)
{
sum = (short)(sum + data[i]);
}
return sum;
}您可能想知道为什么for循环体中没有包含代码sum += data[i]。如果您使用编译器开关-W + n启用隐式窄化转换警告,这段代码在armcc中将产生一个警告。表达式sum + data[i]是一个整数,因此只能使用(隐式或显式)窄化转换将其赋值给short类型。正如您在以下的汇编输出中所看到的,编译器必须插入额外的指令来实现窄化转换:
checksum_v3
MOV r2,r0
; r2 = data
MOV r0,#0
; sum = 0
MOV r1,#0
;i=0
checksum_v3_loop
ADD r3,r2,r1,LSL #1 ; r3 = &data[i]
LDRH r3,[r3,#0] ; r3 = data[i]
ADD r1,r1,#1
; i++
CMP r1,#0x40
; compare i, 64
ADD r0,r3,r0
; r0 = sum + r3
MOV r0,r0,LSL #16
MOV r0,r0,ASR #16 ; sum = (short)r0
BCC checksum_v3_loop ; if (i<64) goto loop
MOV pc,r14
; return sum现在,这个循环比之前的checksum_v2的循环多了三个指令!这些额外指令有两个原因:
■ LDRH指令不允许使用移位地址偏移量,而之前的checksum_v2中LDR指令允许。因此,循环中的第一个ADD计算了数组中项i的地址。LDRH从没有偏移量的地址加载数据。LDRH的寻址模式比LDR少,因为它是ARM指令集的后期添加。(见5.1表)
■ 将total + array[i]转换为short类型需要两个MOV指令。编译器左移16位,然后右移16位来实现16位的符号扩展。右移是一种符号扩展移位,因此它将符号位复制到高16位以填充它们。
我们可以通过使用int类型变量来保存部分求和来避免第二个问题。我们只在函数退出时将总和缩小为short类型。
然而,第一个问题是一个新的问题。我们可以通过递增指针data来访问数组,而不是像data[i]那样使用索引来解决它。这种方式无论数组类型大小或元素大小都是高效的。所有的ARM加载和存储指令都有后增加寻址模式。
示例5.1中的checksum_v4代码修复了我们在本节中讨论的所有问题。它使用int类型的局部变量来避免不必要的转换。它递增指针data,而不是使用索引偏移data[i]。
short checksum_v4(short *data)
{
unsigned int i;
int sum=0;
for (i=0; i<64; i++)
{
sum += *(data++);
}
return (short)sum;
}*(data++)操作转换为一个ARM指令,该指令加载数据并递增数据指针。当然,您也可以编写sum += *data; data++;或者*data++,如果您喜欢的话。编译器产生以下输出。与checksum_v3相比,内部循环中删除了三个指令,每个循环节省三个周期。
checksum_v4
MOV r2,#0
; sum = 0
MOV r1,#0
;i=0
checksum_v4_loop
LDRSH r3,[r0],#2 ; r3 = *(data++)
ADD r1,r1,#1
; i++
CMP r1,#0x40
; compare i, 64
ADD r2,r3,r2
; sum += r3
BCC checksum_v4_loop ; if (sum<64) goto loop
MOV r0,r2,LSL #16
MOV r0,r0,ASR #16 ; r0 = (short)sum
MOV pc,r14
; return r0编译器仍然在函数返回时执行一次将结果转换为16位范围的操作。您可以根据5.2.2节中的讨论,通过返回一个int类型的结果来消除这个转换。
5.2.2 Function Argument Types
我们在5.2.1节中看到,将局部变量从char或short类型转换为int类型可以提高性能并减小代码大小。对于函数参数也是一样的。考虑下面这个简单的函数,它将两个16位的值相加,将第二个值除以2,然后返回一个16位的和:
short add_v1(short a, short b)
{
return a + (b >> 1);
}这个函数可能有些虚构,但它是一个有用的测试用例,可以说明编译器面临的问题。输入值a、b和返回值将被传递到32位ARM寄存器中。编译器应该假设这些32位值在short类型的范围内,即-32,768到+32,767吗?还是应该通过将最低16位进行符号扩展来填充32位寄存器,强制将值限制在这个范围内?编译器必须为函数的调用者和被调用者做出兼容的决策。调用者或被调用者必须执行到short类型的转换。
我们说函数参数是“宽”的,如果它们没有缩小到类型的范围内;如果它们已经缩小到范围内,则称其为“窄”。您可以通过查看add_v1的汇编输出来了解编译器所做的决策。如果编译器以宽的方式传递参数,那么被调用者必须将函数参数缩小到正确的范围内。如果编译器以窄的方式传递参数,那么调用者必须缩小范围。如果编译器返回宽值,则调用者必须将返回值缩小到正确的范围内。如果编译器返回窄值,则被调用者必须在返回值之前将范围缩小。
对于ADS中的armcc编译器,函数参数是窄传递的,返回值也是窄的。换句话说,调用者进行参数的转换,被调用者进行返回值的转换。编译器使用函数的ANSI原型来确定函数参数的数据类型。
add_v1的armcc输出显示,编译器将返回值转换为short类型,但没有对输入值进行转换。它假设调用者已经确保32位值r0和r1在short类型的范围内。这显示了参数和返回值的窄传递。
add_v1
ADD r0,r0,r1,ASR #1 ; r0 = (int)a + ((int)b >> 1)
MOV r0,r0,LSL #16
MOV r0,r0,ASR #16 ; r0 = (short)r0
MOV pc,r14
; return r0我们使用的gcc编译器更为谨慎,不对参数值的范围做任何假设。这个版本的编译器在调用者和被调用者中都将输入参数缩小到short类型的范围内。它还将返回值转换为short类型。以下是add_v1的编译代码示例:
add_v1_gcc
MOV r0, r0, LSL #16
MOV r1, r1, LSL #16
MOV r1, r1, ASR #17 ; r1 = (int)b >> 1
ADD r1, r1, r0, ASR #16 ; r1 += (int)a
MOV r1, r1, LSL #16
MOV r0, r1, ASR #16 ; r0 = (short)r1
MOV pc, lr
; return r0不论窄调用协议和宽调用协议有什么优劣,你可以看到char或short类型的函数参数和返回值会引入额外的转换。这会增加代码大小并降低性能。即使你只传递一个8位的值,使用int类型作为函数参数和返回值也更高效。
5.2.3 Signed versus Unsigned Types
前面的章节展示了在局部变量和函数参数中使用int类型而不是char或short类型的优点。接下来这一节将比较有符号整数和无符号整数的效率。
如果你的代码使用加、减和乘法,那么有符号和无符号操作之间没有性能差异。但是,在进行除法运算时存在差异。考虑以下简短的示例,用于计算两个整数的平均值:
int average_v1(int a, int b)
{
return (a+b)/2;
}This compiles to
average_v1
ADD r0,r0,r1 ; r0=a+b
ADD r0,r0,r0,LSR #31 ; if (r0<0) r0++
MOV r0,r0,ASR #1 ; r0 = r0 >> 1
MOV pc,r14 ; return r0请注意,如果sum是负数,编译器在右移之前会将sum加一。换句话说,它用以下语句替换了x/2的操作:
(x < 0) ? ((x + 1) >> 1) : (x >> 1)
这是因为x是有符号的。在ARM目标上的C语言中,如果x是负数,除以2并不等同于右移操作。例如,-3 >> 1 = -2,但是-3/2 = -1。除法向零取整,而算术右移则向-∞取整。
对于除法运算来说,使用无符号类型更高效。编译器会直接将无符号的2的幂次方除法转换为右移操作。对于一般的除法,C库中的除法函数对于无符号类型更快。参见第5.10节,讨论如何完全避免除法运算。
总结:高效使用C类型
• 对于存储在寄存器中的局部变量,除非需要8位或16位模运算,否则不要使用char或short类型。使用有符号或无符号int类型。在进行除法运算时,使用无符号类型更快。
• 对于存储在主存中的数组元素和全局变量,请使用尽可能小的类型来存储所需的数据。这可以节省内存空间。ARMv4架构有效地加载和存储所有数据宽度,只要您通过递增数组指针遍历数组即可。避免在short类型数组中使用从数组基地址开始的偏移量,因为LDRH指令不支持此操作。
• 在将数组元素或全局变量读入局部变量或将局部变量写入数组元素时,请使用显式转换。这样可以清楚地表明,为了快速操作,您正在将存储在内存中的窄类型扩展为寄存器中的宽类型。在编译器中开启隐式窄化转换警告以检测隐式转换。
• 避免在表达式中使用隐式或显式的窄化转换,因为它们通常会增加额外的周期。加载或存储时的强制转换通常是免费的,因为加载或存储指令会为您执行转换。
• 避免在函数参数或返回值中使用char和short类型。即使参数的范围较小,也请使用int类型。这可以防止编译器执行不必要的转换。
5.3 C Looping Structures
本节介绍在ARM上编写for循环和while循环的最高效方法。我们首先看一下具有固定迭代次数的循环,然后转向具有可变迭代次数的循环。最后我们看一下循环展开。
5.3.1 Loops with a Fixed Number of Iterations
在ARM上编写for循环最高效的方式是什么?让我们回到checksum例子,并查看循环结构。
下面是我们在第5.2节学习过的64字节数据包校验和程序的最新版本。这个例子展示了编译器如何处理一个带有递增计数i++的循环。
int checksum_v5(int *data)
{
unsigned int i;
int sum=0;
for (i=0; i<64; i++)
{
sum += *(data++);
}
return sum;
}This compiles to
checksum_v5
MOV r2,r0
; r2 = data
MOV r0,#0
; sum = 0
MOV r1,#0
;i=0
checksum_v5_loop
LDR r3,[r2],#4 ; r3 = *(data++)
ADD r1,r1,#1
; i++
CMP r1,#0x40
; compare i, 64
ADD r0,r3,r0
; sum += r3
BCC checksum_v5_loop ; if (i<64) goto loop
MOV pc,r14
; return sum在ARM上实现for循环结构通常需要三条指令:
* 使用ADD指令来增加i的值
* 使用比较指令来判断i是否小于64
* 使用条件分支指令如果i < 64,则继续执行循环
然而,这并不高效。在ARM上,循环应该只使用两条指令:
* 使用减法指令来递减循环计数器,并根据结果设置条件码标志位(condition code flags)
* 使用条件分支指令
关键是循环计数器应该按照递减到零的方式进行计数,而不是递增到任意限制值。这样,与零进行比较是免费的,因为结果存储在条件码标志位中。由于我们不再将i用作数组索引,因此按照递减计数没有问题。
下面的示例5.2展示了如果我们将循环由递增改为递减,可以获得的改进效果。
int checksum_v6(int *data)
{
unsigned int i;
int sum=0;
for (i=64; i!=0; i--)
{
sum += *(data++);
}
return sum;
}This compiles to
checksum_v6
MOV r2,r0
; r2 = data
MOV r0,#0
; sum = 0
MOV r1,#0x40
; i = 64
checksum_v6_loop
LDR r3,[r2],#4 ; r3 = *(data++)
SUBS r1,r1,#1
; i-- and set flags
ADD r0,r3,r0
; sum += r3
BNE checksum_v6_loop ; if (i!=0) goto loop
MOV pc,r14
; return sumSUBS和BNE指令实现了循环。我们的校验和示例现在每个循环只有最少的四条指令。这比校验和_v1的六条指令和校验和_v3的八条指令要好得多。
对于无符号循环计数器i,我们可以使用循环继续条件i!=0或i>0的任意一种。由于i不能为负数,它们是等价的条件。对于有符号循环计数器,人们常常倾向于使用条件i>0来继续循环。你可能会期望编译器生成以下两条指令来实现循环:
SUBS r1,r1,#1 ; compare i with 1, i=i-1
BGT loop ; if (i+1>1) goto loopIn fact, the compiler will generate
SUB r1,r1,#1 ; i--
CMP r1,#0 ; compare i with 0
BGT loop
; if (i>0) goto loop编译器并非效率低下。它必须对i = -0x80000000的情况进行特殊处理,因为在这种情况下,两段代码生成的结果是不同的。
对于第一段代码,SUBS指令将i与1进行比较,然后递减i。由于-0x80000000 < 1,循环终止。而对于第二段代码,我们先递减i,然后再与0进行比较。由于模运算的原因,i现在的值为+0x7fffffff,大于零。因此,循环会持续多次迭代。
当然,在实际应用中,i很少会取到-0x80000000这个值。编译器通常无法确定这一点,尤其是如果循环从可变次数开始(参见第5.3.2节)。
因此,对于有符号或无符号的循环计数器,你应该使用终止条件i!=0。相比于有符号i的条件i>0,它可以节省一条指令。
5.3.2 Loops Using a Variable Number of Iterations
现在假设我们希望校验和例程能够处理任意大小的数据包。我们传入一个变量N,表示数据包中的字(word)数。借鉴上一节的经验,我们会倒数计数直到N = 0,并且不需要额外的循环计数器i。
校验和_v7示例展示了编译器如何处理具有可变迭代次数N的for循环。
int checksum_v7(int *data, unsigned int N)
{
int sum=0;
for (; N!=0; N--)
{
sum += *(data++);
}
return sum;
}This compiles to
checksum_v7
MOV r2,#0
; sum = 0
CMP r1,#0
; compare N, 0
BEQ checksum_v7_end ; if (N==0) goto end
checksum_v7_loop
LDR r3,[r0],#4 ; r3 = *(data++)
SUBS r1,r1,#1
; N-- and set flags
ADD r2,r3,r2
; sum += r3
BNE checksum_v7_loop ; if (N!=0) goto loop
checksum_v7_end
MOV r0,r2
; r0 = sum
MOV pc,r14
; return r0请注意,在函数入口处,编译器检查N是否为非零值。通常情况下,这个检查是不必要的,因为你知道数组不会为空。在这种情况下,使用do-while循环比for循环具有更好的性能和代码密度。
示例5.3展示了如何使用do-while循环来消除for循环中对N为零进行测试的情况。
int checksum_v8(int *data, unsigned int N)
{
int sum=0;
do
{
sum += *(data++);
} while (--N!=0);
return sum;
}The compiler output is now
checksum_v8
MOV r2,#0
; sum = 0
checksum_v8_loop
LDR r3,[r0],#4 ; r3 = *(data++)
SUBS r1,r1,#1
; N-- and set flags
ADD r2,r3,r2
; sum += r3
BNE checksum_v8_loop ; if (N!=0) goto loop
MOV r0,r2
; r0 = sum
MOV pc,r14
; return r0请将checksum_v8与checksum_v7的输出进行比较,以了解两个循环节约了两个周期的情况。
5.3.3 Loop Unrolling
//循环展开
在5.3.1节中我们看到,每个循环迭代除了循环体本身外还需要两条指令:一个减法指令来递减循环计数器,一个条件分支指令。我们称这些指令为循环开销(loop overhead)。在ARM7或ARM9处理器上,减法指令需要一个周期,分支指令需要三个周期,因此每次循环的开销为四个周期。
通过展开循环,可以节省一些周期,即重复执行循环体多次,并相应地减少循环迭代的次数。例如,让我们将我们的数据包校验和示例展开四次。
示例5.4展示了将数据包校验和循环展开四次的代码。我们假设数据包中的字(words)数量N是四的倍数。
int checksum_v9(int *data, unsigned int N)
{
int sum=0;
do
{
sum += *(data++);
sum += *(data++);
sum += *(data++);
sum += *(data++);
N -= 4;
} while ( N!=0);
return sum;
}This compiles to
checksum_v9
MOV r2,#0 ; sum = 0
checksum_v9_loop
LDR r3,[r0],#4 ; r3 = *(data++)
SUBS r1,r1,#4
; N -= 4 & set flags
ADD r2,r3,r2
; sum += r3
LDR r3,[r0],#4 ; r3 = *(data++)
ADD r2,r3,r2
; sum += r3
LDR r3,[r0],#4 ; r3 = *(data++)
ADD r2,r3,r2
; sum += r3
LDR r3,[r0],#4 ; r3 = *(data++)
ADD r2,r3,r2
; sum += r3
BNE checksum_v9_loop ; if (N!=0) goto loop
MOV r0,r2
; r0 = sum
MOV pc,r14
; return r0我们将循环的开销从4N个周期减少到(4N)/4=N个周期。在ARM7TDMI上,这将使循环每次累加的周期数从8个减少到20/4=5个,几乎使速度翻倍!对于具有更快加载指令的ARM9TDMI来说,效果甚至更好。
//这个当前编译器是不是已经优化了?
在展开循环时,你需要回答两个问题:
1. 我应该展开循环多少次?
2. 如果循环迭代的次数不是展开数量的倍数会怎样?例如,在checksum_v9中,如果N不是4的倍数会怎么办?
对于第一个问题,只有关乎应用程序整体性能的循环才值得展开。否则,展开只会增加代码大小而带来很少的性能提升。展开甚至可能通过将更重要的代码从缓存中驱逐出去而降低性能。
假设循环很重要,例如占整个应用程序的30%。假设你将循环展开直到达到0.5 KB的代码大小(128条指令)。那么,与大约128个周期的循环体相比,循环的开销最多为4个周期。循环开销成本为3/128,大约为3%。回想一下,假如循环占整个应用程序的30%,因此整体上循环开销只有1%。进一步展开代码几乎没有额外的性能收益,但对缓存内容有显著影响。当增益小于1%时,通常不值得继续展开。
对于第二个问题,请尽量安排数组大小是展开数量的倍数。如果不可能,那么你必须添加额外的代码来处理剩余的情况。这会稍微增加代码大小,但保持性能高效。
示例5.5
这个示例使用展开了四次的循环来处理任意大小的数据包的校验和。
int checksum_v10(int *data, unsigned int N)
{
unsigned int i;
int sum=0;
for (i=N/4; i!=0; i--)
{
sum += *(data++);
sum += *(data++);
sum += *(data++);
sum += *(data++);
}
for (i=N&3; i!=0; i--)
{
sum += *(data++);
}
return sum;
}第二个for循环处理当N不是4的倍数时的剩余情况。注意,N/4和N&3都可能为零,所以我们不能使用do-while循环。
有效地编写循环总结如下:
- 使用向零计数的循环。这样编译器就不需要分配一个寄存器来存储终止值,并且与零比较是免费的。
- 默认使用无符号的循环计数器和继续条件i!=0,而不是i>0。这将确保循环开销只有两个指令。
- 当你知道循环至少会执行一次时,使用do-while循环而不是for循环。这样可以避免编译器检查循环计数是否为零。
- 为了减少循环开销,展开重要的循环。但不要过度展开。如果循环开销在总体上占比很小,那么展开会增加代码大小,并对缓存性能造成影响。
- 尽量安排数组中的元素数量是四或八的倍数。这样,你可以轻松地将循环展开两倍、四倍或八倍,而不用担心剩余的数组元素问题。
5.4 Register Allocation
编译器会尝试为C函数中使用的每个局部变量分配一个处理器寄存器。如果变量的使用不重叠,编译器将尝试为不同的局部变量使用相同的寄存器。当局部变量的数量超过可用寄存器时,编译器将多余的变量存储在处理器栈上。这些变量被称为溢出变量或交换出的变量,因为它们被写入内存(类似于虚拟内存被交换到磁盘上)。与分配给寄存器的变量相比,访问溢出变量的速度较慢。
为了高效实现函数,你需要:
- 最小化溢出变量的数量
- 确保最重要和频繁访问的变量存储在寄存器中
首先,让我们看一下ARM C编译器在分配变量时可用的处理器寄存器数量。表5.3显示了按照ARM-Thumb过程调用标准(ATPCS)进行编码时的标准寄存器名称和用法。
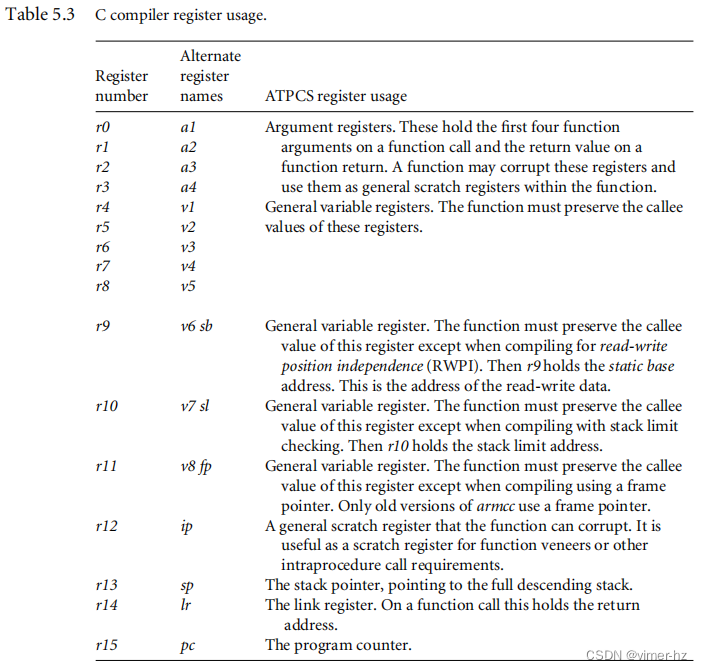
C compiler register usage:
a1~a4: 参数寄存器。这些寄存器在函数调用时保存前四个函数参数,在函数返回时保存返回值。函数可能会破坏这些寄存器,并在函数内部将它们用作通用的临时寄存器。
v1~v5: 通用变量寄存器。函数必须保留这些寄存器的被调用者值。
v6 sb: 通用变量寄存器。函数必须保留该寄存器的被调用者值,除非编译时为读写位置无关性(RWPI)。然后r9保存静态基址。这是读写数据的地址。
v7 sl: 通用变量寄存器。函数必须保留该寄存器的被调用者值,除非在进行栈限制检查编译时。此时,r10保存栈限制地址。
v8 fp: 通用变量寄存器。函数必须保留该寄存器的被调用者值,除非使用帧指针进行编译。只有旧版本的armcc使用帧指针。
ip: 一个通用的临时寄存器,函数可以覆盖其中的值。它对于函数过程中的需求或其他函数调用要求作为临时寄存器来使用是很有用的。
sp: 栈指针,指向完整的降序堆栈。
lr: 链接寄存器。在函数调用中,它保存返回地址。
pc: 程序计数器。
假设编译器没有使用软件栈检查或帧指针,ARM C编译器可以使用r0到r12和r14寄存器来保存变量。如果使用这些寄存器,它必须在栈上保存r4到r11和r14的调用者值。
理论上,C编译器可以分配14个变量到寄存器而不产生溢出。但实际上,一些编译器会将某些寄存器(如r12)固定为中间临时工作寄存器,并不将变量分配给该寄存器。此外,复杂的表达式需要中间工作寄存器进行求值。因此,为了确保良好的寄存器分配,应尽量限制函数内部循环使用的局部变量数量不超过12个。
如果编译器确实需要交换变量,则它会根据使用频率选择要交换的变量。在循环内使用的变量会被计算多次。通过在最内层循环中使用这些变量,你可以告诉编译器哪些变量很重要。
在C中,register关键字提示编译器应该将给定的变量分配给一个寄存器。然而,不同的编译器对待这个关键字的方式不同,不同的体系结构有不同数量的可用寄存器(例如Thumb和ARM)。因此,建议避免使用register,并依赖于编译器的正常寄存器分配例程。
总结高效的寄存器分配方法:
- 尽量限制函数内部循环中的局部变量数量不超过12个。编译器应该能够将这些变量分配给ARM寄存器。
- 通过在最内层循环中使用这些变量,可以告诉编译器哪些变量很重要。
5.5 Function Calls
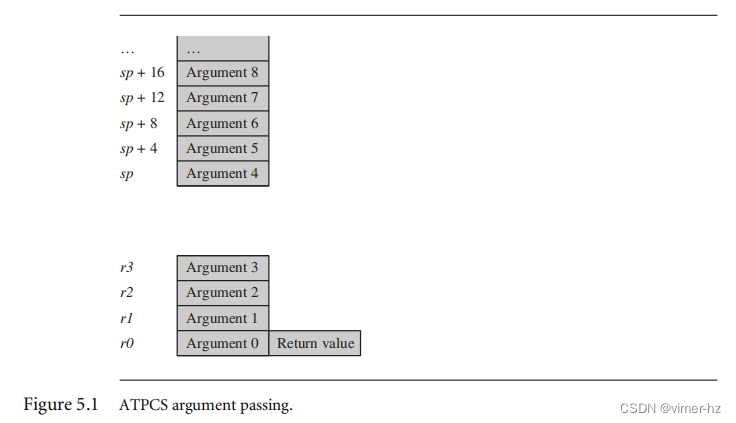
ARM过程调用标准(APCS)定义了在ARM寄存器中如何传递函数参数和返回值。更近期的ARM-Thumb过程调用标准(ATPCS)覆盖了ARM和Thumb之间的交互工作。前四个整数参数通过前四个ARM寄存器(r0、r1、r2和r3)传递。后续的整数参数按照图5.1中所示的方式,从上到下依次放置在降序堆栈中。函数返回的整数值存放在r0中。此描述仅涵盖整数或指针参数。例如long long或double等双字参数会以一对连续的参数寄存器传递,并在r0、r1中返回。编译器可以根据命令行编译选项将结构体参数传递给寄存器或通过引用传递。关于过程调用标准的首要注意事项是四个寄存器规则。调用具有四个或更少参数的函数比调用具有五个或更多参数的函数更高效。对于具有四个或更少参数的函数,编译器可以将所有参数传递到寄存器中。对于具有更多参数的函数,调用方和被调用方都必须对某些参数访问堆栈。请注意,对于C++而言,对象方法的第一个参数是this指针。此参数是隐含的,与显式参数不同。如果您的C函数需要超过四个参数,或者C++方法需要超过三个显式参数,那么使用结构体几乎总是更高效的方法。将相关参数组合成结构体,并传递结构体指针而不是多个参数。哪些参数是相关的将取决于您软件的结构。
下面的示例说明了使用结构体指针的好处。首先,我们展示了一个典型的例程,将来自数组数据的N个字节插入队列中。我们使用循环缓冲区实现队列,起始地址为Q_start(包含),结束地址为Q_end(不包含)。
char *queue_bytes_v1(
char *Q_start, /* Queue buffer start address */
char *Q_end,
/* Queue buffer end address */
char *Q_ptr,
/* Current queue pointer position */
char *data,
/* Data to insert into the queue */
unsigned int N) /* Number of bytes to insert */
{
do
{
*(Q_ptr++) = *(data++);
if (Q_ptr == Q_end)
{
Q_ptr = Q_start;
}
} while (--N);
return Q_ptr;
}This compiles to
queue_bytes_v1
STR r14,[r13,#-4]! ; save lr on the stack
LDR r12,[r13,#4] ; r12 = N
queue_v1_loop
LDRB r14,[r3],#1 ; r14 = *(data++)
STRB r14,[r2],#1 ; *(Q_ptr++) = r14
CMP r2,r1
; if (Q_ptr == Q_end)
MOVEQ r2,r0
; {Q_ptr = Q_start;}
SUBS r12,r12,#1 ; --N and set flags
BNE queue_v1_loop ; if (N!=0) goto loop
MOV r0,r2
; r0 = Q_ptr
LDR pc,[r13],#4 ; return r0与使用三个函数参数的更结构化方法进行比较。示例5.6中的以下代码创建了一个Queue结构,并将其传递给函数,以减少函数参数的数量。
typedef struct {
char *Q_start; /* Queue buffer start address */
char *Q_end;
/* Queue buffer end address */
char *Q_ptr;
/* Current queue pointer position */
} Queue;
void queue_bytes_v2(Queue *queue, char *data, unsigned int N)
{
char *Q_ptr = queue->Q_ptr;
char *Q_end = queue->Q_end;
do
{
*(Q_ptr++) = *(data++);
if (Q_ptr == Q_end)
{
Q_ptr = queue->Q_start;
}
} while (--N);
queue->Q_ptr = Q_ptr;
}This compiles to
queue_bytes_v2
STR r14,[r13,#-4]! ; save lr on the stack
LDR r3,[r0,#8] ; r3 = queue->Q_ptr
LDR r14,[r0,#4] ; r14 = queue->Q_end
queue_v2_loop
LDRB r12,[r1],#1 ; r12 = *(data++)
STRB r12,[r3],#1 ; *(Q_ptr++) = r12
CMP r3,r14
; if (Q_ptr == Q_end)
LDREQ r3,[r0,#0] ; Q_ptr = queue->Q_start
SUBS r2,r2,#1 ; --N and set flags
BNE queue_v2_loop ; if (N!=0) goto loop
STR r3,[r0,#8] ; queue->Q_ptr = r3
LDR pc,[r13],#4 ; returnqueue_bytes_v2比queue_bytes_v1多了一条指令,但实际上总体上更高效。第二个版本只有三个函数参数,而不是五个。每次调用函数只需要三个寄存器的设置。与第一个版本相比,第一个版本需要四个寄存器的设置、一个栈的压入和一个栈的弹出。函数调用开销净节省了两条指令。在被调用函数中也可能有进一步的节省,因为它只需要将一个寄存器分配给Queue结构体指针,而不是非结构化情况下的三个寄存器。
如果您的函数非常小且破坏的寄存器很少(使用的本地变量很少),还有其他减少函数调用开销的方法。将C函数放在与调用它的函数相同的C文件中。这样,C编译器就知道对被调用函数生成的代码,并且可以在调用者函数中进行优化:
- 调用者函数不需要保留它可以看到被调用函数不会破坏的寄存器。因此,调用者函数不需要保存所有可能被ATPCS破坏的寄存器。
- 如果被调用函数非常小,编译器可以将代码内联到调用者函数中。这完全消除了函数调用的开销。
示例5.7中的函数uint_to_hex将一个32位无符号整数转换为一个包含八个十六进制数的数组。它使用一个辅助函数nybble_to_hex,该函数将范围在0到15之间的数字d转换为一个十六进制数。
unsigned int nybble_to_hex(unsigned int d)
{
if (d<10)
{
return d + ’0’;
}
return d - 10 + ’A’;
}
void uint_to_hex(char *out, unsigned int in)
{
unsigned int i;
for (i=8; i!=0; i--)
{
in = (in << 4) | (in >> 28); /* rotate in left by 4 bits */
*(out++) = (char)nybble_to_hex(in & 15);
}
}当我们编译这段代码时,我们可以看到uint_to_hex根本没有调用nybble_to_hex!在下面的编译代码中,编译器已经将uint_to_hex代码内联展开了。这比生成函数调用更高效。
uint_to_hex
MOV r3,#8
;i=8
uint_to_hex_loop
MOV r1,r1,ROR #28 ; in = (in << 4)|(in >> 28)
AND r2,r1,#0xf ; r2 = in & 15
CMP r2,#0xa
; if (r2>=10)
ADDCS r2,r2,#0x37 ; r2 +=’A’-10
ADDCC r2,r2,#0x30 ; else r2 +=’0’
STRB r2,[r0],#1 ; *(out++) = r2
SUBS r3,r3,#1
; i-- and set flags
BNE uint_to_hex_loop ; if (i!=0) goto loop
MOV pc,r14
; return编译器只会内联展开小函数。您可以使用__inline关键字让编译器内联展开函数,尽管这个关键字只是一个暗示,编译器也可能会忽略它(有关内联函数的更多信息,请参见第5.12节)。内联展开大函数可能会导致代码大小大幅增加,而性能改善不明显。
总结:
- 尽量将函数限制在四个参数内。这样可以使它们更高效地调用。使用结构体来组织相关的参数,而不是传递多个参数。
- 在调用它们的函数之前,将小函数定义在同一个源文件中。然后编译器可以优化函数调用或者内联展开小函数。
- 可以使用__inline关键字内联展开关键函数。
5.6 Pointer Aliasing
//指针别名
当两个指针指向相同的内存地址时,它们被称为别名。如果您通过一个指针对其进行写操作,将会影响通过另一个指针读取的值。在函数中,编译器通常无法确定哪些指针可以别名,哪些不能。编译器必须非常保守,并假设对一个指针的任何写操作都可能影响到从任何其他指针读取的值。这可能会显著降低代码的效率。
让我们从一个非常简单的例子开始。下面的函数按照给定的步长递增两个计时器的值:
void timers_v1(int *timer1, int *timer2, int *step)
{
*timer1 += *step;
*timer2 += *step;
}This compiles to
timers_v1
LDR r3,[r0,#0] ; r3 = *timer1
LDR r12,[r2,#0] ; r12 = *step
ADD r3,r3,r12 ; r3 += r12
STR r3,[r0,#0] ; *timer1 = r3
LDR r0,[r1,#0] ; r0 = *timer2
LDR r2,[r2,#0] ; r2 = *step
ADD r0,r0,r2
; r0 += r2
STR r0,[r1,#0] ; *timer2 = t0
MOV pc,r14
; return请注意,编译器两次加载了step。通常情况下,一个称为共同子表达式消除的编译器优化会生效,这样*step只会被计算一次,并且第二次出现时会重用该值。然而,在这里编译器无法使用这种优化。指针timer1和step可能会别名。换句话说,编译器无法确定对timer1的写操作不会影响到对step的读取。在这种情况下,*step的第二个值与第一个值不同,并且具有*timer1的值。这会迫使编译器插入额外的加载指令。
如果您使用结构体访问而不是直接指针访问,同样的问题也会发生。以下代码也会编译得低效:
typedef struct {int step;} State;
typedef struct {int timer1, timer2;} Timers;
void timers_v2(State *state, Timers *timers)
{
timers->timer1 += state->step;
timers->timer2 += state->step;
}当state->step和timers->timer1位于相同的内存地址时,编译器会对state->step进行两次评估。修复方法很简单:创建一个新的局部变量来保存state->step的值,这样编译器只需执行一次加载。
示例5.8:
在timers_v3的代码中,我们使用一个名为step的局部变量来保存state->step的值。现在编译器不需要担心state可能与timers别名的问题了。
void timers_v3(State *state, Timers *timers)
{
int step = state->step;
timers->timer1 += step;
timers->timer2 += step;
}还要注意其他一些不太明显的情况,可能会发生别名问题。当调用另一个函数时,该函数可能会改变内存状态,从而改变任何涉及内存读取的表达式的值。编译器将重新评估表达式。例如,假设您读取state->step,调用一个函数,然后再次读取state->step。编译器必须假定函数可能会更改内存中state->step的值。因此,它将执行两次读取,而不是重复使用它读取state->step的第一个值。
另一个陷阱是取本地变量的地址。一旦这样做,该变量就会被指针引用,因此可以与其他指针发生别名问题。编译器可能会保持从堆栈中读取变量,以防别名出现。考虑以下示例,它读取并计算数据包的校验和:
int checksum_next_packet(void)
{
int *data;
int N, sum=0;
data = get_next_packet(&N);
do
{
sum += *(data++);
} while (--N);
return sum;
}这里get_next_packet是一个函数,返回下一个数据包的地址和大小。前面的代码编译为:
checksum_next_packet
STMFD r13!,{r4,r14} ; save r4, lr on the stack
SUB r13,r13,#8
; create two stacked variables
ADD r0,r13,#4
; r0 = &N, N stacked
MOV r4,#0
; sum = 0
BL get_next_packet ; r0 = data
checksum_loop
LDR r1,[r0],#4
; r1 = *(data++)
ADD r4,r1,r4
; sum += r1
LDR r1,[r13,#4] ; r1 = N (read from stack)
SUBS r1,r1,#1
; r1-- & set flags
STR r1,[r13,#4]
; N = r1 (write to stack)
BNE checksum_loop ; if (N!=0) goto loop
MOV r0,r4
; r0 = sum
ADD r13,r13,#8
; delete stacked variables
LDMFD r13!,{r4,pc} ; return r0请注意,编译器在每次N--时从堆栈中读取并写入N的值。一旦您取出N的地址并将其传递给get_next_packet,编译器就需要担心别名问题,因为指针data和&N可能会发生别名问题。为了避免这种情况,不要取本地变量的地址。如果必须这样做,则在使用之前将值复制到另一个本地变量中。
也许您想知道为什么编译器为两个堆栈变量预留空间,而实际上只使用了一个。这是为了保持堆栈按8字节对齐,这是ARMv5TE中可用的LDRD指令所需的。上面的示例实际上并没有使用LDRD指令,但编译器不知道get_next_packet是否会使用该指令。
避免指针别名问题的总结:
- 不要依赖编译器消除涉及内存访问的公共子表达式。相反,创建新的本地变量来保存表达式。这样可以确保表达式只被评估一次。
- 避免获取本地变量的地址。之后从该地址访问该变量可能会导致效率低下。
5.7 Structure Arrangement
您布置经常使用的结构体的方式可能对其性能和代码密度产生重大影响。在ARM上有两个与结构体相关的问题:结构体条目的对齐和结构体的整体大小。
对于包括ARMv5TE在内的架构,加载和存储指令只能保证加载和存储与访问宽度对齐的地址处的值。表5.4总结了这些限制。
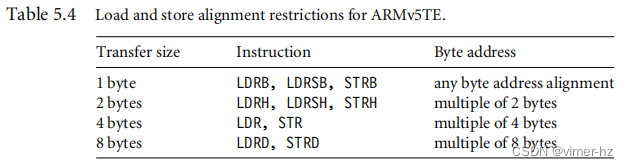
基于这个原因,ARM编译器会自动将结构的起始地址对齐为结构中使用的最大访问宽度(通常为四个或八个字节)的倍数,并通过插入填充来对齐结构中的条目到其访问宽度。
例如,考虑以下结构:
struct {
char a;
int b;
char c;
short d;
}对于小端内存系统,编译器会布置结构并添加填充,以确保下一个对象对齐到该对象的大小:
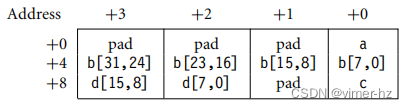
为了改善内存使用情况,您应该重新排列元素。
struct {
char a;
char c;
short d;
int b;
}这将结构的大小从12字节减小到8字节,具有以下新的布局:
因此,将结构元素按照相同的大小进行分组是一个好主意,这样结构布局就不会包含不必要的填充。armcc编译器确实包含了一个名为`__packed`的关键字,可以移除所有的填充。例如,下面的结构:
__packed struct {
char a;
int b;
char c;
short d;
}will be laid out in memory as

然而,紧凑的结构在访问时会变得较慢且效率低下。编译器通过使用多个对齐的访问和数据操作来模拟非对齐的加载和存储操作,并将结果合并。只有在空间远比速度重要且无法通过重新排列来减少填充时,才使用`__packed`关键字。同时,在移植代码时,如果代码假设特定的结构布局存在于内存中,则也可以使用该关键字。
结构在内存中的确切布局可能取决于您使用的编译器供应商和编译器版本。在API(应用程序编程接口)定义中,插入任何无法消除的填充到结构中通常是一个好主意。这样可以避免结构布局的歧义。如果坚持使用明确的结构,更容易在不同的编译器版本和供应商之间链接代码。
另一个不确定性点是enum枚举类型。不同的编译器根据枚举的范围使用不同大小的枚举类型。例如,考虑以下类型:
typedef enum {
FALSE,
TRUE
} Bool;在ADS1.1中,armcc编译器将Bool类型作为一个字节类型处理,因为它只使用值0和1。在结构中,Bool类型只占用8位空间。然而,在gcc中,Bool类型将被视为一个字,并在结构中占用32位空间。为避免歧义,在API中尽量避免在结构中使用枚举类型。
另一个考虑因素是结构的大小和结构内元素的偏移量。当使用Thumb指令集进行编译时,这个问题最为严重。Thumb指令只有16位宽度,因此只允许从结构基地址偏移较小的元素。表5.5显示了在Thumb中可用的加载和存储基寄存器的偏移量。

因此,如果8位元素出现在结构的前32字节内,编译器只能使用单条指令访问这个8位元素。类似地,只有在前64字节内才能使用单条指令访问16位值,并且只有在前128字节内才能使用单条指令访问32位值。一旦超过这些限制,结构访问效率就会降低。
为了实现最大效率的紧凑结构,可以遵循以下规则:
- 将所有的8位元素放在结构的开头。
- 接下来放置所有的16位元素,然后是32位和64位元素。
- 将所有的数组和较大的元素放在结构的末尾。
- 如果结构过大,无法使用单条指令访问所有元素,则将元素分组到子结构中。编译器可以维护对各个子结构的指针。
总结 高效的结构排列方法如下:
- 按照元素大小递增的顺序布置结构。从最小的元素开始,以最大的元素结束。
- 避免使用非常大的结构。而是使用一系列较小的结构层次。
- 为了可移植性,在API结构中手动添加填充(隐含地出现) ,以使结构的布局不依赖于编译器。
- 注意在API结构中使用枚举类型。枚举类型的大小取决于编译器。
5.8 Bit-fields
位字段可能是ANSI C规范中最不标准化的部分。编译器可以选择如何在位字段容器内分配位。单单因为这个原因,避免在联合体或API结构定义中使用位字段。不同的编译器可以将相同的位字段分配给容器中的不同位位置。
出于效率考虑,避免使用位字段也是一个好主意。位字段是结构元素,通常使用结构指针进行访问;因此,它们受到第5.6节中描述的指针别名问题的影响。每次位字段访问实际上都是一次内存访问。可能的指针别名经常迫使编译器多次重新加载位字段。
下面的例子 dostages_v1 就说明了这个问题。它还显示了编译器在位字段测试方面不倾向于进行优化。
void dostageA(void);
void dostageB(void);
void dostageC(void);
typedef struct {
unsigned int stageA : 1;
unsigned int stageB : 1;
unsigned int stageC : 1;
} Stages_v1;
void dostages_v1(Stages_v1 *stages)
{
if (stages->stageA)
{
dostageA();
}
if (stages->stageB)
{
dostageB();
}
if (stages->stageC)
{
dostageC();
}
}在这里,我们使用三个位字段标志来启用三个可能的处理阶段。这个示例编译为:
dostages_v1
STMFD r13!,{r4,r14} ; stack r4, lr
MOV r4,r0
; move stages to r4
LDR r0,[r0,#0] ; r0 = stages bitfield
TST r0,#1
; if (stages->stageA)
BLNE dostageA
; {dostageA();}
LDR r0,[r4,#0] ; r0 = stages bitfield
MOV r0,r0,LSL #30 ; shift bit 1 to bit 31
CMP r0,#0
; if (bit31)
BLLT dostageB
; {dostageB();}
LDR r0,[r4,#0] ; r0 = stages bitfield
MOV r0,r0,LSL #29 ; shift bit 2 to bit 31
CMP r0,#0
; if (!bit31)
LDMLTFD r13!,{r4,r14} ; return
BLT dostageC
; dostageC();
LDMFD r13!,{r4,pc} ; return请注意,编译器三次访问包含位字段的内存位置。由于位字段存储在内存中,dostage函数可以更改其值。此外,编译器使用两个指令来测试位字段的位1和位2,而不是单个指令。
通过使用整数而不是位字段,您可以生成更高效的代码。使用枚举或#define掩码将整数类型划分为不同的字段。
以下代码实现了使用逻辑操作而不是位字段的dostages函数的示例:
typedef unsigned long Stages_v2;
#define STAGEA (1ul << 0)
#define STAGEB (1ul << 1)
#define STAGEC (1ul << 2)
void dostages_v2(Stages_v2 *stages_v2)
{
Stages_v2 stages = *stages_v2;
if (stages & STAGEA)
{
dostageA();
}
if (stages & STAGEB)
{
dostageB();
}
if (stages & STAGEC)
{
dostageC();
}
}现在,一个单独的unsigned long类型包含了所有的位字段,我们可以将它们的值保存在一个单独的局部变量stages中,这样就消除了第5.6节中讨论的内存别名问题。换句话说,编译器必须假设dostageX(其中X是A、B或C)函数可能会改变*stages_v2的值。
编译器生成以下代码,相比使用ANSI位字段的先前版本,节省了33%的空间:
dostages_v2
STMFD r13!,{r4,r14} ; stack r4, lr
LDR r4,[r0,#0] ; stages = *stages_v2
TST r4,#1
; if (stage & STAGEA)
BLNE dostageA ; {dostageA();}
TST r4,#2
; if (stage & STAGEB)
BLNE dostageB ; {dostageB();}
TST r4,#4
; if (!(stage & STAGEC))
LDMNEFD r13!,{r4,r14} ; return;
BNE dostageC ; dostageC();
LDMFD r13!,{r4,pc} ; return您还可以使用掩码来设置、清除或切换位字段,就像对它们进行测试一样简单。以下代码展示了如何使用STAGE掩码来设置、清除或切换位的示例:
stages |= STAGEA;
/* enable stage A */
stages &= ∼STAGEB; /* disable stage B */
stages ∧= STAGEC;
/* toggle stage C */这些位设置、清除和切换操作每个只需要一条ARM指令,分别使用ORR、BIC和EOR指令。另一个优点是现在您可以使用一条指令同时操作多个位字段。例如:
stages |= (STAGEA | STAGEB);
/* enable stages A and B */
stages &= ∼(STAGEA | STAGEC); /* disable stages A and C */总结位字段的使用方法:
- 避免使用位字段,而是使用#define或enum来定义掩码值。
- 使用整数逻辑的与、或、异或操作和掩码值来测试、切换和设置位字段。这些操作在编译时效率高,并且可以同时测试、切换或设置多个字段。
5.9 Unaligned Data and Endianness
未对齐的数据和字节序是可能使内存访问和可移植性复杂化的两个问题。数组指针是否对齐?ARM配置为大端或小端内存系统?
ARM的加载和存储指令假设地址是要加载或存储的类型的倍数。如果加载或存储到的地址与其类型不对齐,则行为取决于特定的实现。核心可能会生成数据中止或加载旋转值。对于良好编写的可移植代码,应避免非对齐访问。
C编译器默认假设指针是对齐的,除非另有说明。如果指针未对齐,程序可能会产生意外结果。当将代码从允许非对齐访问的处理器移植到ARM时,这有时是一个问题。对于armcc编译器,__packed指令告诉编译器数据项可以位于任何字节对齐位置。这对于移植代码很有用,但使用__packed会影响性能。
为了说明这一点,我们看下面这个简单的例程readint。它返回data指针所指向的地址处的整数。我们使用__packed告诉编译器整数可能未对齐。
int readint(__packed int *data)
{
return *data;
}This compiles to
readint
BIC r3,r0,#3
; r3 = data & 0xFFFFFFFC
AND r0,r0,#3
; r0 = data & 0x00000003
MOV r0,r0,LSL #3 ; r0 = bit offset of data word
LDMIA r3,{r3,r12} ; r3, r12 = 8 bytes read from r3
MOV r3,r3,LSR r0 ; These three instructions
RSB r0,r0,#0x20 ; shift the 64 bit value r12.r3
ORR r0,r3,r12,LSL r0 ; right by r0 bits
MOV pc,r14
; return r0注意到这段代码非常庞大和复杂。编译器使用两次对齐访问和数据处理操作来模拟非对齐访问,这非常耗时,这也说明了为什么应该避免使用_packed。相反,可以使用char *类型的指针来指向可能以任何对齐方式出现的数据。稍后我们将介绍从char *中更高效地读取32位字的方法。
当读取用于在计算机之间传输信息的数据包或文件时,很可能会遇到对齐问题。网络数据包和压缩图像文件是很好的例子。这些文件中的两个或四个字节的整数可能出现在任意偏移量处。为了尽可能地压缩数据,牺牲了对齐。
字节序(或字节顺序)在读取数据包或压缩文件时也是一个重要问题。ARM核心可以配置为使用小端序(最低地址存放最不重要的字节)或大端序(最低地址存放最重要的字节)。小端序通常是默认设置。
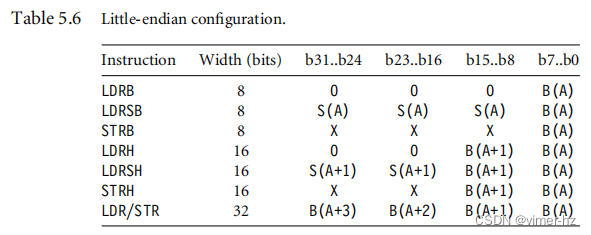
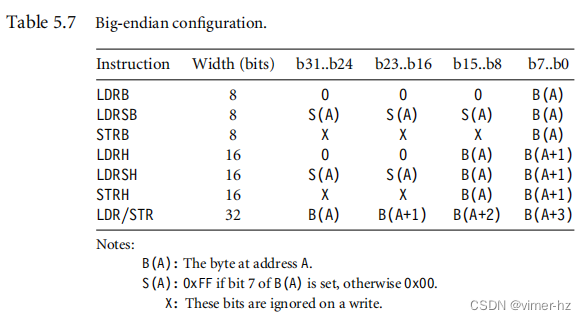
ARM的字节序通常在上电时设置,并且在之后保持固定。表5.6和5.7说明了ARM的8位、16位和32位加载和存储指令在不同的字节序配置下的工作方式。我们假设字节地址A对齐到内存传输的大小。表格显示了指令加载或存储的字节地址如何映射到内存中的32位寄存器。
如果速度不是关键,处理字节序和对齐问题的最佳方式是使用像Example 5.10中的readint_little和readint_big这样的函数,它们从可能未对齐的内存地址中读取一个四字节整数。地址对齐只在运行时才能确定,而不是在编译时就已知。如果你加载的文件包含大端序数据,比如JPEG图像,那么使用readint_big函数。对于包含小端序数据的字节流,使用readint_little函数。无论ARM配置的内存字节序如何,这两个函数都能正确工作。
Example 5.10中的这些函数从data指向的字节流中读取一个32位整数。这些字节流分别包含小端序或大端序数据。这些函数独立于ARM内存系统的字节序,因为它们仅使用字节访问。
int readint_little(char *data)
{
int a0,a1,a2,a3;
a0 = *(data++);
a1 = *(data++);
a2 = *(data++);
a3 = *(data++);
return a0 | (a1 << 8) | (a2 << 16) | (a3 << 24);
}
int readint_big(char *data)
{
int a0,a1,a2,a3;
a0 = *(data++);
a1 = *(data++);
a2 = *(data++);
a3 = *(data++);
return (((((a0 << 8) | a1) << 8) | a2) << 8) | a3;
}如果速度至关重要,最快的方法是编写关键例程的多个变体。对于每种可能的对齐和ARM字节序配置,调用一个针对该情况进行优化的单独例程。
Example 5.11中的read_samples例程接受一个包含N个16位音频样本的数组,位于地址in处。音频样本是小端序(例如来自.wav文件),可以在任意字节对齐位置上。该例程将样本复制到由out指向的对齐的short类型值数组中。样本将按照配置的ARM内存字节序存储。该例程以高效的方式处理所有情况,无论输入对齐方式如何,以及ARM字节序配置如何。
void read_samples(short *out, char *in, unsigned int N)
{
unsigned short *data; /* aligned input pointer */
unsigned int sample, next;
switch ((unsigned int)in & 1)
{
case 0: /* the input pointer is aligned */
data = (unsigned short *)in;
do
{
sample = *(data++);
#ifdef __BIG_ENDIAN
sample = (sample >> 8) | (sample << 8);
#endif
*(out++) = (short)sample;
} while (--N);
break;
case 1: /* the input pointer is not aligned */
data = (unsigned short *)(in-1);
sample = *(data++);
#ifdef __BIG_ENDIAN
sample = sample & 0xFF; /* get first byte of sample */
#else
sample = sample >> 8; /* get first byte of sample */
#endif
do
{
next = *(data++);
/* complete one sample and start the next */
#ifdef __BIG_ENDIAN
*out++ = (short)((next & 0xFF00) | sample);
sample = next & 0xFF;
#else
*out++ = (short)((next << 8) | sample);
sample = next >> 8;
#endif
} while (--N);
break;
}
}该例程通过为每个字节序和对齐方式编写不同的代码来工作。字节序使用编译时的__BIG_ENDIAN编译器标志处理。对齐必须在运行时使用switch语句进行处理。
你可以通过使用32位读写而不是16位读写使例程更加高效,这样可以在switch语句中有四个元素,分别对应可能的地址对齐模4的情况。
总结:字节序和对齐方式
- 尽量避免使用未对齐的数据。
- 对于可以处于任意字节对齐位置的数据,使用char*类型。通过读取字节并与逻辑操作相结合来访问数据。这样代码就不会依赖于对齐或ARM字节序的配置。
- 对于快速访问未对齐的结构,根据指针对齐和处理器字节序编写不同的变体。
5.10 Division
ARM处理器在硬件中没有除法指令。相反,编译器通过调用C库中的软件例程来实现除法运算。你可以根据特定的分子和分母值范围来定制许多不同类型的除法例程。我们将在第7章中详细讨论汇编除法例程。C库中提供的标准整数除法例程的执行时间根据实现、早期终止和输入操作数的范围而有所不同,通常需要20到100个周期。
除法和取模(/和%)是非常慢的操作,应尽量避免使用它们。然而,对于常数除法和反复除以相同分母的情况,可以高效地进行处理。本节将介绍如何通过乘法替代某些除法,并尽量减少除法调用的次数。
循环缓冲区是程序员经常使用除法的一个领域,但完全可以避免使用这些除法。假设你有一个大小为buffer_size字节的循环缓冲区,并且有一个由缓冲区偏移指示的位置。要通过increment字节来推进偏移量,你可以写成:
offset = (offset + increment) % buffer_size;
但实际上,更高效的写法是:
offset += increment;
if (offset>=buffer_size)
{
offset -= buffer_size;
}第一个版本可能需要50个周期;而第二个版本将只需3个周期,因为它不涉及除法运算。我们假设increment < buffer_size;在实际应用中你总是可以满足这个条件。
如果无法避免使用除法,那么尽量确保分子和分母是无符号整数。有符号除法例程速度较慢,因为它们会取分子和分母的绝对值,然后调用无符号除法例程。之后再修复结果的符号。
许多C库的除法例程返回除法的商和余数。换句话说,每次除法操作都可以获得免费的余数操作,反之亦然。例如,要找到位于屏幕缓冲区偏移offset字节处的位置(x, y),很容易写成:
typedef struct {
int x;
int y;
} point;
point getxy_v1(unsigned int offset, unsigned int bytes_per_line)
{
point p;
p.y = offset / bytes_per_line;
p.x = offset - p.y * bytes_per_line;
return p;
}看起来我们通过使用减法和乘法来计算p.x,避免了一次除法操作,但实际上,使用模运算或余数运算符往往更高效。
示例5.12:
在getxy_v2中,商和余数的操作只需要调用一次除法例程:
point getxy_v2(unsigned int offset, unsigned int bytes_per_line)
{
point p;
p.x = offset % bytes_per_line;
p.y = offset / bytes_per_line;
return p;
}在这里只有一次除法调用,正如您可以在下面的编译器输出中看到的那样。实际上,这个版本比getxy_v1短了四条指令。请注意,对于所有的编译器和C库来说,情况可能并非总是如此。
getxy_v2
STMFD r13!,{r4, r14} ; stack r4, lr
MOV r4,r0
; move p to r4
MOV r0,r2
; r0 = bytes_per_line
BL __rt_udiv ; (r0,r1) = (r1/r0, r1%r0)
STR r0,[r4,#4] ; p.y = offset / bytes_per_line
STR r1,[r4,#0] ; p.x = offset % bytes_per_line
LDMFD r13!,{r4,pc} ; return5.10.1 Repeated Unsigned Division with Remainder
//重复的无符号除法和余数运算
在代码中经常会出现相同的分母多次重复的情况。在前面的例子中,bytes_per_line可能在整个程序中保持不变。如果我们从三维笛卡尔坐标投影到二维坐标,那么我们会使用两次分母:
(x, y, z) → (x/z, y/z)
在这些情况下,更有效的做法是以某种方式缓存1/z的值,并使用乘法1/z代替除法。接下来的子节中,我们将展示如何做到这一点。此外,我们还希望坚持使用整数运算,避免使用浮点数(参见第5.11节)。
下面的描述相对较数学化,涵盖了将重复的除法转换为乘法的背后理论。如果您对这个理论不感兴趣,那么不要担心。您可以直接跳到接下来的示例5.13。
5.10.2 Converting Divides into Multiplies
//这个有意思了!像研究生<计算方法>的课程
为了区分精确的数学除法和整数除法,我们将使用以下符号表示:
■ n/d = n除以d的整数部分,向零取整(与C语言中的行为相同)
■ n%d = n除以d的余数,即n - d * (n / d)
■ n/d = nd^(-1) = n除以d的真实数学除法
在坚持使用整数运算的情况下,估计d^(-1)的一种明显方法是计算2^32/d。然后我们可以估计n/d的值
![]()
这种方法需要以64位精度执行乘以n的操作。这种方法存在一些问题:
■ 要计算2^32/d,编译器需要使用64位的long long类型进行算术运算,因为2^32不能适应unsigned int类型。我们必须将除法指定为(1ull << 32)/d。这种64位除法比我们最初想要执行的32位除法要慢得多!
■ 如果d恰好为1,那么2^32/d将不能适应unsigned int类型。
事实证明,稍微粗略的估计方法效果很好,并且解决了这两个问题。我们可以考虑使用(2^32-1)/d而不是2^32/d。
定义 s = 0xFFFFFFFFul / d; /* s = (2^32-1)/d */
我们可以使用单个unsigned int类型的除法来计算s。我们知道

接下来,计算一个对n/d的估计值q:
q = (unsigned int)( ((unsigned long long)n * s) >> 32);
从数学上讲,右移32位引入了一个误差e2:
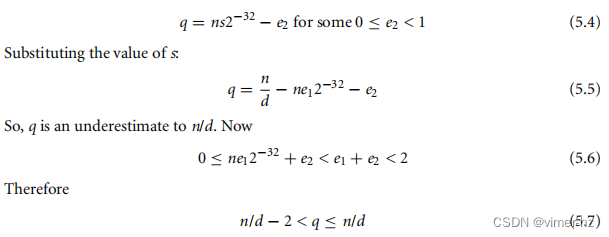
因此,q = n/d或q = (n/d) - 1。我们可以通过计算余数r = n - qd来很容易地找到它的值,该余数必须在0 ≤ r < 2d范围内。以下代码纠正了结果:
r = n - q * d; /* 余数在范围0 <= r < 2 * d内 */
if (r >= d) /* 如果需要修正 */
{
r -= d; /* 将余数修正为0 <= r < d的范围内 */
q++; /* 修正商 */
}
/* 现在q = n / d且r = n % d */例子5.13
下面这个例程scale展示了如何在实践中将除法转换为乘法。它将一个具有N个元素的数组除以分母d。我们首先按上述方法计算s的值。然后,我们将每个除法替换为乘以s的乘法。64位乘法是便宜的,因为ARM具有UMULL指令,它可以将两个32位值相乘,得到一个64位结果。
void scale(
unsigned int *dest,
/* destination for the scale data */
unsigned int *src,
/* source unscaled data */
unsigned int d,
/* denominator to divide by */
unsigned int N) /* data length */
{
unsigned int s = 0xFFFFFFFFu / d;
do
{
unsigned int n, q, r;
n = *(src++);
q = (unsigned int)(((unsigned long long)n * s) >> 32);
r = n - q * d;
if (r >= d)
{
q++;
}
*(dest++) = q;
} while (--N);
}在这里,我们假设分子和分母是32位的无符号整数。当然,对于使用32位乘法的16位无符号整数,或者使用128位乘法的64位整数,该算法同样适用。你应该选择你的数据的最窄宽度。如果你的数据是16位的,那么将s = (2^16 - 1)/d设置为估计的q,使用标准整数C乘法进行估计。
5.10.3 Unsigned Division by a Constant
要除以一个常数c,你可以使用示例5.13的算法,预先计算s = (2^32 - 1)/c。然而,还有一种更高效的方法。ADS1.2编译器使用这种方法来合成对常数的除法。
这个想法是使用一个足够精确的d-1的近似值,以便通过近似值相乘得到n/d的精确值。我们使用以下数学结果:
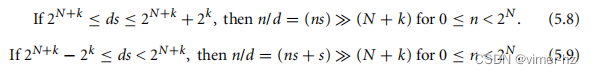
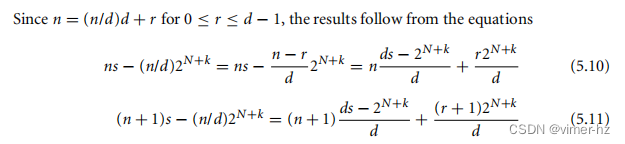
对于这两个方程,右边的范围为0 ≤ x < 2N+k。对于32位无符号整数n,我们取N = 32,选择一个k,使得2k < d ≤ 2k+1,并设置s = (2N+k + 2k)/d。
如果ds ≥ 2N+k,那么n/d = (ns) << (N + k);否则,n/d = (ns + s) << (N + k)。作为额外的优化,如果d是2的幂次,我们可以用移位操作替代除法。
例子5.14
函数udiv_by_const测试了上述算法。在实际应用中,d将是一个固定的常数而不是一个变量。你可以预先计算s和k,并只包括与你特定的d值相关的计算。
unsigned int udiv_by_const(unsigned int n, unsigned int d)
{
unsigned int s,k,q;
/* We assume d!=0 */
/* first find k such that (1 << k) <= d < (1 << (k+1)) */
for (k=0; d/2>=(1u << k); k++);
if (d==1u << k)
{
/* we can implement the divide with a shift */
return n >> k;
}
/* d is in the range (1 << k) < d < (1 << (k+1)) */
s = (unsigned int)(((1ull << (32+k))+(1ull << k))/d);
if ((unsigned long long)s*d >= (1ull << (32+k)))
{
/* n/d = (n*s) >> (32+k) */
q = (unsigned int)(((unsigned long long)n*s) >> 32);
return q >> k;
}
/* n/d = (n*s+s) >> (32+k) */
q = (unsigned int)(((unsigned long long)n*s + s) >> 32);
return q >> k;
}如果你知道 0 ≤ n < 2^31,就像正的有符号整数一样,那么你就不需要担心不同的情况。你可以增加 k 的值一个单位而不必担心 s 溢出。取 N = 31,选择一个 k,使得 2k−1 < d ≤ 2k,并且设置 s = (sN+k+2k−1)/d。那么 n/d = (ns) << (N + k)。
5.10.4 Signed Division by a Constant
我们可以使用与5.10.3节中类似的思想和算法来处理有符号常数。如果d < 0,那么我们可以先除以 |d|,然后在稍后修正符号,所以现在我们假设 d > 0。5.10.3节的第一个数学结果适用于有符号的n。如果 d > 0 并且 2N+k < ds ≤ 2N+k + 2k,那么

对于32位有符号的n,我们取N = 31,并选择k ≤ 31,使得2k−1 < d ≤ 2k。这确保了我们可以找到一个32位无符号整数 s = (2N+k + 2k )/d,满足前面的关系式。我们需要特别注意将32位有符号n与32位无符号s相乘。我们使用带有修正的带符号长整型乘法实现这一点,如果s的最高位设置了,就进行修正。
例子5.15
以下例程sdiv_by_const展示了如何除以一个有符号常数d。在实际应用中,你将在编译时预先计算k和s。只有针对你特定d值的涉及n的操作需要在运行时执行。
int sdiv_by_const(int n, int d)
{
int s,k,q;
unsigned int D;
/* set D to be the absolute value of d, we assume d!=0 */
if (d>0)
{
D=(unsigned int)d; /* 1 <= D <= 0x7FFFFFFF */
}
else
{
D=(unsigned int) - d; /* 1 <= D <= 0x80000000 */
}
/* first find k such that (1 << k) <= D < (1 << (k+1)) */
for (k=0; D/2>=(1u << k); k++);
if (D==1u << k)
{
/* we can implement the divide with a shift */
q = n >> 31; /* 0 if n>0, -1 if n<0 */
q=n+ ((unsigned)q >> (32-k)); /* insert rounding */
q = q >> k; /* divide */
if (d < 0)
{
q = -q;
/* correct sign */
}
return q;
}
/* Next find s in the range 0<=s<=0xFFFFFFFF */
/* Note that k here is one smaller than the k in the equation */
s = (int)(((1ull << (31+(k+1)))+(1ull << (k+1)))/D);
if (s>=0)
{
q = (int)(((signed long long)n*s) >> 32);
}
else
{
/* (unsigned)s = (signed)s + (1 << 32) */
q=n+ (int)(((signed long long)n*s) >> 32);
}
q = q >> k;
/* if n<0 then the formula requires us to add one */
q += (unsigned)n >> 31;
/* if d was negative we must correct the sign */
if (d<0)
{
q = -q;
}
return q;
}第7.3节展示了如何在汇编语言中高效实现除法。
总结除法:
- 尽量避免使用除法。不要将其用于循环缓冲处理。
- 如果无法避免除法,尝试利用除法算法通常同时生成商 n/d 和余数 n%d 的特点。
- 要重复使用相同的分母 d 进行除法运算,可以事先计算 s = (2k − 1)/d。这样,可以用 s 的2k位乘法来代替将一个 k 位无符号整数除以 d。
- 要将小于 2N 的无符号整数 n 除以无符号常数 d,可以找到一个32位无符号整数 s,并进行位移操作,使得 n/d 可以表示为 (ns) << (N + k) 或者 (ns + s) << (N + k)。具体的选择取决于 d。对于有符号除法也有类似的结果。
5.11 Floating Point
大多数ARM处理器实现不提供硬件浮点支持,在价格敏感的嵌入式应用中使用ARM可以节省功耗和面积。除了在ARM7500FE上使用的浮点加速器(FPA)和矢量浮点加速器(VFP)硬件之外,C编译器必须提供对软件浮点的支持。
实际上,这意味着C编译器将每个浮点操作转换为子程序调用。C库包含用整数算术模拟浮点行为的子例程。该代码是用高度优化的汇编语言编写的。
即使如此,浮点算法的执行速度也远远慢于相应的整数算法。
如果您需要快速执行和分数值,应该使用定点或块浮点算法。分数值在处理音频和视频等数字信号时经常使用。这是一个庞大而重要的编程领域,所以我们把一整章,第8章,专门用于介绍ARM上的数字信号处理领域。
为了获得最佳性能,您需要用汇编语言编写算法(请参考第8章的示例)。
5.12 Inline Functions and Inline Assembly
第5.5节介绍了如何高效地调用函数。您可以通过内联函数完全消除函数调用开销。此外,许多编译器允许在C源代码中包含内联汇编。使用包含汇编指令的内联函数,您可以让编译器支持通常不可用的ARM指令和优化。本节的示例将使用armcc中的内联汇编器。请不要将内联汇编器与主汇编器armasm或gas混淆。内联汇编器是C编译器的一部分。C编译器仍然执行寄存器分配、函数入口和出口。编译器还尝试优化您编写的内联汇编代码,或者在调试模式下进行反优化。尽管编译器的输出在功能上等同于您的内联汇编,但可能并非完全相同。
内联函数和内联汇编的主要好处是使得C语言能够访问通常不可用的操作。与#define宏相比,最好使用内联函数,因为后者不检查函数参数和返回值的类型。
以一个示例来说明,许多语音处理算法使用到饱和乘积双累加原语。该操作针对16位有符号操作数x和y以及32位累加器a计算a + 2xy。此外,如果操作结果超过32位范围,所有操作都会饱和到最接近的有效值。我们称x和y为Q15固定点整数,因为它们分别表示x2-15和y2-15的值。同样,a是Q31固定点整数,因为它表示a2-31的值。
我们可以使用内联函数qmac来定义这个新操作:
__inline int qmac(int a, int x, int y)
{
int i;
i = x*y; /* this multiplication cannot saturate */
if (i>=0)
{
/* x*y is positive */
i = 2*i;
if (i<0)
{
/* the doubling saturated */
i = 0x7FFFFFFF;
}
if (a + i < a)
{
/* the addition saturated */
return 0x7FFFFFFF;
}
return a + i;
}
/* x*y is negative so the doubling can’t saturate */
if (a + 2*i > a)
{
/* the accumulate saturated */
return - 0x80000000;
}
return a + 2*i;
}现在我们可以使用这个新操作来计算一个饱和相关性。换句话说,我们可以计算带有饱和的 a = 2x0y0 +···+ 2xN−1yN−1。
int sat_correlate(short *x, short *y, unsigned int N)
{
int a=0;
do
{
a = qmac(a, *(x++), *(y++));
} while (--N);
return a;
}编译器将每个qmac函数调用替换为内联代码。换句话说,它会插入qmac的代码而不是调用qmac。我们C实现的qmac并不是非常高效,需要几个if语句。我们可以使用汇编语言更高效地编写它。C编译器中的内联汇编器允许我们在内联C函数中使用汇编语言。
示例5.16展示了使用内联汇编的qmac的高效实现。该示例支持armcc和gcc的内联汇编格式,这两种格式有相当大的差异。在gcc格式中,"cc"告诉编译器该指令读取或写入条件码标志位。请参阅armcc或gcc手册获取更多信息。
__inline int qmac(int a, int x, int y)
{
int i;
const int mask = 0x80000000;
i = x*y;
#ifdef __ARMCC_VERSION /* check for the armcc compiler */
__asm
{
ADDS i, i, i
/* double */
EORVS i, mask, i, ASR 31 /* saturate the double */
ADDS a, a, i
/* accumulate */
EORVS a, mask, a, ASR 31 /* saturate the accumulate */
}
#endif
#ifdef __GNUC__ /* check for the gcc compiler */
asm("ADDS % 0, % 1, % 2 ":"=r" (i):"r" (i) ,"r" (i):"cc");
asm("EORVS % 0, % 1, % 2,ASR#31":"=r" (i):"r" (mask),"r" (i):"cc");
asm("ADDS % 0, % 1, % 2 ":"=r" (a):"r" (a) ,"r" (i):"cc");
asm("EORVS % 0, % 1, % 2,ASR#31":"=r" (a):"r" (mask),"r" (a):"cc");
#endif
return a;
}这个内联代码将sat_correlate的主循环从19条指令减少到9条指令。 示例5.17 假设我们使用带有ARMv5E扩展的ARM9E处理器。我们可以再次重写qmac,以便编译器使用新的ARMv5E指令:
__inline int qmac(int a, int x, int y)
{
int i;
__asm
{
SMULBB i, x, y /* multiply */
QDADD a, a, i /* double + saturate + accumulate + saturate */
}
return a;
}这次主循环编译为仅六条指令:
sat_correlate_v3
STR r14,[r13,#-4]! ; stack lr
MOV r12,#0
;a=0
sat_v3_loop
LDRSH r3,[r0],#2 ; r3 = *(x++)
LDRSH r14,[r1],#2 ; r14 = *(y++)
SUBS r2,r2,#1 ; N-- and set flags
SMULBB r3,r3,r14 ; r3 = r3 * r14
QDADD r12,r12,r3 ; a = sat(a+sat(2*r3))
BNE sat_v3_loop ; if (N!=0) goto loop
MOV r0,r12 ; r0 = a
LDR pc,[r13],#4 ; return r0其他通常无法从C语言中使用的指令包括协处理器指令。示例5.18展示了如何访问这些指令。
示例5.18向协处理器15写入以刷新指令缓存。您可以使用类似的代码来访问其他协处理器编号。
void flush_Icache(void)
{
#ifdef __ARMCC_VERSION /* armcc */
__asm {MCR p15, 0, 0, c7, c5, 0}
#endif
#ifdef __GNUC__ /* gcc */
asm ( "MCR p15, 0, r0, c7, c5, 0" );
#endif
}总结:内联函数和汇编语言
■ 使用内联函数来声明C编译器不支持的新操作或原语。
■ 使用内联汇编来访问C编译器不支持的ARM指令,例如协处理器指令或ARMv5E扩展指令。
5.13 Portability Issues
下面是将C代码移植到ARM时可能遇到的一些问题的总结:
■ char类型:在ARM上,char类型是无符号的,而不是像其他许多处理器那样有符号。一个常见的问题涉及使用char类型的循环计数器i和终止条件i ≥ 0,它们会变成无限循环。在这种情况下,armcc编译器会产生一个"unsigned comparison with zero"的警告。您可以选择使用编译器选项将char类型设置为有符号,或者将循环计数器改为int类型。
//现在不一定,要看编译器
■ int类型:一些旧的架构使用16位的int类型,在转换为ARM的32位int类型时可能会引起问题,尽管这种情况现在很少见。请注意,表达式在计算之前会被提升为int类型。因此,如果i = -0x1000,在16位机器上,表达式i == 0xF000为真,但在32位机器上为假。
■ 不对齐的数据指针:某些处理器支持从不对齐地址加载short和int类型的值。C程序可能直接操作指针,使它们变得不对齐,例如将char*转换为int*。直到ARMv5TE,ARM架构不支持不对齐指针。要检测它们,请在配置了对齐检查陷阱的ARM上运行程序。例如,您可以配置ARM720T在访问不对齐时发生数据中止。
■ 字节序假设:C代码可能对内存系统的字节序做出假设,例如将char*转换为int*。如果您将ARM配置为与代码所期望的字节序相同,那么就没有问题。否则,您必须删除依赖于字节序的代码片段,并用与字节序无关的代码替换它们。有关更多详细信息,请参阅第5.9节。
■ 函数原型:armcc编译器将参数以狭窄(narrow)方式传递,即缩小到参数类型的范围。如果函数的原型不正确,那么函数可能返回错误的结果。其他将参数以宽的方式传递的编译器,即使函数原型不正确,也可能给出正确的答案。始终使用ANSI原型。
■ 位字段的使用:位字段内的位布局取决于具体实现和字节序。如果C代码假设位按照特定顺序布局,那么这段代码就不具备可移植性。
■ 枚举的使用:尽管枚举是可移植的,不同的编译器会为枚举分配不同数量的字节。gcc编译器将始终为enum类型分配四个字节。armcc编译器只有在枚举值仅为八位时才分配一个字节。因此,如果在API结构中使用枚举,则无法在不同编译器之间交叉链接代码和库。
■ 内联汇编:在C代码中使用内联汇编会降低不同体系结构之间的可移植性。您应该将任何内联汇编分离为小的内联函数,以便于替换。此外,还可以提供参考的纯C实现这些函数的方法,在其他体系结构上可以使用。
■ volatile关键字:在ARM的内存映射外设位置的类型定义中使用volatile关键字。此关键字防止编译器优化内存访问,并确保编译器生成正确类型的数据访问。例如,如果将内存位置定义为volatile short类型,那么编译器将使用16位的加载和存储指令LDRSH和STRH来访问它。
5.14 Summary
通过以一定的方式编写C例程,您可以帮助C编译器生成更快的ARM代码。性能关键的应用程序通常包含一些主导性能的例程;在重写这些例程时,请遵循本章的指导原则。
以下是我们涵盖的关键性能要点:
■ 对于局部变量、函数参数和返回值,请使用有符号和无符号的int类型。这样可以避免强制转换,并有效地使用ARM的本机32位数据处理指令。
■ 最高效的循环形式是向零计数的do-while循环。
■ 展开重要的循环以减少循环开销。
■ 不要依赖编译器来优化重复的内存访问。指针别名通常会阻止这种优化。
■ 尽量将函数的参数限制为四个。如果参数保存在寄存器中,函数调用速度更快。
■ 结构体按元素大小递增的顺序布局,特别是在编译为Thumb指令时。
■ 不要使用位字段,而是使用掩码和逻辑操作。
■ 避免使用除法,可以使用倒数的乘法代替。
■ 避免使用不对齐的数据。如果数据可能不对齐,请使用char*指针类型。
■ 使用C编译器中的内联汇编来访问C编译器不支持的指令或优化。
















 1272
1272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









