






系统主内存存储应用程序和内核指令,它们的工作数据和文件系统缓存。在许多系统中,用于存储这些数据的辅助存储设备是主要存储设备-磁盘,其操作速度比主内存慢几个数量级。一旦主内存填满,系统可能开始在主内存和存储设备之间切换数据。这是一个缓慢的过程,通常会成为系统瓶颈,大大降低性能。系统还可能终止最大的内存消耗进程。
其他需要考虑的性能因素包括分配和释放内存的CPU开销、内存复制以及管理内存地址空间映射的开销。在多处理器架构中,内存局部性可能成为一个因素,因为连接到本地插槽的内存比远程插槽具有更低的访问延迟。
本章分为五个部分,前三个部分提供了内存分析的基础知识,后两个部分展示了其在基于Linux和Solaris的系统中的实际应用。各部分内容如下:
- 背景介绍了与内存相关的术语和关键的内存性能概念。
- 架构提供了硬件和软件内存架构的通用描述。
- 方法论解释了性能分析方法论。
- 分析描述了内存分析的性能工具。
- 调优解释了调优和示例可调参数。
关于CPU上的内存缓存(一级/二级/三级缓存,TLB)在第6章《CPU》中有介绍。
7.1 Terminology
在本章中使用的与内存相关的术语如下:
- 主内存:也称为物理内存,描述了计算机的快速数据存储区,通常以DRAM形式提供。
- 虚拟内存:主内存的抽象,(几乎)是无限的,且非争用的。虚拟内存并非真实的内存。
- 驻留内存:当前驻留在主内存中的内存。
- 匿名内存:没有文件系统位置或路径名的内存。它包括进程地址空间的工作数据,称为堆。
- 地址空间:内存上下文。每个进程和内核都有虚拟地址空间。
- 段:一个标记为特定目的的内存区域,例如用于存储可执行或可写入页面。
- OOM:内存耗尽,当内核检测到可用内存较少时发生。
- 页:操作系统和CPU使用的内存单元。在历史上,它通常是4或8 K字节。现代处理器支持多种页面大小,用于更大的尺寸。
- 缺页:无效的内存访问。这些在使用按需虚拟内存时是正常发生的。
- 分页:在主内存和存储设备之间转移页面。
- 交换:来自Unix,这是在主内存和交换设备之间传输整个进程。Linux通常使用交换来指代向交换设备(交换页面的传输)。在本书中,使用了原始的定义:交换是指整个进程的交换。
- 交换区:用于分页匿名数据和交换进程的磁盘区域。它可以是存储设备上的区域,也称为物理交换设备,或者是文件系统文件,称为交换文件。一些工具使用交换术语来指代虚拟内存(这是令人困惑和不正确的)。
本章还介绍了其他术语。词汇表中包含了基本的术语供参考,包括地址、缓冲区和DRAM。此外,还请参阅第2章和第3章的术语部分。
7.2 Concepts
以下是关于内存和内存性能的一些重要概念的精选。
7.2.1 Virtual Memory
虚拟内存是一种抽象概念,为每个进程和内核提供了一个大型、线性且私有的地址空间。它简化了软件开发,将物理内存的分配交给操作系统来管理。它还支持多任务处理,因为虚拟地址空间通过设计进行了分离,同时也支持超额订阅,因为正在使用的内存可以扩展到主内存之外。虚拟内存在第3章的操作系统中介绍过。有关历史背景,请参考[Denning 70]。
图7.1显示了对于一个带有交换设备(辅助存储)的系统的进程而言,虚拟内存的作用。一个内存页面被展示出来,因为大多数虚拟内存实现都是基于页面的。
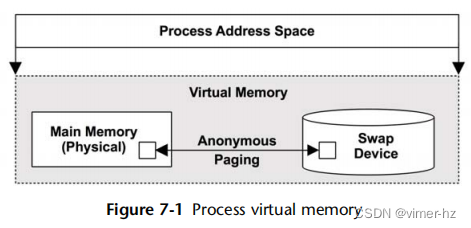
进程的地址空间由虚拟内存子系统映射到主内存和物理交换设备。内存页面可以根据需要在它们之间由内核移动,这个过程称为分页。这使得内核可以超额订阅主内存。
内核可能对超额订阅设置限制。在基于Solaris的内核中,限制是主内存和物理交换设备的大小之和。内核将拒绝试图超过此限制的分配。这样的“虚拟内存耗尽”错误一开始可能会让人困惑,因为虚拟内存本身是一个抽象资源。
Linux可以配置为支持相同的行为,但它也允许其他行为,包括不对内存分配设置任何限制。这称为过度承诺,并且在以下关于分页和需求分页的部分之后进行描述,这些部分对于过度承诺的工作是必要的。
7.2.2 Paging
分页是指将页面在主内存之间移动,分别称为页面调入(page-ins)和页面调出(page-outs)。它最早由Atlas计算机于1962年引入[Corbató 68],使得:
- 部分加载的程序能够执行
- 大于主内存的程序能够执行
- 程序在主内存和存储设备之间进行高效移动
这些功能至今仍然存在。与交换整个程序不同,分页是一种细粒度的管理和释放主内存的方法,因为页面大小单位相对较小(例如,4 K字节)。
通过BSD引入了带有虚拟内存的分页(分页虚拟内存)到Unix[Babaoglu 79],并成为标准实践。
随着后来引入文件系统页面缓存用于共享文件系统页面(参见第8章,文件系统),出现了两种不同类型的分页:文件系统分页和匿名分页。
File System Paging
文件系统分页是由于对内存映射文件中的页面进行读写而引起的。对于使用文件内存映射(mmap())的应用程序以及使用页面缓存的文件系统(大多数文件系统都使用;请参阅第8章,文件系统)来说,这是正常行为。它曾被称为“良好”分页[McDougall 06b]。
在需要时,内核可以通过将一些页面调出来释放内存。在这里术语会有点复杂:如果一个文件系统页面在主内存中被修改过(“脏”),则页面调出将需要将其写入磁盘。相反,如果文件系统页面没有被修改过(“干净”),则页面调出仅释放内存以便立即重用,因为磁盘上已经存在一份副本。由于这个原因,术语“页面调出”意味着页面被移出内存——这可能涉及或不涉及向存储设备的写入(您可能会看到这个定义有所不同)。
Anonymous Paging
匿名分页涉及进程私有的数据:进程堆和栈。它被称为匿名,是因为在操作系统中没有具体的命名位置(即没有文件系统路径名称)。匿名页面调出需要将数据移动到物理交换设备或交换文件。Linux使用术语"swapping"来指代这种类型的分页。
匿名分页会影响性能,因此被称为"不良"分页[McDougall 06b]。当应用程序访问已经调出的内存页面时,它们会阻塞在磁盘I/O上,以便将页面读回主内存。这就是匿名页面调入,它给应用程序引入了同步延迟。匿名页面调出可能不会直接影响应用程序性能,因为它们可以由内核异步执行。
性能最好的情况是没有匿名分页(或交换)。这可以通过配置应用程序保持在可用主内存范围内,并监视页面扫描、内存利用率和匿名分页,以确保不再出现内存不足的迹象。
7.2.3 Demand Paging
支持需求分页的操作系统(大多数都支持)根据需要将虚拟内存页映射到物理内存,如图7.2所示。这样做推迟了创建映射的CPU开销,直到它们真正被需要和访问,而不是在内存范围首次分配时进行。
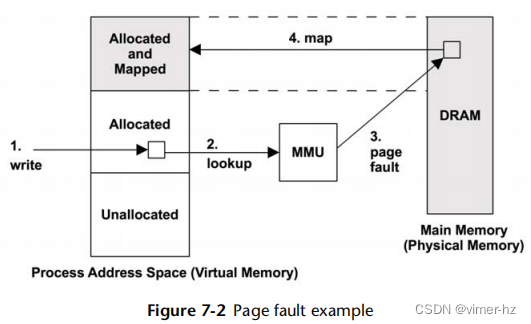
图7.2中显示的序列始于对新分配的虚拟内存页的写入,导致按需映射到物理内存。当虚拟内存到物理内存之间最初没有页面映射时,会发生页面错误。
在已映射文件的情况下,第一步也可以是读取,该文件包含数据但尚未映射到该进程地址空间。
如果映射可以从内存中的另一页满足,则称为次要错误。这可能发生在将新页从可用内存映射到过程中(如图所示)。它还可以发生在将另一页映射到另一页,例如从映射的共享库读取一页。
需要访问存储设备(本图未显示)的页面错误,例如访问非缓存的内存映射文件,称为主要错误。
虚拟内存模型和按需分配的结果是,任何虚拟内存页可能处于以下状态之一:
A. 未分配
B. 已分配,但未映射(未填充且尚未错误)
C. 已分配,并映射到主内存(RAM)
D. 已分配,并映射到物理交换设备(磁盘)
如果由于系统内存压力而将页面调出,则达到状态(D)。从(B)到(C)的转换是一个页面错误。如果需要进行磁盘I/O,则是一个主要页面错误;否则是一个次要页面错误。
从这些状态中,还可以定义两个内存使用术语:
居住集大小(RSS):已分配主内存页的大小(C)
虚拟内存大小:所有已分配区域的大小(B + C + D)
通过BSD,Unix引入了需求分页,以及分页虚拟内存。
7.2.4 Overcommit
Linux支持超额分配的概念,允许分配比系统实际存储的内存更多的内存,即超过物理内存和交换设备的总和。它依赖于按需分页和应用程序不使用其已分配内存的倾向。
有了超额分配,应用程序对内存的请求(例如malloc())将在本应失败时成功。应用程序员可以慷慨地分配内存,之后根据需要稀疏地使用,而不是保守地分配内存以保持在虚拟内存限制范围内。
在Linux上,超额分配的行为可以通过可调参数进行配置。有关详细信息,请参阅第7.6节“调整”。超额分配的后果取决于内核如何管理内存压力;请参阅第7.3节“体系结构”中对OOM killer的讨论。
7.2.5 Swapping
交换是将整个进程在主内存和物理交换设备或交换文件之间移动的过程。这是管理主内存的最初Unix技术,也是“交换”一词的起源(Thompson 78)。
要交换出一个进程,必须将其所有私有数据写入交换设备,包括线程结构和进程堆(匿名数据)。来自文件系统且未被修改的数据可以被丢弃,并在需要时重新从原始位置读取。
被交换出的进程仍然由内核知晓,因为一小部分进程元数据始终驻留在内核内存中。要将进程交换回来,内核会考虑线程优先级、在磁盘上等待的时间以及进程的大小。长时间等待和较小的进程会受到青睐。
交换严重影响性能,因为已被交换出的进程需要大量的磁盘I/O才能再次运行。在早期的Unix系统中,如PDP-11型号的机器,最大进程大小为64K字节时,这种做法更为合理(Bach 86)。
虽然基于Solaris的系统仍然可以进行交换,但只有在分页无法快速释放足够的内存以满足应用程序需求时才会这样做(因为分页受页面扫描速率的限制;请参阅第7.3节“体系结构”)。Linux系统根本不交换进程,而只依赖分页。
当人们说“系统正在交换”时,他们通常指的是分页。在Linux中,“交换”一词指的是分页到交换文件或设备(匿名分页)。
7.2.6 File System Cache Usage
系统启动后内存使用量增长是正常的,因为操作系统利用可用内存来缓存文件系统,从而提高性能。原则是:如果有多余的主内存,则将其用于某些有用的事情。这可能会让幼稚的用户感到困扰,因为他们在启动后不久就看到可用空闲内存几乎降至零。但对应用程序来说并不构成问题,因为内核应该能够在应用程序需要时快速从文件系统缓存中释放内存。
关于可能占用主内存的各种文件系统缓存的更多信息,请参阅第8章《文件系统》。
7.2.7 Utilization and Saturation
主内存利用率可以计算为已使用内存与总内存的比值。文件系统缓存使用的内存可以视为未使用,因为这部分内存可以被应用程序重新利用。
如果对内存的需求超过了主内存的容量,主内存就会饱和。操作系统可以通过使用分页、交换和在Linux上使用OOM killer(稍后描述)来释放内存。这些活动中的任何一项都是主内存饱和的指标。
如果系统对所愿意分配的虚拟内存量设定了限制(Linux的过度承诺除外),也可以根据容量利用率来研究虚拟内存。如果是这样,一旦虚拟内存耗尽,内核将无法进行分配;例如,malloc() 函数返回 ENOMEM。
需要注意的是,系统当前可用的虚拟内存有时会(令人困惑地)称为可用交换空间。
7.2.8 Allocators
虚拟内存处理物理内存的多任务处理,而在虚拟地址空间内的实际分配和放置通常由分配器处理。这些分配器可以是用户空间库或基于内核的例程,为软件程序员提供了一个简单的内存使用接口(例如malloc()、free())。
分配器对性能有显著影响,系统可能提供多个用户级分配器库供选择。它们可以通过使用诸如每线程对象缓存等技术来提高性能,但如果分配变得碎片化和浪费,它们也可能损害性能。具体示例在第7.3节“体系结构”中有详细介绍。
7.2.9 Word Size
正如第6章介绍的那样,CPU处理器可能支持多种字长,例如32位和64位,允许软件在其中任一种上运行。由于地址空间大小受到字长可寻址范围的限制,需要超过4GB(通常略少)的应用程序对于32位地址空间来说太大了,需要编译为64位或更高位。
根据CPU架构的不同,使用更大的位宽可能会提高内存性能。在数据类型具有未使用位的情况下,可能会浪费少量内存。
7.3 Architecture
这一节介绍了内存架构,包括硬件和软件,还有处理器和操作系统的具体内容。这些主题被总结为性能分析和调优的背景知识。更多细节请参阅本章末尾列出的供应商处理器手册和操作系统内部的相关文献。
7.3.1 Hardware
内存硬件包括主存储器、总线、CPU高速缓存和内存管理单元(MMU)。
主存储器
如今常用的主存储器类型是动态随机存取存储器(DRAM)。这是一种易失性存储器,即在断电时会丢失其内容。DRAM提供了高密度存储,因为每个位只需要使用两个逻辑组件来实现:一个电容器和一个晶体管。电容器需要定期刷新以保持电荷。
企业服务器根据其用途配置不同数量的DRAM,通常范围从1GB到1TB甚至更大。这些数量可能使得云计算实例的内存相形见绌,后者通常在512MB到64GB之间。然而,云计算旨在将负载分布到一组实例上,因此它们可以共同为分布式应用程序提供更多DRAM,尽管这会带来更高的一致性成本。
延迟
主存储器的访问时间可以通过列地址选通(CAS)延迟来衡量:发送所需地址(列)到内存模块并且数据可以被读取之间的时间。这取决于内存类型(对于DDR3大约为10纳秒)。对于内存I/O传输,该延迟可能会在内存总线(例如64位宽)多次发生,以传输一个缓存行(例如64字节宽)。还有其他与CPU和MMU相关的延迟,用于读取新可用的数据。
主存储器架构
图7.3展示了一个通用的双处理器统一存储访问(UMA)系统的示例主存储器架构。
每个CPU通过共享系统总线对所有存储器具有统一的访问延迟。当由单个操作系统内核实例管理,并且在所有处理器上均匀运行时,这也是一种对称多处理(SMP)架构。
作为比较,在图7.4中显示了一个双处理器非均匀存储访问(NUMA)系统的示例,该系统使用的CPU互连成为存储器架构的一部分。对于这种架构,主存储器的访问时间取决于其相对于CPU的位置。

CPU 1可以通过其内存总线直接对DRAM A进行I/O。这被称为本地内存。CPU 1通过CPU 2和CPU互连(两次跳跃)对DRAM B执行I/O。这被称为远程内存,并具有更高的访问延迟。
连接到每个CPU的内存块被称为内存节点,或简称节点。操作系统可能根据处理器提供的信息意识到内存节点的拓扑结构,从而使其能够分配内存并根据内存局部性安排线程,尽可能偏向本地内存以提高性能。
总线
主存储器如何物理连接到系统取决于先前描绘的主存储器架构。实际实现可能涉及在CPU和存储器之间的额外控制器和总线,并以以下一种方式访问:
共享系统总线:单处理器或多处理器,通过共享系统总线、内存桥控制器,最终是内存总线。这在UMA示例图7.3中有所描述,并且在第6章CPU的图6.9中作为英特尔前端总线示例有所描述。该示例中的内存控制器是北桥。
直接:单处理器通过内存总线直接连接的内存。
互连:多处理器,每个处理器通过内存总线直接连接的内存,并且处理器通过CPU互连连接。这在前面作为NUMA示例的图7.4中有所描述;CPU互连在第6章CPU中有所讨论。
如果您怀疑您的系统不属于上述任何一种类型,请查找系统功能图并沿着CPU和内存之间的数据路径,注意沿途的所有组件。
DDR SDRAM
无论是哪种架构,内存总线的速度通常由处理器和系统主板支持的内存接口标准决定。自1996年以来,一种常见的标准是双倍数据速率同步动态随机存取存储器(DDR SDRAM)。双倍数据速率指的是数据在时钟信号的上升沿和下降沿上传输(也称为双倍泵送)。同步一词表示内存与CPU同步时钟。
表7.1显示了一些示例DDR SDRAM标准。
DDR4接口标准于2012年9月发布。这些标准通常以“PC-”开头,后面跟着以每秒兆字节为单位的数据传输速率的名称,例如PC-1600。
多通道
系统架构可能支持并行使用多个内存总线,以提高带宽。常见的倍数包括双通道、三通道和四通道。例如,英特尔Core i7处理器支持最多四通道DDR3-1600,最大内存带宽为51.2 G字节/秒。
CPU缓存
处理器通常包括片上硬件缓存,以提高内存访问性能。缓存可能包括下面逐渐降低速度和增加大小的级别:
第1级:通常分为独立的指令缓存和数据缓存
第2级:用于指令和数据的缓存
第3级:另一个更大的缓存级别
第1级通常由虚拟内存地址引用,而第2级及更高级别则由物理内存地址引用,具体取决于处理器。
这些缓存在第6章CPU中进一步讨论。本章还讨论了另一种类型的硬件缓存TLB。
MMU
内存管理单元负责虚拟地址到物理地址的转换。这些转换是按页执行的,页面内的偏移直接映射。MMU在第6章CPU中引入,与附近的CPU缓存相关。
图7.5显示了一个通用的MMU,包括CPU缓存和主存储器级别。
多种页面大小
现代处理器支持多种页面大小,允许操作系统和MMU使用不同的页面大小,例如4K字节、2M字节、1G字节。基于Solaris的内核支持多种页面大小以及动态创建更大页面大小,称之为多页面大小支持(MPSS)。
Linux具有一个名为huge pages的功能,它为特定的大页面大小(如2M字节)保留了一部分物理内存。提前保留大页面不如Solaris的动态分配方法灵活,但也避免了内存碎片化问题,使得无法动态分配更大的页面。
TLB
图7.5中的MMU使用TLB作为第一级地址转换缓存,然后是主存储器中的页表。TLB可以分成分别用于指令和数据页面的独立缓存。
由于TLB对映射的条目数有限,使用较大的页面大小扩大了可以从其缓存中进行转换的内存范围(其覆盖范围),从而减少了TLB未命中,并改善了系统性能。TLB还可以进一步分成每种页面大小的独立缓存,提高了在缓存中保留较大映射的概率。
以TLB大小为例,典型的Intel Core i7处理器提供了表7.2所示的四个TLB [Intel 12]。
这个处理器具有一个数据TLB级别。英特尔Core微体系结构支持两个级别,就像CPU提供多个主存储器缓存级别一样。
TLB的具体组成取决于处理器类型。请参考供应商的处理器手册,了解您的处理器中的TLB详细信息以及它们的运行方式。
7.3.2 Software
内存管理软件包括虚拟内存系统、地址转换、交换、分页和分配。本节包括与性能相关性最高的主题:释放内存、空闲列表、页面扫描、交换、进程地址空间和内存分配器。
释放内存
当系统上可用内存变得不足时,内核可以使用各种方法来释放内存,并将其添加到空闲页面列表中。
这些方法如图7.6所示,按照可用内存减少的一般顺序使用。

这些方法包括:
- 空闲列表:未使用的页面列表(也称为空闲内存),可立即分配。通常实现为多个空闲页面列表,每个用于一个局部群组(NUMA)。
- Reaping(收割):当低内存阈值被越过时,内核模块和内核slab分配器可以被指示立即释放任何可以轻松释放的内存。这也被称为收缩。
在Linux上,具体方法包括:
- 页面缓存:文件系统缓存。一个名为swappiness的可调参数设置了偏向从页面缓存中释放内存而非交换的程度。
- 交换:这是由页面输出守护进程kswapd进行的分页,它会找到最近未被使用的页面并将其添加到空闲列表中,包括应用程序内存。它们被分页出去,可能涉及写入基于文件系统的交换文件或交换设备。只有在配置了交换文件或设备时才可用。
- OOM killer:内存耗尽终结者将通过查找并终止一个牺牲进程来释放内存,该进程是通过select_bad_process()找到的,然后通过调用oom_kill_process()进行终止。这可能会记录在系统日志(/var/log/messages)中作为“内存不足:终止进程”消息。
在特定的基于Solaris系统上,方法包括:
- 循环页面缓存:这包含一个有效但当前未引用的文件系统页面列表,称为cachelist,根据需要可以将其添加到空闲列表中。这避免了页面扫描的开销。
- ZFS ARC:ZFS文件系统将检测到系统可能很快开始进行页面扫描,并将使用arc_kmem_reap_now()执行自己的收割以释放内存。
- 分页:由页面输出守护程序(也称为页面扫描器)执行,找到最近未被使用的页面并将其添加到空闲列表中,包括应用程序内存。它们被分页出去,可能涉及写入文件系统或交换设备。
- 交换:仍然存在于基于Solaris系统上,它将整个进程移动到交换设备,并是处理主内存压力的原始Unix方法。
- 硬交换:卸载未激活的内核模块,并顺序地将进程交换到交换设备。
这些系统之间的比较很有趣。在基于Solaris系统上,文件系统缓存在分页发生时应为空。Linux提供了一种平衡这种行为的方式:swappiness,一个介于0和100之间的参数(默认值为60),更高的值偏向通过分页应用程序释放内存,而较低的值则通过从页面缓存中回收内存(类似于基于Solaris系统的行为)。这允许通过保留热文件系统缓存而分页出冷应用程序内存来改善系统吞吐量。
如果两个系统上都没有配置交换设备或交换文件,这也很有趣。这将限制虚拟内存大小,因此除非使用超额分配,否则内存分配会更早失败。在Linux上,这也意味着可能更早地使用OOM killer。
考虑一个具有无限内存增长的应用程序问题。有了交换空间,这可能首先成为由于分页而导致的性能问题,这是实时调试问题的机会。没有交换空间,就没有分页的宽限期,所以应用程序要么遇到“内存耗尽”错误,要么OOM killer终止它。如果问题只在几个小时的使用后才出现,这可能会延迟调试问题。
接下来的部分将更详细地描述Linux和Solaris操作系统中的空闲列表、收割以及页面分页守护程序。
空闲列表
最初的Unix内存分配器使用了内存映射和首次适配扫描。随着BSD引入分页虚拟内存,添加了一个空闲列表和一个页面分页守护程序。空闲列表允许立即定位可用内存,如图7.7所示。

释放的内存被添加到列表的头部,以供将来分配使用。由页面分页守护进程释放的内存——可能仍包含有用的缓存文件系统页面——被添加到列表的尾部。如果在有用页面被重新使用之前出现对这些页面的未来请求,则可以重新获取并从空闲列表中删除该页面。
一种空闲列表形式仍然被Linux和基于Solaris的系统使用,如图7.6所示。空闲列表通常通过分配器(例如内核的slab分配器和用户空间的libc malloc)进行消耗。它们会消耗页面,然后通过其分配器API将其公开。
拥有一个单一的空闲列表也是一种简化;如何实现这一点取决于内核类型和版本。
Linux
Linux使用伙伴分配器来管理页面。这为不同大小的内存分配提供了多个空闲列表,遵循以2为底的方案。伙伴这个术语指的是找到相邻的空闲内存页面,以便它们可以一起分配。有关历史背景,请参阅[Peterson 77]。
伙伴空闲列表位于以下层次结构的底部,从每个内存节点pg_data_t开始:
- 节点:内存块,支持NUMA
- 区域:用于特定目的的内存范围(直接内存访问(DMA)、正常、高内存)
- 迁移类型:不可移动的、可回收的、可移动的等
- 大小:以2为底的页数
在节点的空闲列表内进行分配可以改善内存局部性和性能。
Solaris
基于Solaris的系统针对不同的内存位置(mnodes)、页面大小和页面着色使用多个空闲列表。它们也以一种类似伙伴的方式行事,将页面分组为更大的页面大小。这些列表在vm_dep.h中声明。

页面着色是虚拟页地址和物理页地址之间的映射关系,可以使用散列、轮询或其他方案。这是另一种提高访问性能的策略。
回收
回收主要涉及从内核slab分配器缓存中释放内存。这些缓存包含以slab大小为单位的未使用内存块,准备重用。回收将此内存返回给系统以进行页面分配。
在Linux上,内核模块还可以调用register_shrinker()函数来注册用于回收其自己内存的特定函数。
在基于Solaris的系统中,回收主要由kmem_reap()驱动的slab分配器完成。
页面扫描
通过页面分页方式释放内存由内核页面守护进程管理。当空闲列表中的可用主内存下降到阈值以下时,页面分页守护进程开始进行页面扫描。
页面扫描仅在需要时发生。一个通常平衡的系统可能不会经常进行页面扫描,而只在短时间内进行。而基于Solaris的系统在进行页面扫描之前会使用其他机制释放内存,如前面所示,超过几秒钟的页面扫描通常是内存压力问题的迹象。
Linux
页面分页守护进程称为kswapd(),它扫描处于非活跃和活跃内存的LRU(最近最少使用)页面列表以释放页面。它根据空闲内存和两个阈值唤醒,以提供滞后效应,如图7.8所示。

一旦空闲内存达到最低阈值,kswapd会以同步模式运行,根据请求释放内存页面(内核免除此要求)[Gorman 04]。这个最低阈值是可调的(vm.min_free_kbytes),其他阈值根据它进行缩放(乘以2倍、3倍)。
页面缓存有专门的列表用于存储非活跃页面和活跃页面。它们以LRU(最近最少使用)的方式运作,使得kswapd能够快速找到空闲页面。这些列表如图7.9所示。
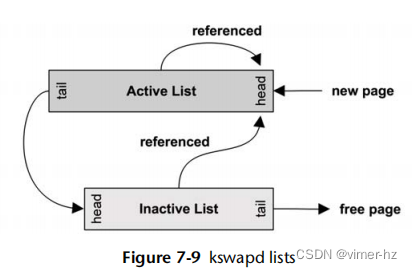
kswapd首先扫描非活跃列表,如果需要的话再扫描活跃列表。扫描这个术语指的是在遍历列表时检查页面:如果页面被锁定或者是脏页,则不能释放。在原始的页面分页守护进程中,"扫描"一词有着不同的含义,它会扫描整个内存,在基于Solaris的系统中仍然存在。
Solaris
页面扫描循环遍历内存中的所有页面,找到最近最少使用的页面,然后安排将它们移动到物理交换设备上。这最初是在带有分页虚拟内存的BSD系统中添加的[Babaoglu 79],后来改进为使用两个指针来扫描内存,如图7.10所示(这种类似时钟的表示方法可以追溯到Multics系统[Corbató 68])。

第一个hand在每个页面上设置一个位,指示该页面尚未被访问。当页面被访问时,这个位会被清除。第二个hand会检查这个位是否仍然被设置。如果是,页面扫描器就知道该页面最近没有被使用,可以被换出。两个hand之间的距离是可调的(handspreadpages)。
页面扫描的速率是动态的,根据可用的空闲内存而变化。这在图7.11中以一个128GB系统为例进行了说明,同时列出了可调的名称(基于[McDougall 06a])。

当可用内存降到desfree以下,然后是minfree以下时,页面换出守护进程会更频繁地被唤醒以扫描页面。如果可用内存连续30秒低于desfree,内核也会开始进行交换。
这些可调参数在setupclock()函数中初始化,根据主内存的比例进行设置。例如,lotsfree被设置为1/64。赤字参数是动态的,当内存消耗快速增加时会增长,这样内核就能更早地增加空闲列表。
对于较大的系统而言,页面扫描变得昂贵,因此添加了循环页面缓存,以便可以快速找到页面。这类似于Linux页面换出守护进程查找页面的方式。
7.3.3 Process Address Space
由硬件和软件共同管理,进程虚拟地址空间是一系列根据需要映射到物理页面的虚拟页面。这些地址被分割成称为段的区域,用于存储线程堆栈、进程可执行文件、库和堆。图7.12展示了32位进程的示例,适用于x86和SPARC处理器。

程序可执行段包含单独的文本和数据段。库也由单独的可执行文本和数据段组成。这些不同的段类型包括:
- 可执行文本:包含进程的可执行CPU指令。它是从文件系统上的二进制程序的文本段映射而来。它具有只读和可执行的权限。
- 可执行数据:包含从二进制程序的数据段映射而来的初始化变量。它具有读/写权限,因此可以在程序运行时修改变量。它还具有私有标志,以便修改不被刷新到磁盘上。
- 堆:这是程序的工作内存,是匿名内存(没有文件系统位置)。它根据需要增长,并通过malloc()进行分配。
- 栈:正在运行的线程的堆栈,映射为可读/写。
库的文本段可以被使用相同库的其他进程共享,每个进程都有一个私有副本的库数据段。
堆的增长
一个常见的困惑源于堆的无限增长。这是否意味着内存泄漏?
对于大多数分配器来说,不会将内存归还给操作系统;相反,它会保留内存以便为未来的分配提供服务。这意味着进程的常驻内存只会增长,这是正常的。进程减少内存的方法包括:
- 重新执行:从一个空地址空间重新开始
- 内存映射:使用和,它们会将内存归还给系统
一些分配器支持mmap作为一种操作模式。请参阅第8章文件系统中的第8.3.10节,内存映射文件。
7.3.4 Allocators
有各种用户级和内核级分配器用于内存分配。图7.13展示了分配器的作用,包括一些常见类型。
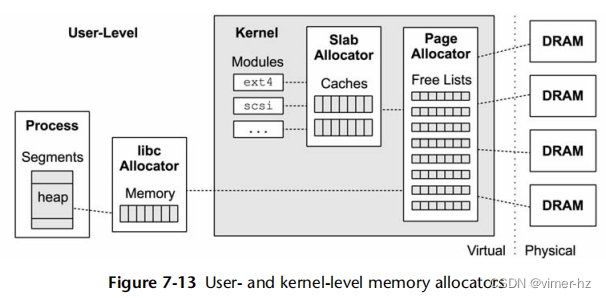
页面管理在之前的第7.3.2节“空闲列表”中有所描述。
内存分配器的特性可以包括:
- 简单的API:例如,`malloc`、`free`。
- 高效的内存使用:当为各种大小的内存分配提供服务时,内存使用可能会变得分散,存在许多未使用的区域浪费内存。分配器可以努力合并未使用的区域,使较大的分配能够利用它们,提高效率。
- 性能:内存分配可能频繁发生,在多线程环境下,由于同步原语的竞争,性能可能表现不佳。分配器可以被设计为尽量少地使用锁,并且利用每个线程或每个CPU的缓存来提高内存局部性。
- 可观察性:分配器可以提供统计信息和调试模式,显示它的使用方式以及哪些代码路径负责分配。接下来的章节将描述内核级分配器——slab和SLUB,以及用户级分配器——libmalloc、libumem和mtmalloc。
Slab(页框)
内核slab分配器管理特定大小对象的缓存,使它们能够在无需分配页面的情况下快速回收。这对于内核分配特别有效,因为内核分配通常是针对固定大小的结构体。
作为内核中的一个示例,以下两行代码摘自ZFS arc.c:

第一个函数`kmem_alloc()`展示了一种传统样式的内核分配,其大小作为参数传递。内核根据该大小将其映射到一个slab缓存(或者是一个超大尺寸区域)。第二个函数`kmem_cache_alloc()`直接在自定义的slab分配器缓存上操作,在这种情况下是`(kmem_cache_t *)hdr_cache`。
Solaris 2.4中引入了这一机制[Bonwick 94],后来通过每CPU缓存(称为magazines)进行了增强[Bonwick 01]:
我们的基本方法是给每个CPU分配一个包含M个对象的缓存,称为magazine,类比于自动武器。每个CPU的magazine可以在CPU需要重新加载之前满足M次分配——也就是说,将其空的magazine换成一个满的magazine。
除了高性能外,Solaris为slab分配器提供了各种调试和分析工具。其中包括审计功能,可以跟踪分配细节,包括堆栈信息。
slab分配器在Linux的2.2版本中引入,多年来一直是默认选项。最近的内核版本提供SLUB作为选项或默认选项。
SLUB
Linux内核的SLUB分配器基于slab分配器,并旨在解决slab分配器的各种问题,特别是其复杂性。这些包括移除对象队列和每个CPU缓存,将NUMA优化留给页面分配器(参见上文的自由列表部分)。
SLUB分配器在Linux 2.6.23中成为默认选项[2]。
libc
Solaris的用户级分配器由libc提供,它简单且通用。尽管通常是默认的分配器(取决于编译器配置),但man页不建议使用它(malloc(3C)):
这些默认的内存分配例程对于多线程应用程序是安全的,但不具备可扩展性。通过使用一个锁,多个线程的并发访问是单线程化的。对于大量使用动态内存分配的多线程应用程序,应链接使用为并发访问设计的分配库,如libumem(3LIB)或libmtmalloc(3LIB)。
除了性能问题外,该分配器是基于堆的,并且随着时间的推移可能会受到碎片化的影响。
glibc
GNU libc分配器基于Doug Lea的dlmalloc。其行为取决于分配请求的大小。小型分配从内存块中提供服务,这些内存块包含相似大小的单位,可以使用伙伴算法合并。较大的分配可以使用树查找来高效地找到空间。而非常大的分配则切换到使用mmap()。其结果是一个性能优秀的分配器,充分利用了多种分配策略的优势。
libumem
在基于Solaris的系统中,libumem是slab分配器的用户空间版本。可以通过链接或预加载库来使用,并为多线程应用程序提供改进的性能。
libumem从一开始就设计为可扩展,并具有以最小的时间和空间开销为代价的调试和分析功能。其他内存分析工具在分析模式下会减慢目标速度,有时甚至导致问题不再发生,而且通常会使它们不适合在生产环境中使用。
mtmalloc
这是另一个针对基于Solaris的系统的高性能多线程用户级分配器。它使用每个线程的缓存来处理小型分配,并使用单个超大区域来处理大型分配。每个线程的缓存避免了传统分配器中的锁争用问题。
7.4 Methodology
本节介绍了用于内存分析和调优的各种方法和练习。这些主题在表7.3中进行了总结。

请参阅第2章“方法论”了解更多策略以及对其中许多内容的介绍。
这些方法可以单独使用,也可以组合使用。我建议首先按照以下顺序使用以下策略:性能监控,USE方法和使用特征化。
第7.5节“分析”展示了应用这些方法的操作系统工具。
7.4.1 Tools Method
工具方法是一个迭代使用可用工具,检查它们提供的关键指标的过程。虽然是一种简单的方法,但它可能忽视那些工具无法提供良好或没有可见性的问题,并且执行起来可能耗时。
对于内存问题,工具方法可以包括检查以下内容:
- 页面扫描:查看持续的页面扫描(超过10秒)是否表示内存压力。在Linux上,可以使用sar -B命令并检查pgscan列。在Solaris上,可以使用vmstat(1M)命令并检查sr列。
- 分页:内存分页是系统内存不足的进一步指示。在Linux上,可以使用vmstat(8)命令并检查si和so列(这里,换出一词表示匿名分页)。在Solaris上,vmstat -p显示按类型的分页;要检查匿名分页。
- vmstat:每秒运行vmstat,并检查可用内存的free列。
- OOM killer:仅适用于Linux,在系统日志/var/log/messages中可以看到这些事件,也可以使用dmesg(1)命令。搜索“Out of memory”。
- 交换:仅适用于Solaris,通常在事后注意到,通过运行vmstat并检查w列来指示已交换出的线程。要实时查看交换情况,使用vmstat -S并检查si和so。
- top/prstat:查看哪些进程和用户是最大的物理内存消耗者(驻留),以及虚拟内存消耗者(请参阅man手册以获取列名,根据版本不同名称可能会有所不同)。这些工具还总结了可用内存。
- dtrace/stap/perf:使用堆栈跟踪跟踪内存分配,以确定内存使用的原因。
如果发现问题,请从可用工具的所有字段中检查,以获取更多上下文信息。有关每个工具的更多信息,请参阅第7.5节“分析”。其他方法可能会识别更多类型的问题。
7.4.2 USE Method
USE 方法用于在性能调查早期跨所有组件识别瓶颈和错误,这样可以在深入和耗时更长的策略之前进行检查。
系统范围内需要检查以下内容:
- 利用率:内存使用量及可用量。应检查物理内存和虚拟内存。
- 饱和度:页面扫描程度、分页、交换以及Linux OOM killer 的牺牲次数,作为减轻内存压力的措施。
- 错误:内存分配失败。
饱和度可能首先进行检查,因为持续饱和是内存问题的迹象。这些指标通常可以从操作系统工具中轻松获取,包括 vmstat(1)、sar(1) 和用于 OOM killer sacrifices 的 dmesg(1)。对于配置有单独磁盘交换设备的系统,任何与交换设备的活动也是内存压力的迹象。
利用率通常较难阅读和解释。通过饱和度指标,您可以了解物理内存是否不足:系统开始分页或进程被牺牲(OOM)。要确定物理利用率,您需要知道有多少可用内存(free)。不同工具可能以不同方式报告这一点,这取决于它们是否考虑了未引用的文件系统缓存页面或非活动页面。系统可能报告只剩下 10MB 可用内存,但实际上有 10GB 文件系统缓存,可以在需要时立即被应用程序回收。查看工具文档以了解其中包含哪些内容。
根据系统是否执行过量承诺,还可能需要检查虚拟内存利用率。对于那些不执行过量承诺的系统,一旦虚拟内存耗尽,内存分配将失败,这是一种内存错误。
历史上,内存错误一直由应用程序报告,尽管并非所有应用程序都这样做(而且在 Linux 过量承诺的情况下,开发人员可能认为没有必要这样做)。最近,SmartOS 添加了系统错误计数器,用于报告每个区域的失败 brk() 调用,作为一种内存相关错误计数器。
对于实施内存限制或配额(资源控制)的环境,如某些云计算环境,可能需要以不同方式测量内存饱和度。例如,在基于 Solaris 的系统上实施 OS 虚拟化时,对于每个客户实例强制执行内存配额的机制不同,并将其与传统的页面扫描器报告的方式有所不同。您的 OS 实例可能已达到其内存限制并进行分页,尽管系统并未使用传统的页面扫描器进行扫描。
7.4.3 Characterizing Usage
对内存使用情况进行表征是进行容量规划、基准测试和模拟工作负载时的重要练习。通过识别配置错误,它也可以带来一些最大的性能增益。例如,数据库缓存可能配置过小,导致命中率低,或者配置过大,引起系统分页。
对于内存,这涉及识别内存使用的位置和数量:
- 系统范围内的物理和虚拟内存利用率
- 饱和度程度:页面扫描、交换、OOM kill
- 内核和文件系统缓存内存使用
- 每个进程的物理和虚拟内存使用
- 如果存在,内存资源控制的使用
下面是一个示例描述,展示了如何将这些属性结合在一起表达:
该系统有 256GB 的主内存,仅利用了 1%,其中有 30% 存储在文件系统缓存中。最大的进程是一个数据库,消耗了 2GB 的主内存(RSS),这是它从之前迁移的系统中配置的限制。
随着更多内存用于缓存工作数据,这些特征可能随时间变化。由于内存泄漏(软件错误)而导致的内核或应用程序内存也可能随时间持续增长,而不仅仅是常规缓存增长。
高级用法分析/检查清单
可能需要包含更多详细信息以更详细地了解使用情况。以下列出了一些考虑问题的问题,这些问题在彻底研究内存问题时也可以作为检查清单:
- 内核内存用于哪里?每个 slab?
- 文件系统缓存(或页面缓存)中有多少是活动的,而不是非活动的?
- 进程内存用于哪里?
- 为什么进程分配内存(调用路径)?
- 为什么内核分配内存(调用路径)?
- 哪些进程正在被分页/交换出?
- 哪些进程以前曾被分页/交换出?
- 进程或内核可能存在内存泄漏吗?
- 在 NUMA 系统中,内存分布在内存节点上的情况如何?
- CPI 和内存停顿周期率是多少?
- 内存总线平衡程度如何?
- 本地内存 I/O 相对于远程内存 I/O 执行了多少?
接下来的章节可以帮助回答其中的一些问题。请参阅第二章“方法论”,了解此方法论的更高级摘要以及要测量的特征(谁、为什么、什么、如何)。
7.4.4 Cycle Analysis
可以通过检查 CPU 性能计数器(CPCs)来确定内存总线负载,这些计数器可以被编程为计算内存停顿周期。它们也可以用来测量每指令周期(CPI),作为衡量 CPU 负载对内存依赖程度的一种指标。请参阅第六章“CPU”了解更多信息。
7.4.5 Performance Monitoring
性能监测可以识别长期内的活跃问题和行为模式。内存的关键指标包括:
- 利用率:已使用百分比,可以从可用内存中推断出
- 饱和度:页面扫描、交换、OOM kill
对于实施内存限制或配额(资源控制)的环境,还可能需要收集与施加限制相关的统计信息。
还可以监视错误(如果可用),这些错误在第7.4.2节“USE 方法”中与利用率和饱和度一起描述。
随时间监视内存使用情况,尤其是按进程监视,可以帮助识别内存泄漏的存在和速率。
7.4.6 Leak Detection
当应用程序或内核模块不断增长,从空闲列表、文件系统缓存,最终从其他进程中消耗内存时,就会出现这个问题。首次注意到这个问题是因为系统正在分页,以应对不断增长的内存压力。
这种问题可能是由以下原因引起的:
- 内存泄漏:一种软件缺陷,内存被遗忘但永远不会释放。可以通过修改软件代码或应用补丁或升级(修改代码)来解决。
- 内存增长:软件正常消耗内存,但速度远高于系统所需。可以通过更改软件配置或软件开发人员更改应用程序消耗内存的方式来解决。
内存增长问题经常被误认为是内存泄漏。首先要问的问题是:它是否应该那样做?检查配置。
如何分析内存泄漏取决于软件和语言类型。一些分配器提供调试模式,用于记录分配细节,然后可以在事后进行分析,以确定责任调用路径。开发人员还可以使用工具进行内存泄漏调查。
7.4.7 Static Performance Tuning
静态性能调优侧重于已配置环境的问题。对于内存性能,需要检查静态配置的以下方面:
- 总共有多少主内存?
- 应用程序配置为使用多少内存(它们自己的配置)?
- 应用程序使用哪些内存分配器?
- 主内存的速度是多少?它是最快的类型吗?
- 系统架构是什么?NUMA,UMA?
- 操作系统是否具有NUMA意识?
- 存在多少内存总线?
- CPU缓存的数量和大小是多少?TLB?
- 是否配置并使用了大页?
- 是否可用并进行了超额承诺?
- 其他系统内存可调参数正在使用吗?
- 是否存在软件规定的内存限制(资源控制)?
回答这些问题可能会揭示被忽视的配置选择。
7.4.8 Resource Controls
操作系统可能为内存分配给进程或进程组提供细粒度控制。这些控制可能包括主内存和虚拟内存使用的固定限制。它们的工作方式是特定于实现的,并在第7.6节“调优”中进行了讨论。
7.4.9 Micro-Benchmarking
微基准测试可用于确定主存储器的速度和CPU缓存以及缓存行大小等特性。在分析系统之间的差异时,它可能会有所帮助,因为内存访问速度可能对性能的影响大于CPU时钟速度,这取决于应用程序和工作负载。在第6章“CPU”中,在CPU缓存下的延迟部分(第6.4.1节),展示了微基准测试内存访问延迟的结果,以确定CPU缓存的特性。
7.5 Analysis
这一部分介绍了针对基于Linux和Solaris的操作系统的内存分析工具。请参阅前一部分,了解在使用它们时应遵循的策略。本节中的工具列在表7.4中。
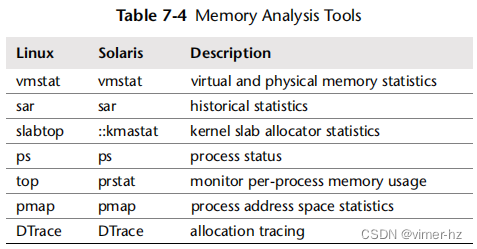
这是一些工具和功能的选择,用于支持第7.4节“方法论”,从系统范围的内存使用统计开始,然后深入到每个进程和分配的跟踪。请查看工具文档,包括man手册,以获取有关其功能的完整参考资料。此外,请参阅第8章“文件系统”,了解更多用于调查文件系统内存使用情况的工具。
虽然您可能只关注基于Linux或Solaris的系统,但请考虑其他操作系统工具以及它们提供的可观察性,以获得不同的视角。
7.5.1 vmstat
虚拟内存统计命令vmstat提供了系统内存健康状况的高层视图,包括当前空闲内存和分页统计信息。CPU统计信息也包括在内,如第6章“CPU”所述。
这个命令是由Bill Joy和Ozalp Babaoglu于1979年为BSD引入的。最初的man手册包括一个BUGS部分:打印出来的数字太多,有时很难弄清楚要观察什么。许多列自第一个版本以来基本保持不变,特别是对于Solaris。接下来的部分将展示Linux和基于Solaris的版本的列和选项。
Linux
以下是示例输出:
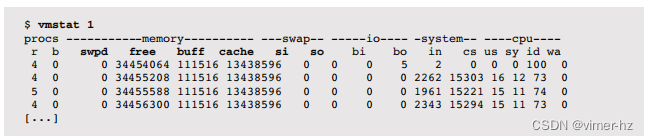
这个vmstat(8)版本在输出的第一行不打印自引导以来内存列的总结数值,而是立即显示当前状态。默认情况下,这些列的单位是千字节,并分别表示以下内容:
- swpd: 交换出的内存量
- free: 可用空闲内存
- buff: 缓冲区中的内存
- cache: 页面缓存中的内存
- si: 交换入的内存(分页)
- so: 交换出的内存(分页)
缓冲区和页面缓存在第8章“文件系统”中有描述。在系统引导后,系统中的可用空闲内存通常会减少,并被这些缓存使用以提高性能。当需要时,它可以被释放供应用程序使用。如果si和so列持续不为零,说明系统面临内存压力,并且正在向交换设备或文件进行分页(参见swapon(8))。可以使用其他工具,包括按进程查看内存使用情况,来调查内存的消耗情况。在拥有大量内存的系统上,这些列可能会变得不对齐并且有点难以阅读。您可以尝试使用-S选项将输出单位更改为兆字节。

还有一个-a选项,用于打印页面缓存中不活跃和活跃内存的详细信息:

可以使用-s选项将这些内存统计信息打印为列表。
Solaris
在基于Solaris的系统上,vmstat(1)命令更接近于BSD的原始版本。有许多字段显示了页面写出守护程序的活动情况,这对于尚未了解页面扫描器内部工作原理的用户来说可能有点不太友好。
以下是示例输出:

在拥有大量内存的系统上,这些列可能会变得不对齐。输出的第一行是自引导以来的总结情况。与内存相关的列包括:
- w: 被交换出的线程数
- swap: 可用虚拟内存(千字节)
- free: 可用空闲内存,包括页面缓存和空闲列表(千字节)
- re: 从页面缓存中回收的页面(缓存命中)
- mf: 小错误
- pi: 分页进入的内存,所有类型(千字节)
- po: 分页出去的内存,所有类型(千字节)
- fr: 页面缓存内存由页面扫描器或文件系统释放(千字节)
- de: 不足—预期的短期内存不足(千字节)(参见第7.3.2节“软件”的Solaris部分)
- sr: 被页面写出守护程序扫描的页面
示例输出显示了一个过去曾经出现问题的系统,有113个线程被交换出(w)。页面扫描器目前没有运行(sr),因此系统目前没有过多的内存压力。有少量的页面进入(pi),尽管它们可能是正常的(文件系统)或异常的(匿名)。-p选项显示了页面进入、页面退出和释放的详细情况:
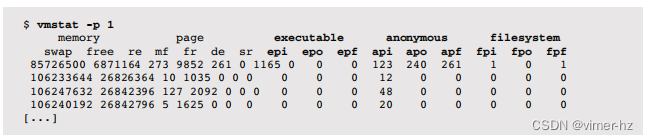
该系统存在匿名页面进入的频率(api),这是“不良”的分页行为。这会在应用程序运行时引起同步磁盘I/O级别的延迟。在这种情况下,这可能是由于先前的内存压力事件导致了内存页面出去,而活动线程目前正在被重新分页回来。
如果需要的话,可以通过kstat针对每个CPU观察许多这些统计信息。请参阅cpu::vm:统计数据组。kstat是在第4章“可观测性工具”中介绍的。
系统启动后,可用空闲内存(free)下降是正常的,因为内存被页面缓存和其他内核缓存使用。当需要时,这部分内存可以返回给应用程序使用。系统持续进行分页扫描(sr)并不正常,这是内存压力问题的迹象。如果是这种情况,请使用其他工具(例如按进程查看内存使用情况)来查看内存的使用情况。
7.5.2 sar
系统活动报告工具sar(1)可用于观察当前活动,并可配置为存档和报告历史统计数据。在本书的各个章节中提到了它,因为它提供了不同的统计信息。
Linux
Linux版本通过以下选项提供内存统计信息:
- B: 分页统计
- H: 大页面统计
- r: 内存利用率
- R: 内存统计
- S: 交换空间统计
- W: 交换统计
这些选项涵盖了内存使用情况、页面写出守护程序的活动以及大页面的使用情况。有关这些主题的背景,请参阅第7.3节“架构”。
提供的统计数据包括表7.5中列出的内容。

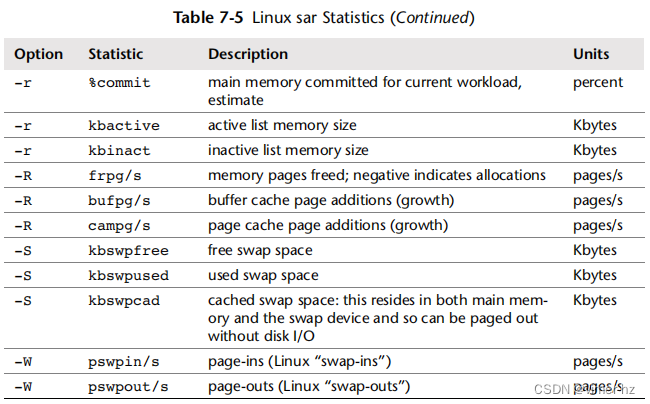
许多统计名称包括衡量单位:pg表示页面,kb表示千字节,%表示百分比,/s表示每秒。请查阅man手册获取完整列表,其中包括一些额外的基于百分比的统计数据。
重要的是要记住,在需要时可以获得关于高级内存子系统的使用和操作的如此详细的信息。要更深入地了解这些信息,您可能需要浏览mm目录下特定的源代码文件mm/vmscan.c。此外,linux-mm邮件列表中有许多帖子提供了进一步的见解,开发人员在讨论统计数据应该是什么。
%vmeff指标是页面回收效率的一个有趣的度量。高值表示页面成功从非活动列表中被窃取(健康);低值表示系统正在努力应对。man手册将近100%描述为高效,小于30%描述为低效。
Solaris版本提供以下选项:
- g: 分页统计
- k: 内核内存分配统计
- p: 分页活动
- r: 未使用内存指标
- w: 交换统计
这些选项涵盖了内存使用、内核分配、分页和交换等内容。有关这些主题的背景,请参阅第7.3节“架构”。
提供的统计数据包括表7.6中列出的内容。

将“-k”分解为“small”和“large”池在今天看来似乎有些不同寻常。我怀疑这是一个历史遗留问题,支持SVR4的延迟伙伴分配器所使用的大内存池和小内存池[Vahalia 96]。
更多有关内存子系统的统计信息可以通过kstat读取,或者使用DTrace动态构建。
7.5.3 slabtop
Linux的slabtop(1)命令从slab分配器中打印内核slab缓存的使用情况。类似于top(1),它实时刷新屏幕。
以下是一些示例输出:
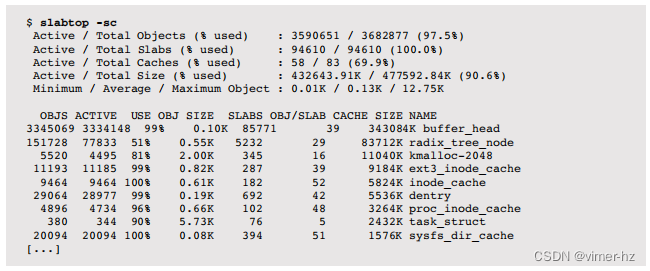
输出内容顶部有一个摘要,下面是一个slab列表,包括它们的对象数量(OBJS)、活跃对象数量(ACTIVE)、使用百分比(USE)、对象大小(OBJ SIZE,字节)和缓存的总大小(CACHE SIZE,字节)。
在这个例子中,使用了-sc选项按缓存大小排序,最大的在顶部。
这些slab统计数据来自/proc/slabinfo,也可以使用vmstat -m打印出来。
7.5.4 ::kmastat
在基于Solaris的系统上,用于mdb(1)的::kmastat调试器命令(dcmd)总结了内核内存的使用情况。输出分为三部分:slab分配器缓存使用情况、使用摘要和vmem使用摘要。
以下是一些示例输出:


输出内容超过了500行,这里进行了截断。尽管冗长,但在追踪内核内存增长的源头时可能是非常宝贵的。
其他有用的与内存相关的dcmd包括::kmem_slabs、::kmem_slabs -v和::memstat。例如:

虽然这是一个有用的摘要,但缺点是您必须是超级用户(root)并且正在运行mdb -k才能查看它。
7.5.5 ps
进程状态命令ps(1)列出了所有进程的详细信息,包括内存使用统计数据。其用法在第六章“CPU”中介绍。
例如,使用BSD风格选项:
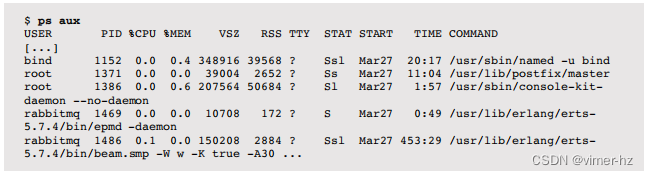
这些输出包括以下列:
- %MEM:主内存使用量(物理内存,RSS)占系统总量的百分比
- RSS:常驻集大小(KB)
- VSZ:虚拟内存大小(KB)
尽管RSS显示了主内存的使用量,但它包括了诸如系统库之类的共享段,这些共享段可能被数十个进程映射。如果你对RSS列进行求和,你可能会发现它超过了系统中可用的内存,这是由于对这些共享内存的重复计数。请参阅后面的pmap(1)命令以分析共享内存的使用情况。
可以使用SVR4风格的-o选项选择这些列,例如:

Linux版本还可以打印主要和次要错误列(maj_flt,min_flt)。
在Solaris上,主要和次要错误信息可以在/proc中找到,但目前未从ps(1)中公开。另外请注意,aux输出中存在一个bug,导致RSS和VSZ列可能会合并——缺少空格分隔符。这个问题在最近的illumos/SmartOS中已经修复。
ps(1)的输出可以在内存列上进行后排序,以便快速识别消耗最高的进程。或者尝试使用top(1)和prstat(1M)工具,它们提供了排序选项。
7.5.6 top
top(1)命令监视当前运行的前几个进程,并包括内存使用统计数据。它在第六章“CPU”中介绍。例如,在Linux系统中:
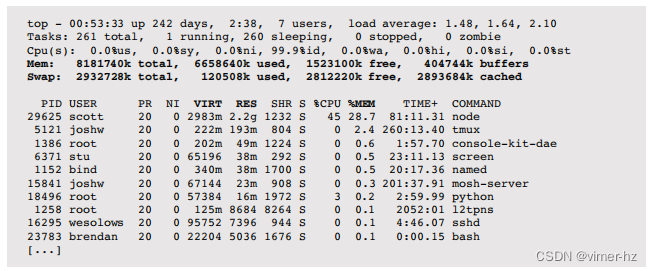
顶部的摘要显示了主内存(Mem)和虚拟内存(Swap)的总量、已使用量和空闲量。同时也显示了缓冲缓存(buffers)和页面缓存(cached)的大小。
在这个例子中,通过配置top命令并改变排序顺序,按%MEM对每个进程的输出进行了排序。在这个例子中,最大的进程是node,它使用了2.2 GB的主内存和将近3 GB的虚拟内存。
主内存百分比列(%MEM)、虚拟内存大小(VIRT)和常驻集大小(RES)的含义与之前描述的ps(1)中相应的列相同。
7.5.7 prstat
prstat(1M)命令是为基于Solaris的系统引入的类似于top的工具,并在第6章“CPU”中介绍过。例如:
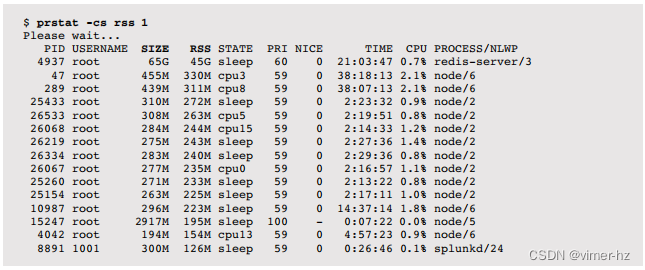
在这个例子中,排序顺序被设置为RSS(-s rss),以便将最大的内存消耗者列在顶部。进程名为redis-server的进程远远是最大的,占用45 GB的主内存(RSS)和65 GB的虚拟内存(SIZE)。
prstat(1M)可以打印微状态账户统计信息,其中包括文本和数据错误时间。对于这台服务器:

这个庞大的redis-server进程在等待数据错误(DFL)的时间百分比较高。这是之前vmstat -p示例中显示匿名页面换入率的相同服务器,这两者可能有关联:系统内存可能不足,将redis-server换出,并且现在正在等待(DFL)将其换回。
7.5.8 pmap
pmap(1)命令列出了进程的内存映射,显示它们的大小、权限和映射的对象。这允许更详细地检查进程的内存使用情况,并量化共享内存。例如,在基于Solaris的系统上:

这显示了一个PostgreSQL数据库的内存映射,包括虚拟内存(Kbytes)、主内存(RSS)、私有匿名内存(Anon)和权限(Mode)。对于大多数映射,很少有内存是匿名的,大部分是只读(r-x),这意味着这些页面可以与其他进程共享。这在系统库中尤其如此。这个例子中消耗的大部分内存位于一个共享内存段(ism)中。
Linux版本的pmap(1)类似,并基于Solaris版本。更新的版本使用Dirty一词代替Anon。
Solaris版本提供了一个-s选项来显示映射的页面大小:

这个PostgreSQL数据库的共享内存段主要使用了2兆字节的页面。
pmap(1)的输出对于具有许多映射的进程来说可能很长。它在报告内存使用情况时会暂停进程,这可能会影响正在进行的活动工作的性能。它在需要诊断和分析时很有用,但不应作为定期监控工具定期运行。
7.5.9 DTrace
DTrace可以用于跟踪用户级和内核级分配、次要和主要页面错误,以及页面换出守护进程的操作。这些功能支持对使用情况的表征和深入分析。
以下各节介绍了在基于Solaris和Linux的系统上进行内存分析的DTrace。除非另有说明,DTrace命令适用于两个操作系统。DTrace入门内容已包含在第4章“可观察性工具”中。
分配跟踪
如果可用,可以使用pid提供程序跟踪用户级分配器。这是一个动态跟踪提供程序,这意味着软件可以在任何时刻进行插装,无需重新启动,也无需事先配置分配器以运行在调试模式下。
以下示例总结了对malloc()调用的请求大小,针对PID 15041(一个Riak数据库):

所有请求的分配大小介于512字节和16,383字节之间,大部分在1-2 K字节的范围内。
这个一行代码总结了malloc()的请求字节数,即将第一个参数(arg0)传递给二次幂quantize()聚合函数。如果需要,还可以跟踪malloc()的返回值,以检查分配是否成功。
关键是将其设置为“请求字节”,仅用于使用ustack()动作装饰输出时包含用户级堆栈跟踪。

在这种情况下,输出非常长,已经被截断以适应。它显示了导致分配的用户级堆栈跟踪,以及请求分配大小的分布情况。
由于分配是频繁发生的活动,尽管每个事件的追踪速度很快,但在追踪过程中成本可能会累积,并引起性能开销。
还可以调查用户级分配器的其他内部情况。例如,列出libumem分配器的入口探测点:

输出列出了163个入口探测点。这些可以用于构建更复杂的一行代码和脚本,以调查分配器的内部情况。
内核级分配器可以使用类似的方式进行跟踪,使用动态fbt提供程序。例如,在基于Solaris的系统上,以下一行代码跟踪slab分配器:

输出包括缓存的名称,后跟用于分配的内核堆栈跟踪,然后是跟踪时的计数。
以下一行代码展示了跟踪用户级和内核级分配器的不同方式。
一行代码示例
总结进程PID的用户级malloc()请求大小:
![]()
总结进程PID的带调用堆栈的用户级malloc()请求大小:
![]()
统计libumem函数调用次数:
![]()
统计用户级堆增长(通过brk()函数)的堆栈数:
![]()
跟踪Solaris系统中按缓存名称和堆栈跟踪的内核级slab分配:

故障跟踪
页面错误的跟踪可以进一步揭示系统如何提供内存。 可以使用动态fbt提供程序或可用的稳定vminfo提供程序来执行此操作。
例如,在基于Solaris的系统上,以下一行代码跟踪名为"beam.smp"的进程(这是 Erlang VM,在本例中运行 Riak 数据库)的次要错误,并统计用户级堆栈跟踪,深度为五层:

这总结了消耗内存并引起次要错误的代码路径。在这种情况下,是 Erlang 垃圾回收代码。也可以使用vminfo:::maj_fault探测点跟踪主要错误。
另一个有用的与故障相关的探测点是vminfo:::anonpgin,用于匿名页面导入。例如:

这条跟踪了系统范围内的匿名页面导入,统计了进程ID和进程名称。这与之前vmstat(1)示例所展示的相同系统,该示例确定了匿名页面导入,并且与prstat(1M)示例相同,该示例确定了redis-server在数据错误中花费的时间。这个DTrace一行代码连接了这些信息,确认了redis-server正花费时间在匿名页面导入上,这是由于系统内存不足和分页引起的。
页面输出守护进程
如果需要,也可以使用fbt提供程序跟踪页面输出守护进程的内部操作。具体操作取决于内核版本。
7.5.10 SystemTap
在Linux系统上,也可以使用SystemTap进行文件系统事件的动态跟踪。请参阅第4章“可观测性工具”中的第4.4节“SystemTap”,以及附录E,了解如何将之前的DTrace脚本转换为SystemTap脚本。
7.5.11 Other Tools
其他Linux内存性能工具包括以下内容:
- free:报告空闲内存,包括缓冲区缓存和页面缓存(请参阅第8章“文件系统”)。
- dmesg:检查来自OOM killer的“内存不足”消息。
- valgrind:一个性能分析套件,包括memcheck,用于内存使用分析和泄漏检测的用户级分配器包装器。这会带来显著的开销;手册建议可能导致目标运行速度减慢20到30倍。
- swapon:用于添加和观察物理交换设备或文件。
- iostat:如果交换设备是物理磁盘或分区,可以使用iostat(1)观察设备I/O,指示系统正在分页。
- perf:在第6章“CPU”中介绍,可用于调查CPI、MMU/TSB事件以及来自CPU性能测试计数器的内存总线停顿周期。它还提供用于页面故障和多个内核内存(kmem)事件的探针。
- /proc/zoneinfo:内存区域(NUMA节点)的统计信息。
- /proc/buddyinfo:内核伙伴分配器页面的统计信息。
其他Solaris内存性能工具包括以下内容:
- prtconf:显示已安装物理内存大小(可以使用|grep Mem或在更新版本中使用-m进行过滤)。
- prtdiag:显示物理内存布局(适用于支持的系统)。
- swap:交换统计信息:列出交换设备(-l),并总结使用情况(-s)。
- iostat:如果交换设备是物理磁盘或分区,可以使用iostat(1)观察设备I/O,指示系统正在分页或交换。
- cpustat:在第6章“CPU”中介绍,可用于调查CPI、MMU/TSB事件以及来自CPU性能测试计数器的内存总线停顿周期。
- trapstat:打印陷阱统计信息,包括不同页面大小的TLB/TSB缺失率和消耗的CPU百分比。目前仅在SPARC处理器上受支持。
- kstat:包含更多统计信息,用于了解内核内存使用情况。对于其中大多数内容,唯一的文档是源代码(如果可用)。
应用程序和虚拟机(例如Java虚拟机)也可能提供自己的内存分析工具。请参阅第5章“应用程序”。
一些分配器维护自己的统计信息以便观察。例如,可以使用Solaris上的mdb(1) dcmds来调查libumem库。


这显示了::vmem,它打印了由libumem使用的内部虚拟内存结构及其使用情况,以及::umem_malloc_info,它显示按缓存分配的统计信息,可以指示内存按大小的使用模式(将BUFSZ与MALLOCED进行比较)。虽然只提供基本属性,但这些命令可以揭示通常是不透明的进程堆中的情况。
7.6 Tuning
最重要的内存调优是确保应用程序保持在主内存中,避免频繁发生分页和交换。识别这个问题已经在第7.4节“方法论”和第7.5节“分析”中讨论过。本节讨论其他内存调优内容:内核可调参数、配置大页面、分配器和资源控制。
调优的具体内容——可用的选项以及如何设置它们——取决于操作系统版本和预期的工作负载。下面按调优类型组织的各节提供了可能可用的示例,以及为什么可能需要进行调优。
7.6.1 Tunable Parameters
这一部分描述了最近的Linux和基于Solaris的内核的可调参数示例。
Linux
各种内存可调参数在内核源代码文档Documentation/sysctl/vm.txt中有描述,并可以使用sysctl(8)进行设置。表7.7中的示例来自3.2.6内核,其中默认值来自Fedora 16。

这些可调参数采用了包含单位的一致命名方案。请注意,dirty_background_bytes和dirty_background_ratio是互斥的,同样dirty_bytes和dirty_ratio也是互斥的(只能设置一个)。
vm.min_free_kbytes的大小会动态设置为主内存的一部分。选择此数值的算法并非线性,因为空闲内存需求与主内存大小并不呈线性比例关系(有关详细信息,请参阅mm/page_alloc.c中的文档)。vm.min_free_kbytes可以减少以释放一些内存供应用程序使用,但这也可能导致在内存压力下内核被迫更早地使用OOM。
另一个避免OOM(Out of Memory)的参数是vm.overcommit_memory,可以将其设置为2以禁用过度承诺,并避免导致OOM的情况发生。如果希望根据每个进程进行OOM killer的控制,请查看您的内核版本是否具有/proc可调参数,例如oom_adj或oom_score_adj。这些内容应该在Documentation/filesystems/proc.txt中有所描述。
vm.swappiness可调参数在早于预期开始交换应用程序内存时可能会显著影响性能。该可调参数的值可以介于0和100之间,较高的值有利于交换应用程序,从而保留页面缓存。可能希望将其设置为零,以便尽可能长时间地保留应用程序内存,以牺牲页面缓存为代价。当仍然存在内存短缺时,内核仍然可以使用交换。
Solaris
表7.8显示了内存的关键可调参数,可以在/etc/system中设置,同时列出了典型的默认值。请参阅供应商文档以获取完整列表、设置说明、描述和警告。其中一些在图7.11中已经展示过。

可以使用pagesize(1)命令来确定这些单位的含义。
请注意,有时公司或供应商政策可能禁止调整内核可调参数(请先检查)。这些参数应该已经设置为适当的值,并且不需要进行调整。
对于大容量内存系统(超过100 GB),调整其中一些参数至较低值可能是值得的,以释放更多内存供应用程序使用。在具有多个存储设备(例如存储阵列)的系统中,可能需要增加maxpgio,以使队列长度更适合可用的I/O容量。
7.6.2 Multiple Page Sizes
大页面大小可以通过提高TLB缓存的命中率(增加其范围)来改善内存I/O性能。大多数现代处理器支持多种页面大小,例如4 K字节的默认大小和2 M字节的大页面。
在Linux上,可以以多种方式配置大页面(称为巨大页面)。有关详细信息,请参阅Documentation/vm/hugetlbpage.txt。
这些通常始于创建巨大页面:

一个应用程序使用巨大页面的方法是通过共享内存段,并在shmget()中使用SHM_HUGETLBS标志。
另一种方法涉及为应用程序创建基于巨大页面的文件系统,以便进行内存映射:

其他方法包括在mmap()中使用MAP_ANONYMOUS|MAP_HUGETLB标志,并使用libhugetlbfs API[4]。
最近,对透明巨大页面(THP)的支持已经得到开发。这在适当时使用巨大页面,无需系统管理员手动操作[5]。有关详细信息,请参阅Documentation/vm/transhuge.txt。
在基于Solaris的系统上,可以通过配置应用程序环境以使用libmpss.so.1库来配置大页面。例如:

这些可以被放置在应用程序的启动脚本中。大页面是由内核动态创建的,只有当有足够的页面可用来创建它们时才会成功(否则将使用默认的较小页面)。
使用Oracle Solaris Studio编译的程序可能会自动使用大页面,因此不需要手动预加载mpss。
7.6.3 Allocators
不同的用户级分配器可能可用,为多线程应用程序提供改进的性能。这些可以在编译时选择,也可以通过设置LD_PRELOAD环境变量在执行时选择。
例如,在Solaris上,可以使用libumem分配器进行选择
![]()
这可以放置在其启动脚本中。
7.6.4 Resource Controls
基本的资源控制,包括设置主内存限制和虚拟内存限制,可以使用ulimit(1)来实现。
对于Linux,容器组(cgroups)内存子系统提供各种额外的控制。其中包括
- memory.memsw.limit_in_bytes:允许的最大内存和交换空间,以字节为单位
- memory.limit_in_bytes:允许的最大用户内存,包括文件缓存使用量,以字节为单位
- memory.swappiness:类似于前面描述的vm.swappiness,但可以为cgroup设置
- memory.oom_control:可以设置为0,以允许为此cgroup启用OOM killer,或设置为1以禁用它
在基于Solaris的系统上,可以使用资源控制和prctl(1)命令应用每个区域或每个项目的内存限制。这些可以通过页面出内存来强制执行它们的限制,而不是失败的分配,这可能更适用于目标应用程序,具体内容请参见第11章云计算中的第11.2节OS虚拟化。
















 605
605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









