






在研究应用程序I/O性能时,文件系统的性能比磁盘性能更重要。文件系统使用缓存、缓冲和异步I/O来避免将应用程序暴露于磁盘级(或远程系统)的延迟中。然而,性能分析和可用的工具集通常过去主要关注磁盘的性能。
在动态跟踪的时代,文件系统分析现在变得简单和实用。本章展示了如何详细检查文件系统请求,包括使用动态跟踪从应用程序上下文中测量启动到完成时间。这通常可以快速排除文件系统及其底层磁盘设备作为性能不佳的源头,从而使调查可以转向其他领域。
本章由五部分组成,前三部分提供文件系统分析的基础,后两部分展示其在基于Linux和Solaris的系统中的实际应用。各部分内容如下:
- 背景介绍了与文件系统相关的术语、基本模型,说明文件系统原则和关键文件系统性能概念。
- 架构介绍了通用和特定的文件系统架构。
- 方法论描述了性能分析方法论,包括观察性和实验性方法。
- 分析展示了针对基于Linux和Solaris系统的文件系统性能工具,包括静态和动态跟踪。
- 调优描述了文件系统可调参数。
8.1 Terminology
在本章中使用的与文件系统相关的术语包括以下内容:
- 文件系统:将数据组织为文件和目录的一种方式,提供基于文件的接口来访问它们,并使用文件权限来控制访问。额外的内容可能包括用于设备、套接字和管道的特殊文件类型,以及包含文件访问时间戳等元数据。
- 文件系统缓存:主存储器(通常是DRAM)中用于缓存文件系统内容的区域,可能包括不同的缓存用于各种数据和元数据类型。
- 操作:文件系统操作是对文件系统的请求,包括read()、write()、open()、close()、stat()、mkdir()和其他操作。
- I/O:输入/输出。文件系统I/O可以用多种方式定义;这里仅表示直接读取和写入(执行I/O)的操作,包括read()、write()、stat()(读取统计信息)和mkdir()(写入新目录条目)。I/O不包括open()和close()。
- 逻辑I/O:应用程序向文件系统发出的I/O。
- 物理I/O:由文件系统直接(或通过原始I/O)发出到磁盘的I/O。
- 吞吐量:应用程序与文件系统之间的当前数据传输速率,以每秒字节数为单位衡量。
- inode:索引节点(inode)是一个包含文件系统对象元数据的数据结构,包括权限、时间戳和数据指针。
- VFS:虚拟文件系统,是一个内核接口,用于抽象和支持不同的文件系统类型。在Solaris中,VFS inode被称为vnode。
- 卷管理器:用灵活的方式管理物理存储设备的软件,从中创建虚拟卷供操作系统使用。
本章还介绍了其他术语。术语表包括用于参考的基本术语,包括fsck、IOPS、操作速率和POSIX。另请参阅第2章和第3章的术语部分。
8.2 Models
以下简单模型说明了文件系统及其性能的一些基本原理。
8.2.1 File System Interfaces
图8.1展示了一个文件系统的基本模型,涉及到其接口。

在图中还标记了逻辑和物理操作发生的位置。有关这些内容的更多信息,请参阅第8.3.12节《逻辑I/O与物理I/O》。研究文件系统性能的一种方法是将其视为黑匣子,重点放在对象操作的延迟上。这在第8.5.2节《延迟分析》中有更详细的解释。
8.2.2 File System Cache
图8.2中展示了存储在主内存中的通用文件系统缓存,用于执行读取操作。读取操作可以从缓存中返回(缓存命中)或从磁盘中返回(缓存未命中)。缓存未命中的数据会被存储到缓存中,填充缓存(使其变热)。

文件系统缓存还可以缓冲待写入(刷新)的数据。对于不同的文件系统类型,执行这一操作的机制各不相同,具体描述请参见第8.4节《架构》。
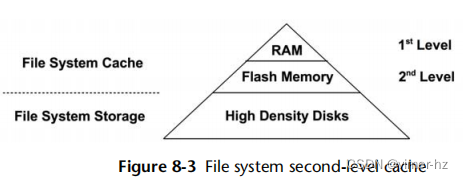
8.2.3 Second-Level Cache
二级缓存可以是任何内存类型;图8.3将其展示为闪存。这种缓存类型最初是为ZFS开发的。
8.3 Concepts
以下是关于文件系统性能的一些重要概念。
8.3.1 File System Latency
文件系统延迟是文件系统性能的主要度量标准,指的是从逻辑文件系统请求到完成所需的时间。它包括在文件系统、内核磁盘I/O子系统以及等待磁盘设备上花费的时间 — 即物理I/O。应用程序线程在应用程序请求期间通常会阻塞,等待文件系统请求完成,文件系统延迟直接且成比例地影响应用程序性能。
应用程序可能不直接受到影响的情况包括使用非阻塞I/O,或者当I/O是从异步线程(例如后台刷新线程)发出时。如果应用程序提供了其文件系统使用的详细指标,那么可以通过这些指标来识别这些情况。如果没有,一个通用的方法是使用可以显示导致逻辑文件系统I/O的用户级堆栈跟踪的内核跟踪工具。然后可以研究此堆栈跟踪,以查看是哪些应用程序例程发出了它。
操作系统在历史上并未使文件系统延迟易于观察,而是提供磁盘设备级别的指标。但有许多情况下,这些指标不会直接影响应用程序,使它们很难解释,甚至毫无意义。例如,文件系统执行写入数据的后台刷新,这可能会表现为高延迟磁盘I/O的突发。从磁盘设备级别的指标来看,这看起来令人担忧;然而,没有任何应用程序在等待这些操作完成。有关更多情况,请参阅第8.3.12节《逻辑I/O与物理I/O》。
8.3.2 Caching
启动后,文件系统通常会使用主内存(RAM)作为缓存以提高性能。对于应用程序来说,这个过程是透明的:它们的逻辑I/O延迟变得更低,因为可以从主内存中提供而不是从速度慢得多的磁盘设备中提供。
随着时间的推移,缓存会增长,而操作系统的空闲内存会减少。这可能会让新用户感到困扰,但这是完全正常的。原则是:如果有多余的主内存,就记住一些有用的东西。当应用程序需要更多内存时,内核应该迅速从文件系统缓存中释放空间供其使用。
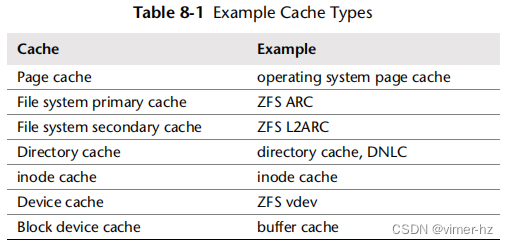
文件系统使用缓存来提高读取性能,并使用缓冲区(在缓存中)来提高写入性能。文件系统和块设备子系统通常会使用多种类型的缓存,其中可能包括表8.1中的缓存。具体的缓存类型在第8.4节“架构”中进行了描述,第3章“操作系统”列出了缓存的完整列表(包括应用程序级和设备级)。
8.3.3 Random versus Sequential I/O
一系列逻辑文件系统I/O操作可以根据每个I/O的文件偏移量描述为随机或顺序。顺序I/O中,下一个I/O从上一个I/O的末尾开始。随机I/O之间没有明显的关系,偏移量会随机变化。随机文件系统工作负载也可能指随机访问许多不同的文件。图8.4说明了这些访问模式,展示了有序的I/O系列和示例文件偏移量。

由于某些存储设备的性能特征(在第9章“磁盘”中描述),文件系统在历史上一直试图通过将文件数据连续和顺序地放置在磁盘上来减少随机I/O。碎片化一词描述了当文件系统执行不佳时,导致文件分布在驱动器上变得散乱,使得顺序逻辑I/O导致随机物理I/O。
文件系统可以测量逻辑I/O访问模式,以便它们可以识别顺序工作负载,然后使用预取或预读取来提高性能。接下来的部分将涵盖这些主题。
8.3.4 Prefetch
常见的文件系统工作负载涉及顺序读取大量文件数据,例如进行文件系统备份。这些数据可能太大而无法放入缓存,或者可能只读取一次,并且不太可能被保留在缓存中(取决于缓存淘汰策略)。这样的工作负载表现相对较差,因为它的缓存命中率较低。
预取是解决这个问题的常见文件系统特性。它可以基于当前和先前的文件I/O偏移量检测顺序读取工作负载,然后在应用程序请求数据之前预测并发出磁盘读取指令。这会填充文件系统缓存,因此如果应用程序确实执行了期望的读取操作,就会导致缓存命中(所需数据已经存在于缓存中)。
以下是一个示例场景,假设一开始没有数据被缓存:
1. 应用程序发出文件read()请求,将执行权交给内核。
2. 文件系统向磁盘发出读取指令。
3. 将先前的文件偏移量指针与当前位置进行比较,如果它们是顺序的,文件系统就会发出额外的读取指令。
4. 第一次读取完成,内核将数据和执行权交还给应用程序。
5. 任何额外的读取完成后,填充了缓存,以供未来应用程序读取使用。
这个场景也在图8.5中有所说明,应用程序首先读取偏移量1,然后触发对接下来的三个偏移量的预取。

当预取检测工作良好时,应用程序表现出显著提高的顺序读取性能;磁盘能够在应用程序请求之前提前读取数据。当预取检测效果不佳时,会发出不必要的I/O请求,这些请求是应用程序不需要的,会污染缓存并消耗磁盘和I/O传输资源。文件系统通常允许根据需要调整预取设置。
8.3.5 Read-Ahead
在历史上,预取功能也被称为read-ahead。更近期,Linux采用了read-ahead这个术语作为系统调用readahead(2),该系统调用允许应用程序明确地预热文件系统缓存。
8.3.6 Write-Back Caching
写回缓存通常被文件系统用来提高写入性能。它的工作方式是将写入视为在传输到主内存后完成,并稍后异步地将其写入磁盘。文件系统处理将这些“脏”数据写入磁盘的过程称为刷新。一个示例序列如下:
1. 应用程序发出文件write()请求,将执行权交给内核。
2. 来自应用程序地址空间的数据被复制到内核中。
3. 内核将write()系统调用视为已完成,并将执行权返回给应用程序。
4. 稍后,异步的内核任务找到已写入的数据并发出磁盘写入操作。
这种折衷是可靠性。基于DRAM的主内存是易失性的,在断电事件发生时,即使应用程序认为写入已完成,脏数据也可能会丢失。它也可能未完全写入磁盘,留下一个磁盘上状态损坏的情况。
如果文件系统元数据损坏,文件系统可能无法加载。这种状态可能只能从系统备份中恢复,导致长时间的停机时间。更糟糕的是,如果损坏影响应用程序读取和使用的文件内容,业务可能会受到威胁。
为了平衡速度和可靠性的需求,文件系统可以默认提供写回缓存,并提供同步写选项以绕过此行为直接写入持久存储设备。
8.3.7 Synchronous Writes
同步写入只有在完全写入持久存储(例如磁盘设备)时才算完成,这包括写入任何必要的文件系统元数据更改。与异步写入(写回缓存)相比,同步写入要慢得多,因为同步写入会产生磁盘设备I/O延迟。一些应用程序,如数据库日志编写器,使用同步写入,因为异步写入可能导致数据损坏风险不可接受。
同步写入有两种形式:单个I/O是同步写入,以及先前写入的组合是同步提交。
单个同步写入
当使用标志O_SYNC或其变体之一O_DSYNC和O_RSYNC(截至Linux 2.6.31时由glib映射为O_SYNC)打开文件时,写入I/O是同步的。一些文件系统具有挂载选项,强制所有文件的写入I/O都是同步的。
同步提交先前的写入
应用程序可以在代码中的检查点处同步提交先前的异步写入,而不是同步写入单个I/O,使用fsync()系统调用。这可以通过分组同步写入来提高性能。
还有其他情况会提交先前的写入,例如关闭文件句柄,或者文件上存在太多未提交的缓冲区时。前一种情况在解压包含许多文件的归档文件时经常会注意到,特别是在NFS上。
8.3.8 Raw and Direct I/O
这些是应用程序可能使用的其他类型的I/O:
原始I/O直接发出到磁盘偏移量,完全绕过文件系统。一些应用程序,特别是数据库,可以比文件系统缓存更好地管理和缓存它们自己的数据而使用原始I/O。一个缺点是管理上的困难:常规文件系统工具集无法用于备份/恢复或可观性。
直接I/O允许应用程序使用文件系统但绕过文件系统缓存。这类似于同步写入(但不提供O_SYNC提供的保证),它也适用于读取。它不像原始设备I/O那样直接,因为文件偏移量到磁盘偏移量的映射仍然必须由文件系统代码执行,I/O也可能被调整大小以匹配文件系统用于磁盘布局的大小(其记录大小)。根据文件系统的不同,这不仅会禁用读取缓存和写入缓冲,还可能禁用预取。
直接I/O可用于执行文件系统备份的应用程序,以避免将只读取一次的数据污染文件系统缓存。原始I/O和直接I/O均可用于避免双重缓存,适用于在进程堆中使用自己的应用程序级缓存的应用程序。
8.3.9 Non-Blocking I/O
通常,文件系统I/O要么立即完成(例如,来自缓存),要么在等待一段时间后完成(例如,等待磁盘设备I/O)。如果需要等待,应用程序线程将被阻塞并释放CPU,允许其他线程在等待期间执行。虽然被阻塞的线程无法执行其他工作,但这通常不是问题,因为多线程应用程序可以创建额外的线程来执行,而有些线程被阻塞。
在某些情况下,非阻塞I/O是可取的,例如当需要避免线程创建的性能或资源开销时。可以通过在open()系统调用中使用O_NONBLOCK或O_NDELAY标志来执行非阻塞I/O,这会导致读取和写入返回EAGAIN错误而不是阻塞,告诉应用程序稍后再试。 (对此的支持取决于文件系统,该文件系统可能只针对咨询或强制文件锁而支持非阻塞。)非阻塞I/O也在第5章“应用程序”中进行了讨论。
8.3.10 Memory-Mapped Files
对于某些应用程序和工作负载,可以通过将文件映射到进程地址空间并直接访问内存偏移量来改善文件系统I/O性能。这样可以避免在调用read()和write()系统调用以访问文件数据时产生的系统调用执行和上下文切换开销。如果内核支持直接将文件数据缓冲区复制到进程地址空间,还可以避免数据的双重复制。
内存映射是使用mmap()系统调用创建的,并使用munmap()删除。可以使用madvise()对映射进行调优,如第8.8节“调优”中总结的那样。一些应用程序在其配置中提供了使用mmap系统调用的选项(可能称为“mmap模式”)。例如,Riak数据库可以使用mmap来进行内存数据存储。
我注意到人们倾向于在分析问题之前尝试使用mmap()来解决文件系统性能问题。如果问题是来自磁盘设备的高I/O延迟,那么通过mmap()避免小的系统调用开销可能意义不大,因为高磁盘I/O延迟仍然存在并且占主导地位。
在多处理器系统上使用映射的一个缺点是保持每个CPU的MMU同步的开销,特别是用于移除映射的CPU交叉调用(TLB shootdowns)。根据内核和映射的不同,这些开销可以通过延迟TLB更新(延迟shootdowns)[Vahalia 96]来最小化。
8.3.11 Metadata
数据描述文件和目录的内容,而元数据描述与它们有关的信息。元数据可能指的是可以从文件系统接口(POSIX)读取的信息,或者实现磁盘上文件系统布局所需的信息。这分别称为逻辑元数据和物理元数据。
逻辑元数据
逻辑元数据是由消费者(应用程序)读取和写入文件系统的信息,可以通过以下方式进行:
- 明确地:读取文件统计信息(stat()),创建和删除文件(creat(),unlink())和目录(mkdir(),rmdir())
- 隐式地:文件系统访问时间戳更新,目录修改时间戳更新
一个“元数据密集型”的工作负载通常指的是逻辑元数据,例如,Web服务器使用stat()函数检查文件是否自缓存以来未更改的频率远高于实际读取文件数据内容。
物理元数据
物理元数据是指在磁盘上记录所有文件系统信息所必需的元数据。所使用的元数据类型取决于文件系统类型,可能包括超级块、inode、数据指针块(主要的、次要的等),以及空闲列表。
逻辑和物理元数据是逻辑I/O和物理I/O之间差异的原因之一。
8.3.12 Logical versus Physical I/O
尽管这可能看起来违反直觉,应用程序向文件系统请求的I/O(逻辑I/O)可能与磁盘I/O(物理I/O)不匹配,原因有几个。文件系统做的远不止提供持久存储(磁盘)作为基于文件的接口。它们会缓存读取、缓冲写入,并创建额外的I/O 来维护需要记录一切位置的磁盘上物理布局元数据。这可能导致与应用程序I/O 不相关、间接、膨胀或紧缩的磁盘I/O。以下是一些示例。
不相关
这是与应用程序无关的磁盘I/O,可能是由于以下因素:
- 其他应用程序:磁盘I/O 来自另一个应用程序。
- 其他租户:磁盘I/O 来自另一个租户(在某些虚拟化技术下可通过系统工具看到)。
- 其他内核任务:例如,当内核正在重建软件RAID卷或执行异步文件系统校验和验证(请参见8.4节,体系结构)。
间接
这是应用程序I/O 没有直接对应的磁盘I/O,可能是由于以下因素:
- 文件系统预取:添加可能或可能不被应用程序使用的额外I/O。
- 文件系统缓冲:使用写回缓存延迟和合并写入以后刷新到磁盘。一些系统可能在写入前缓冲数十秒,然后以大且不经常的突发形式出现。
紧缩
这是磁盘I/O 小于应用程序I/O,甚至不存在的情况,可能是由于以下因素:
- 文件系统缓存:从主存储器中满足读取而不是磁盘。
- 文件系统写取消:相同的字节偏移在刷新到磁盘之前多次修改。
- 压缩:将逻辑I/O 数据量减少至物理I/O。
- 合并:在发送给磁盘之前合并顺序I/O。
- 内存中文件系统:内容可能永远不会写入磁盘(例如tmpfs)。
膨胀
在这种情况下,磁盘I/O 大于应用程序I/O,可能是由于以下因素:
- 文件系统元数据:添加额外的I/O。
- 文件系统记录大小:调整I/O 大小(增加字节),或分片I/O(增加计数)。
- 卷管理器奇偶校验:读-修改-写循环,添加额外的I/O。
示例
为了展示这些因素如何同时发生,以下列举的示例描述了应用程序进行1字节写入时可能发生的情况:
1. 应用程序对现有文件执行1字节写入。
2. 文件系统将该位置识别为128KB文件系统记录的一部分(未缓存,但其元数据已被引用)。
3. 文件系统请求从磁盘加载记录。
4. 磁盘设备层将128KB读取分成适合设备的较小读取。
5. 磁盘执行多个较小读取,总计128KB。
6. 文件系统现在将记录中的1字节替换为新字节。
7. 一段时间后,文件系统请求将128KB脏记录写回磁盘。
8. 磁盘写入128KB记录(如有必要,进行分解)。
9. 文件系统写入新的元数据,例如引用(用于写时复制)或访问时间。
10. 磁盘执行更多写入。
因此,虽然应用程序只执行了单个1字节写入,但磁盘执行了多次读取(总计128KB)和更多写入(超过128KB)。
8.3.13 Operations Are Not Equal
正如前面的部分所述,文件系统操作的性能可能会根据它们的类型而有所不同。仅仅从速率来看,你无法判断“每秒500次操作”的工作负载情况。一些操作可能会从文件系统缓存以主存储器速度返回,而另一些可能会从磁盘返回,速度慢得多。其他确定性因素包括操作是随机的还是顺序的,是读取还是写入,是同步写入还是异步写入,它们的I/O大小,是否包含其他操作类型,以及它们的CPU执行成本。
常见做法是对不同的文件系统操作进行微基准测试,以确定这些性能特征。例如,表8.2中的结果来自一个在Intel Xeon 2.4 GHz多核处理器上的ZFS文件系统。

这些测试没有涉及存储设备,而是测试文件系统软件和CPU速度。一些特殊的文件系统从不访问存储设备。
8.3.14 Special File Systems
文件系统的目的通常是持久存储数据,但也有用于其他目的的特殊文件系统类型,包括临时文件(/tmp)、内核设备路径(/dev)和系统统计信息(/proc)。
8.3.15 Access Timestamps
许多文件系统支持访问时间戳,记录每个文件和目录的访问(读取)时间。这会导致在读取文件时更新文件元数据,从而产生写入工作负载,消耗磁盘I/O资源。第8.8节“调整”展示了如何关闭这些更新。一些文件系统通过延迟和分组访问时间戳写入来优化,以减少对活动工作负载的干扰。
8.3.16 Capacity
当文件系统填满时,性能可能会因为几个原因而下降。在写入新数据时,可能需要更多时间来定位磁盘上的空闲块以进行计算,并执行任何磁盘I/O操作。磁盘上的空闲空间很可能更小,分布更稀疏,这会导致由于更小的I/O或随机I/O而降低性能。这个问题有多严重取决于文件系统类型、其在磁盘上的布局和存储设备。接下来的部分将介绍各种文件系统类型。
8.4 Architecture
本节介绍通用和特定的文件系统架构,从I/O堆栈、VFS、文件系统缓存和特性、常见文件系统类型、卷和池开始。在确定要分析和优化哪些文件系统组件时,这样的背景知识非常有用。要了解更深入的内部结构和其他文件系统主题,请参考源代码(如果可用)和外部文档。本章末尾列出了一些相关资源。
8.4.1 File System I/O Stack

图8.6展示了文件系统I/O堆栈的一般模型。具体的组件和层取决于操作系统类型、版本和使用的文件系统。完整的图表请参见第3章“操作系统”。这显示了I/O通过内核的路径。从系统调用直接到磁盘设备子系统的路径称为原始I/O。通过VFS和文件系统的路径是文件系统I/O,包括跳过文件系统缓存的直接I/O。
8.4.2 VFS
VFS(虚拟文件系统接口)为不同的文件系统类型提供了一个通用接口。其位置显示在图8.7中。

一些操作系统(包括最初的SunOS实现)将VFS视为两个接口:VFS和vnode,如在早期文件系统模型中逻辑上划分的那样[McDougall 06a]。VFS包括文件系统范围的操作,如挂载和卸载。vnode接口包括VFS索引节点(vnode)文件操作,例如打开、关闭、读取和写入。
Linux VFS接口使用的术语可能有点令人困惑,因为它重用术语inode和superblock来引用VFS对象,这些术语源自Unix文件系统的磁盘数据结构。Linux中用于描述这些对象的术语磁盘数据结构通常以它们的文件系统类型作为前缀,例如,ext4_inode 和 ext4_super_block。这些 VFS 索引节点和 VFS 超级块仅存在于内存中。
VFS 接口还可以作为衡量任何文件系统性能的共同位置。通过使用操作系统提供的统计信息或静态或动态跟踪,可能可以实现这一点。
8.4.3 File System Caches
Unix最初只有缓冲高速缓存来提高块设备访问性能。如今,Linux和Solaris拥有多种不同类型的高速缓存。
本节从基于Solaris系统开始,讨论其中一些高速缓存的起源。
Solaris
图8.8显示了基于Solaris系统的文件系统缓存概况,显示了UFS和ZFS的缓存。

这些高速缓存中有三个是操作系统通用的:旧缓冲高速缓存、页面高速缓存和目录名称缓存(DNLC)。其余的是特定于文件系统的,稍后会进行解释。
旧缓冲高速缓存
最初的Unix在块设备接口处使用缓冲高速缓存来缓存磁盘块。这是一个单独的、固定大小的高速缓存,并且随着页面高速缓存的添加,在平衡它们之间的不同工作负载以及双重缓存和同步开销方面存在调优问题。通过使用页面高速缓存来存储缓冲高速缓存,即SunOS引入的一种称为统一缓冲高速缓存的方法,这些问题在很大程度上得到了解决,如图8.9所示。
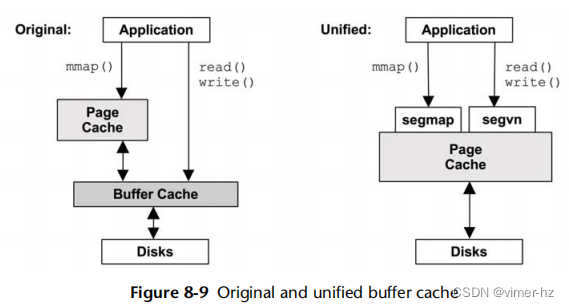
在Solaris中,原始的(“旧的”)缓冲高速缓存仍然存在,仅用于UFS索引节点和文件元数据,这些数据是通过它们的块位置而不是文件进行寻址。其大小是动态的,访问计数可以从kstat中观察到。
索引节点高速缓存也是动态增长的,至少保存所有已打开文件(已引用)的索引节点,以及由DNLC映射的那些索引节点。还会在一个空闲队列上保留一些额外的索引节点。
页面缓存
页面缓存是在1985年SunOS 4进行虚拟内存重写期间引入的,并在SVR4中添加[Vahalia 96]。它缓存虚拟内存页面,包括映射的文件系统页面。对于文件访问,它比需要为每次查找从文件偏移量转换为磁盘偏移量的缓冲高速缓存更有效。
多个文件系统类型使用页面缓存,包括最初的消费者UFS和NFS(但不包括ZFS)。页面缓存的大小是动态的,它会增长以利用可用内存,在应用程序需要时再次释放内存。
脏页内存,正在用于文件系统的页面,由一个称为文件系统刷新守护程序(fsflush)的内核线程写入磁盘,该守护程序定期扫描整个页面缓存。如果存在系统内存不足,另一个内核线程——分页守护程序(pageout,也称为页面扫描器)可能会找到并调度脏页写入磁盘,以便释放内存页面供重新使用(请参阅第7章,内存)。为了可观察性,pageout和fsflush显示为PID 2和3,即使它们是内核线程而不是进程。
页面缓存有两个主要的内核驱动程序:segvn,用于将文件映射到进程地址空间,以及segmap,用于缓存文件系统的读取和写入。有关这些内容以及页面扫描器的更多详细信息,请参见第7章,内存。
DNLC
目录名称查找缓存(DNLC)记住目录条目到vnode的映射,由Kevin Robert Elz在上世纪80年代初开发。它提高了路径名查找(例如,通过open())的性能,因为当遍历路径名时,每个名称查找都可以检查DNLC以获取直接vnode映射,而不必逐个遍历目录内容。DNLC被设计用于性能和可伸缩性,条目存储在一个哈希表中,由父vnode和目录条目名称进行哈希。
多年来,Solaris的DNLC已经添加了各种功能和性能特性。DNLC最初使用指针作为哈希链的一部分,以及LRU列表的附加指针。Solaris 2.4放弃了LRU指针,从而避免了LRU列表锁竞争。然后通过从哈希链的末端释放来实现LRU行为。Solaris 8增加了两个新特性:负缓存,用于记住不存在条目的查找,以及目录缓存,用于有意地缓存整个目录。负缓存有助于提高失败查找的性能,通常用于库路径查找。目录缓存通过避免扫描目录以查看新文件名是否已被使用,提高了文件创建时的性能。
DNLC的大小可以通过可调参数进行调整,当前大小以及命中和未命中计数可以从kstat中观察到。
Linux
图8.10概述了Linux上的文件系统缓存,展示了标准文件系统类型可用的通用缓存。

缓冲缓存
Linux最初使用类似Unix的缓冲缓存。自Linux 2.4以来,缓冲缓存已存储在页面缓存中(因此在图8.10中有虚线边框),遵循SunOS统一缓冲区方法,避免了双重缓存和同步开销。缓冲缓存功能仍然存在,改善了块设备I/O的性能。
缓冲缓存的大小是动态的,并且可以从/proc中观察到。
页面缓存
页面缓存缓存虚拟内存页面,包括文件系统页面,提高了文件和目录I/O的性能。页面缓存的大小是动态的,当应用程序需要时,它会增长以利用可用内存,并在应用程序需要时再次释放它(以及通过swappiness控制的页面调度;参见第7章,内存)。
已修改并供文件系统使用的内存页会被内核线程刷新到磁盘上。在Linux 2.6.32之前,有一个页面脏数据刷新(pdflush)线程池,根据需要在两个到八个之间。这些线程现已被刷新线程(命名为flush)取代,每个设备创建一个以更好地平衡每个设备的工作负载并提高吞吐量。页面被刷新到磁盘的原因包括:
- 经过一段时间间隔(30秒)
- sync()、fsync()或msync()系统调用
- 脏页过多(dirty_ratio)
- 页面缓存中没有可用页
如果系统内存不足,另一个内核线程——页面换出守护进程(kswapd,也称为页面扫描器)也可能找到并调度脏页写入磁盘,以便释放内存页供重用(参见第7章,内存)。就可观察性而言,从操作系统性能工具中可以看到kswapd和flush线程作为内核任务。
有关页面扫描器的更多详细信息,请参阅第7章,内存。
目录项缓存
目录项缓存(Dcache)记住从目录项(struct dentry)到VFS索引节点的映射,类似于早期的Unix DNLC。这提高了路径名查找的性能(例如,通过open()),因为在遍历路径名时,每个名称查找都可以检查Dcache以获取直接的索引节点映射,而不是逐个遍历目录内容。Dcache条目存储在哈希表中,以进行快速和可扩展的查找(由父级目录项和目录项名进行哈希处理)。
多年来,性能已经得到进一步改善,包括使用读-拷贝-更新-行走(RCU-walk)算法[1]。这试图在不更新目录项引用计数的情况下遍历路径名,因为在多CPU系统上高速率导致缓存一致性问题,这些问题会影响可伸缩性。如果在缓存中遇到不在缓存中的目录项,RCU-walk将恢复到较慢的引用计数遍历(ref-walk),因为在文件系统查找和阻塞过程中需要引用计数。对于繁忙的工作负载,预计目录项很可能被缓存,因此RCU-walk方法将成功。
Dcache还执行负面缓存,记住不存在条目的查找。这提高了失败查找的性能,这种情况通常发生在库路径查找中。
Dcache会动态增长,在系统需要更多内存时通过LRU缩小。其大小可以通过/proc查看。
索引节点缓存
此缓存包含VFS索引节点(struct inode),每个描述文件系统对象的属性,其中许多属性通过stat()系统调用返回。这些属性经常用于文件系统工作负载,例如在打开文件时检查权限,或在修改时更新时间戳。这些VFS索引节点存储在哈希表中,以进行快速和可扩展的查找(通过索引号和文件系统超级块进行哈希处理),尽管大多数查找将通过目录项缓存进行。
索引节点缓存会动态增长,至少保存目录项映射的所有索引节点。当系统内存压力较大时,索引节点缓存将缩小,删除没有相关目录项的索引节点。其大小可以通过/proc查看。
8.4.4 File System Features
除了缓存之外,影响性能的其他关键文件系统特性如下所述。
块与区段
基于块的文件系统将数据存储在固定大小的块中,这些块由存储在元数据块中的指针引用。对于大文件,这可能需要许多块指针和元数据块,并且块的放置可能会变得分散,导致随机I/O。一些基于块的文件系统尝试将块连续放置以避免这种情况。另一种方法是使用可变大小的块,使得文件增大时可以使用更大的块大小,这也减少了元数据开销。
基于区段的文件系统为文件预先分配连续空间(区段),根据需要进行扩展。虽然需要付出空间开销,但这提高了流式传输性能,并且可以改善随机I/O性能,因为文件数据是局部化的。
日志记录
文件系统日志(或日志)记录文件系统的更改,以便在系统崩溃时可以原子地重放这些更改——要么完全成功,要么失败。这使得文件系统可以快速恢复到一致状态。非日志记录的文件系统在系统崩溃时可能会损坏,如果与更改相关的数据和元数据写入不完整。要从这样的崩溃中恢复需要遍历所有文件系统结构,对于大型(几TB)文件系统可能需要数小时。
日志是同步写入磁盘的,并且对于一些文件系统,可以配置为使用单独的设备。一些日志记录同时记录数据和元数据,这会消耗存储I/O资源,因为所有I/O都会被写入两次。其他的只写入元数据,并通过采用写时复制来保持数据完整性。
有一种只包含一个日志的文件系统类型:日志结构化文件系统,其中所有数据和元数据更新都写入连续循环日志。这优化了写入性能,因为写入始终是顺序的,并且可以合并以使用更大的I/O大小。
写时复制
写时复制(COW)文件系统不会覆盖现有块,而是按照以下步骤进行:
1. 将块写入新位置(新副本)。
2. 更新到新块的引用。
3. 将旧块添加到空闲列表中。
这有助于在系统失败时保持文件系统的完整性,并通过将随机写入转换为顺序写入来提高性能。
巡检
这是一个文件系统特性,异步读取所有数据块并验证校验和,以尽早检测到故障驱动器,理想情况下在仍然可以通过RAID恢复的时候。然而,巡检读I/O可能会对性能产生负面影响,因此应该以低优先级发出。
8.4.5 File System Types
这一章的大部分内容描述了可以应用于所有文件系统类型的通用特性。以下部分总结了常用文件系统的特定性能特征。它们的分析和调优将在后续部分中进行。
FFS
许多文件系统都基于FFS,这是为了解决原始Unix文件系统存在的问题而设计的。一些背景信息可以帮助解释当前文件系统的状态。
原始Unix文件系统的磁盘布局包括inode表、512字节的存储块以及用于分配资源时使用的超级块。inode表和存储块将磁盘分区划分为两个范围,这在两者之间进行寻址时会导致性能问题。另一个问题是使用了固定的小块大小512字节,这限制了吞吐量,并增加了存储大文件所需的元数据(指针)量。一项试验将此块大小翻倍至1,024字节,然后遇到的瓶颈被描述如下:
尽管吞吐量翻了一番,但旧文件系统仍然只使用了大约四分之一的磁盘带宽。主要问题在于,尽管空闲列表最初按最佳方式排序以进行访问,但随着文件的创建和删除,它很快就变得混乱起来。最终,空闲列表变得完全随机,导致文件在磁盘上随机分配其块。这迫使在每次块访问之前进行寻道。尽管旧文件系统在最初创建时提供了高达175千字节/秒的传输速率,但由于数据块放置的随机化,经过几周适度使用后,该速率降至30千字节/秒。
这段摘录描述了空闲列表碎片化,随着文件系统的使用,这会随着时间的推移而降低性能。

伯克利快速文件系统(FFS)通过将分区分成多个柱面组来改善性能,如图8.11所示,每个柱面组都有自己的inode数组和数据块。文件inode和数据尽可能保持在同一个柱面组内,如图8.12所示,从而减少了磁盘寻址。相关的其他数据也被放置在附近,包括目录及其条目的inode。inode的设计类似(这里没有显示三重间接块)。
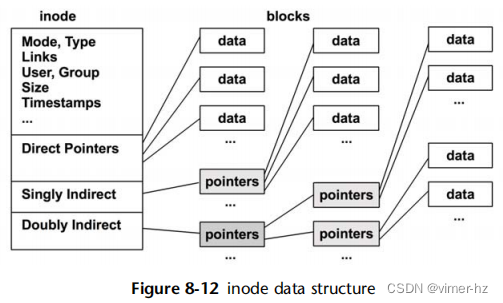
块大小增加到最小的4 K字节,提高了吞吐量。这减少了存储文件所需的数据块数量,因此间接块需要引用这些数据块的数量也减少了。由于间接指针块也更大,所以需要的间接指针块数量进一步减少了。为了在处理小文件时提高空间效率,每个块可以分成1 K字节的片段。
FFS的另一个性能特征是块交错:将磁盘上的顺序文件块之间放置一个或多个块的间隔[Doeppner 10]。这些额外的块给了内核和处理器时间来发出下一个顺序文件读取,因为它们在那时与控制磁盘更直接相关。如果没有交错,下一个块可能会在准备发出读取之前经过磁头,导致等待几乎完整旋转的延迟。
UFS
1984年,FFS作为UFS([McDougall 06a]中的SunOS 1.0)引入。在接下来的二十年中,向SunOS UFS添加了各种功能:I/O聚类、文件系统增长、多TB支持、日志记录、直接I/O、快照、访问控制列表(ACL)、扩展属性。Linux目前支持读取UFS,但不支持写入,而是支持另一个类似UFS的文件系统(ext3)。
UFS的关键性能特征包括以下内容:
- I/O聚类:通过延迟写入,将数据块分组在磁盘上,直到填满一个聚类,从而使它们被顺序放置。当检测到顺序读工作负载时,UFS执行预取(称为读取前瞻),通过读取这些聚类来执行。
- 日志记录(日志化):仅针对元数据。这提高了系统崩溃后的启动性能,因为日志重放可以避免运行fsck(文件系统检查)的需要。它还可以通过合并元数据写入来改善某些写入工作负载的性能。
- 直接I/O:绕过页面缓存,避免为数据库等应用程序进行双重缓存。
可配置功能在mkfs_ufs(1M)手册页中有文档。有关UFS及其内部的更多信息,请参阅Solaris Internals第2版,第15章[McDougall 06a]。
ext3
Linux扩展文件系统(ext)于1992年开发,是Linux及其VFS的第一个文件系统,基于原始Unix文件系统。第二个版本,1993年的ext2,包括来自FFS的多个时间戳和柱组。1999年的第三个版本,ext3,包括文件系统增长和日志记录。
关键性能特征,包括自发布以来添加的功能,包括:
- 日志记录:有序模式或日志模式,仅针对元数据或元数据和数据。日志记录提高了系统在崩溃后的启动性能,避免运行fsck的需要。它还可以通过合并元数据写入来改善某些写入工作负载的性能。
- 日志设备:可以使用外部日志设备,以便日志工作负载不与读取工作负载竞争。
- Orlov块分配器:将顶级目录分布在柱组中,使子目录和内容更有可能共同定位,减少随机I/O。
- 目录索引:为文件系统添加了散列B树,用于加快目录查找速度。
可配置功能在MKE2FS(8)手册页中有文档。
ext4
Linux ext4文件系统于2008年发布,通过添加各种功能和性能改进扩展了ext3:范围、大容量、使用fallocate()进行预分配、延迟分配、日志校验、更快的fsck、多块分配器、纳秒级时间戳和快照。
关键性能特征,包括自发布以来添加的功能,包括:
- 范围:范围改善连续放置,减少随机I/O并增加顺序I/O的I/O大小。
- 预分配:通过fallocate()系统调用,允许应用程序预先分配空间,这些空间可能是连续的,从而提高后续写入性能。
- 延迟分配:块分配被延迟至刷新到磁盘,允许写入组(通过多块分配器)以减少碎片化。
- 更快的fsck:未分配的块和inode条目被标记,减少fsck时间。
可配置功能在MKE2FS(8)手册页中有文档。某些功能,例如范围,可以应用于ext3文件系统。
ZFS
ZFS是由Sun Microsystems开发并于2005年发布的,它将文件系统与卷管理器相结合,并包括许多企业级特性:池化存储、日志记录、写时复制、自适应替换缓存(ARC)、大容量、可变大小块、动态条带化、多预读流、快照、克隆、压缩、数据校验和128位校验和。随着更新,还添加了其他功能,包括(其中一些将在下文中进一步解释)热备份、双奇偶校验RAID、gzip压缩、SLOG、L2ARC、用户和组配额、三重奇偶校验RAID、数据去重、混合RAID分配和加密。这些功能使ZFS成为文件服务器(文件存储器)的理想选择,Sun/Oracle和其他公司基于开源的ZFS版本开发了这些服务器。
自发布以来增加的主要性能特性包括:
池化存储:所有存储设备都放置在一个池中,从中创建文件系统。这允许所有设备并行使用,以获得最大吞吐量和IOPS。可以使用不同的RAID类型:0、1、10、Z(基于RAID-5)、Z2(双奇偶校验)和Z3(三重奇偶校验)。
写时复制(COW):按组顺序写入数据。
日志记录:ZFS刷新更改的事务组(TXGs),这些更改作为整体成功或失败,因此磁盘上的格式始终保持一致。这也批处理写操作,提高异步写入吞吐量。
自适应替换缓存(ARC):通过同时使用多种缓存算法(最近使用的(MRU)和最频繁使用的(MFU)),实现高缓存命中率。主存储器在这些算法之间进行平衡,根据它们的性能进行调整,通过维护额外的元数据(幽灵列表)来了解如果其中一个算法占据了整个主存储器将如何执行。
可变块大小:每个文件系统都有一个可配置的最大块大小(记录大小),可以选择以匹配工作负载。较小的大小用于较小的文件。
动态条带化:这在所有存储设备上进行条带化,以获得最大吞吐量,并在添加设备时将额外的设备包含在条带中。
智能预读:ZFS根据需要应用不同类型的预读:对于元数据、znodes(文件内容)和vdevs(虚拟设备)。
多预读流:单个文件上的多个流式读取器可以创建随机I/O工作负载,因为文件系统在它们之间寻找(这在UFS中是一个问题)。ZFS跟踪各个预读流,允许新的流加入它们,并有效地发出I/O。
快照:由于COW架构,可以几乎即时创建快照,推迟复制新块直到需要为止。
ZIO管道:设备I/O经过一系列阶段的处理,每个阶段由一组线程提供服务,以提高性能。
压缩:支持多种算法,通常由于CPU开销而降低性能。lzjb(Lempel-Ziv Jeff Bonwick)选项是轻量级的,通过降低I/O负载(因为它被压缩)可以在一定程度上提高存储性能,但会牺牲一些CPU性能。
SLOG:ZFS单独的意向日志允许将同步写入写入到单独的设备中,避免与池磁盘工作负载发生冲突。在系统故障时,写入SLOG只能被读取,以进行回放。这可以极大地提高同步写入的性能。
L2ARC:第二级缓存,用于在基于闪存的固态硬盘(SSD)上缓存随机读取工作负载。它不缓冲写入工作负载,只包含已经存在于存储池磁盘上的干净数据。L2ARC扩展了系统的缓存范围,有助于避免工作负载超出主存储器缓存时的性能急剧下降。它还提供滞后效应,因为与主存储器相比,它的填充速度较慢,它将包含长期数据的副本。如果干扰污染了主存储器缓存,L2ARC可以快速恢复“热”主存储器缓存状态。
vdev缓存:类似于原始缓冲缓存的作用,ZFS使用每个虚拟设备的独立vdev缓存,支持LRU和预读。(这在某些操作系统中可能已被禁用。)
数据去重:避免记录相同数据的多个副本的文件系统级特性。这个功能对性能有显著的影响,既有利(减少设备I/O),也有弊(当哈希表不再适合主存储器时,设备I/O会膨胀,可能会显著增加)。初始版本仅适用于哈希表预计始终适合主存储器的工作负载。
L2ARC和SLOG是ZFS混合存储池(HSP)模型的一部分,智能地在ZFS存储池中使用读取和写入优化的固态硬盘(SSD)。读取优化的SSD的价格/性能比介于主存储器和磁盘之间,使其适用于作为额外缓存层使用。
还包括其他次要的性能特性,例如“不在乎间隙”,在适当时发出更大的读取,即使不需要小部分(间隙);以及混合RAID,支持一个池中的不同策略。
与其他文件系统相比,ZFS的一个行为可能会降低性能:默认情况下,ZFS向存储设备发出缓存刷新命令,以确保写入在断电情况下已完成。这是ZFS的完整性特性之一;然而,代价是可能会导致必须等待缓存刷新的ZFS操作产生延迟,并且某些工作负载在ZFS上的表现可能会比其他文件系统差。可以调整ZFS以避免执行缓存刷新以提高性能;然而,与其他文件系统一样,这会引入部分写入和断电时数据损坏的风险,取决于所使用的存储设备。
有两个项目正在将ZFS引入Linux。一个是由劳伦斯利弗莫尔国家实验室[2]开发的ZFS on Linux,它是一个本地内核端口。另一个是ZFS-FUSE,在用户空间运行ZFS,由于上下文切换开销,其性能预计会较差。
btrfs
Btrfs(B-tree文件系统)基于写时复制的B树结构。这是一种现代文件系统和卷管理器相结合的架构,类似于ZFS,并且预计最终会提供类似的功能集。当前的功能包括池化存储、大容量、范围、写时复制、卷增长和收缩、子卷、块设备添加和移除、快照、克隆、压缩和CRC-32C校验和。该项目由甲骨文公司于2007年启动,目前仍在积极开发中,并被认为是不稳定的。
关键的性能特性包括以下内容:
- 池化存储:存储设备被放置在一个卷中,从中创建文件系统。这允许所有设备并行使用,以获得最大吞吐量和IOPS。可以使用不同的RAID类型:0、1和10。
- 写时复制(COW):按组顺序写入数据。
- 在线平衡:对象可以在存储设备之间移动,以平衡它们的工作负载。
- 范围:改善了顺序布局和性能。
- 快照:由于采用了写时复制的架构,可以几乎即时创建快照,推迟复制新块直到需要为止。
- 压缩:支持zlib和LZO。
- 日志记录:可以创建每个子卷的日志树,以记录同步写入的COW工作负载。
计划中与性能相关的特性包括RAID-5和6、对象级RAID、增量转储和数据去重。
8.4.6 Volumes and Pools
历史上,文件系统是建立在单个磁盘或磁盘分区之上的。卷和存储池允许文件系统建立在多个磁盘上,并可以使用不同的RAID策略进行配置(见第9章《磁盘》)。
卷将多个磁盘呈现为一个虚拟磁盘,文件系统建立在其上。如果建立在整个磁盘上(而不是切片或分区),卷会隔离工作负载,减少争用的性能问题。
卷管理软件包括Linux系统的逻辑卷管理器(LVM)和Solaris卷管理器(SVM)。卷或虚拟磁盘也可以由硬件RAID控制器提供。

存储池包括存储池中的多个磁盘,可以从中创建多个文件系统。在图8.13中显示了与卷进行对比的存储池。存储池比卷存储更灵活,因为无论支持设备如何,文件系统都可以增长和收缩。这种方法被现代文件系统(包括ZFS和btrfs)所采用。
存储池可以使用所有磁盘设备来支持所有文件系统,提高性能。工作负载不会被隔离;在某些情况下,可以使用多个存储池来分隔工作负载,尽管这会导致一定的灵活性降低,因为磁盘设备必须最初放置在一个池中或另一个池中。
在使用软件卷管理器或存储池时,额外的性能考虑包括以下内容:
- 条带宽度:与工作负载匹配。
- 可观察性:虚拟设备利用可能会令人困惑;请检查单独的物理设备。
- CPU开销:特别是在执行RAID奇偶校验计算时。随着现代更快的CPU,这已经不再是问题。
- 重建:也称为重新同步,当向RAID组添加空白磁盘(例如替换故障磁盘)并用必要的数据填充以加入组时。这可能会显著影响性能,因为它会消耗I/O资源,可能持续数小时甚至数天。
随着存储设备容量增长速度超过吞吐量的增长,未来重建可能会成为更严重的问题。
8.5 Methodology
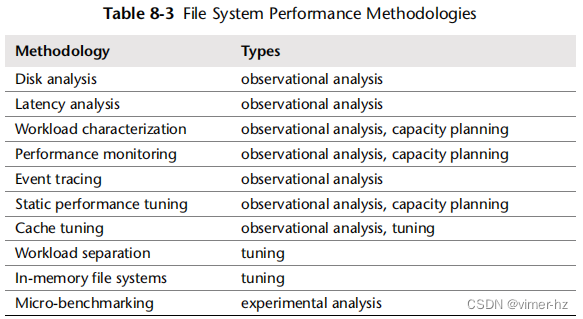
这一部分介绍了文件系统分析和调优的各种策略和练习。这些主题在表8.3中有总结。
更多策略和这些主题的介绍,请参见第2章《方法论》。
这些策略可以单独遵循,也可以组合使用。我的建议是按照以下顺序开始使用这些策略:延迟分析、性能监控、工作负载特征化、微基准测试、静态分析和事件跟踪。您可以提出不同的组合和顺序,在您的环境中找到最佳的方法。
第8.6节《分析》展示了应用这些方法的操作系统工具。
8.5.1 Disk Analysis
一个常见的策略是忽略文件系统,而是专注于磁盘性能。这种做法假设最糟糕的I/O是磁盘I/O,因此通过仅分析磁盘,您便方便地聚焦于问题的预期来源。
在文件系统较简单且缓存较小的情况下,这通常是有效的。然而,如今这种方法变得令人困惑,并且忽略了整个类别的问题(请参见第8.3.12节《逻辑I/O与物理I/O之间的区别》)。
8.5.2 Latency Analysis
对于延迟分析,首先要测量文件系统操作的延迟。这应该包括所有对象操作,而不仅仅是I/O(例如,包括sync())。
操作延迟 = 时间(操作完成) - 时间(操作请求)
这些时间可以从附近的四个层中的任何一个进行测量,如表8.4所示。

选择层可能取决于工具的可用性。请检查以下内容:
应用程序文档:一些应用程序已经提供文件系统延迟指标,或者具有启用收集这些指标的功能。
操作系统工具:操作系统通常也会提供指标,最好是针对每个文件系统或应用程序分别统计。
动态跟踪:如果您的系统支持动态跟踪,可以通过自定义脚本检查所有层,无需重新启动任何内容。
延迟可能呈现为
每个间隔的平均值:例如,每秒的平均读取延迟
完整分布:作为直方图或热力图;请参见第8.6.18节《可视化》
每个操作的延迟:列出每个操作;请参见第8.5.5节《事件跟踪》
对于高缓存命中率(超过99%)的文件系统,每个间隔的平均值可能会受到缓存命中延迟的影响。当存在重要但难以从平均值中看到的高延迟实例(离群值)时,这可能是不幸的。检查完整分布或每个操作的延迟允许调查这些离群值,以及不同延迟层级(包括文件系统缓存命中和未命中)的影响。
一旦发现高延迟,继续深入分析文件系统以确定来源。
Transaction Cost
将文件系统延迟表示为应用程序事务(例如,数据库查询)中等待文件系统的总时间的另一种方法是:
文件系统中百分比时间 = 100 * 总阻塞文件系统延迟 / 应用程序事务时间
这允许以应用程序性能的术语量化文件系统操作的成本,并预测性能改进。该指标可以表示为在间隔期间所有事务的平均值,或者针对单个事务。

图8.14显示了用于服务事务的应用程序线程所花费的时间。该事务发出单个文件系统读取请求;应用程序阻塞并等待其完成,转移到了非 CPU 状态。在这种情况下,总阻塞时间是单个文件系统读取的时间。如果在事务期间调用了多个阻塞 I/O,则总时间为它们的总和。
作为具体示例,一个应用程序事务需要 200 毫秒,期间在多个文件系统 I/O 上等待了总共 180 毫秒。应用程序由文件系统阻塞的时间为 90%(100 * 180 毫秒 / 200 毫秒)。消除文件系统延迟可能最多可以将性能提高 10 倍。
另一个例子,如果一个应用程序事务需要 200 毫秒,在此期间仅花费了 2 毫秒在文件系统中,则文件系统——以及整个磁盘 I/O 栈——仅占事务运行时间的 1%。这个结果非常有用,因为它可以将性能调查引导到真正的延迟源,并避免浪费时间在不必要的地方进行调查。
如果应用程序正在发出非阻塞 I/O,那么在文件系统响应时应用程序可以继续在 CPU 上执行。在这种情况下,阻塞文件系统延迟仅度量应用程序在非 CPU 上阻塞的时间。
8.5.3 Workload Characterization
在容量规划、基准测试和模拟工作负载时,对所施加的负载进行特征化是一项重要的任务。通过识别可以消除的不必要工作,它还可以带来最大的性能提升。
以下是描述文件系统工作负载的基本属性:
- 操作速率和操作类型
- 文件 I/O 吞吐量
- 文件 I/O 大小
- 读/写比例
- 同步写入比例
- 随机与顺序文件偏移访问
操作速率和吞吐量的定义可参考第8.1节中的术语。同步写入和随机与顺序的描述可参考第8.3节中的概念。
这些特征可以从秒到秒地变化,特别是对于按间隔执行的定时应用程序任务。为了更好地描述工作负载,捕获最大值和平均值是必要的。更好的做法是对随时间变化的值进行完整的分布分析。
以下是一个工作负载描述的示例,展示了如何将这些属性结合起来表达:
在一个金融交易数据库中,文件系统具有随机读取的工作负载,平均每秒处理 18,000 次读取,平均读取大小为 2 Kbytes。总操作速率为 21,000 ops/s,其中包括读取、统计、打开、关闭以及约 200 次同步写入每秒。写入速率稳定,而读取速率则有所变化,最高峰可达到每秒 39,000 次读取。
这些特征可以描述单个文件系统实例,也可以描述同类型系统上的所有实例。
高级工作负载特征化/检查清单
可以包含额外细节来描述工作负载。以下列出了一些考虑的问题,这些问题也可以作为一个检查清单,在彻底研究文件系统问题时使用:
- 文件系统缓存命中率是多少?未命中率呢?
- 文件系统缓存容量和当前使用情况是多少?
- 还有哪些其他缓存存在(目录、inode、缓冲),它们的统计数据是什么?
- 哪些应用程序或用户正在使用文件系统?
- 正在访问哪些文件和目录?创建和删除了哪些?
- 是否遇到过任何错误?这是由于无效请求还是文件系统问题引起的?
- 文件系统 I/O 为何发出(用户级调用路径)?
- 文件系统 I/O 应用程式是多么同步?
- I/O 到达时间的分布是怎样的?
这些问题中的许多可以针对每个应用程序或每个文件提出。任何一个问题也可以随着时间的推移进行检查,以寻找最大值和最小值,以及基于时间的变化。此外,还请参阅第2章方法论中的2.5.10节,工作负载特征化,提供了要测量的特征的更高级摘要(谁、为什么、什么、如何)。
性能特性
以下问题(与之前的工作负载特性对比)描述了工作负载的结果性能:
- 平均文件系统操作延迟是多少?
- 是否有任何高延迟的异常值?
- 操作延迟的完整分布是什么样的?
- 系统资源控制是否存在并且对文件系统或磁盘 I/O 有效?
前三个问题可以分别针对每种操作类型进行提问。
8.5.4 Performance Monitoring
性能监控可以识别出活动问题和随时间变化的行为模式。文件系统性能的关键指标是:
- 操作速率
- 操作延迟
操作速率是应用负载的最基本特性,而延迟则是产生的性能结果。正常或不良延迟的值取决于您的工作负载、环境和延迟要求。如果您不确定,可以进行已知良好和不良工作负载的微基准测试,以调查延迟情况(例如,通常从文件系统缓存中命中的工作负载与通常未命中的工作负载)。请参阅第8.7节,实验。
操作延迟指标可以作为每秒平均值进行监控,并可以包括其他值,如最大值和标准偏差。理想情况下,可以检查延迟的完整分布,例如使用直方图或热力图,以查找异常值和其他模式。
速率和延迟也可以记录每种操作类型(读取、写入、stat、打开、关闭等)的情况。这将极大地帮助工作负载和性能变化的调查,通过识别特定操作类型的差异。
对于实施了基于文件系统的资源控制(例如ZFS I/O限流)的系统,可以包含统计信息,以显示何时使用了限流。
8.5.5 Event Tracing
事件跟踪捕获每个文件系统操作的详细信息。对于观察性分析来说,这是最后的手段。由于捕获和保存这些详细信息会增加性能开销,通常将它们写入日志文件以供后续检查。这些日志文件可以包含每个操作的以下详细信息:
- 文件系统类型
- 文件系统挂载点
- 操作类型:读取、写入、stat、打开、关闭、mkdir等
- 操作大小(如果适用):字节
- 操作开始时间戳:操作发出到文件系统的时间
- 操作完成时间戳:文件系统完成操作的时间
- 操作完成状态:错误
- 路径名(如果适用)
- 进程ID
- 应用程序名称
开始和完成时间戳允许计算操作延迟。许多跟踪框架允许在跟踪过程中进行计算,因此可以计算并将延迟包含在日志中。它还可以用于过滤输出,只记录超过某个阈值的操作。文件系统操作速率可以达到每秒数百万次,因此在适当的情况下进行过滤可能是一个很好的主意。
事件跟踪可以在第8.5.2节中列出的四个层级中的任何一个执行。有关示例,请参阅第8.6节,分析。
8.5.6 Static Performance Tuning
静态性能调优侧重于已配置环境的问题。对于文件系统性能,要检查静态配置的以下方面:
- 挂载和活动使用的文件系统数量是多少?
- 文件系统记录大小是多少?
- 是否启用了访问时间戳?
- 是否启用了其他文件系统选项(压缩、加密等)?
- 文件系统缓存如何配置?最大大小是多少?
- 其他缓存(目录、inode、缓冲区)如何配置?
- 是否存在并使用二级缓存?
- 存在和使用的存储设备数量是多少?
- 存储设备的配置是什么?RAID吗?
- 使用了哪些文件系统类型?
- 文件系统(或内核)的版本是什么?
- 是否存在应考虑的文件系统错误/补丁?
- 是否对文件系统I/O使用了资源控制?
回答这些问题可以揭示被忽视的配置选择。有时系统被配置为适应一种工作负载,然后被重新用于另一种用途。这种方法将重新审视这些选择。
8.5.7 Cache Tuning
内核和文件系统可能使用许多不同的缓存,包括缓冲区缓存、目录缓存、inode缓存和文件系统(页)缓存。各种缓存在第8.4节“架构”中进行了描述,可以按照第2章“方法论”中第2.5.17节“缓存调优”的描述进行调整。总的来说,检查存在哪些缓存,检查它们是否正常工作,检查它们的工作情况如何,检查它们的大小,然后为缓存调整工作负载,为工作负载调整缓存。
8.5.8 Workload Separation
某些类型的工作负载在配置为使用自己的文件系统和磁盘设备时可以获得更好的性能。这种方法被称为使用“独立的磁盘”,因为通过在两个不同的工作负载位置之间进行寻址来创建随机I/O对于旋转磁盘尤其不利(详见第9章“磁盘”)。
例如,数据库可以从为其日志文件和数据库文件使用单独的文件系统和磁盘受益。
8.5.9 Memory-Based File Systems
另一种改善性能的配置方法是使用基于内存的文件系统。这些文件系统保留在内存中,以便尽快提供文件内容。它们通常仅作为解决方案部署,因为许多应用程序在进程内存中具有自己的(可配置的)应用程序特定缓存,通过文件和系统调用接口访问比通过文件更高效。在现代系统中,使用大型文件系统缓存,通常不值得使用基于内存的文件系统。
/tmp
标准的/tmp文件系统用于存储临时文件,通常配置为基于内存。例如,Solaris使用tmpfs作为/tmp,它是一个由交换设备支持的基于内存的文件系统。Linux也有一个tmpfs,用于几个特殊的文件系统类型。
8.5.10 Micro-Benchmarking
用于文件系统和磁盘基准测试的基准工具(有很多种)可以用来测试不同文件系统类型或文件系统内的设置在给定工作负载下的性能。可能测试的典型因素包括:
操作类型:读取、写入和其他文件系统操作的速率
I/O 大小:从 1 字节到 1 M 字节及更大
文件偏移模式:随机或顺序
随机访问模式:均匀随机或帕累托分布
写入类型:异步或同步(O_SYNC)
工作集大小:它在文件系统缓存中的适应程度
并发性:正在进行中的 I/O 数量,或执行 I/O 的线程数量
内存映射:通过 mmap() 进行文件访问,而不是 read()/write()
缓存状态:文件系统缓存是“冷”(未填充)还是“热”
文件系统可调参数:可能包括压缩、数据去重等
常见的组合包括随机读取、顺序读取、随机写入和顺序写入。
最关键的因素通常是工作集大小:在基准测试期间访问的数据量。根据基准测试的不同,这可能是正在使用的文件的总大小。小的工作集大小可能完全从主内存中的文件系统缓存中返回(DRAM)。大的工作集大小可能主要从存储设备(磁盘)返回。性能差异可能是多个数量级。
考虑不同基准测试的一般期望,其中包括文件的总大小(工作集大小),见表 8.5。
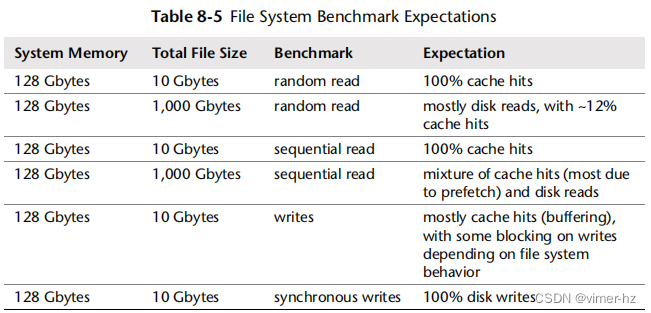
一些文件系统基准测试工具并不清楚它们正在测试什么,并可能暗示进行磁盘基准测试,但使用小的总文件大小并完全从缓存中返回。参见第 8.3.12 节,逻辑与物理 I/O,了解测试文件系统(逻辑 I/O)与测试磁盘(物理 I/O)之间的区别。
一些磁盘基准测试工具通过使用直接 I/O 绕过缓存和缓冲来操作文件系统。文件系统仍然扮演较小的角色,增加了代码路径开销和文件与磁盘位置之间的映射差异。这有时是测试文件系统的一种有意策略:分析最坏情况性能(0% 缓存命中率)。随着内存系统变得越来越大,这种策略越来越不现实,因为应用程序通常期望有显著的缓存命中率。
有关这个主题的更多信息,请参见第12章“基准测试”。
8.6 Analysis
本节介绍了针对基于Linux和Solaris操作系统的文件系统性能分析工具。有关使用这些工具时要遵循的策略,请参见前一节。
本节中列出的工具如表8.6所示。


这是一些工具和功能的选择,用于支持前面的方法论部分,从系统范围和每个文件系统的可观测性开始,然后进行操作和延迟分析,并最后完成缓存统计。有关它们功能的完整参考,请参阅工具文档,包括man手册。
虽然您可能只对基于Linux或Solaris的系统感兴趣,但考虑一下其他操作系统工具以及它们提供的可观测性,可以获得不同的视角。
8.6.1 vfsstat
vfsstat(1) 是一个类似于 iostat(1M) 的工具,用于 VFS 层级,最初由 Bill Pijewski 为 SmartOS 开发。它会打印文件系统操作(逻辑 I/O)的每个时间间隔摘要,包括用户级应用程序经历的平均延迟。与 iostat(1) 中显示的磁盘 I/O(物理 I/O),包括异步类型的统计信息相比,这些信息对应用程序性能更为相关。

输出的第一行是自启动以来的摘要,其后是每秒的摘要。列包括:
- r/s, w/s:每秒的文件系统读取和写入次数
- kr/s, kw/s:每秒的文件系统读取和写入的千字节数
- ractv, wactv:服务中的读取和写入操作的平均数量
- read_t, writ_t:平均的VFS读取和写入延迟(毫秒)
- %r, %w:VFS读取和写入操作挂起的时间百分比
- d/s, del_t:每秒的I/O节流延迟,以及平均延迟(微秒)
vfsstat(1) 提供了用于描述工作负载以及其结果性能的信息。它还包括有关ZFS I/O节流的信息,该信息在SmartOS云计算环境中用于平衡租户。前面的示例显示了读取工作负载介于1.5到2K读取/秒之间,吞吐量介于73到92兆字节/秒之间。平均延迟非常小,以至于已被舍入为0.0毫秒。这种工作负载很可能是从文件系统缓存返回的,它使文件系统处于忙碌(活动)状态的时间仅占3%到4%。
8.6.2 fsstat
Solaris的fsstat工具报告各种文件系统统计信息:

这些信息可用于工作负载特征化,并且可以根据每个文件系统进行检查。请注意,fsstat不包括延迟统计信息。
8.6.3 strace, truss
以前用于详细测量文件系统延迟的操作系统工具包括针对系统调用接口的调试器,例如Linux中的strace(1)和Solaris中的truss(1)。这些调试器可能会影响性能,并且只有在性能开销可接受且无法使用其他方法分析延迟时才适合使用。
以下示例显示了在ext4文件系统上使用strace(1)定时读取的情况:


-tt选项在左侧打印相对时间戳,-T在右侧打印系统调用时间。每个read()调用读取64 KB,第一个调用花费了18毫秒,接着是56微秒(可能是缓存),然后是5毫秒。这些读取是对文件描述符9的。要检查这是否是对文件系统的读取(而不是套接字),要么open()系统调用将在较早的strace(1)输出中可见,要么可以使用其他工具如lsof(8)。
8.6.4 DTrace
DTrace可以从系统调用接口、VFS接口和文件系统内部来检查文件系统行为。这些功能支持工作负载特征化和延迟分析。以下部分介绍了在基于Solaris和Linux的系统上进行文件系统分析的DTrace。除非另有说明,否则DTrace命令适用于两种操作系统。在第四章《可观测性工具》中包括了一个DTrace入门指南。
操作计数
通过应用程序和类型对文件系统操作进行汇总,提供了有用的工作负载特征化的指标。
这个Solaris的一行命令通过应用程序名称,使用fsinfo(文件系统信息)提供程序统计文件系统操作次数:

输出显示,在跟踪期间,名为node的进程执行了25,340次文件系统操作。可以添加一个tick-1s探针来报告每秒的汇总情况,以便观察速率。
操作的类型可以通过对probename进行聚合来报告。例如:

这也展示了如何检查特定应用程序,本例中过滤条件是"splunkd"。
在Linux上,可以从syscall和fbt提供程序观察文件系统操作,直到fsinfo可用为止。例如,使用fbt跟踪内核VFS函数:

在这个跟踪过程中,执行最多文件系统操作的应用程序名为sysbench(一个基准测试工具[3])。
通过对probefunc进行聚合来计算操作类型的数量:

这与sysbench进程匹配,该进程在执行随机读写基准测试时显示了操作的比率。要从输出中去掉vfs_,而不是使用@[probefunc],可以使用@[probefunc + 4](指针加偏移量)。
文件打开
之前的一行命令使用DTrace来汇总事件计数。接下来的示例演示了单独打印所有事件数据,即在此情况下,系统范围内open()系统调用的详细信息:

opensnoop是来自DTraceToolkit的基于DTrace的工具;它默认包含在Oracle Solaris 11和Mac OS X中,并可用于其他操作系统。它提供了对文件系统工作负载的某种视图,显示了open()的进程、路径名和错误,这对性能分析和故障排除都很有用。在这个示例中,nginx进程遇到了一个打开失败的情况(ERR 2 == 文件未找到)。其他常用的DTraceToolkit脚本包括rwsnoop和rwtop,它们跟踪和汇总逻辑I/O。rwsnoop跟踪read()和write()系统调用,而rwtop使用sysinfo提供程序汇总吞吐量(字节)。
系统调用延迟
这个一行命令在系统调用接口处测量文件系统的延迟,并将其汇总为以纳秒为单位的直方图:

该分布显示了两个峰值,第一个在4到16微秒之间(缓存命中),第二个在2到8毫秒之间(磁盘读取)。与quantize()不同,avg()函数可以用于显示平均值(均值)。然而,这将对两个峰值进行平均,这可能会产生误导性。
这种方法跟踪单个系统调用,本例中为read()。要捕获所有文件系统操作,需要跟踪所有相关的系统调用,包括每种类型的变体(例如,pread()、pread64())。这可以通过构建一个脚本来捕获所有类型,或者针对给定的应用程序,通过DTrace检查它使用的系统调用类型,然后只跟踪那些类型来执行。
这种方法还捕获了所有文件系统活动,包括非存储文件系统,如sockfs。对于这个一行命令,文件系统类型通过检查fds[arg0].fi_fs的值来进行过滤,该值将文件描述符(read()的arg0)转换为文件系统类型(fds[].fi_fs)。在这种情况下,还可以应用其他有用的过滤器,例如按应用程序名称或PID、挂载点或路径名组件进行过滤。
请注意,此延迟可能会直接影响应用程序的性能,如第8.3.1节“文件系统延迟”所述。这取决于延迟是在应用程序请求期间遇到的,还是在异步后台任务期间遇到的。您可以使用DTrace开始回答这个问题,方法是捕获用于系统调用I/O的用户级堆栈跟踪,这可能会解释为什么执行了该操作(例如,使用@[ustack(), "ns"]进行聚合)。这可能会根据应用程序的复杂性和其源代码变得更加复杂。
VFS延迟
VFS接口可以通过静态提供程序(如果存在)或通过动态跟踪(fbt提供程序)进行跟踪。
在Solaris上,可以通过fop_*()函数跟踪VFS,例如:

与先前的系统调用示例不同,这显示了一个完全缓存的工作负载。这个一行命令还具有更广泛的可见性,因为它匹配了所有的读取变体。
其他VFS操作也可以类似地进行跟踪。列出入口探针:

请注意,fbt提供程序被认为是一个不稳定的接口,因此任何基于fbt的一行命令或脚本可能需要更新,以匹配随着内核变化而变化的情况(尽管VFS实现并不经常更改)。
在Linux上,可以使用DTrace原型:
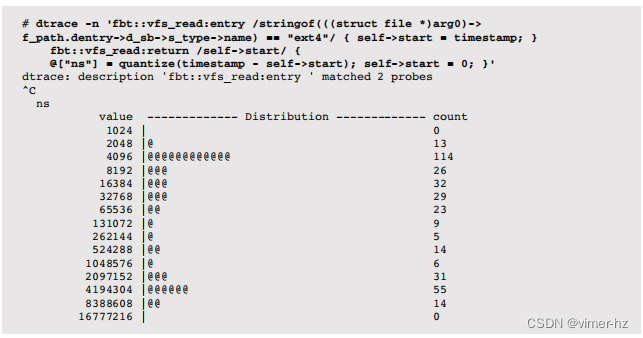
这次的谓词匹配的是ext4文件系统。可以看到缓存命中和未命中的峰值,伴随着预期的延迟。
列出VFS函数入口探针:


块设备I/O堆栈
检查块设备I/O的内核堆栈跟踪是了解文件系统内部工作原理以及导致磁盘I/O的代码路径的绝佳方法。它还可以帮助解释超出预期工作负载的附加磁盘I/O(异步、元数据)的原因。
通过在发出块设备I/O时对内核堆栈跟踪进行频率计数来暴露ZFS内部:

输出显示了跟踪过程中堆栈跟踪及其出现次数。
顶部堆栈显示了一个异步的ZFS I/O(来自运行ZIO管道的taskq线程)和一个源自读取系统调用的同步I/O。为了收集更多细节,可以使用DTrace fbt提供程序对这些堆栈的每一行进行单独跟踪,采用相同的方法来暴露ext4:

这条路径显示了一个read()系统调用触发了页面缓存的预读取。
文件系统内部
必要时,可以通过跟踪其实现来确定文件系统中的延迟。
在Solaris上列出ZFS函数入口探针:
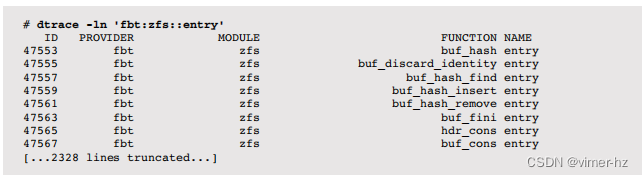
ZFS与VFS有直接的映射关系,使得高级跟踪变得简单。例如,跟踪ZFS读取延迟:


输出显示了大约8μs(缓存命中)左右的I/O峰值,另一个在大约4毫秒(缓存未命中)左右。这是因为zfs_read()在系统调用上同步阻塞。在ZFS内部更深处,函数会发出I/O,但不会阻塞等待其完成,因此测量I/O时间变得更加复杂。
在Linux上,可以以类似的方式跟踪ext4文件系统的内部实现:

一些函数是同步的,例如ext4_readdir(),其延迟可以像前面的zfs_read()示例一样进行测量。
其他函数则不是同步的,包括ext4_readpage()和ext4_readpages()。要测量它们的延迟,需要将I/O发出和完成之间的时间相关联并进行比较。或者,可以在堆栈中更高的位置进行跟踪,就像VFS示例中演示的那样。
慢事件跟踪
DTrace可以打印每个文件系统操作的详细信息,就像第9章“磁盘”中的iosnoop打印每个磁盘I/O一样。然而,在文件系统级别进行跟踪可能会产生更大量的输出,因为它包括文件系统缓存命中。解决这个问题的一种方法是只打印慢操作,这有助于分析特定类别的问题:延迟异常值。
zfsslower.d脚本[4]打印了比设定的毫秒数慢的ZFS级别操作:

这个经过编辑的输出显示了比10毫秒慢的文件系统操作。
高级跟踪
在需要进行高级分析时,动态跟踪可以更详细地探索文件系统。为了提供可能性的想法,表8.7显示了来自DTrace的《文件系统》章节(共108页)的脚本[Gregg 11](这些脚本也可以在网上找到[4])。


尽管这种程度的可观察性令人难以置信,但许多这些动态跟踪脚本都与特定的内核内部绑定在一起,并且需要进行维护以匹配新内核版本中的更改。
作为高级跟踪的一个示例,以下是一个DTraceToolkit脚本,它在从UFS读取50KB文件时跟踪了多个层面的事件:


第一个事件是一个8千字节的系统调用读取(sc-read),它被处理为VFS读取(fop_read),然后是磁盘读取(disk_io),随后是下一个8千字节的预读(disk_ra)。接下来的偏移8千字节的系统调用读取不会触发磁盘读取,因为它已经被缓存,而是触发了从偏移16开始的预读,以获取下一个34千字节的数据——50千字节文件的剩余部分。其余的系统调用都从缓存中返回,只有VFS事件可以看到。
8.6.5 SystemTap
SystemTap也可以用于Linux系统中对文件系统事件进行动态跟踪。有关如何将先前的DTrace脚本转换的帮助,请参阅第4章可观测性工具中的第4.4节SystemTap,以及附录E。
8.6.6 LatencyTOP
LatencyTOP是一种报告延迟来源的工具,可以汇总系统范围和每个进程的延迟[5]。它最初是为Linux开发的,后来已经移植到基于Solaris的系统上。
LatencyTOP会报告文件系统的延迟。例如:
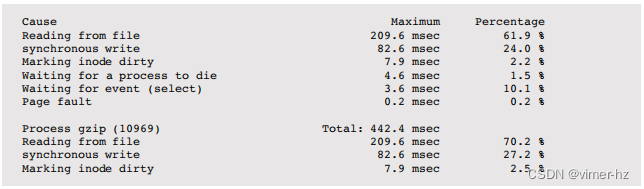
顶部部分是系统范围的摘要,底部是一个单独的gzip(1)进程,正在压缩一个文件。gzip(1)的大部分延迟是由于文件读取,占70.2%,而同步写入占27.2%,因为新压缩的文件正在写入。
LatencyTOP需要以下内核选项:CONFIG_LATENCYTOP和CONFIG_HAVE_LATENCYTOP_SUPPORT。
8.6.7 free
Linux的free(1)命令显示内存和交换空间的统计信息:

buffers列显示缓冲区缓存大小,cached列显示页面缓存大小。使用了-m选项以兆字节为单位呈现输出。
8.6.8 top
一些版本的top(1)命令包括文件系统缓存的详细信息。这来自Linux top的一行包括缓冲区缓存大小,这也由free(1)报告:
![]()
有关top(1)的更多信息,请参阅第6章的CPU部分。
8.6.9 vmstat
vmstat(1)命令,类似于top(1),也可能包括有关文件系统缓存的详细信息。有关vmstat(1)的更多详细信息,请参阅第7章内存部分。
Linux
以下命令运行vmstat(1),间隔为1,以提供每秒更新:

buff列显示缓冲区缓存大小,cache列显示页面缓存大小,单位均为千字节(kilobytes)。
Solaris
Solaris vmstat(1)的默认输出不显示缓存大小,但在这里值得一提:

free列的单位为千字节(kilobytes)。自Solaris 9以来,页面缓存被视为空闲内存,并且其大小包含在此列中。
-p选项显示按类型的页面进入/退出详细信息:

这允许将文件系统分页与匿名分页(低内存)区分开来。不幸的是,文件系统列目前不包括ZFS文件系统事件。
8.6.10 sar
系统活动报告工具sar(1)提供各种文件系统统计信息,并可以配置记录历史信息。sar(1)在本书的各个章节中都提到了,因为它提供了不同的统计信息。
Linux
执行sar(1)以报告当前活动的间隔:

-v选项提供以下列:
- dentunusd:目录条目缓存未使用计数(可用条目)
- file-nr:正在使用的文件句柄数
- inode-nr:正在使用的索引节点数
还有一个-r选项,用于打印缓冲区和页面缓存大小的kbbuffers和kbcached列,单位为千字节(kilobytes)。
Solaris
通过指定间隔和次数执行sar(1)以报告当前活动:

-v选项提供inod-sz,显示索引节点缓存大小和最大值。
还有一个-b选项,提供有关旧缓冲区缓存的统计信息。
8.6.11 slabtop
Linux的slabtop(1)命令打印有关内核slab缓存的信息,其中一些用于文件系统缓存:

在没有-o输出模式的情况下,slabtop(1)将刷新并更新屏幕。
Slabs可能包括:
- dentry:目录项缓存
- inode_cache:索引节点缓存
- ext3_inode_cache:用于ext3的索引节点缓存
- ext4_inode_cache:用于ext4的索引节点缓存
slabtop(1)使用/proc/slabinfo,如果启用了CONFIG_SLAB选项,则会存在该文件。
8.6.12 mdb ::kmastat
Solaris上可以使用mdb -k中的::kmastat查看详细的内核内存分配器统计信息,其中包括文件系统使用的各种缓存:

输出很长,显示所有的内核分配器缓存。可以研究正在使用的内存列,以确定哪些缓存存储了大量数据,从而了解内核内存使用情况。在此示例中,ZFS 8K字节文件数据缓存使用了23.5GB的内存。如果需要,还可以动态跟踪到特定缓存的分配,以识别代码路径和消费者。
8.6.13 fcachestat
这是一个针对基于Solaris的系统的开源工具,使用Perl的Sun::Solaris::Kstat库,并打印适合在UFS上进行缓存活动分析的摘要:

第一行是自启动以来的摘要。有五组列,用于各种缓存和驱动程序。ufsbuf是旧的缓冲区缓存,segmap和segvn显示页面缓存的驱动程序。列显示命中/未命中比例的百分比(%hit)和总访问数(total)。
fcachestat可能需要更新才能正常工作;这里包括它是为了展示系统可以提供哪些信息。
8.6.14 /proc/meminfo
Linux的/proc/meminfo文件提供了内存细分的摘要,并被像free(1)这样的工具所读取:

其中包括缓冲区缓存(Buffers)和页面缓存(Cached),并提供系统内存使用的其他高级细分。这些内容在第7章“内存”中有所涉及。
8.6.15 mdb ::memstat
Solaris中,使用mdb -k的::memstat命令可以提供Solaris内存使用的高级细分:
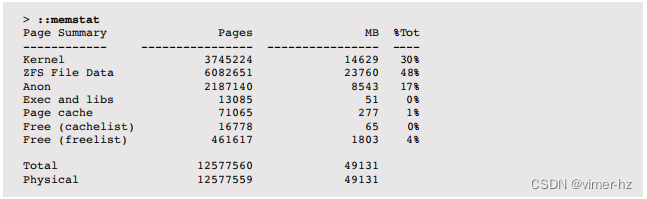
其中包括由ARC缓存的ZFS文件数据,以及包括UFS缓存数据的页面缓存。
8.6.16 kstat
前述工具的原始统计数据可以通过kstat获得,可以通过Perl的Sun::Solaris::Kstat库、C的libkstat库或kstat(1)命令来访问。表8.8中的命令显示了文件系统统计信息的组,以及可用数量(来自最近的内核版本)。

以下是其中一个示例:

虽然kstats可以提供丰富的信息,但它们在历史上并没有被文档化。有时统计名称是自说明的;有时需要查看内核源代码(如果可用)来确定每个统计数据的含义。
可用的统计数据也会因内核版本而异。在最近的SmartOS/illumos内核中,以下计数器已添加:

这些计数器记录了超出描述周期的文件系统操作,并按区域进行记录。在追踪云计算环境中的文件系统延迟时,这些信息可能非常宝贵。
8.6.17 Other Tools
其他工具和可观察性框架可能存在用于调查文件系统性能并描述其使用情况的情况。其中包括:
- df(1):报告文件系统使用情况和容量统计信息
- mount(8):可以显示文件系统挂载选项(静态性能调优)
- inotify:Linux的一个框架,用于监视文件系统事件
一些文件系统类型除了操作系统提供的工具外,还有自己特定的性能工具,例如ZFS。
ZFS
ZFS附带了zpool(1M),它具有用于观察ZFS池统计信息的iostat子选项。它报告池操作速率(读取和写入)和吞吐量。
一个受欢迎的附加工具是arcstat.pl工具,它报告ARC和L2ARC的大小以及命中率和未命中率。例如:


这些统计数据是按照间隔来统计的,其中包括:
- read, miss:总的 ARC 访问次数,未命中次数
- miss%,dm%,pm%,mm%:ARC 未命中百分比的总和,需求访问,预取访问,元数据访问
- dmis,pmis,mmis:需求访问,预取访问,元数据访问的未命中次数
- arcsz,c:ARC 大小,ARC 目标大小
arcstat.pl 是一个 Perl 程序,从 kstat 中读取统计数据。
8.6.18 Visualizations
应用于文件系统的负载可以随时间绘制成折线图,以帮助识别基于时间的使用模式。为了更好地理解,可以分别绘制读取、写入和其他文件系统操作的不同图表。
文件系统延迟的分布预计是双峰的:一个峰值代表文件系统缓存命中时的低延迟,另一个峰值代表缓存未命中(存储设备 I/O)时的高延迟。因此,将分布表示为单一值——如平均值、众数或中位数——是误导性的。
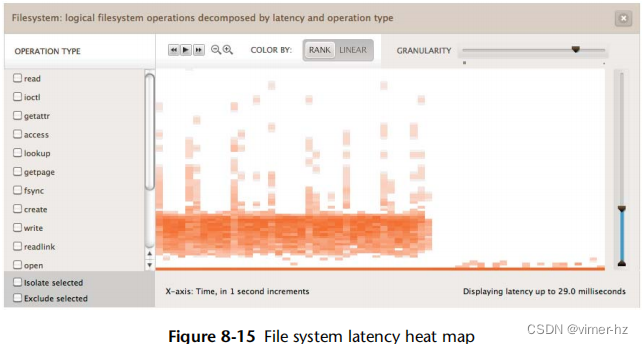
解决这个问题的一种方法是使用能够显示完整分布的可视化工具,比如热力图(热力图在第二章“方法论”中介绍过)。图 8.15 中给出了一个例子,它将时间的变化显示在 x 轴上,将 I/O 延迟显示在 y 轴上。
这个热力图展示了随机读取一个 1 G 字节文件时的文件系统情况。在热力图的前半部分,可以看到介于 3 到 10 毫秒之间的延迟云,这很可能反映了磁盘 I/O。底部的线表示文件系统缓存命中(DRAM)。在超过一半的位置,文件完全被缓存在了DRAM中,磁盘I/O云消失了。
这个例子来自 Joyent Cloud Analytics,它允许选择和隔离文件系统操作类型。
8.7 Experimentation
本节描述了用于主动测试文件系统性能的工具。请参阅第8.5.10节“微基准测试”,了解建议的跟随策略。
在使用这些工具时,建议始终保持 iostat(1) 运行,以确认达到磁盘的工作负载是否符合预期。例如,当测试应轻松适合文件系统缓存的工作集大小时,对于读取工作负载的期望是100%的缓存命中,因此 iostat(1) 不应显示磁盘I/O。iostat(1) 在第9章“磁盘”中有介绍。
8.7.1 Ad Hoc
dd(1) 命令(设备到设备复制)可用于执行顺序文件系统性能的临时测试。以下命令用于以 1 M 字节的 I/O 大小写入,然后读取名为 file1 的 1 G 字节文件:

Linux 版本的 dd(1) 在完成时会打印统计信息。
8.7.2 Micro-Benchmark Tools
有许多可用的文件系统基准测试工具,包括Bonnie、Bonnie++、iozone、tiobench、SysBench、fio和FileBench。以下是一些讨论的工具,按照递增复杂性的顺序排列。还请参阅第12章“基准测试”。
Bonnie, Bonnie++
Bonnie工具是一个简单的C程序,用于在单个文件上测试多个工作负载,从单个线程执行。它最初由Tim Bray于1989年编写。使用方法很简单:

使用 -s 参数设置要测试的文件大小。默认情况下,Bonnie使用100兆字节,该大小在此系统上完全被缓存:

输出包括每个测试期间的CPU时间,当CPU时间达到100%时,这表明Bonnie从未在磁盘I/O上阻塞,而总是从缓存中命中并保持在CPU上。
有一个称为Bonnie-64的64位版本,允许测试更大的文件。还有一个由Russell Coker重写的C++版本,名为Bonnie++。
不幸的是,像Bonnie这样的文件系统基准测试工具可能会误导人,除非您清楚地了解正在测试的内容。第一个结果是一个putc()测试,它可能会因系统库的实现而异,这样就会成为测试的目标,而不是文件系统本身。请参阅第12章“基准测试”的12.3.2节“主动基准测试”中的示例。
fio
The Flexible IO Tester (fio),由Jens Axboe开发,是一个可定制的文件系统基准测试工具,具有许多高级功能[8]。导致我选择使用它而不是其他基准测试工具的两个特点是:
1. 非均匀随机分布,可以更准确地模拟实际访问模式(例如,-random_distribution=pareto:0.9)。
2. 报告延迟百分位数,包括99.00、99.50、99.90、99.95、99.99。
以下是一个示例输出,显示了一个随机读取工作负载,其中包括8 K字节的I/O大小、5 G字节的工作集大小和非均匀访问模式(pareto:0.9):

延迟百分位数(clat)清楚地显示了缓存命中的范围,本例中可达到50th百分位数,因为它们的延迟较低。其余百分位数显示了缓存未命中的影响,包括队列的尾部;在本例中,99.99th百分位数显示了63毫秒的延迟。
尽管这些百分位数缺乏信息来真正理解可能是多模式分布的情况,但它们确实专注于最有趣的部分:较慢模式的尾部(磁盘I/O)。
如果你想要一个类似但更简单的工具,你可以尝试SysBench。另一方面,如果你想要更多的控制权,可以尝试FileBench。
FileBench
FileBench是一个可编程的文件系统基准测试工具,可以通过描述它们的工作负载模型语言来模拟应用程序工作负载。这允许模拟具有不同行为的线程,并指定同步线程行为。它附带了各种这些配置,称为个性化配置,包括用于模拟Oracle 9i I/O模型的配置。不幸的是,FileBench不是一个易于学习和使用的工具,可能只对全职从事文件系统工作的人感兴趣。
8.7.3 Cache Flushing
Linux提供了一种清空(从中删除条目)文件系统缓存的方法,这对于从一致且“冷”缓存状态进行性能基准测试可能很有用,比如在系统启动后。这个机制在内核源代码文档(Documentation/sysctl/vm.txt)中被非常简单地描述为:

目前Solaris系统中没有类似的机制。
8.8 Tuning
已经在第8.5节“方法论”中涵盖了许多调优方法,包括缓存调优和工作负载特征化。后者通过识别和消除不必要的工作,可能会带来最高的调优效果。本节包括具体的调优参数(可调参数)。
调优的具体方式——可用选项和如何设置它们——取决于操作系统版本、文件系统类型和预期的工作负载。以下各节提供了可能可用的示例以及它们可能需要进行调优的原因。涵盖的内容包括应用程序调用和两种示例文件系统类型:ext3和ZFS。有关页面缓存的调优,请参阅第7章“内存”。
8.8.1 Application Calls
第8.3.7节《同步写入》提到,通过使用fsync()来刷新一组逻辑写入,而不是在使用O_DSYNC/O_RSYNC open()标志时单独刷新,可以改善同步写入工作负载的性能。其他可以提高性能的调用包括posix_fadvise()和madvise(),它们提供了缓存合格性的提示。
posix_fadvise()
这个库调用在文件的一个区域上操作,并具有以下函数原型
![]()
该建议可能如表8.9所示。
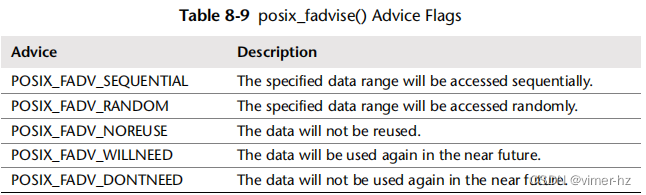
内核可以使用这些信息来提高性能,帮助它决定何时最好预取数据,以及何时最好缓存数据。这可以提高高优先级数据的缓存命中率,如应用程序建议的那样。请参阅您系统上的man页,以获取建议参数的完整列表。
posix_fadvise()在第3章《操作系统》的第3.3.4节《差异》中被用作示例,因为支持可能会根据内核的不同而变化。
madvise()
这个库调用在内存映射上操作,并具有概要。
![]()
建议可能如表8.10所示。

与posix_fadvise()类似,内核可以利用这些信息来提高性能,包括做出更好的缓存决策。
8.8.2 ext3
在Linux上,可以使用tune2fs(8)命令来调整ext2、ext3和ext4文件系统。还可以在挂载时设置各种选项,可以手动使用mount(8)命令进行设置,也可以在/boot/grub/menu.lst和/etc/fstab中设置启动时的选项。可用的选项在tune2fs(8)和mount(8)的man页面中,可以使用tunefs -l 设备 和 mount(无选项)命令查看当前设置。可以使用mount(8)中的noatime选项禁用文件访问时间戳更新,这样如果文件系统用户不需要这些更新,则会减少后端I/O,从而提高整体性能。
用于提高性能的tune2fs(8)的一个关键选项是
![]()
它使用哈希B树来加速大型目录中的查找。
e2fsck(8)命令可用于重新索引文件系统中的目录。例如:
![]()
e2fsck(8)的其他选项与检查和修复文件系统相关。
8.8.3 ZFS
ZFS支持每个文件系统的大量可调参数(称为属性),还有一些可以在系统范围内设置(/etc/system)。可以使用zfs(1)命令列出文件系统的属性。例如:


(截断的)输出包括属性名称、当前值和来源的列。来源显示了如何设置属性:是从更高级别的ZFS数据集继承的,是默认值,还是在该文件系统上本地设置的。
这些参数也可以使用命令进行设置,并在man页面中进行了描述。与性能相关的关键参数列在表8.11中。

调整最重要的参数通常是记录大小,以匹配应用程序的I/O。它通常默认为128 KB,这对于小范围的随机I/O可能效率低下。请注意,这不适用于小于记录大小的文件,这些文件使用与其文件长度相等的动态记录大小保存。
如果不需要时间戳,禁用atime也可以提高性能(尽管其更新行为已经经过优化)。
表8.12中显示了示例系统范围的ZFS可调参数。(随着ZFS版本的变化,对性能最重要的参数可能会有所不同;表中的这三个参数在您阅读时可能会再次更改。)

在多年的发展中,zfs_txg_synctime_ms和zfs_txg_timeout可调参数的默认值已经降低,这样TXG就会更小,不太可能因为排队而与其他I/O竞争。与其他内核可调参数一样,请查阅供应商文档以获取完整列表、描述和警告。根据公司或供应商政策,设置这些参数可能也被禁止。
关于ZFS调优的更多信息,您可能会喜欢查阅《ZFS邪恶调优指南》[9]。
















 895
895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









