






磁盘I/O可能会导致应用程序延迟显著增加,因此是系统性能分析的重要目标。在高负载下,磁盘成为瓶颈,导致CPU空闲,系统等待磁盘I/O完成。识别和消除瓶颈可以将性能和应用程序吞吐量提高数个数量级。
术语“磁盘”指的是系统的主要存储设备。它们包括磁性旋转磁盘和基于闪存存储的固态硬盘(SSD)。后者主要是为了提高磁盘I/O性能而引入的,它们确实做到了。然而,对于容量和I/O速率的需求也在增加,闪存存储设备也不免遇到性能问题。
本章包括五个部分,前三部分为磁盘I/O分析提供基础,后两部分展示了它在基于Linux和Solaris的系统中的实际应用。这些部分如下:
- 背景介绍了与存储相关的术语、磁盘设备的基本模型和关键的磁盘性能概念。
- 架构提供了存储硬件和软件架构的通用描述。
- 方法论描述了性能分析方法论,包括观察和实验。
- 分析展示了基于Linux和Solaris的系统上进行分析和实验的磁盘性能工具,包括跟踪和可视化。
- 调优描述了示例磁盘可调参数。
上一章讨论了建立在磁盘上的文件系统的性能。
9.1 Terminology
在本章中使用的与磁盘相关的术语包括以下内容:
- 虚拟磁盘:存储设备的仿真。它在系统中显示为单个物理磁盘;然而,它可能由多个磁盘构成。
- 传输:用于通信的物理总线,包括数据传输(I/O)和其他磁盘命令。
- 扇区:传统上大小为512字节的磁盘上的存储块。
- I/O:严格来说,对于磁盘,这仅指读取和写入,并不包括其他磁盘命令。I/O至少包括方向(读取或写入)、磁盘地址(位置)和大小(字节)。
- 磁盘命令:除了读取和写入之外,磁盘可能被命令执行其他非数据传输命令(例如,缓存刷新)。
- 吞吐量:对于磁盘,吞吐量通常指当前的数据传输速率,以每秒字节计量。
- 带宽:这是存储传输或控制器的最大可能数据传输速率。
- I/O延迟:I/O操作的时间,在操作系统堆栈中广泛使用,不仅仅在设备级别。请注意,网络使用此术语的方式不同,延迟是指启动I/O的时间,然后是数据传输时间。
- 延迟异常值:具有异常高延迟的磁盘I/O。
本章还介绍了其他术语。如果需要,词汇表包括基本术语供参考,包括磁盘、磁盘控制器、存储阵列、本地磁盘、远程磁盘和IOPS。另请参阅第2章和第3章中的术语部分。
9.2 Models
以下简单模型说明了磁盘I/O性能的一些基本原理。
9.2.1 Simple Disk
现代磁盘包括一个用于I/O请求的磁盘队列,如图9.1所示。
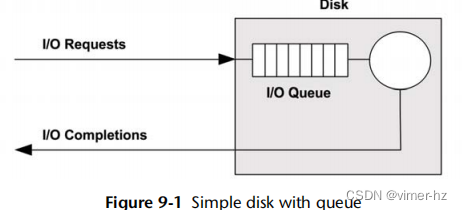
磁盘接受的I/O请求可能在队列中等待或正在被处理。
这个简单的模型类似于杂货店的结账,顾客排队等待服务。它也非常适合使用排队理论进行分析。
虽然这可能暗示着一个先来先服务的队列,但磁盘控制器可以应用其他算法来优化性能。这些算法可能包括对旋转磁盘进行电梯搜索(请参阅第9.4.1节,磁盘类型中的讨论),或者为读和写I/O分别设置队列(特别是对于基于闪存的磁盘)。
9.2.2 Caching Disk
在磁盘上添加一个缓存允许一些读取请求从更快的内存类型中得到满足,如图9.2所示。这可以实现为包含在物理磁盘设备内部的少量内存(DRAM)。
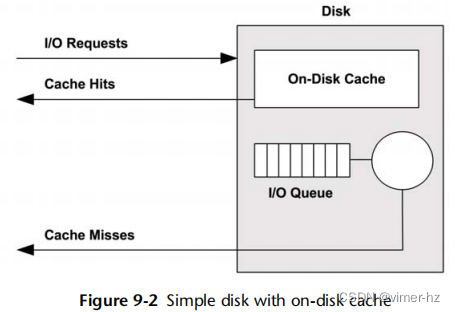
虽然缓存命中的延迟非常低(良好),但通常仍然会出现缓存未命中,返回带有高磁盘设备延迟的情况。
磁盘上的缓存也可以用于提高写入性能,通过将其用作写回缓存。这意味着在数据传输到缓存之后,但在较慢的传输到持久磁盘存储之前,将写入标记为已完成。与之相对应的术语是写直通缓存,它仅在完全传输到下一级之后才完成写入。
9.2.3 Controller
图9.3展示了一个简单类型的磁盘控制器,它连接了CPU I/O传输和存储传输,并连接了磁盘设备。这些也被称为主机总线适配器(HBAs)。
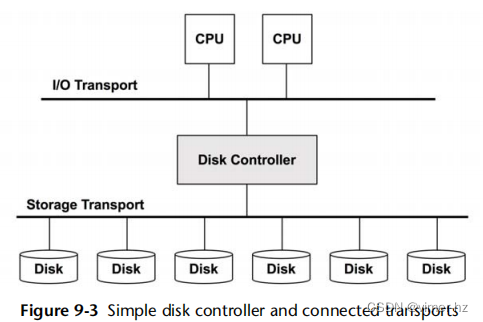
性能可能会受到这些总线、磁盘控制器或磁盘的限制。有关磁盘控制器的更多信息,请参阅第9.4节《体系结构》。
9.3 Concepts
以下是磁盘性能中的重要概念。
9.3.1 Measuring Time
存储设备的响应时间(也称为磁盘I/O延迟)是从I/O请求到I/O完成的时间。它由服务时间和等待时间组成:
- 服务时间:I/O被积极处理(服务)所花费的时间,不包括在队列中等待的时间。
- 等待时间:I/O在队列中等待被处理的时间。
这些概念如图9.4所示,还有其他相关术语。
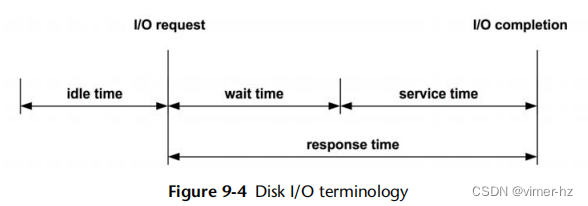
响应时间、服务时间和等待时间都取决于它们所测量的位置。以下是对此进行解释,通过描述操作系统和磁盘上下文中的服务时间(这也是一种简化):
在操作系统(块设备接口)的上下文中,服务时间可以被定义为从发出 I/O 请求到磁盘设备的时间,到完成中断发生的时间。它不包括在操作系统队列中等待的时间,并且仅反映磁盘设备对所请求操作的整体性能。
在磁盘的上下文中,服务时间指的是磁盘积极为 I/O 提供服务的时间,不包括在磁盘自身的磁盘队列上等待的任何时间。 服务时间一词源自于磁盘是由操作系统直接管理的更简单的设备时代,因此操作系统知道磁盘何时在积极为I/O提供服务。 现在磁盘有自己的内部队列,操作系统的服务时间包括在设备队列上等待的时间。 这个操作系统度量标准可能更好地被描述为“磁盘响应时间”。
响应时间这个术语也可以从不同的角度应用。 例如,“磁盘响应时间”可能描述从操作系统观察到的服务时间,而“ I/O响应时间”则是从应用程序的角度来看,可能指系统调用层以下的一切(服务时间,所有等待时间和代码路径执行时间)。
来自块设备接口的服务时间通常被视为磁盘性能的一种度量标准(也是iostat(1)显示的内容); 但是,您应该意识到这是一种简化。 在图9.6中,描绘了一个通用的I/O堆栈,显示了块设备接口下方的三个可能的驱动程序层。 这些任何一个都可以实现自己的队列,或者可能在互斥体上阻塞,从而增加I/O的延迟。 这个延迟包含在从块设备接口测量的服务时间中。
计算时间
通常,操作系统无法直接观察到磁盘服务时间;但是,可以使用IOPS和利用率推断出平均磁盘服务时间:
磁盘服务时间 = 利用率 / IOPS
例如,如果利用率为60%,IOPS为300,则平均服务时间为2毫秒(600毫秒/300 IOPS)。这假设利用率反映了一个只能一次处理一个I/O的单个设备(或服务中心)。磁盘通常可以并行处理多个I/O。
9.3.2 Time Scales
磁盘I/O的时间尺度可以差异巨大,从几十微秒到数千毫秒不等。在时间尺度的最慢端,单个慢速磁盘I/O可能导致应用响应时间不佳;在最快端,磁盘I/O问题可能只会在数量众多时出现(许多快速I/O的总和等于一个慢速I/O)。
为了提供背景信息,表9.1提供了磁盘I/O延迟可能的一般范围的概念。要获取准确和最新的值,请参阅磁盘供应商的文档,并进行您自己的微基准测试。另请参阅第2章《方法论》,了解除磁盘I/O之外的时间尺度。
为了更好地说明涉及的数量级差异,"缩放"列显示了基于虚构的一秒钟内磁盘缓存命中延迟的比较。

这些延迟可能根据环境需求有不同的解释。在企业存储行业工作时,我认为任何超过10毫秒的磁盘I/O都异常缓慢,可能是性能问题的潜在来源。在云计算行业中,对于高延迟有更高的容忍度,特别是在面向网络和客户端浏览器之间已经预期高延迟的Web应用程序中。在这些环境中,磁盘I/O可能只在超过100毫秒(在单个应用程序请求期间或总体上)时成为问题。
这个表格还说明了磁盘可以返回两种类型的延迟:一种是针对磁盘缓存命中的延迟(小于100微秒),另一种是针对未命中的延迟(1–8毫秒或更高,取决于访问模式和设备类型)。由于磁盘将返回这两种延迟的混合,将它们一起表达为平均延迟(正如iostat(1)所做的那样)可能会产生误导,因为这实际上是具有两种模式的分布。请参阅第2章《方法论》中的图2.22,这是一个示例磁盘I/O延迟分布的直方图(使用DTrace测量)。
9.3.3 Caching
磁盘I/O性能最佳的情况是完全避免磁盘I/O。软件堆栈的许多层次都试图通过缓存读取和缓冲写入来避免磁盘I/O,甚至直到磁盘本身。这些缓存的完整列表在《操作系统》第3章的表3.2中,包括应用程序级别和文件系统级别的缓存。在磁盘设备驱动程序级别及以下,它们可能包括表9.2中列出的缓存。
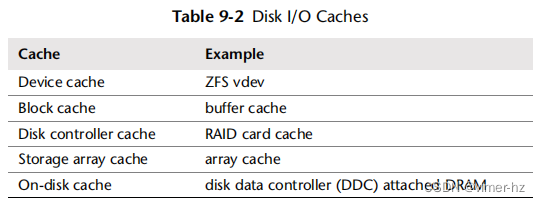
基于块的缓冲缓存在《文件系统》第8章进行了描述。这些磁盘I/O缓存对于提高随机I/O工作负载的性能尤为重要。
9.3.4 Random versus Sequential I/O
磁盘I/O工作负载可以用随机和顺序两个术语来描述,这取决于I/O在磁盘上的相对位置(磁盘偏移量)。这些术语在第8章《文件系统》中讨论过,涉及到文件访问模式。
顺序工作负载也被称为流式工作负载。流式通常在应用程序级别使用,用于描述“对磁盘”的流式读取和写入。
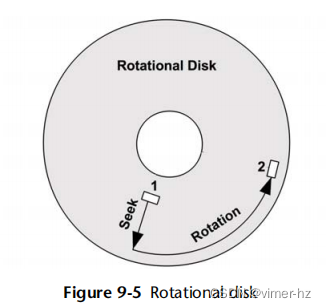
在磁性旋转盘时代,研究随机与顺序磁盘I/O模式非常重要。对于这些情况,随机I/O会增加额外的延迟,因为磁盘磁头在I/O之间进行寻道并且盘片在其间旋转。如图9.5所示,磁头在扇区1和扇区2之间移动需要进行寻道和旋转(实际路径将尽可能直接)。性能调优涉及识别随机I/O,并尝试通过多种方式消除它,包括缓存、将随机I/O隔离到单独的磁盘以及通过磁盘位置调整以减少寻道距离。
其他类型的磁盘,包括基于闪存的固态硬盘(SSD),通常在随机和顺序I/O模式之间表现不同。根据磁盘的不同,可能会存在一些差异,例如,由于其他因素,如地址查找缓存可能会跨越顺序访问但不跨越随机访问。
请注意,从操作系统中看到的磁盘偏移量可能与物理磁盘上的偏移量不匹配。例如,硬件提供的虚拟磁盘可能会将连续的偏移范围映射到多个磁盘上。磁盘可能会以自己的方式重新映射偏移量(通过磁盘数据控制器)。有时,随机I/O并非通过检查偏移量来识别,而是通过测量增加的服务时间来推断。
9.3.5 Read/Write Ratio
除了识别随机与顺序工作负载之外,另一个特征性指标是读取与写入的比例,指的是IOPS或吞吐量。这可以表示为随时间的比率,以百分比的形式,例如,“系统自启动以来读取占80%”。
了解这个比率有助于在设计和配置系统时。读取率高的系统可能最适合增加缓存。写入率高的系统可能最适合增加更多磁盘以增加最大可用吞吐量和IOPS。
读取和写入本身可能是不同的工作负载模式:读取可能是随机I/O,而写入可能是顺序的(特别是对于写时复制文件系统)。它们也可能展示不同的I/O大小。
9.3.6 I/O Size
平均I/O大小(字节)或I/O大小的分布是另一个工作负载特征。较大的I/O大小通常提供更高的吞吐量,尽管会增加每个I/O的延迟。
I/O大小可能会被磁盘设备子系统改变(例如,量化为512字节的块)。自从应用程序级别发出I/O以来,大小可能已被内核组件(如文件系统、卷管理器和设备驱动程序)进行了膨胀和收缩。请参阅第8章文件系统中第8.3.12节《逻辑与物理I/O》中的膨胀和收缩部分。
一些磁盘设备,特别是基于闪存的,对不同的读写大小表现出非常不同的性能。例如,基于闪存的磁盘驱动器可能会在4KB的读取和1MB的写入时表现最佳。理想的I/O大小可能由磁盘供应商记录,也可以使用微基准测试进行识别。当前使用的I/O大小可以通过观察工具找到(参见第9.6节《分析》)。
9.3.7 IOPS Are Not Equal
由于这些最后三个特性,IOPS并非相等,不能直接在不同设备和工作负载之间进行比较。一个IOPS值单独而言意义不大,不能单独使用来准确比较工作负载。例如,在旋转磁盘上,一个5,000个顺序IOPS的工作负载可能比一个1,000个随机IOPS的工作负载快得多。基于闪存内存的IOPS也很难比较,因为它们的I/O性能通常相对于I/O大小和方向(读或写)而言。
为了理解IOPS,应包括其他细节:随机或顺序、I/O大小、读/写。还应考虑使用基于时间的指标,如利用率和服务时间,这些指标反映了结果性能并且可以更容易地进行比较。
9.3.8 Non-Data-Transfer Disk Commands
除了I/O读取和写入之外,磁盘还可以发送其他命令。例如,具有磁盘缓存(RAM)的磁盘可以被命令将缓存刷新到磁盘。这样的命令不是数据传输;数据先前通过写入命令发送到了磁盘。这些命令可能会影响性能,并导致磁盘被利用,而其他I/O处于等待状态。
9.3.9 Utilization
利用率可以被计算为在一个时间段内磁盘忙于主动执行工作的时间。
利用率为0%的磁盘处于“空闲”状态,而利用率为100%的磁盘则持续忙于执行I/O(和其他磁盘命令)。处于100%利用率的磁盘很可能是性能问题的一个来源,特别是如果它们保持在100%一段时间。然而,任何磁盘利用率都可能导致性能不佳,因为磁盘I/O通常是一个缓慢的活动。
在0%和100%之间可能还存在一个点(比如说,60%),在这个点上,由于排队的可能性增加,磁盘的性能不再令人满意,无论是在磁盘队列上还是在操作系统中。成为问题的确切利用率取决于磁盘、工作负载和延迟要求。在第二章方法论的2.6.5节排队理论中的M/D/1和60%利用率部分有更多信息。
要确认高利用率是否导致应用程序问题,请研究磁盘响应时间以及应用程序是否在此I/O上阻塞。应用程序或操作系统可能会异步执行I/O,因此缓慢的I/O并不直接导致应用程序等待。
请注意,利用率是一个时间段的摘要。磁盘I/O可能会突发发生,特别是由于写入刷新,这可能在长时间间隔内进行摘要时被掩盖。在第二章方法论的2.3.11节利用率中有关于利用率度量类型的进一步讨论。
虚拟磁盘利用率
对于由硬件提供的虚拟磁盘(例如,磁盘控制器提供的),操作系统可能只知道虚拟磁盘何时忙碌,但对其构建所依赖的底层磁盘的性能一无所知。这导致了一种情况,即操作系统报告的虚拟磁盘利用率与实际磁盘情况(并且是违反直觉的)显著不同:
- 包含写回缓存的虚拟磁盘在写工作负载期间可能看起来并不繁忙,因为磁盘控制器立即返回写完成,尽管底层磁盘之后可能忙碌。
- 一个100%繁忙的虚拟磁盘,构建在多个物理磁盘之上,可能能够接受更多的工作。在这种情况下,100%可能意味着某些磁盘一直处于繁忙状态,但并非所有磁盘都一直处于繁忙状态,因此某些磁盘可能处于空闲状态。
出于相同的原因,解释操作系统软件创建的虚拟磁盘(软件RAID)的利用率可能会很困难。然而,操作系统应该也会公开物理磁盘的利用率,可以对其进行检查。
一旦物理磁盘达到100%的利用率并且请求更多I/O,它就会变得饱和。
9.3.10 Saturation
饱和度是排队工作量的度量,超出资源可以提供的范围。对于磁盘设备而言,它可以被计算为操作系统中设备等待队列的平均长度(假设它进行排队)。
这提供了一个超过100%利用率点的性能度量。一个利用率为100%的磁盘可能没有饱和(排队),或者它可能有很多,由于I/O的排队而显著影响性能。
可以假设利用率低于100%的磁盘没有饱和。然而,这取决于利用率间隔:在一个时间段内的50%磁盘利用率可能意味着在其中一半时间内利用率达到100%,而在其余时间内处于空闲状态。任何间隔摘要都可能遇到类似的问题。当需要准确了解发生了什么时,可以使用跟踪来检查I/O事件。
9.3.11 I/O Wait
I/O等待是一个基于每个CPU的性能指标,显示了空闲时间,当CPU调度队列上有线程(处于睡眠状态)被阻塞在磁盘I/O上时。这将CPU的空闲时间分成两部分:一部分是没有任务可执行的时间,另一部分是被阻塞在磁盘I/O上的时间。每个CPU的高I/O等待率表明磁盘可能是一个瓶颈,导致CPU在等待磁盘时处于空闲状态。I/O等待可能是一个非常令人困惑的指标。如果另一个CPU密集型进程出现,I/O等待值可能会下降:CPU现在有任务可执行了,而不是处于空闲状态。然而,尽管I/O等待指标下降,但相同的磁盘I/O仍然存在并阻塞线程。有时,当系统管理员升级应用软件并且新版本更高效、使用的CPU周期更少时,会出现相反的情况,从而暴露了I/O等待。这可能会让系统管理员误以为升级导致了磁盘问题,并使性能变差,但实际上磁盘性能保持不变,CPU性能得到了改善。关于如何在Solaris上计算I/O等待,还存在一些微妙的问题。对于Solaris 10发布版,I/O等待指标已被弃用,并且对于仍需要显示它的工具(为了兼容性),该指标已被硬编码为零。一个更可靠的指标可能是应用线程在磁盘I/O上被阻塞的时间。这捕获了应用线程由于磁盘I/O而遭受的痛苦,而不管CPU可能在做什么其他工作。可以使用静态或动态跟踪来测量此指标。I/O等待仍然是Linux系统上一个流行的指标,尽管它具有令人困惑的性质,但成功地用于识别一种类型的磁盘瓶颈:磁盘繁忙,CPU空闲。解释它的一种方式是将任何等待I/O都视为系统瓶颈的迹象,然后调整系统以将其最小化——即使I/O仍然与CPU利用率同时发生。并发I/O更有可能是非阻塞I/O,不太可能引起直接问题。如I/O等待所指示的非并发I/O更可能是应用阻塞I/O,是一个瓶颈。
9.3.12 Synchronous versus Asynchronous
重要的是要理解,如果应用程序I/O和磁盘I/O是异步操作的话,磁盘I/O延迟可能不会直接影响应用程序性能。这种情况通常发生在写回缓存中,其中应用程序I/O提前完成,而磁盘I/O稍后发出。
应用程序可能会使用预读取来执行异步读取,这可能不会在磁盘完成I/O时阻塞应用程序。文件系统可以自行启动此过程以预热缓存(预取)。
即使一个应用程序正在同步等待I/O,该应用程序代码路径也可能是非关键的并且与客户端应用程序请求异步。
有关更详细的解释,请参阅第8章文件系统中的第8.3.9节“非阻塞I/O”、第8.3.5节“预读取”、第8.3.4节“预取”和第8.3.7节“同步写入”。
9.3.13 Disk versus Application I/O
磁盘I/O是各种内核组件(包括文件系统和设备驱动程序)的最终结果。导致这种磁盘I/O的速率和数量与应用程序发出的I/O不匹配的原因有很多。这些原因包括:
- 文件系统的膨胀、紧缩和不相关的I/O。请参阅第8章文件系统中的第8.3.12节“逻辑I/O与物理I/O”。
- 由于系统内存不足而导致的页面调度。请参阅第7章内存中的第7.2.2节“页面调度”。
- 设备驱动程序I/O大小:将I/O大小舍入或分片。
当出现意外时,这种不匹配可能会令人困惑。通过学习体系结构并进行分析,可以理解这种不匹配。
9.4 Architecture
本节描述了磁盘架构,通常在容量规划期间进行研究,以确定不同组件和配置选择的限制。在调查后续性能问题时,还应该检查磁盘架构,以防问题源于架构选择而不是当前的负载和调优。
9.4.1 Disk Types
目前最常用的两种磁盘类型是磁性旋转硬盘和基于闪存存储的固态硬盘(SSD)。这两种提供永久存储;与易失性内存不同,在断电后它们存储的内容仍然可用。
磁性旋转硬盘
也称为硬盘驱动器(HDD),这种类型的磁盘由一个或多个盘片组成,称为盘片,其中充满了氧化铁颗粒。这些颗粒的一小部分可以在两个方向中的一个方向上磁化;此方向用于存储位。盘片旋转,同时带有读写数据电路的机械臂伸展到表面。这些电路包括磁头,一个臂可能有一个以上的磁头,使其能够同时读写多个位。数据存储在盘片的圆形轨道上,每个轨道分为扇区。
由于是机械设备,它们的性能相对较慢。随着基于闪存存储的技术的进步,固态硬盘正在取代旋转硬盘,可以想象有一天旋转硬盘将会过时(以及鼓式磁盘和核心内存)。与此同时,在某些情况下,如经济型高密度存储(每兆字节成本低)中,旋转硬盘仍然具有竞争力。
以下主题总结了旋转硬盘性能中的因素。
搜索和旋转
磁性旋转硬盘的慢I/O通常是由于磁头的搜索时间和盘片的旋转时间,两者都可能需要毫秒级的时间。最理想的情况是,下一个请求的I/O位于当前正在服务的I/O的末尾,这样磁头就不需要搜索或等待额外的旋转。正如前文所述,这被称为顺序I/O,而需要磁头搜索或等待旋转的I/O被称为随机I/O。
有许多策略可以减少搜索和旋转等待时间,包括
- 缓存:完全消除I/O
- 文件系统的放置和行为,包括写入时复制
- 将不同的工作负载分开放置到不同的磁盘上,以避免在工作负载I/O之间进行搜索
- 将不同的工作负载移到不同的系统上(某些云计算环境可以通过这种方式减少多租户效应)
- 电梯搜索,由磁盘自身执行
- 更高密度的磁盘,以紧凑的工作负载位置
- 分区(或“切片”)配置,例如,短距离行驶
另一种减少旋转等待时间的策略是使用更快的磁盘。
磁盘以不同的旋转速度提供,包括每分钟5400、7200、10000(10K)和15000(15K)转。
理论最大吞吐量
如果一个磁盘的最大每磁道扇区数已知,则可以使用以下公式计算磁盘的吞吐量:
\[ \text{max throughput} = \text{max sectors per track} \times \text{sector size} \times \frac{\text{rpm}}{60 \text{ s}} \]
这个公式在过去更适用于准确公开这些信息的老式磁盘。现代磁盘将提供虚拟磁盘映像给操作系统,并公开这些属性的合成值。
短程慢速
短程慢速是指只使用磁盘的外部磁道进行工作负载;其余的要么未使用,要么用于低吞吐量的工作负载(例如,存档)。这减少了寻道时间,因为磁头移动受较小范围的限制,并且磁盘可能将磁头放置在外部边缘,减少闲置后的首次寻道。由于扇区分区(见下一节),外部磁道通常也具有更好的吞吐量。在检查发布的磁盘基准测试时要特别注意短程慢速,特别是那些不包括价格的基准测试,并且可能使用了许多短程慢速的磁盘。
扇区分区
磁盘磁道的长度不同,中心处最短,外侧边缘最长。与固定每磁道扇区数(和位数)不同,扇区分区(也称为多区域记录)增加了长磁道的扇区计数,因为可以物理写入更多扇区。由于旋转速度恒定,较长的外侧边缘磁道提供比内部磁道更高的吞吐量(每秒兆字节)。
扇区大小
存储行业已经制定了一项新的磁盘设备标准,称为高级格式,支持更大的扇区大小,特别是 4 KB。这减少了 I/O 计算开销,提高了吞吐量,同时减少了磁盘每扇区存储的元数据开销。通过称为高级格式 512e 的仿真标准,磁盘固件仍然可以提供 512 字节的扇区。根据磁盘的不同,这可能会增加写入开销,调用读修改写循环将 512 字节映射到 4 KB 扇区。要注意的其他性能问题包括不对齐的 4 KB I/O,它们跨越两个扇区,使得扇区 I/O 膨胀以服务它们。
磁盘缓存
这些磁盘的一个常见组成部分是少量内存(RAM),用于缓存读取的结果和缓冲写入。这段内存还允许将I/O(命令)排队在设备上,并以更高效的方式重新排序。对于SCSI,这被称为标记命令排队(TCQ);对于SATA,它被称为原生命令排队(NCQ)。
电梯寻道
电梯算法(也称为电梯寻道)是命令队列可以提高效率的一种方式。它根据它们在磁盘上的位置重新排列I/O,以最小化磁盘磁头的移动。结果类似于建筑电梯,它不会根据按下楼层按钮的顺序服务楼层,而是上下扫过建筑,停在当前请求的楼层。
当检查磁盘I/O跟踪并发现按完成时间排序的I/O与按启动时间排序的I/O不匹配时,此行为变得明显:I/O无序完成。
虽然这似乎是一个显而易见的性能优势,但请考虑以下情景:一批I/O被发送到偏移量1,000附近的磁盘,以及偏移量2,000的单个I/O。磁盘磁头当前位于1,000。那么偏移量2,000的I/O将何时得到服务?现在考虑到,当服务于1,000附近的I/O时,更多的I/O接近1,000到达,还有更多,还有更多——足以持续让磁盘在偏移量1,000附近忙碌10秒。那么现在偏移量2,000的I/O将何时得到服务,它的最终I/O延迟是多少?
ECC
磁盘在每个扇区的末尾存储一个纠错码,因此驱动器可以验证数据是否被正确读取,并可能纠正一些错误。如果扇区读取不正确,磁盘磁头可能会在下一次旋转时重试读取(并可能多次重试,每次稍微变化磁头的位置)。在性能上下文中,了解这一点可能很重要,因为这可能是异常缓慢I/O的一个可能解释。请调查操作系统和磁盘错误计数器以确认。
振动
虽然磁盘设备供应商对振动问题早有所闻,但这些问题在业界并不被普遍了解或认真对待。2008年,在调查一个神秘的性能问题时,我进行了一个振动诱发的实验,当时我对着一个磁盘阵列大声喊叫,而它正在执行写入基准测试,结果引发了一次非常缓慢的I/O爆发。我的实验立即被录制成视频并上传到YouTube,迅速走红,被描述为首次展示振动对磁盘性能影响的示范[Tuner 10]。这段视频已经获得了超过800,000次的观看,提升了对磁盘振动问题的认识[1]。根据我收到的电子邮件,我还似乎意外地催生了一个声音隔离数据中心的行业:现在你可以聘请专业人员分析数据中心的声音水平,并通过减震来改善磁盘性能。
慢速磁盘
目前一些旋转磁盘的一个性能问题是我们发现了我们所称的慢速磁盘。这些磁盘有时会返回非常缓慢的I/O,超过一秒钟,而没有报告任何错误。如果这样的磁盘报告了一个故障,实际上可能会更好,而不是花费如此长的时间,这样操作系统或磁盘控制器就可以采取纠正措施,比如在冗余环境中将磁盘下线并报告故障。慢速磁盘是一个麻烦,特别是当它们是存储阵列呈现的虚拟磁盘的一部分时,以至于操作系统无法直接看到它们,这使得它们更难以识别。
磁盘数据控制器
机械磁盘向系统提供了一个简单的接口,意味着一个固定的每磁道扇区比率和一个连续的可寻址偏移范围。实际上发生在磁盘上的事情取决于磁盘数据控制器——这是一个由固件编程的磁盘内部微处理器。磁盘如何布置可寻址的偏移量取决于磁盘,它可以实现包括扇区分区在内的算法。这是需要注意的事情,但很难分析——操作系统无法看到磁盘数据控制器的内部情况。
固态硬盘
这些有时也被称为固态磁盘(SSD),这是指它们使用固态电子技术。存储介质采用可编程的非易失性存储器,通常比旋转磁盘具有更好的性能。没有运动部件,这些磁盘也具有物理耐用性,并且不易受振动引起的性能问题的影响。
这种磁盘类型的性能通常在不同的偏移量上保持一致(没有旋转或搜索延迟),对于给定的I/O大小是可预测的。工作负载的随机或顺序特性与旋转磁盘相比不那么重要。所有这些都使它们更容易进行研究和容量规划。然而,如果它们遇到性能病理,了解它们可能会像旋转磁盘一样复杂,这是由于它们内部的操作方式。
一些固态硬盘使用非易失性DRAM(NV-DRAM)。大多数使用闪存存储器。
Flash Memory
基于闪存内存的固态硬盘(SSD)是一种存储类型,提供了高读取性能,特别是随机读取性能,可以比旋转磁盘提高数量级。大多数采用NAND闪存存储器构建,它使用基于电子的被困电荷存储介质,在无电源状态下可以持久地存储电子[Cornwell 12]。名称“闪存”与数据写入的方式有关,这需要一次擦除整个内存块(包括多个页面,通常每页8 KBytes)并重写内容。由于这些写入开销,闪存存储器具有不对称的读/写性能:读取速度快,写入速度较慢。
闪存存储器有不同类型。单级单元(SLC)将数据位存储在单个单元中,多级单元(MLC)可以在单元中存储多个位(通常是两个,需要四个电压级别)。还有三级单元(TLC)用于存储三位(八个电压级别)。与MLC相比,SLC倾向于具有更高的性能,并且在企业使用时更受青睐,尽管成本更高。还有eMLC,这是带有高级固件的MLC,专为企业使用而设计。
控制器
SSD的控制器具有以下任务[Leventhal 13]:
输入:按页进行读写(通常为8 K字节);只能对已擦除的页面进行写入;页面以32到64块(256-512 K字节)的块进行擦除。
输出:模拟硬盘块接口:对任意扇区(512字节或4 K字节)进行读取或写入。
控制器的闪存转换层(FTL)负责在输入和输出之间进行转换,还必须跟踪空闲块。它基本上使用自己的文件系统来执行此操作,例如日志结构文件系统。
写入特性可能会对写入工作负载造成问题,特别是在写入的I/O大小小于闪存内存块大小时(可能达到512 K字节)。这可能会导致写入放大,即在擦除之前将块的余下部分复制到其他位置,并且至少会有擦除-写入周期的延迟。一些闪存驱动器通过提供由电池支持的磁盘缓冲区(基于RAM),来缓解延迟问题,以便在发生断电时可以缓冲写入并稍后写入。
我使用过的最常见的企业级闪存存储器,由于闪存内存的布局,对于4 K字节的读取和1 M字节的写入性能最佳。这些值因不同驱动器而异,并可以通过I/O大小的微基准测试找到。
由于闪存的本机操作与暴露的块接口之间存在差异,操作系统及其文件系统有改进的空间。TRIM命令就是一个例子:它通知SSD某个区域不再使用,从而使SSD更容易组装其空闲块池。(对于SCSI,可以使用UNMAP或WRITE SAME命令来实现此操作;对于ATA,可以使用DATA SET MANAGEMENT命令。)
寿命
NAND闪存作为存储介质存在各种问题,包括烧毁、数据衰减和读扰动[Cornwell 12]。这些问题可以通过SSD控制器解决,它可以移动数据以避免问题。通常会采用磨损平衡技术,将写入分散到不同的块中,以减少单个块上的写入周期,并进行内存过度配置,保留额外的内存,以在需要时进行映射。
尽管这些技术可以改善寿命,但SSD仍然具有有限数量的每个块的写入周期,这取决于闪存类型和驱动器采用的缓解特性。企业级驱动器使用内存过度配置和最可靠的闪存类型SLC,以实现100万次以上的写入周期。基于MLC的消费级驱动器可能仅提供1,000个周期。
病理学
以下是一些需要注意的闪存SSD病理学:
- 由于老化造成的延迟异常和SSD尝试更努力提取正确数据(使用ECC进行检查)
- 由于碎片化导致的较高延迟(重新格式化可能通过清理FTL块映射来解决此问题)
- 如果SSD实现了内部压缩,则吞吐性能较低
请查看关于SSD性能特性和遇到的问题的更多最新发展。
9.4.2 Interfaces
接口是驱动器支持的用于与系统通信的协议,通常通过磁盘控制器实现。以下是SCSI、SAS和SATA接口的简要概述。您需要检查当前的接口和支持的带宽是什么,因为随着新的规范的开发和采用,它们会随着时间而变化。
SCSI
SCSI(Small Computer System Interface)最初是一个并行传输总线,使用多个电连接器以并行方式传输位。最初的版本,1986年的SCSI-1,数据总线宽度为8位,允许每个时钟传输1字节,并提供5兆字节/秒的带宽。这是使用50针Centronics C50连接的。后来的并行SCSI版本使用了更宽的数据总线和更多的连接器引脚,最多可达到80针,并具有数百兆字节的带宽。由于并行SCSI是一个共享总线,可能会由于总线争用而出现性能问题。例如,预定的系统备份可能会用低优先级的I/O饱和总线。解决方法包括将低优先级设备放置在自己的SCSI总线或控制器上。在更高速度下,并行总线的时钟分频也成为一个问题,这连同其他问题(包括设备数量有限以及需要SCSI终端器包)导致转向串行版本:SAS。
SAS
串行连接SCSI接口被设计为高速点对点传输,避免了并行SCSI的总线争用问题。最初的SAS规范为3 Gbit/s,2009年增加到了6 Gbit/s,2012年增加到了12 Gbit/s。支持链路聚合,因此多个端口可以组合以提供更高的带宽。由于8b/10b编码,实际的数据传输速率为带宽的80%。其他SAS特性包括驱动器的双端口化以与冗余连接器和体系结构一起使用、I/O多路径、SAS域、热插拔以及对SATA设备的兼容性支持。这些特性通常使SAS在企业环境中更受青睐,特别是在冗余体系结构中。
SATA
出于与SCSI和SAS类似的原因,平行ATA(又称IDE)接口标准已经发展成为串行ATA接口。串行ATA于2003年创建,SATA 1.0支持1.5 Gbit/s;后续版本支持3.0和6.0 Gbit/s,并且额外的特性包括本地命令排队支持。SATA使用8b/10b编码,因此数据传输速率为带宽的80%。SATA在消费者台式机和笔记本电脑中广泛使用。
9.4.3 Storage Types
存储可以以多种方式提供给服务器;以下各节描述了四种通用架构:磁盘设备、RAID、存储阵列和网络附加存储(NAS)。
磁盘设备
最简单的架构是由操作系统独立控制的内部磁盘服务器。磁盘连接到磁盘控制器,这是主板或扩展卡上的电路,允许看到和访问磁盘设备。在这种架构中,磁盘控制器仅充当通道,以便系统可以与磁盘通信。典型的个人电脑或笔记本电脑使用这种方式连接的磁盘作为主存储。
这种架构是使用性能工具最容易分析的,因为每个磁盘对操作系统都是已知的,可以单独观察。
一些磁盘控制器支持这种架构,称为混合硬盘(JBOD)。
RAID
高级磁盘控制器可以为磁盘设备提供冗余独立磁盘阵列(RAID)架构(最初称为廉价磁盘冗余阵列[Patterson 88])。RAID可以将磁盘呈现为一个大的、快速的、可靠的虚拟磁盘。这些控制器通常包括一个内置缓存(RAM)以提高读写性能。
通过磁盘控制器卡提供RAID称为硬件RAID。RAID也可以由操作系统软件实现,但硬件RAID更受青睐,因为CPU昂贵的校验和奇偶校验计算可以在专用硬件上更快地执行。然而,处理器的进步产生了大量的周期和核心,减少了将奇偶校验计算卸载的需要。许多存储解决方案已经回到了软件RAID(例如使用ZFS),这减少了复杂性和硬件成本,并提高了操作系统的可观察性。
以下各节描述了RAID的性能特征。
类型
有各种RAID类型可满足不同的容量、性能和可靠性需求。本摘要重点关注表9.3中显示的性能特征。
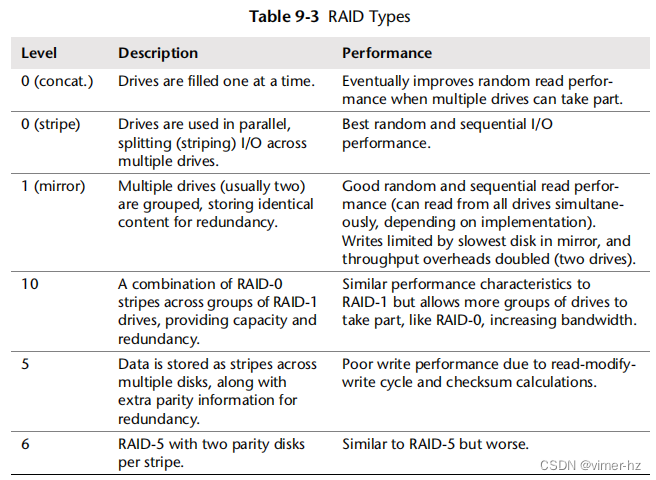
虽然RAID-0条带化性能最佳,但没有冗余性,使其在大多数生产环境中不实用。
可观察性
如前所述,使用硬件提供的虚拟磁盘设备可能会使操作系统中的可观察性更加困难,因为操作系统无法知道物理磁盘的活动情况。如果RAID是通过软件提供的,则通常可以观察到各个磁盘设备,因为操作系统直接管理它们。
读-修改-写
当数据存储为包含校验和的条带时(如RAID-5),写入I/O可能会产生额外的读取I/O和计算时间。这是因为小于条带大小的写入需要读取整个条带,修改字节,重新计算校验和,然后重新写入条带。跨越整个条带的写入可以覆盖先前的内容,而无需先读取它们。在这种环境中,通过平衡条带的大小和写入的平均I/O大小,可以减少额外的读取开销,从而提高性能。
缓存
实现RAID-5的磁盘控制器可以通过使用写回缓存来缓解读-写-修改性能。这些缓存可能是带电池备份的,以便在断电情况下仍然可以完成缓冲写入。
附加功能
请注意,高级磁盘控制器卡可以提供可能影响性能的高级功能。查阅供应商文档是一个好主意,至少要了解可能涉及的内容。例如,以下是戴尔PERC 5卡的一些功能:
- 巡逻读取:每隔几天,读取所有磁盘块并验证它们的校验和。如果磁盘正在忙于处理请求,则给予巡逻读取功能的资源会减少,以避免与系统工作负载竞争。
- 缓存刷新间隔:在将脏数据刷新到磁盘之间的时间(以秒为单位)。较长的时间可能会减少由于写入取消而导致的磁盘I/O,并实现更好的集合写入;然而,它们也可能会导致较大刷新期间更高的读取延迟。这两者都可能对性能产生重大影响。
存储阵列
存储阵列允许将许多磁盘连接到系统。它们使用高级磁盘控制器,以便可以配置RAID,并通常提供大型缓存(以GB为单位)以提高读取和写入性能。这些缓存通常也是带电池备份的,使它们可以在写回模式下运行。一个常见的策略是在电池故障时切换到写通过模式,这可能首先表现为由于等待读-修改-写周期而导致的写入性能突然下降。另一个性能考虑因素是存储阵列如何连接到系统——通常是通过外部存储控制器卡。卡和其与存储阵列之间的传输都将对IOPS和吞吐量有限制。为了在性能和可靠性上实现改进,存储阵列通常具有双连接性,意味着它们可以使用两根物理电缆连接到一个或两个不同的存储控制器卡。
网络附加存储
网络附加存储(NAS)通过现有网络使用网络协议(例如NFS、SMB/CIFS或iSCSI)提供给系统,通常是从专用系统,即NAS设备。这些是独立的系统,应该作为单独的实体进行分析。一些性能分析可能会在客户端上进行,以检查应用的工作负载和I/O延迟。网络的性能也成为一个因素,问题可能由网络拥塞和多跳延迟引起。
9.4.4 Operating System Disk I/O Stack
磁盘I/O堆栈中的组件和层次结构将取决于操作系统、版本以及所使用的软件和硬件技术。图9.6展示了一个通用模型。完整的图表请参见第3章《操作系统》。
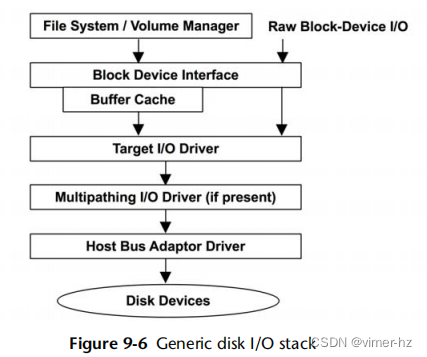
块设备接口
块设备接口是早期Unix中创建的,用于以512字节的块为单位访问存储设备,并提供缓冲区缓存以提高性能。该接口今天仍然存在于Linux和Solaris中,尽管随着其他文件系统缓存的引入,缓冲区缓存的作用已经减弱,如第8章《文件系统》所述。
Unix提供了一条绕过缓冲区缓存的路径,称为原始块设备I/O(或简称原始I/O),可以通过字符特殊设备文件使用(请参见第3章《操作系统》)。在Linux中,默认情况下这些文件已不再常见。原始块设备I/O与“直接I/O”文件系统功能有所不同,但在某些方面类似,如第8章《文件系统》所述。
块I/O接口通常可以通过操作系统性能工具(如iostat(1))观察到。它也是静态跟踪的常见位置,最近也可以通过动态跟踪进行探索。Linux通过增加了组成块层的其他功能来增强了内核的这一领域。
Linux
Linux块层在图9.7 ([2], [Bovet 05])中显示出来。
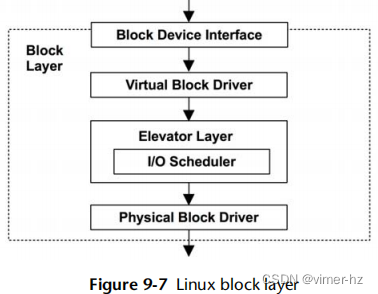
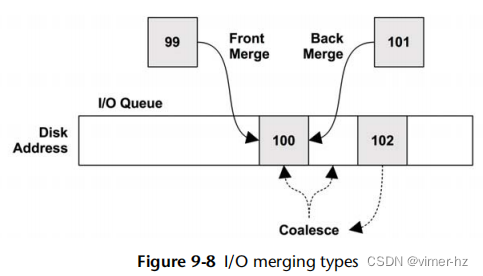
电梯层提供了通用功能,用于对请求进行排序、合并和批处理以进行传输。这些包括早期描述的电梯寻找算法(根据它们的位置对挂起的I/O进行排序以减少磁盘头旋转移动)以及在图9.8中显示的合并和合并I/O的方法。
这些功能实现了更高的吞吐量和更低的I/O延迟。I/O调度程序允许对I/O进行排队和重新排序(或重新调度),以进行优化传输,由额外的调度策略确定。这可以进一步提高性能并更公平地平衡性能,特别是对于I/O延迟较高(转动磁盘)的设备。
可用的策略包括:
- Noop:不执行调度(noop是CPU对于无操作的说法),当认为调度的开销是不必要的时候可以使用(例如,在RAM磁盘中)。
- Deadline:尝试强制执行延迟期限;例如,可以选择以毫秒为单位的读取和写入到期时间。这对于需要确定性的实时系统非常有用。它还可以解决饥饿问题:当新发出的I/O跳过队列时,导致I/O请求被磁盘资源饥饿,从而产生延迟异常值。饥饿可能是由写入饿死读取,以及由于电梯寻找和对磁盘的某一区域进行大量I/O而使I/O饥饿另一区域而导致的。截止时间调度程序部分地解决了这个问题,它使用三个单独的I/O队列:读取FIFO、写入FIFO和排序队列。有关更多内部信息,请参见[Love 10]和Documentation/block/deadline-iosched.txt。
- Anticipatory:deadline的增强版本,具有预测I/O性能的启发式方法,提高了全局吞吐量。这些可以包括在读取后暂停几毫秒,而不是立即服务写入,以预测在此期间可能会收到附近磁盘位置的另一个读取请求,从而减少整体的磁盘头寻找。
- CFQ:完全公平队列调度程序为进程分配I/O时间片,类似于CPU调度,以公平使用磁盘资源。它还允许通过ionice(1)命令为用户进程设置优先级和类别。请参阅Documentation/block/cfq-iosched.txt。
进行I/O调度后,请求被放置在块设备队列上,以被发送到设备。
Solaris
基于Solaris的内核使用简单的块设备接口,在目标驱动程序(如sd)中使用队列。高级I/O调度通常由ZFS提供,它可以优先处理和合并I/O(包括跨容量的合并)。与其他文件系统不同,ZFS是一个组合的卷管理器和文件系统:它管理自己的虚拟磁盘设备和一个I/O队列(管道)。
图9.6中显示的底层三层使用诸如以下驱动程序:
- 目标设备驱动程序:sd、ssd
- 多路径I/O驱动程序:scsi_vhci、mpxio
- 主机总线适配器驱动程序:pmcs、mpt、nv_sata、ata
所使用的驱动程序取决于服务器硬件和配置。
9.5 Methodology
该部分描述了磁盘I/O分析和调优的各种方法和练习。这些主题在表9.4中有概述。
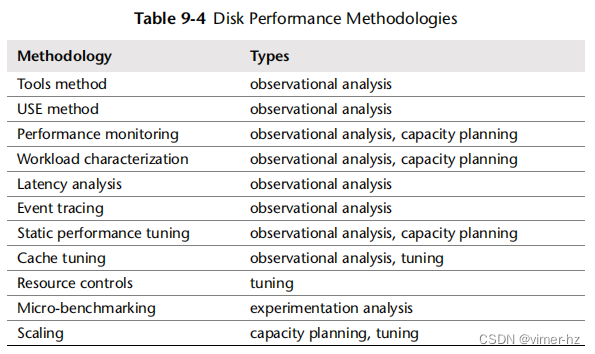
请参阅第2章“方法论”了解更多策略和这些方法的介绍。
这些方法可以单独或结合使用。在调查磁盘问题时,我的建议是按照以下顺序使用以下策略:使用USE方法、性能监控、工作负载特征化、延迟分析、微基准测试、静态分析和事件跟踪。
第9.6节“分析”展示了用于应用这些方法的操作系统工具。
9.5.1 Tools Method
工具方法是对可用工具进行迭代,检查它们提供的关键指标。虽然这是一种简单的方法,但它可能会忽视工具无法提供良好或没有可见性的问题,并且执行起来可能耗时。
对于磁盘,工具方法可以涉及以下检查:
- iostat:使用扩展模式查看繁忙的磁盘(利用率超过60%)、高平均服务时间(例如超过10毫秒)和高IOPS(取决于情况)
- iotop:识别导致磁盘I/O的进程
- dtrace/stap/perf:包括iosnoop(1)工具以详细检查磁盘I/O延迟,查找延迟异常值(例如超过100毫秒)
- 磁盘控制器特定的工具(来自供应商)
如果发现问题,要从可用工具中检查所有字段以了解更多上下文信息。有关每个工具的更多信息,请参阅第9.6节“分析”。也可以使用其他方法,这些方法可以识别更多类型的问题。
9.5.2 USE Method
USE 方法用于在性能调查的早期阶段识别所有组件中的瓶颈和错误。以下各节描述了USE 方法如何适用于磁盘设备和控制器,第9.6节“分析”展示了用于测量特定指标的工具。
磁盘设备
对于每个磁盘设备,检查以下内容:
- 利用率:设备繁忙的时间
- 饱和度:I/O 在队列中等待的程度
- 错误:设备错误
错误可能首先进行检查。它们可能被忽视,因为尽管磁盘发生故障,系统仍然能够正常运行,尽管速度较慢:磁盘通常配置为冗余磁盘池,设计用于容忍故障。除了操作系统提供的标准磁盘错误计数器外,磁盘设备可能支持更广泛的错误计数器,可以通过特殊工具(例如 SMART 数据)检索。
如果磁盘设备是物理磁盘,那么利用率应该很容易找到。如果它们是虚拟磁盘,利用率可能不反映底层物理磁盘的活动。有关此事的更多讨论,请参阅第9.3.9节“利用率”。
磁盘控制器
对于每个磁盘控制器,检查以下内容:
- 利用率:当前吞吐量与最大吞吐量的比较,以及操作速率的比较
- 饱和度:I/O 等待由于控制器饱和度造成的程度
- 错误:控制器错误
在这里,利用率指标并未以时间为单位定义,而是以磁盘控制器卡的限制为基础:吞吐量(每秒字节)和操作速率(每秒操作)。操作包括读/写和其他磁盘命令。吞吐量或操作速率可能也受到连接磁盘控制器与系统的传输的限制,就像它也可能受到从控制器到各个磁盘的传输的限制一样。每种传输都应该以相同的方式进行检查:错误、利用率、饱和度。
您可能会发现观测工具(例如 Linux 的 iostat(1))不会提供每个控制器的度量指标,而仅提供每个磁盘的度量指标。有解决方法:如果系统只有一个控制器,您可以通过对所有磁盘的度量指标求和来确定控制器的 IOPS 和吞吐量。如果系统有多个控制器,您需要确定哪些磁盘属于哪个控制器,并相应地求和度量指标。
磁盘控制器和传输的性能通常被忽视。幸运的是,它们不是系统瓶颈的常见来源,因为它们的容量通常超过所连接的磁盘的容量。如果总磁盘吞吐量或 IOPS 在不同工作负载下始终保持在某个速率,这可能是磁盘控制器或传输实际上引起问题的线索。
9.5.3 Performance Monitoring
性能监控可以识别随时间活跃的问题和行为模式。磁盘 I/O 的关键指标包括磁盘利用率和响应时间。磁盘利用率在多秒钟内达到 100% 很可能是一个问题。根据您的环境,超过 60% 的利用率也可能由于增加排队而导致性能不佳。响应时间的增加会影响性能,并可能是由于工作负载的变化或新增竞争工作负载而导致的。对于“正常”或“不良”的值取决于您的工作负载、环境和延迟要求。如果不确定,可以执行已知为良好和不良工作负载的微基准测试,以调查响应时间(例如,随机与顺序、小型与大型 I/O、单个租户与多个租户)。参见第 9.7 节,“实验”。
这些指标应该按磁盘进行检查,以查找不平衡的工作负载和性能差的单个磁盘。响应时间指标可以作为每秒的平均值进行监控,并可以包括其他值,例如最大值和标准差。理想情况下,可以检查响应时间的完整分布,例如使用直方图或热力图,以查找延迟异常值和其他模式。
如果系统施加了磁盘 I/O 资源控制,还可以收集显示这些控制何时以及何时被使用的统计信息。由于施加的限制,磁盘 I/O 可能会成为瓶颈,而不是磁盘活动本身。
利用率和响应时间显示了磁盘性能的结果。还可以添加更多指标来描述工作负载,包括 IOPS 和吞吐量,这些是用于容量规划的重要数据(请参见下一节和第 9.5.11 节,“扩展”)。
9.5.4 Workload Characterization
表征所施加的负载是容量规划、基准测试和模拟工作负载的重要练习。通过识别可以消除的不必要工作,它还可以带来一些最大的性能增益。以下是表征磁盘I/O工作负载的基本属性。它们集合起来可以提供对磁盘被要求执行的工作的近似描述:
- I/O率
- I/O吞吐量
- I/O大小
- 随机与顺序
- 读/写比率
随机与顺序、读/写比率和I/O大小在第9.3节“概念”中有描述。I/O率(IOPS)和I/O吞吐量在第9.1节“术语”中定义。
这些特征可能会随着时间的推移而变化,特别是对于应用程序和文件系统来说,它们会在间隔期间缓冲和刷新写入。为了更好地描述工作负载,捕获最大值以及平均值。更好的是,检查随时间变化的所有值的完整分布。
下面是一个示例工作负载描述,展示了如何将这些属性一起表达出来:
系统磁盘具有轻量级的随机读工作负载,平均每秒进行350次IOPS,吞吐量为3兆字节/秒,读取率为96%。偶尔会有短暂的顺序写入突发,将磁盘推动到最高4800次IOPS和560兆字节/秒。读取大小约为8千字节,写入大小约为128千字节。
除了系统范围内描述这些特征外,它们还可以用于描述每个磁盘和每个控制器的I/O工作负载。
高级工作负载特性/检查清单
可以包含更多细节来描述工作负载。以下列出了作为考虑因素的问题,这些问题也可以作为彻底研究磁盘问题时的检查清单:
- 系统范围内的IOPS速率是多少?每个磁盘?每个控制器?
- 系统范围内的吞吐量是多少?每个磁盘?每个控制器?
- 哪些应用程序或用户正在使用磁盘?
- 正在访问哪些文件系统或文件?
- 是否遇到过任何错误?这些错误是由于无效请求还是磁盘问题引起的?
- I/O在可用磁盘上的平衡程度如何?
- 每个涉及的传输总线的IOPS是多少?
- 每个涉及的传输总线的吞吐量是多少?
- 正在发出哪些非数据传输磁盘命令?
- 为什么发出磁盘I/O(内核调用路径)?
- 磁盘I/O多大程度上与应用程序同步?
- I/O到达时间的分布是什么?
针对读取和写入分别提出IOPS和吞吐量的问题。这些问题也可以随时间进行检查,以查找最大值、最小值和基于时间的变化。另请参阅第2章方法论中第2.5.10节“工作负载特性”,提供了要测量的特性的高级摘要(谁、为什么、什么、如何)。
性能特性
与工作负载特性进行比较,以下问题描述了工作负载的结果性能:
- 每个磁盘的繁忙程度如何(利用率)?
- 每个磁盘的I/O饱和程度如何(等待队列长度)?
- 平均I/O服务时间是多少?
- 平均I/O等待时间是多少?
- 是否存在高延迟的I/O异常值?
- I/O延迟的完整分布是什么?
- 系统资源控制,如I/O限制,是否存在并处于活动状态?
- 非数据传输磁盘命令的延迟是多少?
9.5.5 Latency Analysis
延迟分析涉及深入系统,以找出延迟的来源。对于磁盘而言,这通常会止步于磁盘接口:即I/O请求和完成中断之间的时间。如果这与应用程序级别的I/O延迟匹配,通常可以安全地假设I/O延迟源自磁盘,从而使您能够将调查重点放在它们上面。如果延迟不同,通过在操作系统堆栈的不同级别测量它,将能够确定其来源。图9.9显示了I/O堆栈,显示了两个I/O异常值A和B在不同级别的延迟。
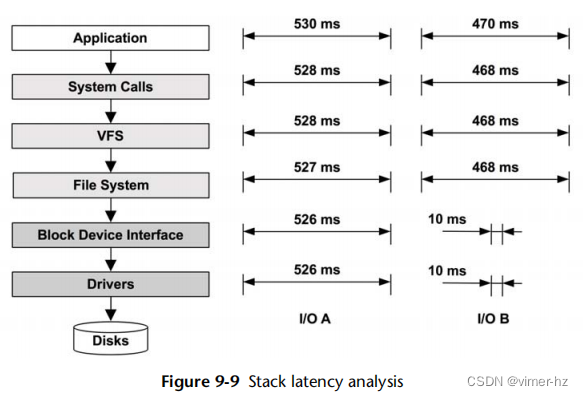
I/O A的延迟在从应用程序到磁盘驱动程序的每个级别上都相似。这种相关性指向磁盘(或磁盘驱动程序)作为延迟的原因。如果独立测量了各层,基于它们之间的相似延迟值,就可以推断出这一点。
B的延迟似乎起源于文件系统级别(锁定或排队?),较低级别的I/O延迟贡献的时间要少得多。请注意,堆栈的不同层可能会增加或减少I/O,这意味着大小、计数和延迟将在不同层之间有所不同。B示例可能是仅观察了较低级别的一个I/O(10毫秒),但未考虑用于处理相同文件系统I/O的其他相关I/O的情况(例如元数据)。
每个级别的延迟可以呈现为:
- 每个间隔的I/O平均值:通常由操作系统工具报告
- 完整的I/O分布:作为直方图或热力图;请参阅第9.6.12节“可视化”中的延迟热力图
- 每个I/O的延迟值:请参阅下一节“事件跟踪”
最后两种方法对于追踪异常值的来源并且有助于确定I/O是否已分割或合并是有用的。
9.5.6 Event Tracing
事件跟踪是指捕获和记录每个I/O事件的信息。对于观察性分析而言,这是最后的手段。由于捕获和保存这些细节,通常会增加一些性能开销,这些细节通常会被写入日志文件以供以后检查。这些日志文件应至少包含每个I/O的以下细节:
- 磁盘设备ID
- I/O类型:读或写
- I/O偏移量:磁盘位置
- I/O大小:字节
- I/O请求时间戳:当I/O被发送到设备时(也称为I/O策略)
- I/O完成时间戳:当I/O事件完成时(完成中断)
- I/O完成状态:错误
其他细节可能包括(如果适用)PID、UID、应用程序名称、文件名,以及所有非数据传输磁盘命令的事件(以及这些命令的自定义细节)。
I/O请求和完成时间戳允许计算磁盘I/O延迟。在阅读日志时,可以对每个时间戳单独进行排序以进行比较,以了解磁盘I/O如何被设备重新排序。还可以从时间戳中研究到达分布情况。
由于磁盘I/O通常被分析,因此通常会为此目的提供静态跟踪点,跟踪请求和完成。动态跟踪也可能用于高级分析,并且可能捕获以下类似的跟踪日志:
- 块设备驱动程序I/O
- 接口驱动程序命令(例如,sd)
- 磁盘设备驱动程序命令
命令意味着读取/写入和非数据传输。请参阅第9.6节“分析”中的示例。
9.5.7 Static Performance Tuning
静态性能调优关注的是配置环境的问题。对于磁盘性能,需要检查静态配置的以下方面:
- 存在多少个磁盘?属于哪些类型?
- 磁盘固件的版本是多少?
- 存在多少个磁盘控制器?属于哪种接口类型?
- 磁盘控制器卡是否连接到高速插槽?
- 磁盘控制器固件的版本是多少?
- 是否配置了RAID?具体如何配置,包括条带宽度?
- 是否可用并配置了多路径?
- 磁盘设备驱动程序的版本是多少?
- 是否存在适用于任何存储设备驱动程序的操作系统错误/补丁?
- 是否对磁盘I/O使用了资源控制?
需要注意的是,设备驱动程序和固件可能存在性能缺陷,最好通过供应商的更新来修复。
回答这些问题可以揭示被忽视的配置选择。有时,系统已配置为处理一种工作负载,然后被重新用于处理另一种工作负载。这种策略将重新审视这些选择。
在担任Sun公司ZFS存储产品的性能主管期间,我收到的最常见的性能投诉是由于错误配置引起的:使用了半个JBOD(12个磁盘)的RAID-Z2(宽条带)。我学会了首先要求配置细节(通常通过电话)然后再花时间登录系统并检查I/O延迟。
9.5.8 Cache Tuning
系统中可能存在许多不同的缓存,包括应用程序级别、文件系统、磁盘控制器以及磁盘本身的缓存。这些缓存的列表包含在第9.3.3节“缓存”中,可以按照第2章“方法论”中第2.5.17节“缓存调优”的描述进行调优。总之,检查存在哪些缓存,检查它们是否在工作,检查它们的工作效果如何,然后调整工作负载以适应缓存,并为缓存调整工作负载。
9.5.9 Resource Controls
操作系统可能提供控制功能,用于将磁盘I/O资源分配给进程或进程组。这些功能可能包括为IOPS和吞吐量设置固定限制,或者使用份额来进行更灵活的处理。这些功能的工作方式是特定于实现的,并在第9.8节“调优”中进行了讨论。
9.5.10 Micro-Benchmarking
在第8章“文件系统”中介绍了微基准测试磁盘I/O的方法,其中解释了测试文件系统I/O和测试磁盘I/O之间的区别。在这里,我们想要测试磁盘I/O,通常意味着通过操作系统的设备路径进行测试,特别是如果可用的话,要使用原始设备路径,以避免所有文件系统行为(包括缓存、缓冲、I/O分割、I/O合并、代码路径开销和偏移映射差异)。
微基准测试的因素包括:
- 方向:读取或写入
- 磁盘偏移模式:随机或顺序
- 偏移范围:完整磁盘或紧密范围(例如,仅偏移0)
- I/O大小:512字节(典型最小值)到1兆字节
- 并发性:进行中的I/O数量,或执行I/O的线程数量
- 设备数量:单个磁盘测试,或多个磁盘(用于探索控制器和总线限制)
接下来的两节展示了如何将这些因素结合起来测试磁盘和磁盘控制器的性能。有关可以用来执行这些测试的具体工具的详细信息,请参阅第9.7节“实验”。
磁盘
可以按磁盘进行微基准测试,以确定以下内容,并提供建议的工作负载:
- 最大磁盘吞吐量(每秒兆字节):128K字节读取,顺序
- 最大磁盘操作速率(IOPS):512字节读取,仅偏移0
- 最大磁盘随机读取(IOPS):512字节读取,随机偏移
- 读取延迟概要(平均微秒):顺序读取,重复进行512字节,1K,2K,4K等操作
- 随机I/O延迟概要(平均微秒):512字节读取,重复进行完整偏移跨度,仅开始偏移,仅结束偏移
这些测试也可以用于写入。使用“仅偏移0”旨在将数据缓存在磁盘缓存中,以便测量缓存访问时间。
磁盘控制器
可以通过将工作负载应用于多个磁盘来对磁盘控制器进行微基准测试,设计用于达到控制器的极限。可以使用以下内容执行这些测试,并提供磁盘的建议工作负载:
- 最大控制器吞吐量(每秒兆字节):128K字节,仅偏移0
- 最大控制器操作速率(IOPS):512字节读取,仅偏移0
逐个将工作负载应用于磁盘,观察是否存在极限。即使可能需要超过十几个磁盘才能找到磁盘控制器的极限。
9.5.11 Scaling
磁盘和磁盘控制器具有吞吐量和IOPS限制,可以通过之前描述的微基准测试来展示。调优只能提高性能达到这些限制。如果需要更多的磁盘性能,并且其他策略如缓存无效,那么就需要扩展磁盘。以下是一种简单的基于资源容量规划的方法:
1. 确定目标磁盘工作负载,按照吞吐量和IOPS来衡量。如果这是一个新系统,请参阅第2章方法论中的第2.7节容量规划。如果系统已经有了工作负载,请将用户人口表达为当前磁盘吞吐量和IOPS,并将这些数字按比例缩放到目标用户人口。(如果在同一时间不扩展缓存,则磁盘工作负载可能会增加,因为缓存每用户比例变小,将更多I/O推送到磁盘。)
2. 计算支持此工作负载所需的磁盘数量。考虑RAID配置。不要使用每个磁盘的最大吞吐量和IOPS值,因为这将导致计划将磁盘驱动器利用率达到100%,从而导致由于饱和和排队而立即出现性能问题。选择一个目标利用率(例如50%)并相应地缩放值。
3. 计算支持此工作负载所需的磁盘控制器数量。
4. 检查是否已超出传输限制,并在必要时扩展传输。
5. 计算每个磁盘I/O的CPU周期数以及所需的CPU数量。
所使用的每个磁盘吞吐量和IOPS的最大值取决于它们的类型和磁盘类型。请参阅第9.3.7节“IOPS不相等”。微基准测试可用于查找给定I/O大小和I/O类型的特定限制,而工作负载特征化可用于现有工作负载,以查看哪些大小和类型至关重要。
为了满足磁盘工作负载要求,通常会发现需要连接到存储阵列的数十个磁盘的服务器。我们曾经说,“增加更多的磁盘轴承。”现在我们可能会说,“增加更多的闪存。”
9.6 Analysis
本节介绍了用于基于Linux和Solaris的操作系统的磁盘I/O性能分析工具。有关使用它们的策略,请参见前一节。
本节中的工具列在表9.5中。
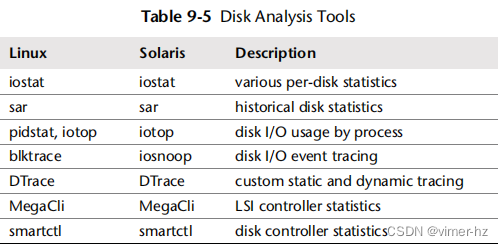
这是一些工具的选择,用于支持第9.5节“方法论”,从系统范围的统计数据开始,然后是每个进程的统计数据,再深入到事件跟踪和控制器统计数据。有关其功能的完整参考,请参阅工具文档,包括man页面。
9.6.1 iostat
iostat(1)总结了每个磁盘的I/O统计信息,提供了工作负载特征化、利用率和饱和度的指标。它可以由任何用户执行,通常是在命令行上调查磁盘I/O问题时首先使用的命令。它所提供的统计信息始终由内核维护,因此该工具的开销被认为是可以忽略不计的。
名称“iostat”缩写为“I/O统计”,尽管更好的做法可能是将其命名为“diskiostat”以反映其报告的I/O类型。这导致了偶尔的混淆,当用户知道应用程序正在执行I/O(到文件系统)但想知道为什么在iostat(1)(磁盘)中看不到时。
iostat(1)是在上世纪80年代初编写的,不同版本可用于不同的操作系统。它可以通过sysstat软件包添加到基于Linux的系统中,并且在基于Solaris的系统中默认包含。尽管其通用目的在两者中是相同的,但列和选项有所不同。请参阅您操作系统的iostat手册页面,以查看您的版本支持的内容。
以下部分描述了Linux和Solaris系统的iostat(1),其中选项和输出略有不同。iostat(1)可以使用各种选项执行,然后是一个可选的间隔和计数。
Linux
常用的iostat(1)选项如表9.6所示。
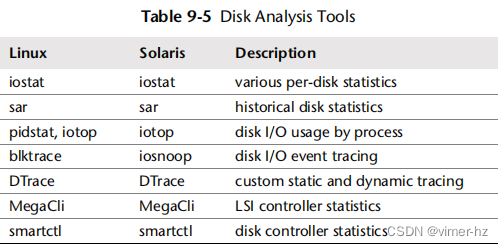
默认行为是启用-c和-d报告;如果在命令行上指定了一个选项,则另一个选项将被禁用。一些旧版本包含了一个用于NFS统计信息的选项,-n。自sysstat版本9.1.3以来,这个选项被移到了单独的nfsiostat命令中。
如果没有任何参数或选项,则打印-c和-d报告的自启动以来的摘要。这里将其作为对该工具的介绍进行了介绍;然而,预计您不会使用这种模式,因为后面介绍的扩展模式通常更有用。
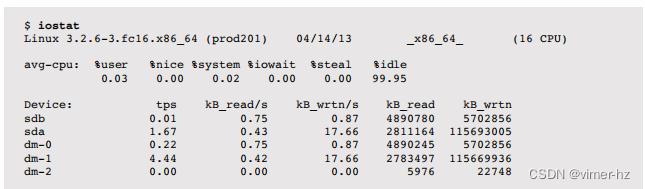
默认情况下,iostat显示系统的摘要信息,包括内核版本、主机名、日期、架构和CPU数量,然后是自启动以来的摘要统计信息,分别针对CPU(avg-cpu)和磁盘设备(在设备下)。每个磁盘设备显示为一行,列出了基本细节:
- tps:每秒事务数(IOPS)
- kB_read/s,kB_wrtn/s:每秒读取的千字节和每秒写入的千字节
- kB_read,kB_wrtn:总共读取和写入的千字节
SCSI设备,包括磁带和CD-ROM,目前在Linux版本的iostat(1)中无法看到。这导致了一些解决方法,包括SystemTap的iostat-scsi.stp脚本。还要注意,虽然iostat(1)报告了块设备的读取和写入,但根据内核的不同(例如,在blk_do_io_stat()中的逻辑),它可能会排除一些其他类型的磁盘设备命令。
如前所述,可以使用-m选项将输出报告为兆字节。在较旧版本的iostat(1)(sysstat 9.0.6及更早版本)中,默认输出使用块(每个512字节)而不是千字节。可以通过以下环境变量强制使用旧的行为:

通过使用-x选项可以选择扩展输出,提供了额外的列,对于前面介绍的许多策略非常有用。这些额外的列包括用于工作负载特征化的IOPS和吞吐量指标,用于USE方法的利用率和队列长度,以及用于性能特征化和延迟分析的磁盘响应时间。
以下输出太宽以至于无法放在一页上,因此左侧和右侧部分被显示在一起。此示例包括-d仅用于磁盘报告,-k用于千字节,以及-z用于省略所有零行(空闲设备):
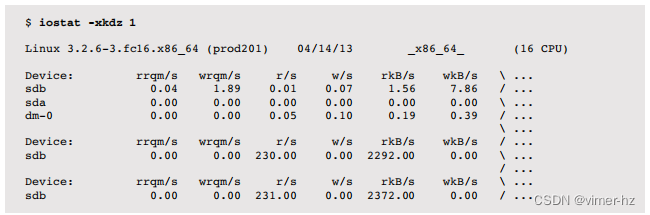
输出列如下:
- rrqm/s:每秒放置在驱动程序请求队列上并合并的读请求
- wrqm/s:每秒放置在驱动程序请求队列上并合并的写请求
- r/s:每秒发出到磁盘设备的读请求
- w/s:每秒发出到磁盘设备的写请求
- rkB/s:每秒从磁盘设备读取的千字节
- wkB/s:每秒写入到磁盘设备的千字节
在rrqm/s和wrqm/s列中的非零计数显示了在传递给设备之前合并的连续请求,以改善性能。这个度量指标也是顺序工作负载的标志。r/s和w/s列显示实际发给设备的请求。
以下是剩余的输出部分:
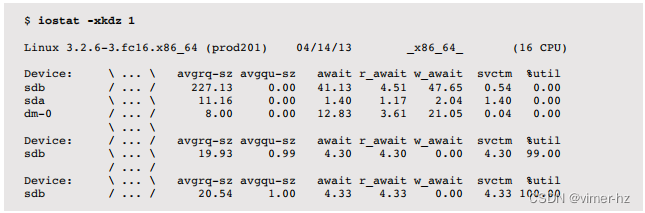
输出列如下:
- avgrq-sz:平均请求大小,以扇区(512字节)为单位
- avgqu-sz:平均等待在驱动程序请求队列中并在设备上活动的请求数量
- await:平均I/O响应时间,包括等待在驱动程序请求队列中的时间和设备的I/O响应时间(毫秒)
- r_await:与await相同,但仅针对读取(毫秒)
- w_await:与await相同,但仅针对写入(毫秒)
- svctm:磁盘设备的平均(推断)I/O响应时间(毫秒)
- %util:设备忙于处理I/O请求的时间百分比(利用率)
由于avgrq-sz是在合并之后,小尺寸(16个扇区或更少)表明无法合并的随机I/O工作负载。大尺寸可能是大I/O或合并的顺序工作负载(由早期列指示)。
交付性能的最重要度量标准是await。如果应用程序和文件系统使用一种技术来减轻写入延迟(例如,写透传),则w_await可能不那么重要,您可以转而关注r_await。
对于资源使用和容量规划,%util很重要,但请注意它仅是忙碌度(非空闲时间)的度量,并且对于由多个磁盘支持的虚拟设备可能意义不大。这些设备可能更好地通过所施加的负载来理解:IOPS(r/s + w/s)和吞吐量(rkB/s + wkB/s)。
r_await和w_await列是iostat(1)工具的较新添加;以前的版本只有await。iostat(1)的man页面警告说svctm字段将在未来的版本中被删除,因为这个度量被认为是不准确的。(我不认为它是不准确的,但我认为它可能会误导人们,因为它是一个推断值,而不是设备延迟的测量。)
以下是另一个有用的组合:
-t包括时间戳,当与其他有时间戳的来源进行比较时可以很有用。-p ALL包括每个分区的统计信息。
不幸的是,当前版本的iostat(1)不包括磁盘错误;否则,所有USE方法的度量都可以从一个工具中检查!
Solaris
列出使用-h选项的选项(尽管出现“非法选项”错误):

这包括-e和-E选项来报告错误计数。
-I选项打印计数,而不是计算的间隔摘要;它通常由定期运行iostat(1)的监控软件使用,然后对输出进行自己的计算以生成摘要。

从左到右,默认输出显示终端(tty)的输入和输出字符(tin,tout),然后是最多三组列(kps,tps,serv)用于磁盘设备,然后是用于CPU统计信息的一组列(cpu)。在这个系统上,显示的磁盘设备是ramdisk1,sd0和sd1。更多设备没有以这种方式显示,因为iostat(1)试图保持80字符宽度的输出。
磁盘设备列是:
- kps:每秒读写的千字节
- tps:每秒事务数(IOPS)
- serv:服务时间,毫秒
此示例使用-n选项使用磁盘设备的描述性/dev名称,而不是内核实例名称,并使用-z选项省略所有零行(空闲设备):


输出列是:
- r/s, w/s:每秒读取次数,每秒写入次数
- kr/s, kw/s:每秒读取的千字节数,每秒写入的千字节数
- wait:块驱动程序队列中等待的请求平均数量
- actv:设备上已发出并处于活动状态的请求的平均数量
- wsvc_t:在块驱动程序队列中等待的平均时间(毫秒);wsvc_t表示等待服务时间
- asvc_t:设备上活动的平均时间(毫秒);asvc_t表示活动服务时间,尽管这实际上是平均设备I/O响应时间
- %w:I/O在等待队列中存在的时间百分比
- %b:I/O忙碌的时间百分比(利用率)吞吐量
平均读取或写入I/O大小不包括在内(它在Linux版本中可用),但可以通过将IOPS速率除以来轻松计算,例如,平均读取大小=(kr/s)/(r/s)。
另一个有用的组合是
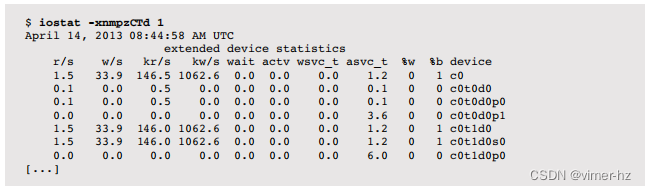
使用-C可以显示每个控制器的统计信息,使用-p可以显示每个分区的统计信息,并且可以使用-Td对输出进行时间戳标记。
可以使用-e选项将错误计数器添加到输出中:
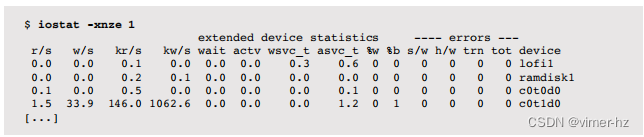
然而,除非您的设备正在积极地遇到错误,否则每个间隔的摘要可能并不那么有用。要仅检查自启动以来的计数,请使用-E选项获取不同的iostat输出格式:
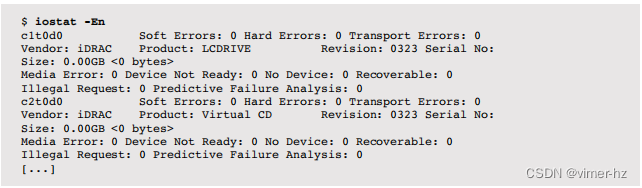
软错误(在-e输出中为s/w)是可恢复的错误,可能会导致性能问题。硬错误(来自-e输出的h/w)对磁盘不可恢复,尽管它们可能可由更高级别的架构(如RAID)恢复,这允许系统继续运行,但通常也会导致性能问题(例如,I/O超时延迟,随后是服务降级)。
可以使用更简单的方式阅读错误计数器:

使用iostat(1M)可以推导出USE方法:
- %b:显示磁盘利用率。
- actv:大于一的数字表示饱和:在设备中排队。对于前端连接多个物理设备的虚拟设备,这更难确定(这取决于RAID策略);大于设备数量的actv可能表明设备饱和。
- wait:大于零的数字表示饱和:在驱动程序中排队。
- 错误总数:总错误计数。
正如9.4.1节“磁盘类型”中早期“懒惰磁盘”部分所述,可能存在错误计数未增加的磁盘问题。希望这种情况很少发生,您不会遇到它。以下是此类问题的示例屏幕截图:
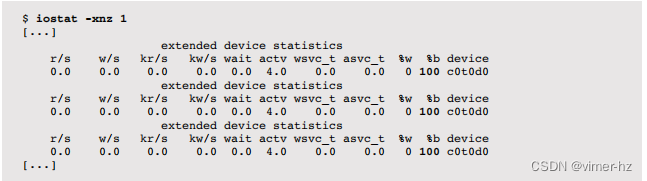
请注意,磁盘处于100%繁忙状态,但没有执行I/O操作(r/s和w/s的计数为零)。这个特定的示例来自于RAID控制器的问题。如果这种情况持续了很短的时间,将引入多秒级的I/O延迟,从而导致性能问题。如果持续时间更长,系统可能会出现挂起的情况。
9.6.2 sar
系统活动报告工具sar(1)可用于观察当前活动,并可配置为存档和报告历史统计数据。在本书的各个章节中提到了sar(1),因为它提供了不同的统计信息。
使用-d选项打印sar(1)磁盘摘要,以下示例演示了每秒一个间隔。
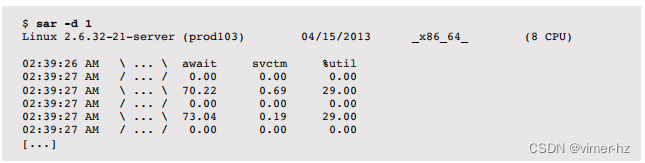
Linux
这个磁盘摘要输出很宽,这里分为两部分列出:
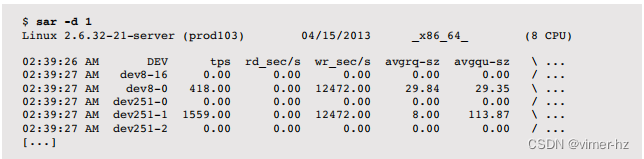
以下是剩余的列:
许多列与iostat(1)相似(请参阅前面的描述),但有以下区别:
- tps:每秒设备数据传输次数
- rd_sec/s、wr_sec/s:每秒读取和写入扇区(每扇区512字节)
Solaris
以下是使用1秒间隔运行sar(1)来报告当前活动的命令:
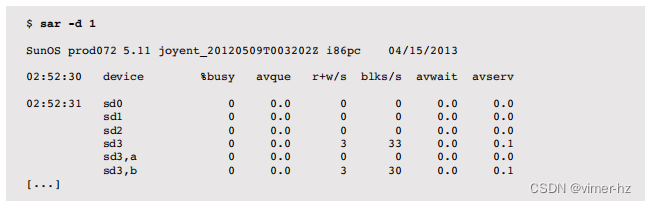
输出列类似于iostat(1M)的扩展模式,但具有不同的名称。
例如,%busy对应iostat(1M)中的%b,avwait和avserv被称为iostat(1M)中的wsvc_t和asvc_t。
9.6.3 pidstat
Linux的pidstat(1)工具默认打印CPU使用情况,并包含一个-d选项用于磁盘I/O统计信息。这在2.6.20及更高版本的内核上可用。例如:

列包括:
- kB_rd/s:每秒读取的千字节
- kB_wd/s:每秒写入的千字节
- kB_ccwr/s:每秒取消写入的千字节(例如,在刷新之前被覆盖)
只有超级用户(root)可以访问他们不拥有的进程的磁盘统计信息。这些信息通过/proc/PID/io读取。
9.6.4 DTrace
DTrace可以用于从内核内部检查磁盘I/O事件,包括块设备接口I/O、I/O调度器事件、目标驱动程序I/O和设备驱动程序I/O。这些功能支持工作负载特征化和延迟分析。以下各节介绍了用于磁盘I/O分析的DTrace,演示了应该适用于基于Linux和Solaris的系统的功能。除非特别指出是针对Linux的,否则这些示例均取自基于Solaris的系统。在第4章“可观察性工具”中包含了一个DTrace入门。用于跟踪磁盘I/O的DTrace提供程序包括表9.7中列出的那些。
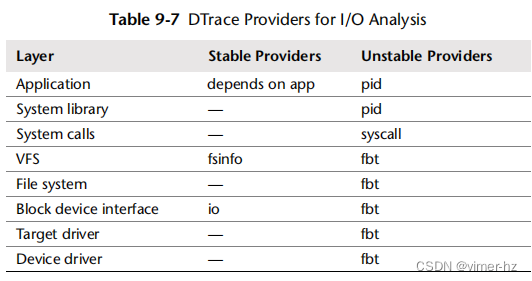
应尽可能始终使用稳定的提供程序;然而,对于磁盘I/O堆栈,确实只有io提供程序可用于进行严肃的分析。检查您的操作系统是否已发布了更稳定的提供程序用于其他领域。如果没有,可以使用不稳定的接口提供程序,尽管脚本将需要更新以匹配软件更改。
io Provider
io提供程序提供了对块设备接口的可见性,并可用于表征磁盘I/O并测量延迟。探针包括:
- io:::start:向设备发出了一个I/O请求。
- io:::done:设备上的一个I/O请求已完成(完成中断)。
- io:::wait-start:一个线程开始等待一个I/O请求。
- io:::wait-done:一个线程完成了对一个I/O请求的等待。
在Solaris上列出这些:
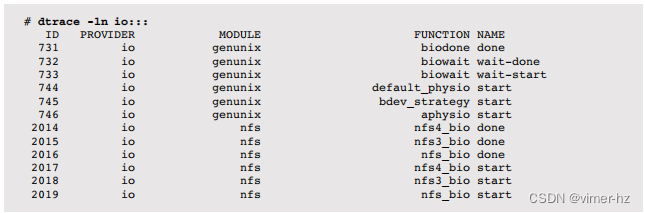
MODULE和FUNCTION列显示了探针的位置(作为实现细节,不属于稳定接口的一部分)。请注意,在Solaris上,nfs客户端I/O也通过io提供程序进行跟踪,如nfs模块探针所示。
这些探针具有稳定的参数,提供了有关I/O的详细信息,包括:
- args[0]->b_count:I/O大小(字节)
- args[0]->b_blkno:设备I/O偏移量(块)
- args[0]->b_flags:按位标志,包括B_READ以指示读取I/O
- args[0]->b_error:错误状态
- args[1]->dev_statname:设备实例名称+实例/次要号码
- args[1]->dev_pathname:设备路径名
- args[2]->fi_pathname:文件路径名(如果已知)
- args[2]->fi_fs:文件系统类型
除了标准的DTrace内置函数外,这些参数还允许构建一些强大的单行命令。
事件跟踪
以下是每个磁盘I/O请求的跟踪,包括PID、进程名称和I/O大小(字节):
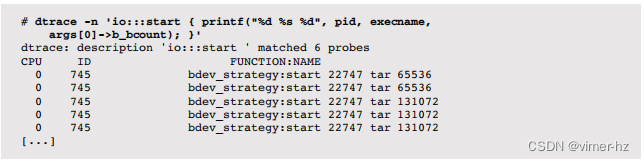
这个单行命令使用printf()语句打印每个I/O的详细信息。输出显示PID为22747的tar进程发出了五个I/O请求,大小为64或128KB。在这种情况下,当发出I/O请求时,应用程序线程仍处于CPU上,使得可以通过execname看到它。(在某些情况下,这将以异步方式发生,并且将标识内核、sched。)
I/O大小摘要
通过应用程序名称总结磁盘I/O大小:
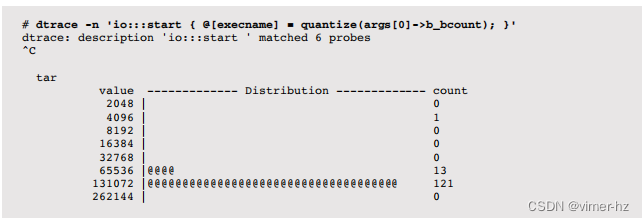

与使用DTrace报告平均、最小或最大I/O大小不同,这个单行命令生成了一个分布图来可视化完整的分布。值列显示了字节范围,计数列显示了在该范围内的I/O数量。在跟踪过程中,名为tar的进程执行了121个I/O,大小在128到256KB之间(即131,072到262,143字节)。内核(sched)具有一个有趣的分布(看起来是双峰的),这种分布无法通过单一的平均值来很好地理解。
除了按进程名称(execname)总结外,I/O大小还可以按以下方式进行总结:
- 设备名称:使用args[1]->dev_statname
- I/O方向(读/写):使用args[0]->b_flags & B_READ ? "read" : "write"
除了大小(args[0]->b_count)之外,还可以总结其他特征。例如,可以检查磁盘上的位置以测量I/O搜索。
I/O Seek Summary
I/O搜索摘要跟踪相同应用程序对同一设备连续I/O之间的搜索距离,并将其按进程报告为直方图。这已经变得太长,无法作为一个单行命令,因此已经实现为以下的DTrace脚本(diskseeksize.d):

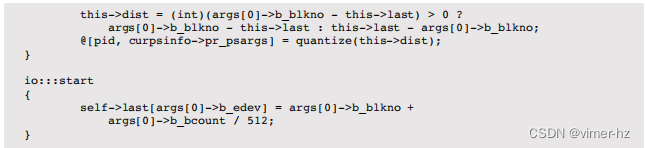
该脚本计算了一个I/O与前一个I/O的最后一个扇区(起始偏移量+大小)之间的扇区距离。这是针对每个设备进行跟踪的,同时也通过每个线程(使用self->)进行跟踪,以便可以将不同进程的工作负载模式分离和研究。
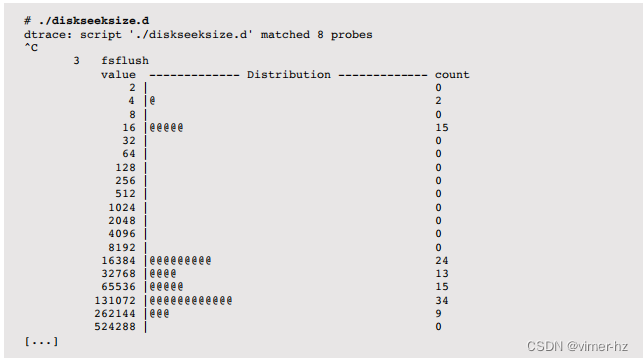
这显示了来自fsflush线程的I/O,通常会寻求超过8,192个块。如果搜索距离主要为0,那么这表明是顺序工作负载。
I/O Latency Summary
这个脚本(disklatency.d)跟踪块I/O的开始和完成事件,并将延迟分布总结为直方图:

在开始探针上记录了一个时间戳,以便在完成时计算时间差。这个脚本的技巧在于将开始时间与结束时间戳关联起来,因为可能有很多I/O正在进行中。使用了一个关联数组,其键是I/O的唯一标识符(恰好是缓冲结构的指针)。
执行中:
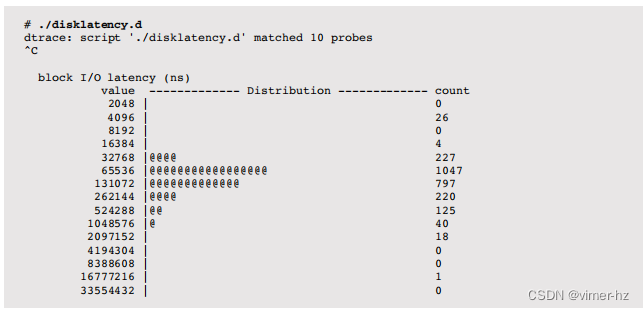
在跟踪过程中,大多数I/O在65,536到262,143纳秒的范围内(0.07到0.26毫秒)。最慢的是在16到33毫秒范围内的单个I/O。这种直方图输出非常适合识别这样的I/O延迟异常值。
这里,对所有设备的I/O进行了总结。该脚本可以改进为根据设备、进程ID或其他标准生成单独的直方图。
I/O Stacks
I/O堆栈频率计算了发出I/O请求的调用内核堆栈,直到块设备驱动程序(io:::start探针的位置)。在基于Solaris的系统上:
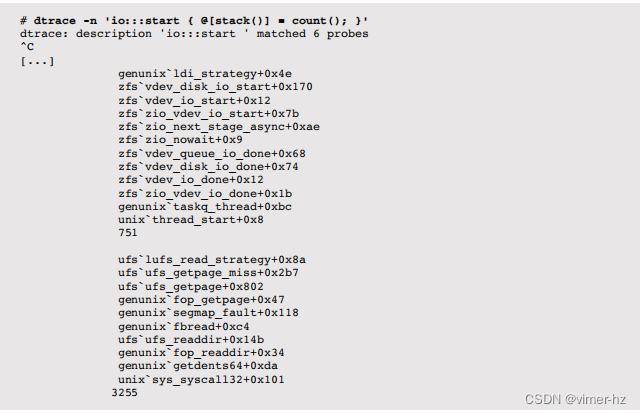
输出内容很长,显示了通过内核所采取的确切代码路径,导致发出磁盘I/O,然后是每个堆栈的计数。在调查超出工作负载预期速率的意外额外I/O(异步、元数据)时,这通常很有用。顶部堆栈显示了来自任务队列线程运行ZIO管道的异步ZFS I/O,底部显示了由getdents()系统调用发起的同步UFS I/O。
在Linux上,这是通过对内核submit_bio()函数进行动态跟踪实现的(io:::start探针仍在为此原型机开发中):
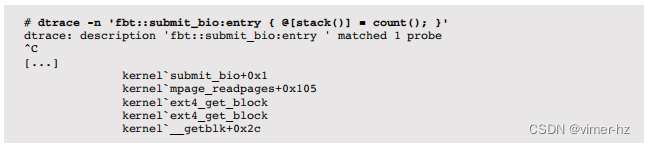
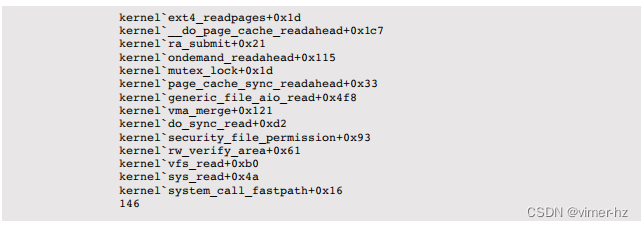
该路径显示了祖先关系,从系统调用接口(底部开始),VFS,页面缓存,到ext4。
这些堆栈的每一行都可以通过DTrace的fbt提供程序进行单独跟踪。请参阅第9.8节《调优》,了解通过fbt跟踪sd_start_cmds()函数的示例。
SCSI 事件
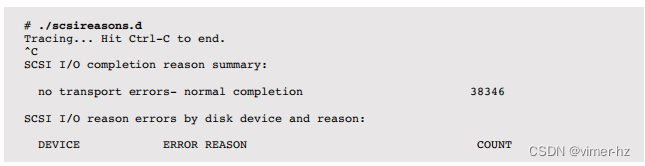
这个脚本(scsireasons.d)演示了在SCSI层进行跟踪,报告带有描述完成原因的特殊SCSI代码的I/O完成情况。以下是关键摘录(有关完整脚本参考,请参见下一节):

该脚本使用关联数组将SCSI原因整数转换为人类可读的字符串。在scsi_destroy_pkt()中引用了这一点,在那里,原因字符串被频率计数。在跟踪过程中没有发现错误。
高级跟踪
在需要进行高级分析时,动态跟踪可以更详细地探索内核I/O堆栈的每一层。为了提供对其功能的了解,表9.8显示了来自DTrace [Gregg 11](该书有140页)磁盘I/O章节的脚本(这些脚本也可以在线获取 [4])。
虽然这种观测度令人难以置信,但这些动态跟踪脚本与特定的内核内部绑定在一起,将需要维护以适应新内核版本的变化。
9.6.5 SystemTap
SystemTap也可以用于Linux系统,用于对磁盘I/O事件进行动态跟踪,并使用其ioblock提供程序进行静态跟踪。请参阅第4章《可观测性工具》中的第4.4节《SystemTap》,以及附录E,以获取有关转换前面的DTrace脚本的帮助。
9.6.6 perf
Linux perf(1)工具(在第6章《CPU》中介绍)提供了块跟踪点,可以用于跟踪一些基本信息。以下是它们的列表:
例如,以下跟踪块设备问题,并提供调用图,以便可以检查堆栈跟踪。提供了一个sleep 10命令作为跟踪持续时间。
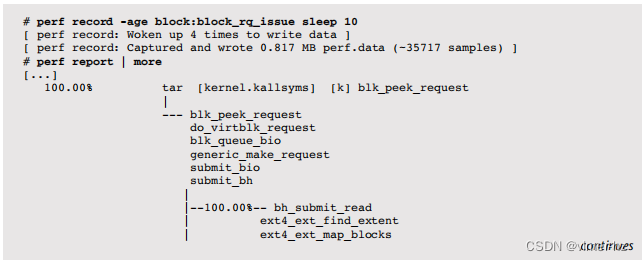

输出很长,显示了导致块设备I/O的不同代码路径。这里给出的部分是用于ext4目录读取的。
9.6.7 iotop
iotop(1)是一个包含磁盘I/O列的top版本。第一个版本于2005年编写,使用了基于Solaris的系统的DTrace [McDougall 06b],作为一个较早版本的psio(1)工具(带有I/O的进程状态,该工具使用了DTrace之前的跟踪框架)的top风格版本。iotop(1)及其伴侣iosnoop(1M)现在默认随许多具有DTrace的系统一起提供,包括Mac OS X和Oracle Solaris 11。在Linux上也有基于内核账户统计信息的iotop(1)工具可用[5]。
Linux
iotop(1)需要内核版本2.6.20(根据后端口状态可能稍早一些)或更高版本,以及以下内核选项:CONFIG_TASK_DELAY_ACCT、CONFIG_TASK_IO_ACCOUNTING、CONFIG_TASKSTATS和CONFIG_VM_EVENT_COUNTERS。
用法
提供了各种选项以自定义输出:
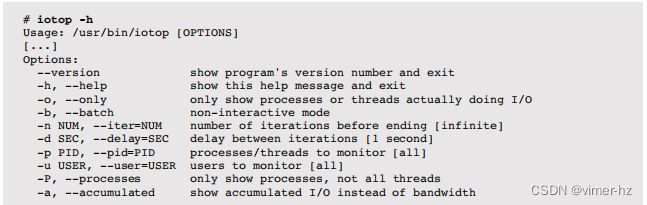

默认情况下,iotop(1)会清除屏幕并打印一秒钟的摘要。
批处理模式
批处理模式(-b)可用于提供滚动输出(不清除屏幕);以下示例演示了仅包含I/O进程(-o)和5秒间隔(-d5)的情况:
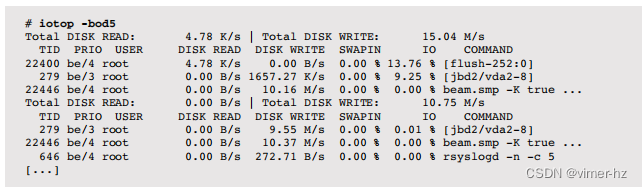
输出显示了beam.smp进程(Riak)执行约10兆字节/秒的磁盘写入工作负载。
其他有用的选项包括-a,用于累积I/O而不是间隔平均值,以及-o,用于仅显示执行磁盘I/O的那些进程。
Solaris
iotop(1)可能已经在/opt/DTT或/usr/DTT目录下可用。它也可以在DTraceToolkit中找到(源自该工具包)。
用法
以下是iotop(1)的用法示例:

默认设置
默认情况下,输出间隔为5秒,使用统计数据以字节为单位呈现:

在此示例中,tar(1)命令在这5秒的间隔内从sd5设备读取了约3GB的数据。
利用率
-P选项显示磁盘利用率,-C打印滚动输出:
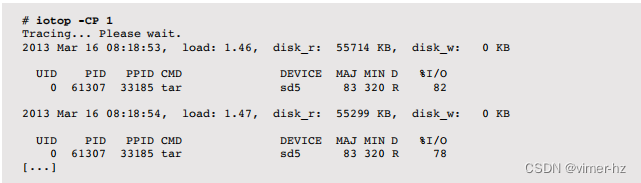
这显示了tar(1)命令使sd5磁盘的使用率约为80%。
disktop.stp
另一个基于SystemTap的iotop(1)版本被命名为disktop.stp。名称“disktop”应该比“iotop”更好,因为“io”具有歧义,可能意味着应用程序级(VFS)或磁盘级别。不幸的是,disktop.stp 中的“disk”指的是“从用户空间的角度读写磁盘”,并通过跟踪VFS 来实现这一点。这意味着对于从文件系统缓存大量返回的应用程序,disktop.stp 的输出可能与iostat(1)完全不匹配。
9.6.8 iosnoop
iosnoop(1M)通过块设备接口同时跟踪所有磁盘,并为每个磁盘I/O打印一行输出。提供了各种命令行选项以输出额外的详细信息,并且由于iosnoop(1M)是一个简短的DTrace脚本,可以轻松修改以提供更多功能。这个工具对于先前的跟踪和延迟分析策略非常有用。
用法
以下是iosnoop(1)的用法示例:
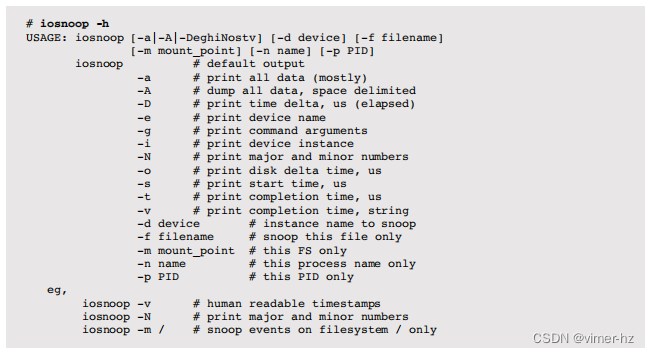
跟踪磁盘I/O
在启动(非缓存的)vim文本编辑器时的磁盘I/O:

列标识如下:
- PID:进程ID
- COMM:进程名称
- D:方向(R = 读取,W = 写入)
- BLOCK:磁盘块地址(扇区)
- SIZE:I/O大小(字节)
- PATHNAME:文件系统路径名(如果适用且已知)
前面的示例跟踪了一个UFS文件系统,其中路径名通常是已知的。路径名未知的情况包括UFS磁盘文件系统元数据以及当前所有ZFS I/O。有一个功能请求,要求将ZFS路径名添加到DTrace io提供程序中,这将被iosnoop(1M)所见。(与此同时,可以通过对内核进行动态跟踪来获取ZFS路径名。)
时间戳
以下显示了一个运行在ZFS上的Riak云数据库(使用Erlang虚拟机beam.smp)。它正在使用来自硬件存储控制器的虚拟磁盘。
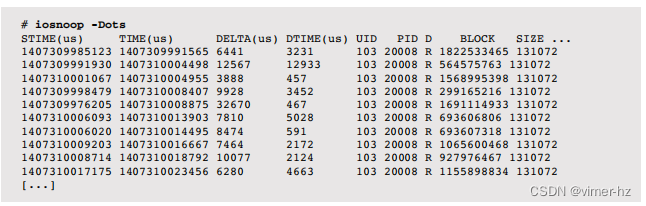
宽输出已被截断以适应;右侧缺失的列是 COMM 和 PATHNAME,它们都包含了 beam.smp <none>。
输出显示了一个128 K字节读取的工作负载,具有某种随机的块地址。iostat(1)确认了这个工作负载的结果:

iostat(1)没有显示I/O响应时间的变化,但是iosnoop的DELTA(us)列(微秒)显示了这种变化。在这个样本中,I/O的响应时间介于3,888到32,670微秒之间。DTIME(us)列显示了从I/O完成到上一个磁盘事件的时间,作为对该I/O实际磁盘服务时间的估计。
iosnoop(1M)的输出大致按照完成时间排序,由TIME(us)列显示。请注意,起始时间STIME(us)并不完全按照相同的顺序排列。这表明磁盘设备已经重新排序了请求。最慢的I/O(32,670)是在1407309976205之前发出的,而之前已完成的I/O是在1407310001067发出的。对于旋转磁盘,重新排序的原因通常可以通过检查磁盘地址(BLOCK)并考虑电梯搜索算法来看到。在这个例子中并不明显,因为它是在几个物理磁盘上构建的虚拟磁盘,偏移映射仅由磁盘控制器知道。
在繁忙的生产服务器上,仅仅几秒的跟踪就可以生成数百行的iosnoop(1M)输出。这非常有用(可以研究到底发生了什么),但也可能需要花费大量时间来阅读。考虑使用另一种工具(比如散点图,在第9.6.12节中介绍)来可视化输出,以便更快地考虑。
9.6.9 blktrace
blktrace(8)是Linux上用于跟踪块设备I/O事件的自定义跟踪工具,包括一个内核组件来跟踪和缓冲数据(后来被移动到tracepoints),以及一个用于控制和报告的机制,供用户态工具使用。这些工具包括blktrace(8),blkparse(1)和btrace(8)。
blktrace(8)使内核块驱动程序跟踪并检索原始跟踪数据,可以使用blkparse(1)来处理以产生可读的输出。为了方便起见,btrace(8)工具同时运行blktrace(8)和blkparse(1),因此以下两者是等效的:

默认输出
以下显示了btrace(8)的默认输出,并捕获了由cksum(1)命令执行的单个磁盘读取事件:
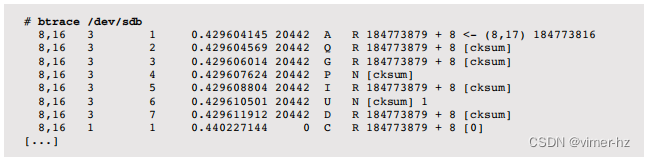
对于这个单个磁盘I/O,报告了八行输出,显示了涉及块设备队列和设备的每个动作(事件)。
默认情况下,有七列:
1. 设备的主要和次要编号
2. CPU ID
3. 序列号
4. 动作时间,以秒为单位
5. 进程ID
6. 动作标识符(见下文)
7. RWBS描述:可能包括R(读取)、W(写入)、D(块丢弃)、B(屏障操作)、S(同步)
这些输出列可以使用 -f 选项进行自定义。它们后面是基于动作的自定义数据。
最终的数据取决于动作。例如,184773879 + 8 [cksum] 表示在块地址184773879处的大小为8个(扇区)的I/O,来自名为 cksum 的进程。
动作标识符
这些在blkparse(1)手册页中有描述:


这个列表被包含在这里,因为它还显示了blktrace框架的可见性。
动作过滤
blktrace(8)和btrace(8)命令可以过滤动作,只显示感兴趣的事件类型。例如,要仅跟踪D动作(已发出的I/O),请使用过滤选项 -a issue:

其他过滤器在blktrace(8)手册页中有描述,比如仅跟踪读取(-a read)、写入(-a write)或同步操作(-a sync)。
9.6.10 MegaCli
磁盘控制器(主机总线适配器)由系统外部的硬件和固件组成。即使是操作系统分析工具,甚至是动态跟踪,也无法直接观察它们的内部。有时,可以通过仔细观察输入和输出(包括通过静态或动态内核跟踪),来推断它们的工作方式,以了解磁盘控制器如何响应一系列的I/O操作。
对于特定的磁盘控制器,例如LSI的MegaCli,有一些分析工具可供使用。以下是最近的控制器事件:
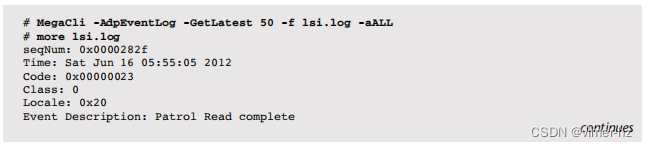
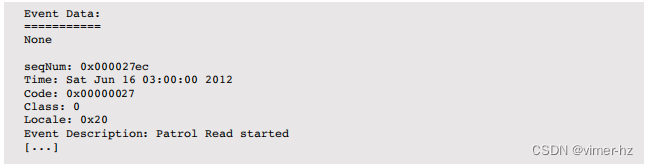
最后两个事件显示,在凌晨3:00到5:55之间发生了一次巡逻读取(可能会影响性能)。巡逻读取在第9.4.3节“存储类型”中提到过;它们读取磁盘块并验证它们的校验和。
MegaCli有许多其他选项,可以显示适配器信息、磁盘设备信息、虚拟设备信息、外壳信息、电池状态和物理错误。这些帮助识别配置和错误问题。即使有了这些信息,有些问题仍然很难分析,比如为什么特定的I/O操作需要几百毫秒。
查看供应商文档,了解磁盘控制器分析的接口情况,如果有的话。
9.6.11 smartctl
磁盘具有控制磁盘操作的逻辑,包括排队、缓存和错误处理。与磁盘控制器类似,操作系统无法直接观察磁盘的内部行为,通常是通过观察I/O请求及其延迟来推断。
许多现代驱动器提供SMART(自我监控、分析和报告技术)数据,其中包含各种健康统计信息。以下是在Linux上使用smartctl(8)显示的样本数据(这是访问虚拟RAID设备中的第一个磁盘,使用-d megaraid,0):
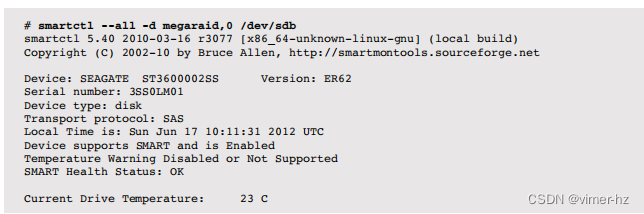
虽然这非常有用,但它不能解决有关单个缓慢磁盘I/O的问题,类似于内核跟踪框架。
9.6.12 Visualizations
有许多类型的可视化工具可帮助分析磁盘I/O性能。本节将使用各种工具的截图来演示这些工具。关于一般可视化工具的讨论,请参阅第2章方法论中的第2.10节“可视化”。
折线图
性能监控解决方案通常将磁盘IOPS、吞吐量和利用率随时间的测量值绘制为折线图。这有助于说明基于时间的模式,例如一天中负载的变化,或者像文件系统刷新间隔这样的周期性事件。
注意正在绘制的度量标准。跨所有磁盘设备的平均值可能隐藏了不平衡的行为,包括单个设备的异常值。跨较长时间段的平均值也可能隐藏了较短期的波动。
散点图
散点图对于可视化I/O跟踪数据非常有用,这些数据可能包含成千上万个事件。图9.10中的示例绘制了来自生产MySQL数据库服务器的1,400个I/O事件,使用iosnoop捕获,并使用R绘制。
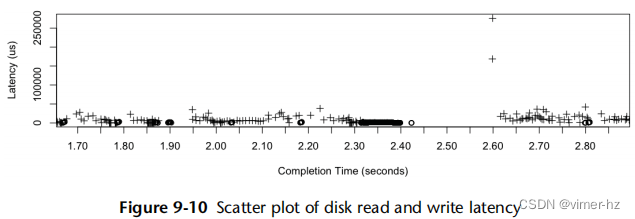
散点图根据它们的完成时间(x轴)和I/O响应时间(y轴)显示了读取(+)和写入(o)。其他维度也可以绘制,例如,在y轴上绘制磁盘块地址。
这里可以看到几个读取异常值,延迟超过150毫秒。以前不知道这些异常值的原因。这个散点图以及其他包含类似异常值的图表显示,它们发生在大量写入之后。这些写入具有较低的延迟,因为它们从RAID控制器的写回缓存返回,该缓存在返回完成后将它们写入设备。有人怀疑这些读取在排队等待设备写入。
这个散点图显示了一个服务器的几秒钟。多个服务器或更长的时间间隔可以捕获更多事件,当绘制时会合并在一起,变得难以阅读。在那时,考虑使用热图(请参阅本章后面的“延迟热图”部分)。
偏移热图
图9.11显示了一个热图(更正式地称为列量化),用于可视化磁盘I/O访问模式。
磁盘偏移(块地址)显示在y轴上,时间显示在x轴上。每个像素根据在该时间和延迟范围内落入其中的I/O数量着色,数字越大颜色越深。可视化的工作负载是一个文件系统存档,从块0逐渐遍布整个磁盘。较深的线表示顺序I/O,较浅的云表示随机I/O。
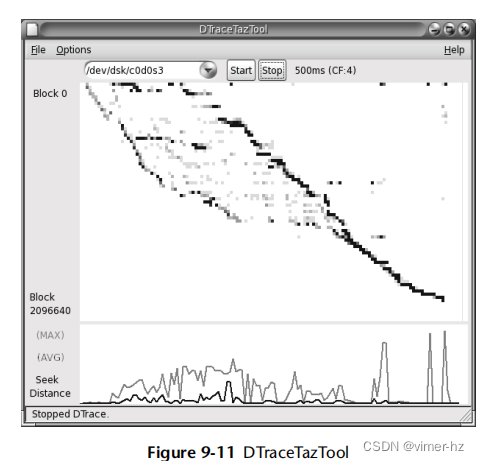
这种可视化是由Richard McDougall在1995年引入的,使用taztool。此屏幕截图来自我在2006年编写的DTrace版本的taztool,名为DTraceTazTool。磁盘I/O偏移热图后来出现在其他工具中,包括Sun ZFS存储设备分析、Joyent云分析和seekwatcher(Linux)。
延迟热图
热图的另一种用途是显示I/O延迟的完整分布[Gregg 10b],如图9.12所示。
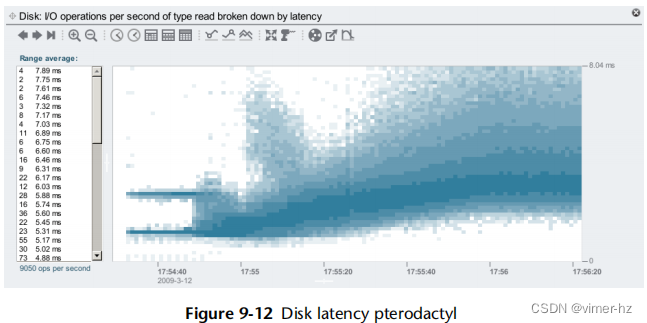
y轴显示I/O响应时间(延迟),x轴显示时间的流逝。可视化的工作负载是实验性的,一次对多个磁盘应用顺序读取,以探索总线和控制器的限制。结果的热图出乎意料(它被描述为翼龙),显示了仅考虑平均值时可能遗漏的信息。这个特定的屏幕截图来自Oracle ZFS存储设备上的Analytics。
利用率热图
每个设备的利用率也可以显示为热图,以便识别设备利用率平衡和个别异常值;参见图9.13。
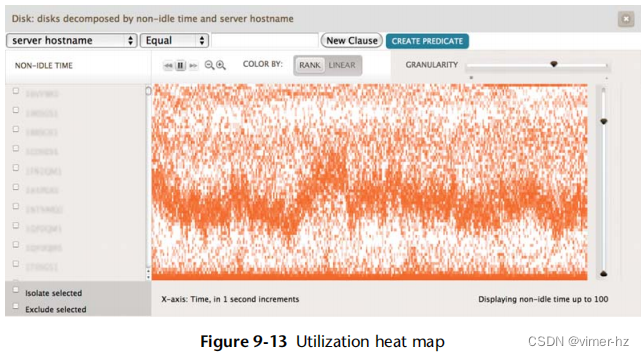
设备利用率位于y轴,时间位于x轴,利用率和时间范围内设备数量由颜色深浅表示(颜色越深表示设备越多)。这个热图显示许多设备是空闲的或接近空闲(底部的深色区域),一组设备的利用率相似,变化在约20%至50%之间。右上角有一条深线,显示一些设备已达到100%。(这个特定的可视化是交互式的,所以这些像素可以点击以显示负责的主机和设备。)
我创建了这种可视化类型,以帮助识别单个的高热磁盘,包括之前描述的懒惰磁盘。这个屏幕截图来自Joyent Cloud Analytics,它显示了超过200台物理服务器云中的磁盘设备利用率。
9.7 Experimentation
本节介绍了用于主动测试磁盘I/O性能的工具。请参阅第9.5.10节“微基准测试”,了解建议的方法论。
在使用这些工具时,最好让iostat(1)持续运行,以便可以立即对任何结果进行双重检查。
9.7.1 Ad Hoc
dd(1)命令(设备到设备的复制)可用于执行顺序磁盘性能的临时测试。例如,使用1兆字节的I/O大小进行顺序读取测试:

基于Solaris系统的dd(1)版本目前不会打印这个摘要。理想情况下,磁盘设备路径将是字符特殊的,以便直接应用请求的工作负载。Solaris系统默认提供这些特殊路径,在/dev/rdsk下。在Linux上,如果可用,raw(8)命令可以创建字符特殊版本,在/dev/raw下。如果使用块特殊文件,则要考虑缓冲。
顺序写入可以类似地进行测试;但是,请注意可能会销毁磁盘上的所有数据,包括主引导记录和分区表!
9.7.2 Custom Load Generators
为了测试定制的工作负载,您可以编写自己的负载生成器,并使用iostat(1)来测量结果性能。自定义负载生成器可以是一个简短的C程序,它打开设备路径并应用预期的工作负载。在Linux上,可以使用O_DIRECT打开块特殊设备文件,以避免缓冲。如果您使用更高级的语言,请尝试使用也避免缓冲的系统级接口(例如,在Perl中使用sysread())。
9.7.3 Micro-Benchmark Tools
可用的磁盘基准测试工具包括,在Linux上,例如hdparm(8):

-T选项测试缓存读取,而-t选项测试磁盘设备读取。结果显示了在磁盘缓存命中和未命中之间的显著差异。
请仔细研究工具文档以了解任何注意事项,并参阅第12章“基准测试”,以了解有关微基准测试的更多背景知识。还请参阅第8章“文件系统”,了解通过文件系统测试磁盘性能的工具,其中有许多其他工具可用。
9.7.4 Random Read Example
作为一个示例实验,编写了一个定制工具来执行磁盘设备路径的随机8K字节读取工作负载。并发地运行了从一个到五个实例的该工具,并运行了iostat(1)。以下是基于Linux和Solaris系统的结果。
Linux
已删除写入列(全部为零):
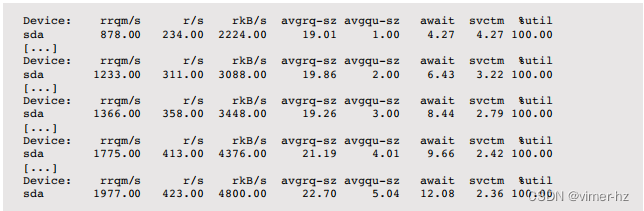
请注意avgqu-sz的逐步增加,以及await的延迟增加。
Solaris
来自基于Solaris的系统的相同实验:

请注意actv的逐步增加,以及asvc_t的延迟增加。这是在由RAID卡支持的虚拟磁盘设备上进行的测试,它允许进行许多并发I/O(其sd_max_throttle为256;请参阅第9.8.1节,“操作系统可调参数”)。物理磁盘设备具有较低的并发设置,并且会更早地将I/O排队到驱动程序中,从而增加等待列而不是活动列。
9.8 Tuning
在第9.5节“方法论”中涵盖了许多调优方法,包括缓存调优、扩展和工作负载特征化,这些方法可以帮助您识别和消除不必要的工作。调优的另一个重要领域是存储配置,它可以作为静态性能调优方法论的一部分进行研究。接下来的章节展示了可以调优的不同领域:操作系统、磁盘设备和磁盘控制器。可用的可调参数因操作系统的版本、磁盘型号、磁盘控制器及其固件而异;请参阅它们各自的文档。尽管更改可调参数可能很容易,但默认设置通常是合理的,很少需要进行大量调整。
9.8.1 Operating System Tunables
这些包括ionice(1)、资源控制和内核可调参数。
ionice
在Linux上,ionice(1)命令可用于为进程设置I/O调度类别和优先级。调度类别以数字形式标识:
- 0,none:未指定类别,因此内核将选择默认的——尽力而为,其优先级基于进程nice值。
- 1,real-time:对磁盘的最高优先级访问。如果被滥用,这可能会使其他进程饥饿(就像RT CPU调度类别一样)。
- 2,best effort:默认的调度类别,支持优先级0-7,0为最高。
- 3,idle:只有在磁盘闲置一段时间后才允许进行磁盘I/O操作。
以下是示例用法:
![]()
将进程ID 1623置于idle I/O调度类别中。对于长时间运行的备份作业,这可能是理想的,以减少它们干扰生产工作负载的可能性。
资源控制
现代操作系统提供了资源控制,以自定义方式管理磁盘或文件系统的I/O使用情况。
对于Linux,容器组(cgroups)块I/O(blkio)子系统为进程或进程组提供了存储设备资源控制。这可以是比例权重(如份额)或固定限制。可以独立设置读取和写入的限制,以及IOPS或吞吐量(每秒字节)的限制。
一些基于Solaris的系统具有ZFS I/O限制,它在文件系统级别(而不是磁盘级别)进行I/O限制,并且可以针对每个区域进行设置。这在第11章“云计算”中有描述。
可调参数
操作系统可调参数示例包括
- /sys/block/sda/queue/scheduler(Linux):选择I/O调度程序策略:noop、deadline、an(anticipatory)、cfq。请参阅第9.4节“架构”中对这些的早期描述。
- sd_max_throttle(Solaris):这调节可以发送到sd存储设备的最大命令数。对于由多个磁盘支持的存储阵列支持的虚拟设备,增加此值可能是有意义的。
可以通过对活动命令数量进行分析来获取调整sd_max_throttle的信息,以了解其是否接近限制。例如(来自生产云环境):
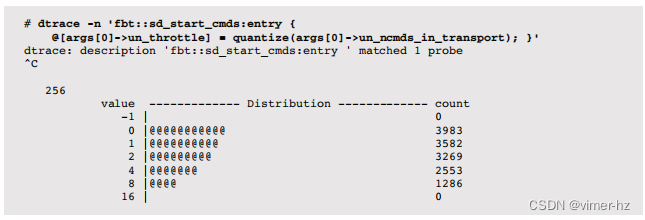
这显示了当前sd_max_throttle的活动值为256,而I/O的最高速率仅在8-15范围内。如果在存储设备上排队更合理,那么这个值就不需要调整。
与其他内核可调参数一样,请查看供应商文档以获取完整列表、描述和警告。公司或供应商政策也可能禁止设置这些参数。
9.8.2 Disk Device Tunables
在Linux上,hdparm(8)工具可以设置各种磁盘设备的可调参数。在Solaris上,可以使用format(1M)命令。
9.8.3 Disk Controller Tunables
可用的磁盘控制器可调参数取决于磁盘控制器型号和供应商。以下是使用MegaCli命令查看的Dell PERC 6卡的一些设置,以此来给您一个概念:

每个设置都有一个相当描述性的名称,并在供应商文档中有更详细的描述。


















 1412
1412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









