






随着系统变得更加分布式,特别是在云计算环境中,网络在性能中扮演着更重要的角色。除了改善网络延迟和吞吐量外,另一个常见任务是消除由丢包引起的延迟异常。
网络分析涵盖硬件和软件。硬件是物理网络,包括网络接口卡、交换机、路由器和网关(这些通常也包含软件)。系统软件是内核协议栈,通常是TCP/IP,以及所涉及的每个协议的行为。
网络经常因潜在的拥塞而被指责性能不佳。本章将展示如何弄清楚实际发生了什么,这可能会证明网络无辜,从而使分析得以继续进行。
本章分为五个部分,前三部分提供网络分析的基础知识,后两部分展示其在基于Linux和Solaris的系统中的实际应用。这些部分包括:
背景介绍与网络相关的术语、基本模型和关键的网络性能概念。
架构提供物理网络组件和网络协议栈的通用描述。
方法论描述了性能分析的方法论,包括观察性和实验性方法。
分析展示了用于在基于Linux和Solaris的系统上进行分析和实验的网络性能工具。
调整描述了示例可调参数。
10.1 Terminology
供参考,本章中使用的与网络相关的术语包括以下内容:
接口:术语接口端口指的是物理网络连接器。术语接口或链接指的是操作系统所见和配置的网络接口端口的逻辑实例。
数据包:术语数据包通常指的是IP级可路由消息。
帧:物理网络级消息,例如以太网帧。
带宽:网络类型的最大数据传输速率,通常以每秒位数(bits per second)为单位。例如,“10 GbE”是带有10 Gbits/s带宽的以太网。
吞吐量:网络端点之间当前的数据传输速率,以每秒位数或每秒字节数为单位。
延迟:网络延迟可以指消息在端点之间往返的时间,也可以指建立连接所需的时间(例如TCP握手),不包括随后的数据传输时间。
本章还介绍了其他术语。术语表包括基本术语供参考,包括客户端、以太网、主机、RFC、服务器、SYN、ACK等。
还请参阅第2章和第3章的术语部分。
10.2 Models
以下简单模型阐明了一些基本的网络和网络性能原理。第10.4节《架构》将深入探讨,包括实现特定的细节。
10.2.1 Network Interface
网络接口是操作系统中用于网络连接的端点;它是由系统管理员配置和管理的抽象概念。
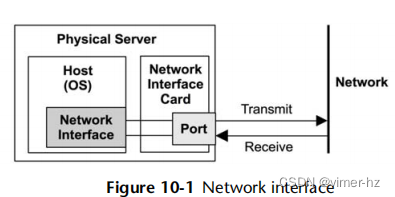
网络接口如图10.1所示。网络接口在其配置中被映射到物理网络端口。端口连接到网络,通常具有单独的发送和接收通道。
10.2.2 Controller
网络接口卡(NIC)为系统提供一个或多个网络端口,并容纳一个网络控制器:用于在端口和系统I/O传输之间传输数据包的微处理器。图10.2显示了一个带有四个端口的示例控制器,展示了所涉及的物理组件。
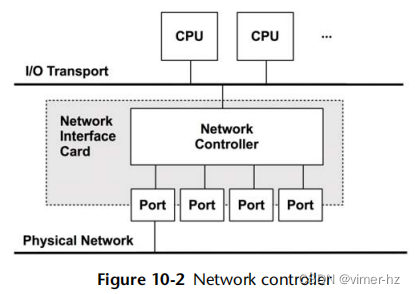
控制器可以作为一个独立的卡片提供,也可以集成在系统主板上。
10.2.3 Protocol Stack
网络连接是通过一堆协议完成的,每一层都有特定的目的。图10.3展示了两种堆栈模型,并附带示例协议。
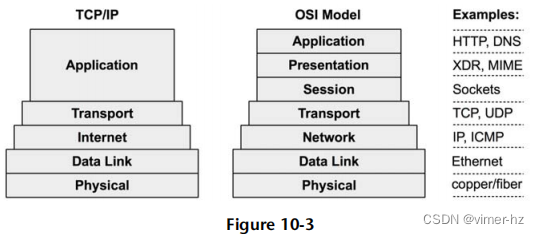
较低的层被绘制得更宽,以表示协议的封装。发送的消息从应用程序向物理网络下传。接收的消息向上传递。
请注意,以太网标准也描述了物理层,以及如何使用铜线或光纤。
尽管TCP/IP堆栈已成为标准,但考虑到OSI模型也是有用的。例如,OSI会话层通常以BSD套接字的形式存在于TCP/IP堆栈中。 "层"这个术语来自OSI,其中第3层指的是网络协议。
10.3 Concepts
以下是网络和网络性能中的一些重要概念:
10.3.1 Networks and Routing
网络是由通过网络协议地址相关联的连接主机组成的集合。拥有多个网络而不是一个巨大的全球网络有许多优点,尤其是可扩展性。一些网络消息将广播到所有相邻的主机。通过创建较小的子网络,这些广播消息可以在本地进行隔离,以免在规模化时造成洪泛问题。这也是将常规消息的传输仅限于源和目的地之间的网络的基础,从而更有效地利用网络基础设施。
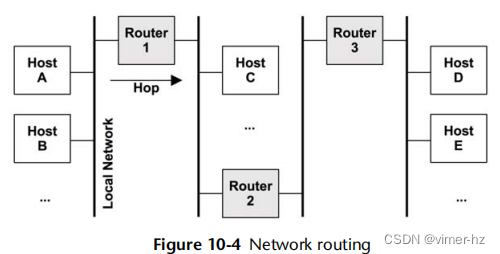
路由管理跨这些网络传递消息(称为数据包)。路由的作用如图10.4所示。从主机A的角度来看,本地主机就是主机A本身。所描绘的其他主机都是远程主机。主机A可以通过本地网络连接到主机B,通常由网络交换机驱动(参见第10.4节,架构)。主机A可以通过路由器1连接到主机C,通过路由器1、2和3连接到主机D。由于网络组件(如路由器)是共享的,来自其他流量(例如,主机C到主机E)的争用可能会影响性能。主机对之间的连接涉及单播传输。多播传输允许发送方同时向多个目的地发送,这些目的地可能跨越多个网络。路由器配置必须支持此功能以允许传送。
用于路由数据包的地址信息包含在IP头部中。
10.3.2 Protocols
网络协议标准,如IP、TCP和UDP等,是系统和设备之间进行通信的必要条件。通信是通过传输称为数据包的消息来完成的,通常是通过封装有效载荷数据来进行的。
网络协议具有不同的性能特征,这些特征源自原始协议设计、扩展或软件或硬件的特殊处理。例如,IP协议的不同版本IPv4和IPv6可能通过不同的内核代码路径进行处理,并且可能表现出不同的性能特征。
通常,还有一些系统可调参数可以影响协议的性能,例如通过更改缓冲区大小、算法和各种计时器等设置。这些特定协议的差异将在后面的部分中描述。
数据包的大小及其有效载荷也会影响性能,较大的尺寸可以提高吞吐量并减少数据包开销。对于TCP/IP和以太网,数据包的大小通常在54到9,054字节之间,包括封装数据的协议头部的54字节(或更多,取决于选项或版本)。
10.3.3 Encapsulation
封装在有效载荷的开头(标题)、结尾(页脚)或两者都添加了元数据。这不会改变有效载荷数据,尽管会稍微增加消息的总大小,这会为传输增加一些开销。图10.5展示了一个TCP/IP堆栈与以太网的封装示例。
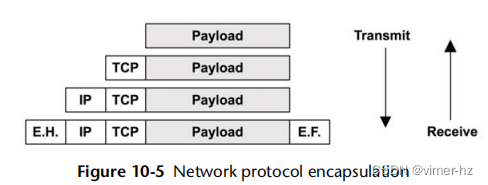
E.H.是以太网头,E.F.是可选的以太网页脚。
10.3.4 Packet Size
数据包大小通常受网络接口的最大传输单元(MTU)大小限制,对于许多以太网网络来说,MTU大小通常配置为1,500字节。以太网支持更大的数据包(帧),最大可达约9,000字节,称为超大帧。这些超大帧可以提高网络吞吐量性能,以及数据传输的延迟,因为它们需要更少的数据包。
两个因素的交汇干扰了超大帧的采用:老旧的网络硬件和配置错误的防火墙。不支持超大帧的老旧硬件可以使用IP协议对数据包进行分段,或者响应ICMP的“无法分段”错误,通知发送方减小数据包大小。现在配置错误的防火墙开始起作用:过去曾发生过基于ICMP的攻击(包括“死亡之ping”),一些防火墙管理员对此做出了回应,即阻止所有ICMP。这样就阻止了有用的“无法分段”消息传递给发送方,并在数据包大小超过1,500后导致网络数据包被静默丢弃。
为了避免这个问题,许多系统坚持使用1,500的MTU默认值。1,500的MTU帧的性能已经通过网络接口卡功能得到了改进,包括TCP卸载和大分段卸载。这些功能向网络卡发送更大的缓冲区,然后网络卡可以使用专用和优化的硬件将它们分割成较小的帧。这在某种程度上缩小了1,500和9,000的MTU网络性能之间的差距。
10.3.5 Latency
延迟是网络性能的重要指标,可以通过不同的方式进行测量,包括名称解析延迟、ping延迟、连接延迟、首字节延迟、往返时间和连接寿命。这些都是由客户端连接到服务器时进行的测量。
名称解析延迟
当建立到远程主机的连接时,主机名通常被解析为IP地址,例如通过DNS解析。这需要的时间可以单独测量为名称解析延迟。在最坏情况下,这种延迟涉及到名称解析超时,可能需要几十秒钟的时间。
有时,名称解析对应用程序的运行并非必需,可以禁用以避免这种延迟。
Ping延迟
这是一个ICMP回显请求到回显响应的时间,由ping(1)命令测量。此时间用于测量主机之间的网络延迟,包括中间的跳数,并且被测量为一个数据包往返所需的时间。它被广泛使用,因为它简单易行,而且通常容易获得:许多操作系统默认会对ping作出响应。
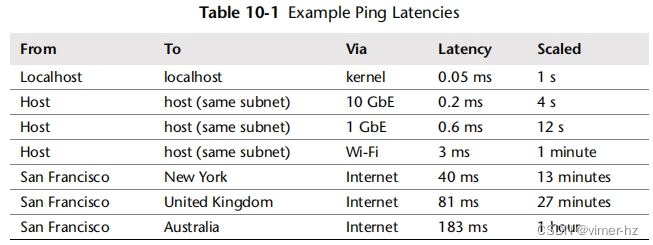
表10.1显示了示例ping延迟。为了更好地说明涉及的数量级,缩放列显示了基于想象中本地主机ping延迟为一秒的比较。
在接收端,ICMP回显请求通常在中断上下文中处理并立即返回,最大程度地减少了执行内核代码的额外时间。在发送端,由于时间戳是从用户态测量的,可能会包含一点额外的时间,使得内核上下文切换和内核代码路径时间也被计入其中。
连接延迟
连接延迟是建立网络连接所需的时间,在任何数据传输之前。对于TCP连接延迟来说,这是TCP握手时间。从客户端测量,它是从发送SYN到接收相应的SYN-ACK的时间。连接延迟更好地称为连接建立延迟,以清晰地区分它与连接寿命。
连接延迟类似于ping延迟,尽管它会调用更多内核代码来建立连接,并包括重新传输任何丢失的数据包的时间。特别是TCP的SYN数据包,如果服务器的等待队列已满,可能会被服务器丢弃,导致客户端重新传输SYN。这发生在TCP握手期间,因此连接延迟包括重新传输延迟,增加了一秒或更多的时间。
连接延迟之后是首字节延迟。
首字节延迟
也称为首字节时间(TTFB),首字节延迟是从建立连接到接收第一个字节的时间。这包括远程主机接受连接的时间,安排服务线程的时间以及该线程执行并发送第一个字节的时间。
虽然ping和连接延迟测量网络产生的延迟,但首字节延迟包括目标服务器的思考时间。这可能包括服务器超负荷时需要处理请求的时间(例如TCP等待队列),以及安排服务器的时间(CPU运行队列延迟)。
往返时间
往返时间描述了网络数据包在端点之间进行往返的时间。
连接寿命
连接寿命是从建立网络连接到关闭连接的时间。一些协议使用保持活动策略,延长连接的持续时间,以便将来的操作可以使用现有连接,避免连接建立的开销和延迟。
10.3.6 Buffering
尽管可能会遇到各种网络延迟,但通过在发送端和接收端使用缓冲区,网络吞吐量可以保持在较高的速率。较大的缓冲区可以通过在阻塞并等待确认之前继续发送数据来缓解较高的往返时间的影响。
TCP采用了缓冲区,以及滑动发送窗口,以提高吞吐量。网络套接字也有缓冲区,并且应用程序可能会额外使用它们来在发送之前聚合数据。
缓冲也可以由外部网络组件执行,例如交换机和路由器,以提高其自身的吞吐量。不幸的是,这些组件上的大型缓冲区的使用可能会导致一个称为缓冲膨胀的问题,其中数据包被排队等待了很长时间。这会导致主机上的TCP拥塞避免,从而限制性能。Linux 3.x内核已添加了用于解决此问题的功能(包括字节队列限制、CoDel队列管理[Nichols 12]和TCP小队列),并且有一个讨论此问题的网站[1]。
缓冲(或大型缓冲)的功能可能最好由端点(主机)而不是中间网络节点提供,遵循一种称为端到端论证的原则[Saltzer 84]。
10.3.7 Connection Backlog
另一种类型的缓冲是用于初始连接请求。TCP实现了一个后备队列,在用户空间进程接受之前,SYN请求可以在内核中排队等待。当有太多的TCP连接请求无法及时被进程接受时,后备队列达到上限,SYN数据包被丢弃,稍后由客户端重新发送。这些数据包的重新传输会导致客户端连接时间延迟。衡量后备队列丢弃是衡量网络连接饱和度的一种方法。
10.3.8 Interface Negotiation
网络接口可以以不同的模式运行,并与另一端点进行自动协商。一些例子包括:
带宽:例如,10、100、1,000、10,000 Mbits/s
双工:半双工或全双工
这些例子来自以十进制为基础的以太网,其倾向于使用圆整的基数限制带宽。其他物理层协议,如SONET,具有不同的可能带宽集合。
网络接口通常根据其最高带宽和协议来描述,例如,1 Gbit/s以太网(1 GbE)。然而,如果需要,该接口可以自动协商到较低的速度。如果另一个端点无法以更快的速度运行,或者为了适应连接介质的物理问题(如糟糕的布线),这种情况可能会发生。
全双工模式允许双向同时传输,具有分别用于发送和接收的独立路径,可以以全带宽运行。半双工模式一次只允许一个方向的传输。
10.3.9 Utilization
网络接口利用率可以计算为当前吞吐量除以最大带宽。由于自动协商导致带宽和双工模式可变,计算这一指标并不像听起来那么简单。
对于全双工模式,利用率适用于每个方向,并且被测量为该方向的当前吞吐量除以当前协商的带宽。通常情况下,只有一个方向的利用率最重要,因为主机通常是非对称的:服务器的传输负载较重,而客户端的接收负载较重。
一旦网络接口的某个方向达到100%的利用率,它就会成为瓶颈,限制性能。
一些操作系统性能工具仅以数据包为单位报告活动,而不是字节。由于数据包的大小可能差异很大(如前面提到的),因此不可能将数据包计数与字节计数相关联,用于计算吞吐量或(基于吞吐量的)利用率。
10.3.10 Local Connections
网络连接可以在同一系统上的两个应用程序之间发生。这些是本地主机连接,并使用虚拟网络接口:环回接口。
分布式应用程序环境通常被划分为逻辑部分,它们通过网络进行通信。这些部分可以包括Web服务器、数据库服务器和应用服务器。如果它们在同一主机上运行,则它们的连接是到本地主机的。
通过IP连接到本地主机是进程间通信(IPC)的IP套接字技术。另一种技术是Unix域套接字(UDS),它在文件系统上创建一个文件进行通信。使用UDS可能会提高性能,因为可以绕过内核TCP/IP栈,跳过内核代码和协议数据包封装的开销。
对于TCP/IP套接字,内核可能会在握手之后检测到本地主机连接,然后快捷方式使用TCP/IP栈进行数据传输,从而提高性能。这种方法在基于Solaris的系统中被称为TCP融合。
10.4 Architecture
本节介绍了网络架构:协议、硬件和软件。这些被总结为性能分析和调优的背景,重点放在性能特征上。更多详细信息,包括一般网络主题,请参阅网络文本([Stevens 93],[Hassan 03]),RFC以及网络硬件的供应商手册。一些这些资源在本章末尾列出。
10.4.1 Protocols
本节总结了TCP和UDP的性能特征。
TCP
传输控制协议(TCP)是创建可靠网络连接的常用互联网标准。TCP由[RFC 793]和后续补充规定。在性能方面,TCP可以在高延迟网络上通过使用缓冲和滑动窗口提供高吞吐量。TCP还采用拥塞控制和由发送方设置的拥塞窗口,以便在不同和变化的网络中保持高但适当的传输速率。拥塞控制避免发送过多的数据,这会导致拥塞和性能下降。
以下是TCP性能特性的摘要,包括自原始规范以来的补充:
- 滑动窗口:这允许在收到确认之前在网络上发送多个大小不超过窗口大小的数据包,即使在高延迟网络上也能提供高吞吐量。接收方通告窗口大小以指示其在该时间段内愿意接收多少个数据包。
- 拥塞避免:为了防止发送过多的数据并导致饱和,从而引发数据包丢失和更差的性能。
- 慢启动:作为TCP拥塞控制的一部分,它从一个小的拥塞窗口开始,然后随着在一定时间内收到的确认(ACK)增加而增加。当没有收到时,拥塞窗口会减小。
- 选择性确认(SACKs):允许TCP确认不连续的数据包,减少需要重新传输的数量。
- 快速重传:TCP可以根据接收到的重复ACK的到达而重新传输丢失的数据包,而不是等待定时器。这些是往返时间的函数,而不是通常更慢的定时器。
- 快速恢复:在检测到重复ACK后,通过将连接重置为执行慢启动来恢复TCP性能。在某些情况下,这些功能通过添加到协议头的扩展TCP选项来实现。
TCP性能的重要主题包括三次握手、重复ACK检测、拥塞控制算法、Nagle算法、延迟确认、SACK和FACK。
三次握手
主机之间使用三次握手建立连接。一个主机被动监听连接;另一个主动发起连接。要澄清的术语:被动和主动来自[RFC 793];然而,在套接字API之后,它们通常分别称为监听和连接。对于客户端/服务器模型,服务器执行监听,客户端执行连接。三次握手如图10.6所示。
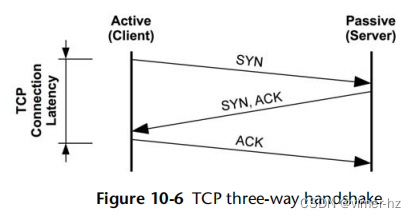
客户端的连接延迟被指示,当最后一个ACK被发送时完成。之后,数据传输可以开始。这个图示了握手的最佳情况延迟。一个数据包可能会被丢弃,增加延迟,因为它超时并被重新发送。
重复ACK检测
重复ACK检测由快速重传和快速恢复算法使用。它在发送方执行,工作如下:
1. 发送方发送一个序列号为10的数据包。
2. 接收方回复一个序列号为11的ACK。
3. 发送方发送11、12和13。
4. 数据包11被丢弃。
5. 接收方通过发送对11的ACK来回复12和13,因为它仍然期望11。
6. 发送方接收到重复的11 ACK。
重复ACK检测也被TCP Reno和Tahoe拥塞避免算法使用。
拥塞控制:Reno和Tahoe
这些用于拥塞控制的算法首次在4.3BSD中实现:
- Reno:三次重复的ACK触发:拥塞窗口减半,慢启动阈值减半,快速重传和快速恢复。
- Tahoe:三次重复的ACK触发:快速重传,慢启动阈值减半,拥塞窗口设置为一个最大段大小(MSS),慢启动状态。
一些操作系统(例如Linux和Oracle Solaris 11)允许选择算法作为系统调整的一部分。为TCP开发的较新算法包括Vegas、New Reno和Hybla。
Nagle
这个算法[RFC 896]通过延迟传输小数据包来减少网络上的小数据包数量,以允许更多的数据到达和合并。只有在管道中存在数据并且已经遇到延迟时,才会延迟数据包。系统可能会提供一个可调参数来禁用Nagle,如果它的操作与延迟的ACK冲突,则可能需要禁用Nagle。
延迟确认(Delayed ACKs)
这个算法[RFC 1122]延迟发送确认ACK,最多延迟500毫秒,以便将多个ACK组合在一起。其他TCP控制消息也可以组合,从而减少网络上的数据包数量。
SACK和FACK
TCP选择性确认(SACK)算法允许接收方通知发送方它接收到了非连续的数据块。如果没有这个功能,数据包丢失最终会导致整个发送窗口被重新传输,以保持顺序确认的方案。这会损害TCP性能,大多数支持SACK的现代操作系统都会避免这种情况。
SACK已经被前向确认(FACK)扩展,Linux默认支持。FACK跟踪额外的状态,并更好地调节网络中未完成数据的数量,从而提高了整体性能[数学家96]。
UDP
用户数据报协议(UDP)是一个常用的Internet标准,用于在网络上发送消息,称为数据报[RFC 768]。在性能方面,UDP提供了:
简单性:简单且小的协议头减少了计算和大小的开销。
无状态性:连接和传输的开销更低。
无重传:这会给TCP连接增加显著的延迟。
虽然简单且通常性能良好,但UDP并不打算提供可靠性,数据可能会丢失或乱序。这使其不适用于许多类型的连接。UDP也没有拥塞避免机制,因此可能会导致网络拥塞。
一些服务,包括NFS的某些版本,可以根据需要配置为通过TCP或UDP进行操作。执行广播或组播数据的其他服务可能只能使用UDP。
10.4.2 Hardware
网络硬件包括接口、控制器、交换机和路由器。了解它们的操作是有用的,即使这些组件中的任何一个都由其他人员(网络管理员)管理。
接口
物理网络接口在连接的网络上发送和接收消息,称为帧。它们管理所涉及的电气、光学或无线信号传输,包括处理传输错误。
接口类型基于第二层标准,每种提供最大带宽。更高带宽的接口通常提供更低的延迟,尽管成本也更高。这在设计新服务器时通常是一个关键选择,以平衡服务器价格和期望的网络性能。
对于以太网,选择包括有线或光学,以及最大速度为1 Gbit/s(1 GbE)、10 GbE、40 GbE或100 GbE。许多供应商制造以太网接口控制器,尽管您的操作系统可能不支持其中一些的驱动程序。
接口利用率可以通过当前协商的带宽除以当前吞吐量来检查。大多数接口都有单独的传输和接收通道,在全双工模式下运行时,必须分别研究每个通道的利用率。
控制器
物理网络接口通过控制器提供给系统,控制器可以是集成在系统主板上的,也可以通过扩展卡提供。
控制器由微处理器驱动,并通过I/O传输(例如PCI)连接到系统。其中任何一个都可能成为网络吞吐量或IOPS的限制因素。
例如,双端口10 GbE网络接口卡连接到一个四通道PCI Express(PCIe)Gen 2插槽。该卡的最大带宽为2 x 10 GbE = 20 Gbits/s。插槽的最大带宽为4 x 4 Gbits/s = 16 Gbits/s。因此,在两个端口上的网络吞吐量都将受到PCIe Gen 2带宽的限制,而且不可能同时以线速率驱动它们(我也从实践中了解到这一点!)。
交换机和路由器
交换机提供了任意两个连接主机之间的专用通信路径,允许多个主机对之间进行传输而不会发生干扰。这项技术取代了集线器(以及之前的共享物理总线:例如,厚型以太网同轴电缆),后者将所有数据包与所有主机共享。这种共享导致了当主机同时传输时的竞争,这可能被接口识别为使用“带冲突检测的载波侦听多路访问”(CSMA/CD)算法的冲突,并指数级地进行退避和重传,直到成功。这种行为在负载下会导致性能问题。通过使用交换机,这些问题已经过去了,但是观察工具仍然具有冲突计数器,即使这些通常只是由于错误(协商或错误布线)而发生。
路由器在网络之间传递数据包,并使用网络协议和路由表确定有效的传递路径。在两个城市之间传递数据包可能涉及十几个或更多的路由器,以及其他网络硬件。路由器和路由通常配置为动态更新,以便网络可以自动响应网络和路由器的故障,并平衡负载。这意味着在特定时间点,没有人能确定数据包实际经过的路径。由于存在多条可能的路径,还存在数据包可能被乱序传递的可能性,这可能导致TCP性能问题。网络上的这种神秘元素经常被归咎于性能不佳:也许来自其他不相关主机的大量网络流量正在使源和目的地之间的路由器饱和?因此,网络管理团队经常需要免除其基础设施的责任。他们可以使用先进的实时监控工具来检查所有涉及的路由器和其他网络组件。
路由器和交换机都包含微处理器,它们本身在负载下可能成为性能瓶颈。作为一个极端的例子,我曾经发现一个早期的10 GbE交换机总共无法驱动超过11 Gbit/s的带宽,这是由于其有限的CPU容量。
其他设备
您的环境可能包括其他物理网络设备,例如集线器、桥接器、中继器和调制解调器。其中任何一个都可能是性能瓶颈和丢包的来源。
10.4.3 Software
网络软件包括网络堆栈、TCP和设备驱动程序。本节讨论与性能相关的主题。
网络堆栈
所涉及的组件和层取决于操作系统类型、版本、使用的协议和接口。图10.7描述了一个通用模型,显示了软件组件。

在现代内核上,堆栈是多线程的,入站数据包可以由多个CPU处理。入站数据包映射到CPU的方式可能有不同的方式:可以基于源IP地址的哈希进行,以均匀分配负载;或者可以基于最近处理套接字的CPU来进行,以从CPU缓存热度和内存局部性中受益。Linux和基于Solaris的系统都有不同的框架来支持这种行为。
Linux
在Linux系统中,TCP、IP和通用网络驱动程序软件是核心内核组件,设备驱动程序是额外的模块。数据包以struct sk_buff数据类型通过这些内核组件传递。
图10.8更详细地展示了通用网络驱动程序,包括新API(NAPI)接口,通过合并中断来提高性能。
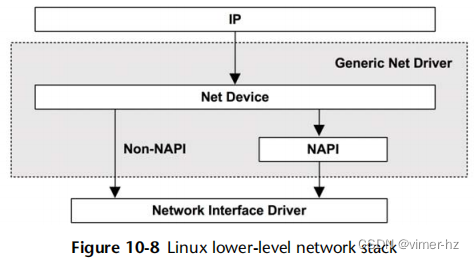
通过利用多个CPU来处理数据包和TCP/IP堆栈可以实现高数据包速率。有关此内容已经记录在Linux 3.7内核文档(Documentation/networking/scaling.txt)中,其中包括:
- RSS:接收端侧扩展(Receive Side Scaling):适用于支持多队列并且能够将数据包哈希到不同队列的现代网卡,这些数据包通过直接中断不同的CPU来处理。此哈希可能基于IP地址和TCP端口号,以便来自同一连接的数据包最终由同一CPU处理。
- RPS:接收数据包定向(Receive Packet Steering):RSS的软件实现,适用于不支持多队列的网卡。这涉及一个简短的中断服务例程,将入站数据包映射到CPU进行处理。可以使用类似的哈希将数据包映射到CPU,基于数据包头字段。
- RFS:接收流定向(Receive Flow Steering):类似于RPS,但具有对套接字上一次在CPU上处理的亲和性,以提高CPU缓存命中率和内存局部性。
- 加速接收流定向(Accelerated Receive Flow Steering):这在支持此功能的网卡上通过硬件实现RFS。它涉及向网卡更新流信息,以便确定要中断哪个CPU。
- XPS:传输数据包定向(Transmit Packet Steering):对于具有多个传输队列的网卡,此功能支持由多个CPU向队列传输。
如果没有针对网络数据包的CPU负载平衡策略,网卡可能只会中断一个CPU,这可能会达到100%的利用率并成为瓶颈。根据诸如缓存一致性之类的因素将中断映射到CPU,就像RFS所做的那样,可以显着提高网络性能。irqbalancer进程也可以完成这个任务,它将中断请求(IRQ)线路分配给CPU。
Solaris
在基于Solaris的系统中,套接字层是 sockfs 内核模块,而 TCP、UDP 和 IP 协议被合并到 ip 模块中。数据包通过内核作为消息块 mblk_t 传递。更详细地展示了底层堆栈,如图10.9所示 [McDougall 06a]。
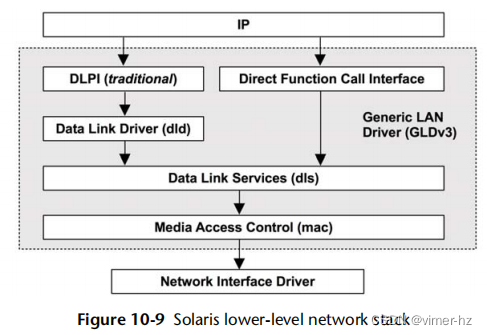
GLDv3 软件还通过垂直边界(vertical perimeters)提高了性能:这是与连接相关的每个 CPU 同步机制,避免了网络堆栈中每个数据结构的锁需求。这使用了一个称为序列化队列(squeue)的抽象,它处理每个连接。
通过启用 IP fanout 可以实现高数据包速率,该功能可以在多个 CPU 之间负载均衡入站数据包。
最近,Erik Nordmark 在 Solaris IP 数据通路重构项目中简化了网络堆栈的内部。关于之前堆栈状态的描述,包括性能[2],来自该项目:
IP 数据通路非常难以理解……这使得甚至修复代码中的错误都变得困难,更不用说使其性能达到最佳状态了。通过创建许多快速路径,即完整数据通路的子集,来改善性能。这进一步使代码维护成为一项危险的活动。
该项目已经集成到 snv_122,并将 IP 代码从 140,000 行减少了 34,000 行。
TCP
TCP 协议之前已经描述过。本节描述了内核 TCP 实现的性能特性:积压队列和缓冲区。
通过使用积压队列来处理连接的突发性增加。有两个这样的队列,一个用于在 TCP 握手完成之前的未完成连接(也称为 SYN 积压),另一个用于已建立会话等待被应用程序接受的已建立会话(也称为监听积压)。这些在图10.10中显示。
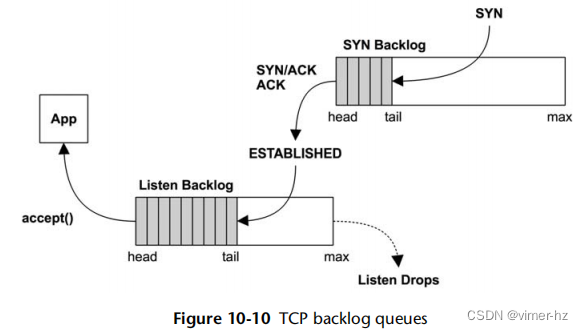
在早期的内核中只使用了一个队列,并且容易受到 SYN 洪水攻击的影响。SYN 洪水是一种 DoS 攻击类型,涉及向虚假 IP 地址发送大量的 SYN,以连接到监听 TCP 端口。这会在 TCP 等待完成握手时填满积压队列,阻止真实客户端连接。
有了两个队列,第一个可以作为潜在虚假连接的暂存区,只有在连接建立后才将其提升到第二个队列。第一个队列可以被设置得很长,以吸收 SYN 洪水,并优化为仅存储必要的最小元数据。
这些队列的长度可以独立调整(参见第10.8节,调整)。第二个队列也可以由应用程序设置为监听(listen())的积压参数。
通过使用与套接字关联的发送和接收缓冲区来提高数据吞吐量。这些在图10.11中显示。
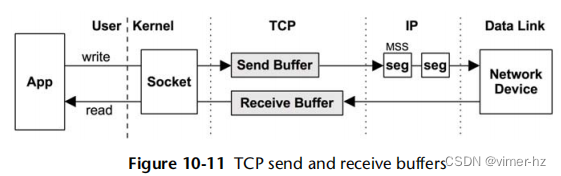
对于写路径,数据被缓存在TCP发送缓冲区中,然后发送到IP进行传送。虽然IP协议具有分片数据包的能力,但TCP通过将数据作为MSS大小的段发送到IP来尽量避免这种情况。这意味着(重新)传输的单位与分片的单位相匹配;否则,丢失的分片将需要重新传输整个预分片的数据包。这种方法还可以提高TCP/IP堆栈的效率,因为它避免了常规数据包的分片和重组。
发送和接收缓冲区的大小都是可调整的。较大的大小会提高吞吐量性能,但每个连接消耗的主存更多。如果预计服务器需要更多发送或接收,则可以将其中一个缓冲区设置为较大。Linux内核还会根据连接活动动态增加这些缓冲区的大小。
网络设备驱动
网络设备驱动程序通常具有额外的缓冲区——环形缓冲区——用于在内核内存和网卡之间发送和接收数据包。
随着10GbE网络的引入,一个越来越常见的性能特性是使用中断合并模式。不是为每个到达的数据包中断内核,而是仅在定时器(轮询)到达或达到一定数量的数据包时才发送中断。这降低了内核与网卡通信的速率,允许更大的传输被缓冲,从而提高了吞吐量,尽管在延迟方面会付出一些代价。在基于Solaris的内核中,这被称为动态轮询。
10.5 Methodology
本节介绍了网络分析和调优的各种方法和练习。表10.2总结了这些主题。
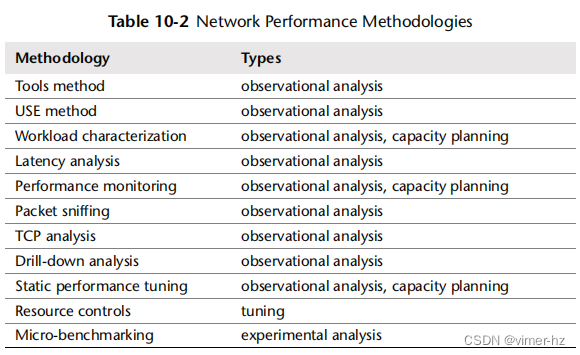
有关更多策略和其中许多内容的介绍,请参阅第2章“方法论”。
这些方法可以单独跟随,也可以组合使用。我建议首先按照以下顺序使用以下策略:性能监控,USE方法,静态性能调优和工作负载特征化。
第10.6节“分析”展示了应用这些方法的操作系统工具。
10.5.1 Tools Method
工具方法是一个迭代使用可用工具、检查它们提供的关键指标的过程。这种方法可能会忽视工具未能提供良好或没有可见性的问题,并且可能需要花费大量时间来执行。
对于网络,工具方法可能涉及以下检查:
netstat -s:查看重传率和乱序数据包的高速率。对于何为“高”重传率取决于客户端:面向互联网的系统与不可靠的远程客户端应该具有比同一数据中心内的内部系统更高的重传率。
netstat -i:检查接口错误计数器(特定计数器取决于操作系统版本)。
ifconfig(仅适用于Linux版本):检查“errors”,“dropped”,“overruns”。
吞吐量:检查字节传输和接收的速率——在Linux上,通过ip(8);在Solaris上,通过nicstat(1)或dladm(1M)。高吞吐量可能会达到协商速度的线速并受到限制。它还可能在系统上的网络用户之间造成争用和延迟。
tcpdump/snoop:虽然在CPU成本方面可能昂贵,但在短时间内使用它们可能足以查看谁在使用网络,并识别可以消除的不必要工作。
dtrace/stap/perf:用于在应用程序和线路之间选择性地检查数据包,包括检查内核状态。
如果发现问题,请从可用工具的所有字段中检查以了解更多上下文。有关每个工具的更多信息,请参见第10.6节“分析”。还可以使用其他方法,这些方法可以识别更多类型的问题。
10.5.2 USE Method
USE方法用于快速识别所有组件中的瓶颈和错误。对于每个网络接口,在每个方向(发送(TX)和接收(RX))检查以下内容:
利用率(Utilization):接口忙于发送或接收帧的时间。
饱和度(Saturation):由于完全利用的接口而产生的额外排队、缓冲或阻塞程度。
错误(Errors):对于接收端:坏校验和、帧太短(小于数据链路头)或太长、碰撞(在交换网络中不太可能);对于发送端:迟到的碰撞(坏的布线)。
错误可能首先进行检查,因为它们通常很快检查完毕并且易于解释。
利用率通常不会直接由操作系统或监控工具提供。可以将其计算为每个方向(RX、TX)的当前吞吐量除以当前协商速度。当前吞吐量应以字节每秒的形式在网络上传输,包括所有协议头。
对于实施网络带宽限制(资源控制)的环境,如某些云计算环境中所发生的,网络利用率可能需要根据所施加的限制来衡量,而不仅仅是物理限制。
网络接口的饱和度很难测量。一些网络缓冲是正常的,因为应用程序可以比接口更快地发送数据。可能可以将其测量为应用程序线程在网络发送上被阻塞的时间,随着饱和度增加,这个时间可能会增加。此外,还要检查是否有与接口饱和度更密切相关的其他内核统计信息,例如,Linux的“overruns”或Solaris的“nocanputs”。
在TCP级别上的重传通常作为统计数据很容易获得,并且可以作为网络饱和度的指标。但是,它们是在服务器与其客户端之间的网络上测量的,可能发生在任何跳跃点。
USE方法也可以应用于网络控制器及其与处理器之间的传输。由于这些组件的可观察性工具稀少,根据网络接口统计信息和拓扑推断指标可能更容易。例如,如果网络控制器A包含端口A0和A1,则可以将网络控制器吞吐量计算为接口吞吐量A0 + A1的总和。有了已知的最大吞吐量,然后可以计算网络控制器的利用率。
10.5.3 Workload Characterization
对应用的负载进行表征是容量规划、基准测试和模拟工作负载的重要练习。通过识别可以消除的不必要工作,它还可以带来一些最大的性能增益。以下是用于表征网络工作负载的基本属性,它们可以共同提供对网络被要求执行的近似描述:
- 网络接口吞吐量:接收(RX)和发送(TX),每秒字节数
- 网络接口IOPS(每秒输入/输出操作数):接收(RX)和发送(TX),每秒帧数
- TCP连接速率:活动和被动连接,每秒连接数
"活动"和"被动"这两个术语在“三次握手”章节中有描述。
这些特性随着时间的推移可能会发生变化,因为一天中的使用模式会发生变化。关于随时间的监控在"性能监控"章节中有描述。以下是一个示例工作负载描述,展示了如何将这些属性结合在一起表达:
网络吞吐量基于用户的不同而变化,执行更多的写入(TX)比读取(RX)。峰值写入速率为每秒200兆字节和每秒210,000个数据包,峰值读取速率为每秒10兆字节和每秒70,000个数据包。入站(被动)TCP连接速率达到每秒3,000个连接。
除了对系统范围内描述这些特性外,它们也可以针对每个接口进行表达。如果观察到吞吐量已达到线路速率,这允许确定接口瓶颈。如果存在网络带宽限制(资源控制),则可能在达到线路速率之前会限制网络吞吐量。
高级工作负载表征/检查清单还可以包含其他细节以表征工作负载。这些被列为考虑的问题,也可以在彻底研究CPU问题时作为检查清单:
- 平均数据包大小是多少?RX、TX?
- 协议分布是什么?TCP与UDP?
- 活动的TCP/UDP端口是哪些?每秒字节数、每秒连接数?
- 哪些进程正在积极使用网络?
随后的章节回答了其中一些问题。有关此方法论和要测量的特性的更高级别摘要,请参阅第2章“方法论”。
10.5.4 Latency Analysis
有各种不同的时间(延迟)可以研究,以帮助理解和表达网络性能。它们包括网络延迟——一个稍微模糊的术语,通常用来指代连接初始化时间。各种网络延迟总结如表10.3所示。
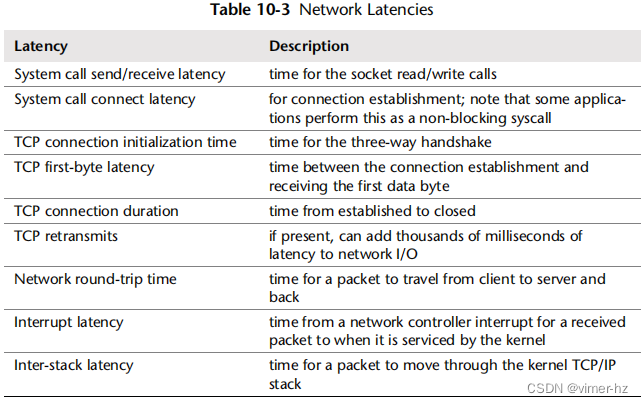
其中一些延迟在第10.3节“概念”中有详细描述。延迟可以呈现为:
- 每个时间间隔的平均值:最好针对每个客户端/服务器对执行,以隔离中间网络中的差异
- 完整分布:作为直方图或热力图
- 每个操作的延迟:列出每个事件的详细信息,包括源和目标IP地址
问题的常见来源是由TCP重传引起的延迟异常值。这些可以使用完整分布或每个操作的延迟跟踪来识别,包括通过过滤最小延迟阈值来进行。
10.5.5 Performance Monitoring
性能监控可以识别出时间上的活动问题和行为模式。它将捕获活跃终端用户数量的变化,计时活动,包括分布式系统监控,以及通过网络进行的应用活动,包括备份。
网络监控的关键指标包括:
- 吞吐量:每秒接收和发送的网络接口字节数,最好是针对每个接口
- 连接:每秒TCP连接数,作为网络负载的另一个指标
- 错误:包括丢包计数器
- TCP重传:也有助于记录以与网络问题进行相关性分析
- TCP乱序数据包:也可能导致性能问题
对于实施网络带宽限制(资源控制)的环境,例如某些云计算环境,还可以收集与施加的限制相关的统计信息。
10.5.6 Packet Sniffing
数据包嗅探(又称数据包捕获)涉及从网络中捕获数据包,以便可以逐个数据包地检查其协议头和数据。对于观察性分析而言,这可能是最后的手段,因为从CPU和存储开销方面来看,执行起来可能会很昂贵。网络内核代码路径通常经过循环优化,因为它们需要处理每秒高达数百万个数据包,并且对任何额外的开销都很敏感。为了尝试减少这种开销,内核可能会使用环形缓冲区通过共享内存映射将数据包数据传递给用户级别的跟踪工具,例如,Linux的PF_RING选项而不是每个数据包的PF_PACKET [Deri 04]。
可以在服务器上创建一个数据包捕获日志,然后使用其他工具进行分析。有些工具仅打印内容;其他工具对数据包数据执行更高级别的分析。虽然阅读数据包捕获日志可能会耗费时间,但也可能会非常有启发性——准确显示了网络上正在发生的事情,以及数据包之间的延迟。这使得可以应用工作负载特征化和延迟分析方法。
数据包捕获日志可以包含以下内容:
- 时间戳
- 整个数据包,包括
- 所有协议头(例如以太网、IP、TCP)
- 部分或完整的有效载荷数据
- 元数据:数据包数量、丢包数量
作为数据包捕获的示例,以下显示了tcpdump工具的默认输出。
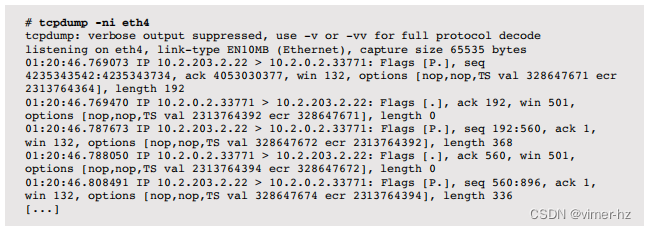
该输出包含一行总结每个数据包,包括IP地址、TCP端口和其他TCP头部详情的细节。
由于数据包捕获可能是一项消耗CPU资源的活动,大多数实现都包括在负载过重时放弃捕获事件而不是捕获它们的能力。丢弃数据包的计数可能会包含在日志中。
除了使用环形缓冲区外,数据包捕获实现通常允许用户提供过滤表达式,并在内核中执行此过滤。这通过不将不需要的数据包传输到用户级别来减少开销。
10.5.7 TCP Analysis
除了在第10.5.4节“延迟分析”中讨论的内容外,还可以调查其他特定的TCP行为,包括:
- TCP发送/接收缓冲区的使用情况
- TCP后台队列(backlog queues)的使用情况
- 由于后台队列已满而导致内核丢弃的数据包
- 拥塞窗口大小,包括零大小的广告(zero-size advertisements)
- 在TCP TIME-WAIT1间隔期间收到的SYN包
在同一目标端口上频繁连接到另一个服务器时,这些行为可能会成为可探究的问题,使用相同的源和目标IP地址。每个连接的唯一区分因素是客户端源端口(临时端口),对于TCP来说,这是一个16位值,并且可能会受到操作系统参数(最小和最大值)的进一步限制。
结合TCP TIME-WAIT间隔(可能为60秒),在60秒内高速连接的数量(超过65,536个)可能会遇到新连接的冲突。在这种情况下,当临时端口仍然与处于TIME-WAIT状态的先前TCP会话关联时发送了SYN包,如果新的SYN包被误识别为旧连接的一部分(发生冲突),则可能会被拒绝。为了避免这个问题,Linux内核会尝试快速重用或回收连接(通常效果良好)。
10.5.8 Drill-Down Analysis
可以根据需要调查内核网络堆栈的内部情况,通过逐层深入到处理数据包的网络接口驱动程序。内部结构复杂,这是一项耗时的活动。进行此活动的原因包括:
- 检查是否需要调整网络可调参数(而不是进行实验性修改)
- 确认内核网络性能特性是否生效,包括例如CPU分流和中断合并
- 解释内核丢弃的数据包
通常涉及使用动态跟踪来检查内核网络堆栈函数的执行情况。
10.5.9 Static Performance Tuning
静态性能调优侧重于已配置环境的问题。对于网络性能,要检查静态配置的以下方面:
- 可供使用的网络接口数量是多少?当前有多少在使用中?
- 网络接口的最大速度是多少?
- 网络接口的当前协商速度是多少?
- 网络接口是半双工还是全双工协商的?
- 网络接口配置了什么MTU?
- 网络接口是否进行了干线聚合(trunked)?
- 设备驱动程序、IP层和TCP层存在哪些可调参数?
- 是否有任何可调参数已从默认值更改?
- 路由是如何配置的?默认网关是什么?
- 数据路径中网络组件的最大吞吐量是多少(所有组件,包括交换机和路由器背板)?
- 转发是否已启用?系统是否作为路由器运行?
- DNS配置是如何的?服务器距离有多远?
- 网络接口固件的版本是否已知存在性能问题(bug)?
- 网络设备驱动程序或内核TCP/IP堆栈的版本是否已知存在性能问题(bug)?
- 是否存在软件实施的网络吞吐量限制(资源控制)?它们是什么?
这些问题的答案可能会揭示被忽视的配置选择。最后一个问题尤其适用于云计算环境,因为网络吞吐量可能受到限制。
10.5.10 Resource Controls
操作系统可能提供控制,以限制连接类型、进程或进程组的网络资源。这些控制可能包括以下类型:
- 网络带宽限制:由内核应用于不同协议或应用程序的允许带宽(最大吞吐量)。
- IP服务质量(QoS):网络流量的优先级排序,由网络组件(例如路由器)执行。这可以通过不同方式实现:IP头包含服务类型(ToS)位,包括一个优先级;这些位已经被重新定义,用于新的QoS方案,包括区分服务[RFC 2474]。其他协议层可能实现了其他优先级,以实现相同的目的。
你的网络可能有各种流量,可以分类为低优先级或高优先级。低优先级可能包括备份传输和性能监控流量。高优先级可能是生产服务器与客户端之间的流量。任何资源控制方案都可以用于限制低优先级流量,从而为高优先级流量提供更好的性能。
这些控制的工作方式因实现而异,将在第10.8节“调优”中讨论。
10.5.11 Micro-Benchmarking
有许多用于网络的基准测试工具。它们在调查分布式应用环境的吞吐量问题时特别有用,以确认网络至少可以达到预期的网络吞吐量。如果不能达到预期吞吐量,可以使用网络微基准测试工具来调查网络性能,这通常比应用程序更简单且更容易调试。
在网络调优到期望速度之后,可以重新关注应用程序。可能被测试的典型因素包括:
- 方向:发送或接收
- 协议:TCP或UDP,以及端口
- 线程数
- 缓冲区大小
- 接口MTU大小
更快的网络接口,例如10 Gbit/s,可能需要驱动多个客户端线程以达到最大带宽。一个示例网络微基准测试工具是iperf,在第10.7.1节“iperf”中介绍。
10.6 Analysis
本节介绍了基于Linux和Solaris操作系统的网络性能分析工具。请参阅前一节以了解在使用它们时要遵循的策略。本节中的工具列在表10.4中。
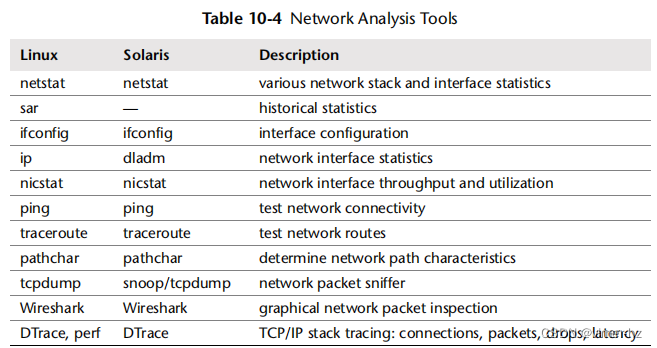
这是一些工具和功能的选择,用于支持第10.5节《方法论》,从系统范围的统计信息开始,然后深入到数据包嗅探和事件跟踪。查看工具文档,包括man手册,以获取其功能的完整参考资料。
10.6.1 netstat
这是一些工具和功能的选择,用于支持第10.5节《方法论》,从系统范围的统计信息开始,然后深入到数据包嗅探和事件跟踪。查看工具文档,包括man手册,以获取其功能的完整参考资料。
netstat(8)命令根据所使用的选项报告各种类型的网络统计信息。它类似于一个具有多种不同功能的多工具。这些功能包括以下内容:
- (默认):列出连接的套接字
- -a:列出所有套接字的信息
- -s:网络堆栈统计信息
- -i:网络接口统计信息
- -r:列出路由表
其他选项可以修改输出,包括-n以不将IP地址解析为主机名,以及-v用于提供详细信息的情况下的详细输出。
netstat(8)的输出在不同操作系统之间略有不同。
Linux
以下是netstat(8)接口统计信息的示例:
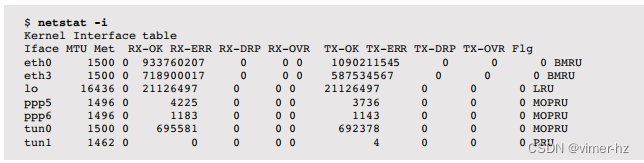
这些列包括网络接口(Iface)、MTU以及一系列接收(RX-)和发送(TX-)的指标:
- OK:成功传输的数据包
- ERR:数据包错误
- DRP:数据包丢失
- OVR:数据包溢出
数据包丢失和溢出是网络接口饱和的指示,可以与错误一起作为USE方法的一部分进行检查。
可以在-i选项中使用-c连续模式,它会每秒打印这些累积计数器。这提供了计算数据包速率的数据。
以下是netstat(8)网络堆栈统计信息的示例(已截断):

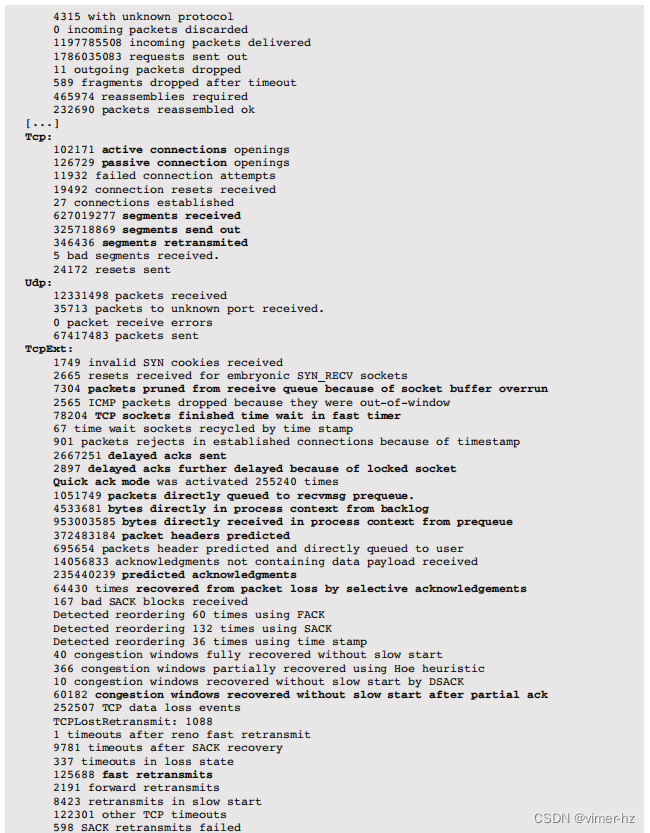
输出列出了各种网络统计信息,主要来自TCP,按其协议分组。幸运的是,其中许多具有长的描述性名称,因此它们的含义可能很明显。不幸的是,输出不一致,并包含拼写错误,这在以编程方式处理此文本时会带来麻烦。一些与性能相关的指标已用粗体突出显示,以显示可用的信息类型。其中许多需要对TCP行为有深入理解,包括近年来引入的新功能和算法。以下是一些要查找的示例指标:
- 转发数据包与接收到的总数据包的高比率:检查服务器是否应该转发(路由)数据包。
- 被动连接打开次数:这可以监视客户端连接方面的负载。
- 重传的段与发送出去的段的高比率:可能显示网络不可靠。这可能是预期的(Internet客户端)。
- 因套接字缓冲区溢出而从接收队列中剪切的数据包:这是网络饱和的迹象,可以通过增加套接字缓冲区来修复——前提是系统资源足够,可以维持应用程序的运行。
部分统计名称中包含有拼写错误。如果其他监控工具是基于相同的输出构建的,简单修复这些错误可能会带来问题。这样的工具最好通过阅读这些统计数据的/proc源文件来提供服务,这些源文件是/proc/net/snmp和/proc/net/netstat。例如:

这些/proc/net/snmp统计信息也用于SNMP管理信息库(MIB),为每个统计量提供了进一步的文档说明。扩展统计信息位于/proc/net/netstat中。
netstat(8)可以使用一个以秒为单位的间隔,以便每个间隔持续打印累积计数器。然后可以对此输出进行后处理,以计算每个计数器的速率。
Solaris
这里是netstat(1M)接口统计的一个示例:
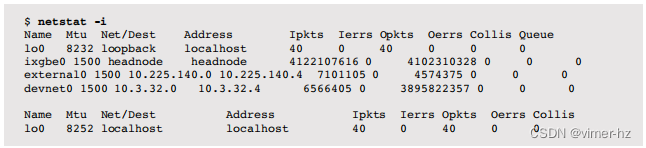
列包括网络接口(名称)、MTU、网络(Net/Dest)、接口地址(Address)以及一系列指标:
- Ipkts:输入数据包(接收)
- Ierrs:输入数据包错误
- Opkts:输出数据包(发送)
- Oerrs:输出数据包错误(例如,迟到的碰撞)
- Collis:数据包碰撞(现在不太可能发生,因为有缓冲交换机)
- Queue:始终为零(硬编码,历史遗留)
如果提供了一个间隔(以秒为单位)作为参数,则输出会随时间总结单个接口的情况。可以使用-I选项指定要显示的接口。
以下是netstat(1M)网络堆栈统计的一个示例(截断):
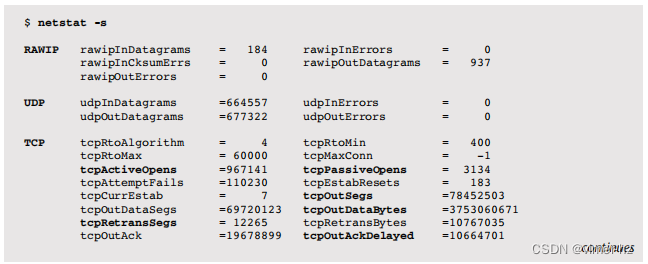
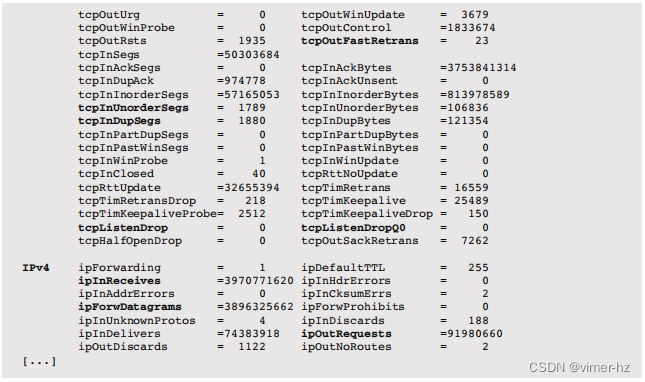
输出按协议分组列出了各种网络统计信息。许多这些统计信息的名称都基于SNMP网络MIB,这些MIB解释了它们的用途。一些与性能相关的指标已经以粗体突出显示,以展示可用的信息类型。其中许多需要对现代TCP行为有深入的理解。要查找的指标包括与之前提到的Linux指标类似的指标,以及:
- tcpListenDrop和tcpListenDropQ0:它们分别显示套接字监听队列和SYN队列中丢弃的数据包数量。tcpListenDrops的增加表示应用程序无法接受的连接请求越来越多。可以通过两种方式来解决这个问题:增加监听队列的长度(tcp_conn_req_max_q),允许更大的连接突发队列;和/或为应用程序配置更大的系统资源。
报告的指标是从kstat中读取的,可以使用libkstat接口访问。
还可以提供一个间隔,它打印自启动以来的摘要,然后是间隔摘要。每个摘要显示该间隔的统计信息(不像Linux版本那样),因此速率是明显的。例如:

这显示了每秒的TCP连接速率,包括活动连接和被动连接。
10.6.2 sar
系统活动报告工具sar(1)可用于观察当前活动,并可配置以存档和报告历史统计信息。它在第4章“可观察性工具”中介绍,并在其他章节中适当提及。Linux版本通过以下选项提供网络统计信息:
- -n DEV:网络接口统计信息
- -n EDEV:网络接口错误
- -n IP:IP数据报统计信息
- -n EIP:IP错误统计信息
- -n TCP:TCP统计信息
- -n ETCP:TCP错误统计信息
- -n SOCK:套接字使用情况
提供的统计信息包括表10.5中显示的内容。
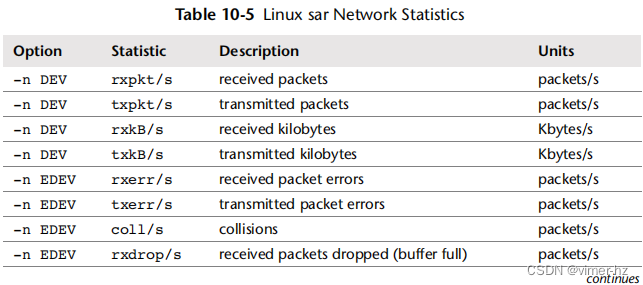
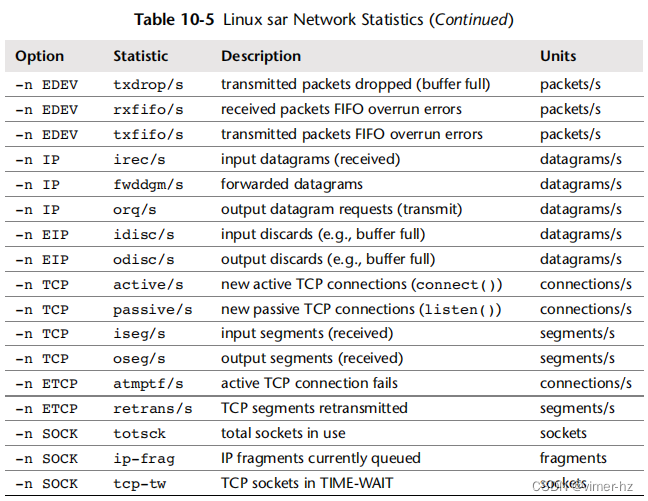
许多统计名称包括方向和所测量的单位:例如,rx表示“接收”,i表示“输入”,seg表示“段”等。请参阅man页面获取完整列表,其中包括ICMP、UDP、NFS和IPv6的统计信息,还注明了一些等效的SNMP名称(例如,ipInReceives对应irec/s)。以下示例每秒打印一次TCP统计信息:
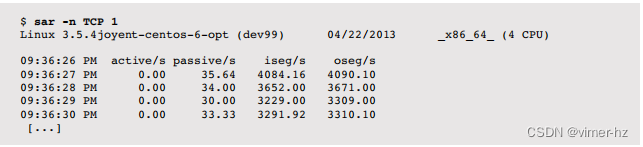
输出显示了每秒大约30个的被动连接率(入站)。网络接口统计列(NET)列出了所有接口;然而,通常只有一个是感兴趣的。以下示例使用了一点awk(1)来过滤输出:

这显示了传输和接收的网络吞吐量。在这种情况下,两个方向的速率都超过了2兆字节/秒。
Solaris版本的sar(1)目前不提供网络统计信息(可以使用netstat(1M)、nicstat(1)和dladm(1M))。
10.6.3 ifconfig
ifconfig(8)命令允许手动配置网络接口。它还可以列出所有接口的当前配置,这在静态性能调整期间很有用,可以检查系统、网络和路由的配置情况。Linux版本的输出包含统计信息。
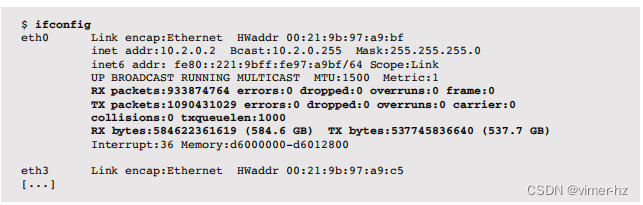
这些计数器与先前的netstat -i命令描述的相同。txqueuelen是接口传输队列的长度。调整此值的方法在man页面中有描述:
对于传输速度较慢且延迟较高的设备(例如调制解调器链接、ISDN),将此值设置为较小值是有用的,以防止快速大量传输过程对交互式流量(如telnet)造成过多干扰。
在Linux上,ifconfig(8)现在被认为已过时,被ip(8)命令取代。在Solaris上,ifconfig(1M)的各种功能也已经过时,被ipadm(1M)和dladm(1M)命令取代。
10.6.4 ip
Linux的ip(8)命令可用于配置网络接口和路由,以及观察它们的状态和统计信息。例如,显示链接统计信息:
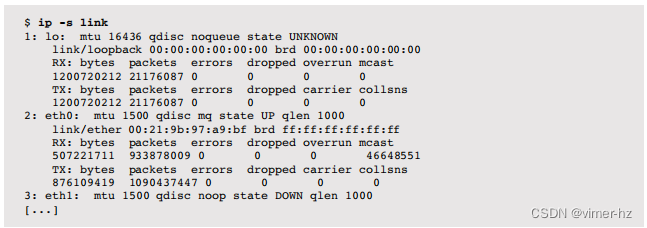
这些计数器与先前描述的netstat -i命令相同,额外增加了接收(RX)和发送(TX)字节。这将允许轻松观察吞吐量;然而,ip(8)目前没有提供打印每个间隔报告的方法(请使用sar(1))。
10.6.5 nicstat
最初为基于Solaris的系统编写的开源工具nicstat(1)可打印网络接口统计信息,包括吞吐量和利用率。nicstat(1)遵循传统资源统计工具iostat(1M)和mpstat(1M)的风格。已经编写了C和Perl版本,适用于基于Solaris的系统和Linux [3]。
例如,以下是在Linux上版本1.92的输出:
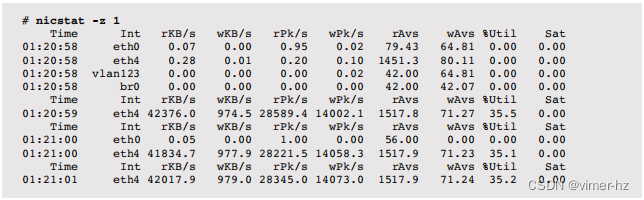
第一个输出是自启动以来的总结,接着是间隔摘要。间隔摘要显示eth4接口的利用率为35%(这报告了来自RX或TX方向的最高当前利用率),读取速度为42兆字节/秒。
字段包括接口名称(Int)、最大利用率(%Util)、反映接口饱和统计的值(Sat),以及一系列以r表示“读取”(接收)和w表示“写入”(发送)为前缀的统计信息:
- KB/s:每秒字节数
- Pk/s:每秒数据包数
- Avs/s:平均数据包大小,字节
此版本支持各种选项,包括使用-z跳过零行(空闲接口)和-t用于TCP统计。
nicstat(1)对于使用USE方法特别有用,因为它提供了利用率和饱和度值。
10.6.6 dladm
在基于Solaris的系统上,dladm(1M)命令可以提供接口统计信息,包括数据包和字节速率、错误率和利用率,并且还可以显示物理接口的状态。
每秒显示ixgbe0接口上的网络流量:
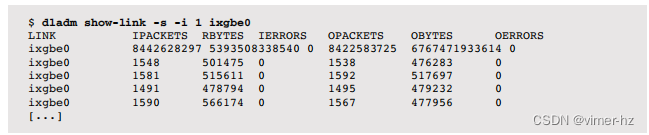
输出的第一行是自启动以来的总和,接着是每秒摘要(-i 1)。输出显示该接口目前的接收和发送速率约为500千字节/秒。dladm show-link -S提供了另一种输出,显示了千字节速率、数据包速率和%Util列。
列出物理接口的状态:
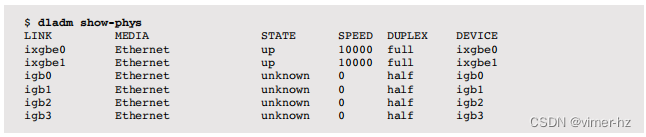
这对于静态性能调优非常有用,可以检查接口是否已协商到最快速度。
在dladm(1M)之前,这些属性是使用ndd(1M)来检查的。
10.6.7 ping
ping(8)命令通过发送ICMP回显请求数据包来测试网络连接。例如:
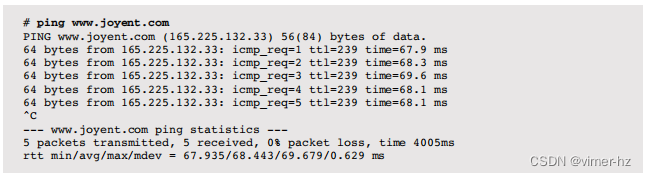
输出包括每个数据包的往返时间(rtt),并显示各种统计摘要。由于时间戳是由ping(8)命令本身测量的,它们包含了在获取时间戳和执行网络I/O之间的一些CPU代码路径执行时间。
Solaris版本需要使用-s选项以这种方式发送连续的数据包。路由器可能会将使用的ICMP数据包视为比应用程序协议更低优先级的数据包,并且延迟可能显示比通常更高的变化。
10.6.8 traceroute
traceroute(8)命令发送一系列测试数据包,实验性地确定到主机的当前路由。这是通过每个数据包增加IP协议的生存时间(TTL)一个来完成的,导致路由到主机的网关序列通过发送ICMP生存时间过期响应消息来显露自己(前提是防火墙没有阻止它们)。
例如,测试加利福尼亚州主机与弗吉尼亚州目标之间的当前路由:
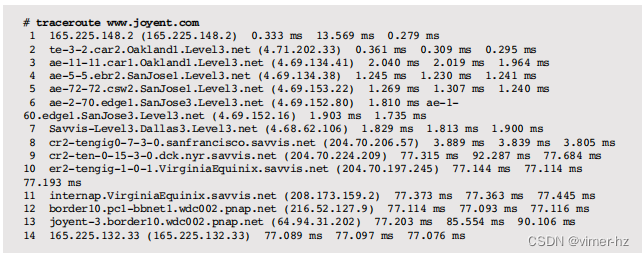
每个跳跃都显示了一系列三个RTT,可以用作粗略的网络延迟统计来源。与ping(8)一样,使用的数据包是低优先级的,可能比其他应用程序协议显示出更高的延迟。
路径也可以作为静态性能调优的一部分进行研究。网络被设计成动态的,并对故障做出响应。随着路径的改变,性能可能已经下降。
traceroute(8)最初由Van Jacobson编写。他后来创建了一个令人惊叹的工具称为pathchar。
10.6.9 pathchar
pathchar类似于traceroute(8),但包括跳跃之间的带宽[4]。这是通过多次发送一系列网络数据包大小并进行统计分析来确定的。以下是示例输出:
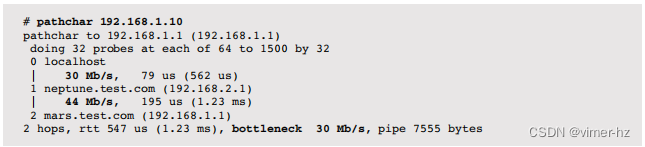
不幸的是,pathchar在某种程度上并没有变得流行(也许是因为据我所知,源代码没有发布),而且很难找到适用于现代操作系统的工作版本。它也非常耗时,根据跳数不同可能需要花费几十分钟来运行,尽管已经提出了减少此时间的方法[Downey 99]。
10.6.10 tcpdump
可以使用tcpdump(8)实用程序捕获和检查网络数据包。这可以在STDOUT上打印数据包摘要,也可以将数据包写入文件以供以后分析。后者通常更实用:数据包速率可能太高,无法实时跟踪它们的摘要。
将来自eth4接口的数据包转储到/tmp目录中的文件中:

输出记录了内核放弃传递给tcpdump(8)的数据包数量,这种情况发生在数据包速率过高时。
从转储文件中检查数据包:
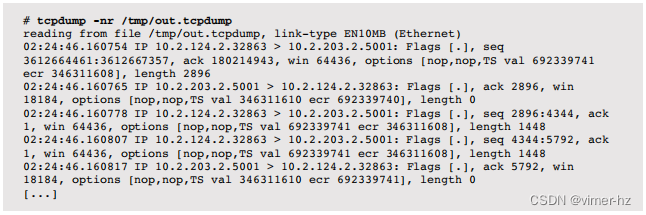
输出的每一行显示了数据包的时间(以微秒为分辨率)、源和目标IP地址以及TCP头的值。通过研究这些内容,可以详细了解TCP的运作,包括高级功能如何为您的工作负载提供服务。
使用了-n选项来不将IP地址解析为主机名。还有各种其他选项可用,包括在可用时打印详细信息(-v)、链路层头部(-e)和十六进制地址转储(-x或-X)。例如:
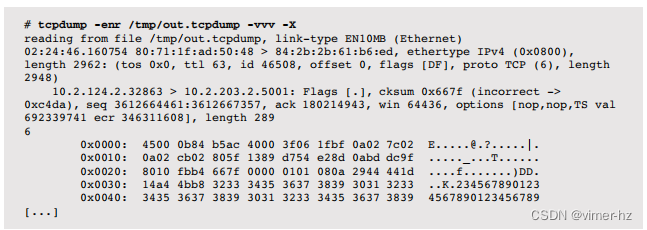
在性能分析过程中,将时间戳列更改为显示数据包之间的增量时间(-ttt)或自第一个数据包以来的经过时间(-ttttt)可能很有用。
还可以提供一个表达式来描述如何过滤数据包(请参阅pcapfilter(7)),以便集中在感兴趣的数据包上。这在内核中执行以提高效率(除了Linux 2.0及更早版本)。
数据包捕获在CPU成本和存储方面都很昂贵。如果可能的话,尽量仅在短时间内使用tcpdump(8)以限制性能成本。
如果有理由不使用snoop(1M)实用程序,可以将tcpdump(8)添加到基于Solaris的系统中。
10.6.11 snoop
虽然tcpdump(8)已经移植到基于Solaris的系统中,但用于数据包捕获和检查的默认工具是snoop(1M)。它的行为类似于tcpdump(8),也可以创建数据包捕获文件以供以后检查。使用snoop(1M),数据包捕获文件遵循[RFC 1761]标准。
例如,在ixgbe0接口上捕获数据包并将其写入/tmp中的文件:

输出包括到目前为止接收到的数据包。使用安静模式(-q)可以将此内容抑制,以便在通过网络会话执行时不会导致额外的网络数据包。
检查来自转储文件的数据包:

输出每个数据包包含一行,以数据包ID编号开头,接着是时间戳(以秒为单位,微秒分辨率)、源和目标IP地址,以及其他协议细节。使用-r选项禁用了将IP地址解析为主机名。
对于性能调查,可以根据需要修改时间戳。默认情况下,它们是增量时间戳,显示数据包之间的时间。-ta选项打印绝对时间:挂钟时间。-tr选项打印相对时间:与第一个数据包的时间差。
-V选项打印半详细输出,包括每个协议栈层的一行:

小写的 -v 选项打印完整详细输出,通常为每个数据包产生一页的输出:

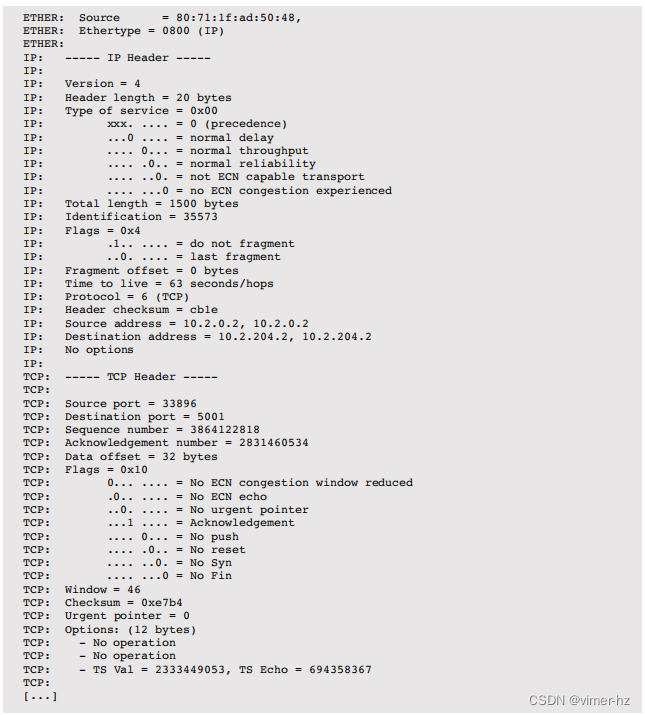
此示例仅包含了第一个数据包。snoop(1M)已经编程实现了解析多种协议的功能,可以快速进行命令行调查以处理各种网络流量。
还可以提供表达式来描述如何过滤数据包(请参阅snoop(1M)的man页面),以便专注于感兴趣的数据包。尽可能地,过滤是在内核中执行以提高效率。
请注意,默认情况下,snoop(1M)捕获整个数据包,包括所有有效负载数据。可以使用-s选项设置截取长度来在捕获时截断。许多版本的tcpdump(8)默认会截断。
10.6.12 Wireshark
虽然tcpdump(8)和snoop(1M)在日常调查中表现良好,但对于深入分析来说,在命令行中使用它们可能会耗费大量时间。Wireshark工具(以前称为Ethereal)提供了一个图形界面,用于数据包捕获和检查,并且还可以从tcpdump(8)或snoop(1M)导入数据包转储文件。其有用的功能包括识别网络连接及其相关数据包,以便可以分开研究,还可以翻译数百种协议头。
10.6.13 DTrace
DTrace可以用于检查内核和应用程序中的网络事件,包括套接字连接、套接字I/O、TCP事件、数据包传输、积压丢弃、TCP重传以及其他细节。这些功能支持工作负载特征化和延迟分析。
以下部分介绍了用于网络分析的DTrace,演示了适用于Linux和Solaris系统的功能。其中许多示例来自基于Solaris系统,也包括一些来自Linux。在第4章“可观测性工具”中包含了DTrace入门。
用于跟踪网络栈的DTrace提供程序包括表10.6中列出的那些。
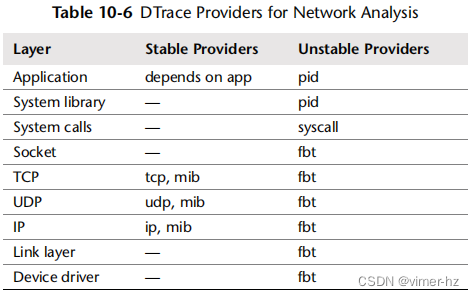
最好使用稳定的提供程序,但它们可能尚未在您的操作系统和DTrace版本中可用。如果没有,可以使用不稳定的接口提供程序,尽管脚本需要更新以匹配软件更改。
套接字连接
套接字活动可以通过执行网络操作的应用程序函数、系统套接字库、系统调用层或内核进行跟踪。系统调用层通常是首选,因为它有良好的文档、低开销(基于内核)且适用于整个系统。通过connect()计算出站连接的数量:

这个一行命令用于统计connect()系统调用的次数。在这种情况下,调用connect()最多的是名为haproxy的进程,它调用了22次connect()。如果需要,输出中可以包括其他详细信息,包括PID、进程参数和connect()参数。
通过accept()计算入站连接的数量:
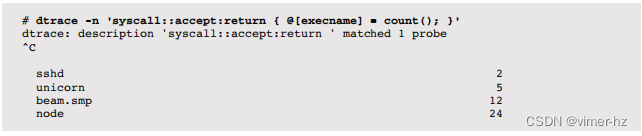
在这种情况下,名为node的进程接受了最多的连接,总共有24个。
在套接字事件期间,可以检查内核和用户级堆栈,以显示执行它们的原因,作为工作负载特征化的一部分。例如,以下跟踪连接()用户级堆栈的进程名为ssh:
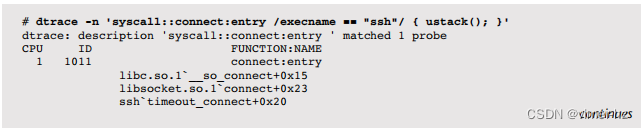

这些系统调用的参数也可以被检查。这需要DTrace比平常更多的工作,因为有趣的信息位于一个结构体中,必须从用户空间复制到内核空间,然后进行解引用。这由soconnect.d脚本执行(来自[Gregg 11])。
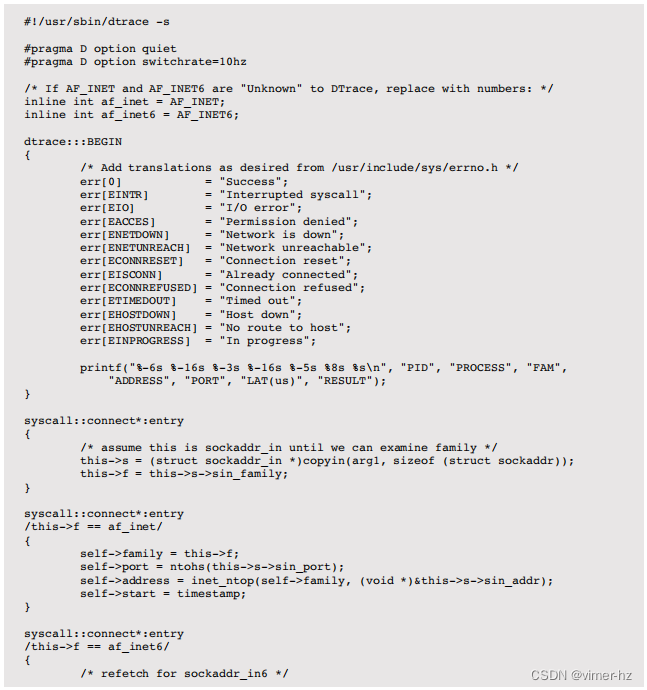
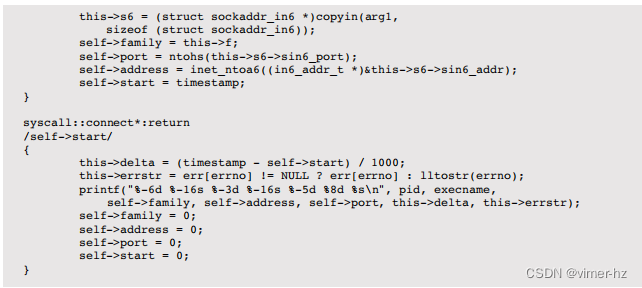
以下是示例输出:
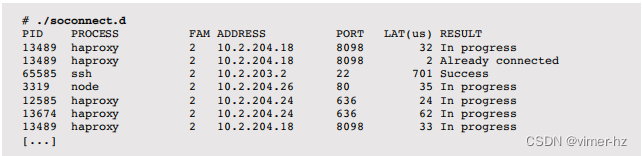
这跟踪connect()系统调用,并打印一行输出来总结它们。系统调用的延迟包括在内,并且系统调用返回的错误代码(errno)被转换为字符串。错误代码通常是“进行中”,这发生在非阻塞连接()中。
除了connect()和accept()之外,还可以跟踪socket()和close()系统调用。这允许在创建时查看文件描述符(FD),并通过时间差来测量套接字的持续时间。
套接字I/O
在建立套接字之后,可以基于文件描述符在系统调用层跟踪后续的读取和写入事件。这可以通过以下两种方式之一来执行:
关联数组的套接字FD:这涉及跟踪syscall::socket:return并构建一个关联数组,例如,is_socket[pid,arg1] = 1;。在谓词中可以检查数组以识别将来的I/O系统调用中的哪些FD是套接字。记得在syscall::close:entry上清除值。
如果在您的DTrace版本中可用,则使用fds[].fi_fs的状态。这是文件系统类型的文本字符串描述。由于套接字映射到VFS,它们的I/O与虚拟套接字文件系统关联。
以下一行命令使用了后一种方法。
通过execname计算通过read()或recv()读取的套接字数:
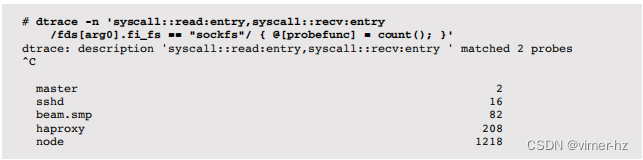
这个输出显示,在跟踪过程中,名为 node 的进程使用这些系统调用中的任何一个从套接字读取了 1,218 次。
通过 execname 计算通过 write() 或 send() 写入套接字的次数,是以下一行命令:

请注意,您的操作系统可能会使用这些系统调用的变体(例如,readv()),这些变体也应该被跟踪。
I/O 的大小也可以通过跟踪每个系统调用的返回探测来检查。
套接字延迟
鉴于可以在系统调用层跟踪套接字事件,以下测量可以作为延迟分析的一部分进行:
连接延迟:对于同步系统调用,连接(connect())的时间。对于非阻塞 I/O,从发出 connect() 到 poll() 或 select() (或其他系统调用) 报告套接字准备就绪的时间。
首字节延迟:从发出 connect() 或 accept() 返回的时间,到通过该套接字的任何 I/O 系统调用接收到第一个数据字节的时间。
套接字持续时间:从相同文件描述符的 socket() 到 close() 的时间。为了更专注于连接持续时间,可以从 connect() 或 accept() 计时。
这些可以作为长一行命令或脚本来执行。它们也可以从其他网络堆栈层次执行,包括 TCP。
套接字内部
可以使用 fbt 提供程序跟踪套接字的内部内核。例如,在 Linux 上,列出以 sock_ 开头的函数:

输出已被截断——它列出了超过 100 个探测点。可以单独跟踪每一个探测点,以及其参数和时间戳,以回答关于套接字行为的任意问题。
TCP 事件
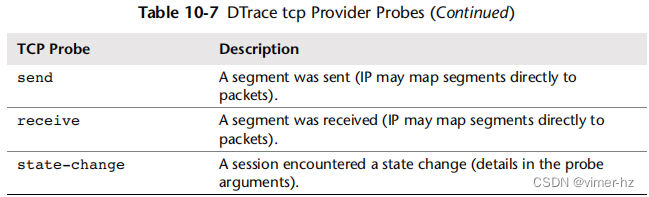
与套接字类似,可以使用 fbt 提供程序跟踪 TCP 的内部内核。但是,已经开发了一个稳定的 tcp 提供程序(最初由我开发),并且可能已经在您的系统上可用。这些探测点如表 10.7 所示。

其中大多数提供了显示协议头详细信息和内部内核状态的参数,包括“缓存”的进程ID。通常使用 DTrace 内置的 execname 跟踪的进程名称可能无效,因为内核 TCP 事件可能会异步发生于进程。频率统计接受的 TCP 连接(被动)与远程 IP 地址和本地端口:

在跟踪过程中,主机 10.2.204.30 连接到 TCP 本地端口 636 五次。类似的延迟可以使用 TCP 探针进行跟踪,如前面套接字延迟部分所述,使用 TCP 探针的组合。
列出 TCP 探针:

MODULE 和 FUNCTION 字段显示了探测点在内核代码中的(不稳定)位置,可以使用 fbt 提供程序跟踪以获取更多详细信息。
数据包传输
要研究 TCP 提供程序以外的内核内部情况,以及当 TCP 提供程序不可用时,可以使用 fbt 提供程序。这是动态跟踪使某些事情成为可能的情况之一——这比不可能要好,但不一定容易!网络堆栈的内部结构很复杂,初学者可能需要花费多天的时间来熟悉代码路径。
浏览堆栈的快速方法是跟踪一个深度事件,然后检查其堆栈回溯。例如,在 Linux 上,跟踪 ip_output() 并使用堆栈:
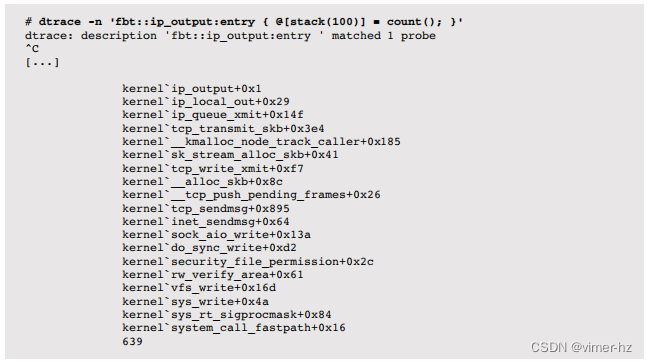
每行标识了一个可以单独跟踪的内核函数。这需要检查源代码以确定每个函数及其参数的作用。
例如,考虑到 tcp_sendmsg() 的第四个参数是以字节为单位的大小,可以使用跟踪它:
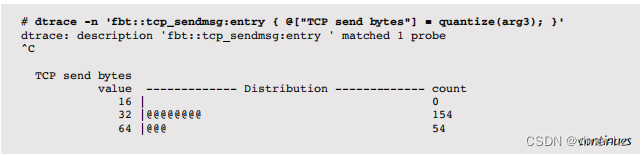

这个一行命令使用 quantize() 动作将 TCP 发送段的大小总结为二的幂分布图。大多数段的大小在 128 到 511 字节之间。
可以编写更长的一行命令和复杂的脚本,比如用于调查 TCP 重传和积压丢弃的脚本。
重传跟踪
研究 TCP 重传对于调查网络健康状态是一项有用的活动。虽然以往通常通过使用嗅探工具将所有数据包转储到文件中进行事后检查来执行此操作,但是 DTrace 可以实时检查重传,并且开销很低。以下脚本适用于 Linux 3.2.6 内核,跟踪 tcp_retransmit_skb() 函数并打印有用的细节:
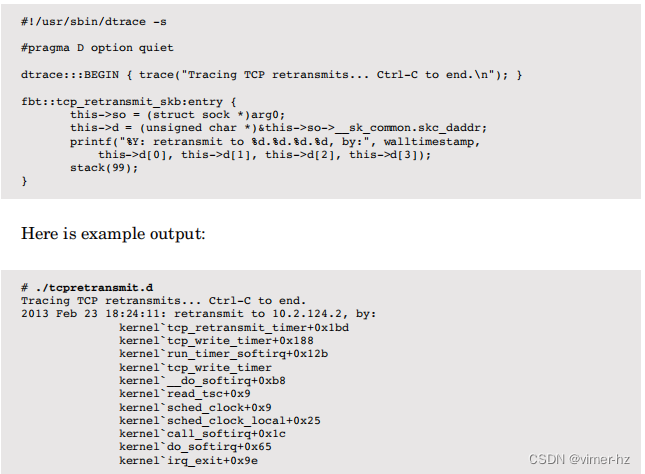

这包括时间、目标 IP 地址和内核堆栈跟踪,有助于解释为什么发生了重传。为了获得更详细的信息,可以单独跟踪内核堆栈中的每个函数。
类似的脚本已经为 SmartOS 开发,作为云运营商工具包的一部分。其中包括 tcpretranssnoop.d,其输出如下:
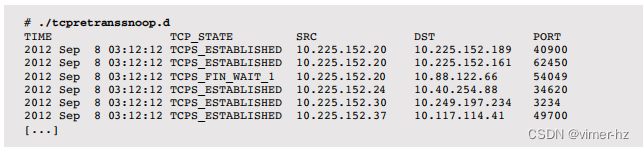
这显示了 TCP 重传的目标 IP 地址(在此输出中已编辑),并包括内核 TCP 状态。
积压丢弃
这个最后的示例脚本也来自 SmartOS 的 TCP 脚本工具包,用于估算是否需要进行积压调优以及其是否有效。这是一个较长的脚本,提供为高级分析的示例。
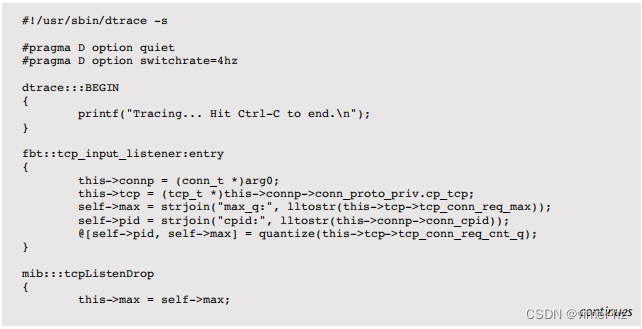
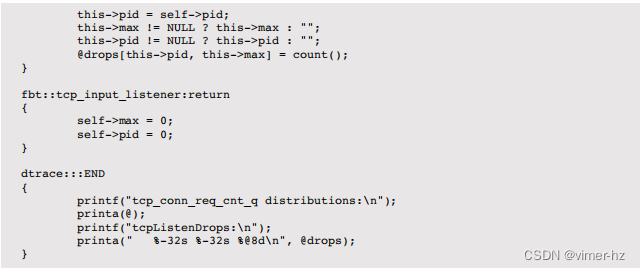
该脚本同时使用不稳定的 fbt 提供程序获取 TCP 状态,并使用 mib 提供程序计算发生丢弃的次数。
以下是示例输出:
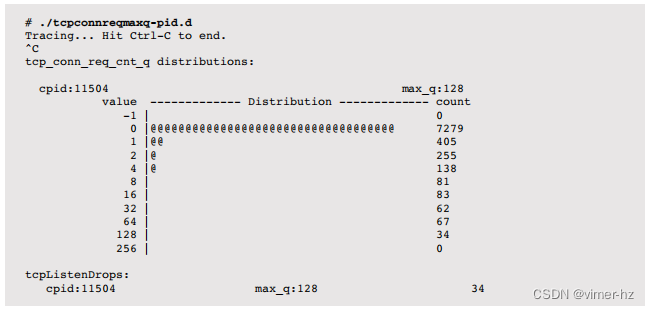
当按下 Ctrl-C 键时,将打印一个摘要,显示缓存的进程 ID(cpid)、套接字积压的当前最大长度(max_q),以及一个分布图,显示在添加新连接时测量的积压长度。输出显示,PID 11504 发生了 34 次积压丢弃,最大积压长度为 128。分布图显示,大部分时间积压长度为 0,只有一小部分将队列推到了最大值。这是增加队列长度的候选方案。
通常只有在发生丢弃时才调整这个积压队列,可以通过 netstat -s 命令的 tcpListenDrops 计数器看到这一点。这个 DTrace 脚本允许在丢弃成为问题之前预测丢弃并应用调整。以下是另一个示例输出:
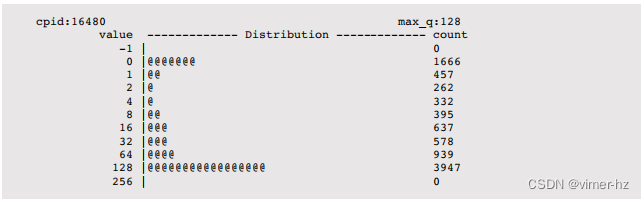
在这种情况下,积压通常达到了其 128 的限制。这表明应用程序负载过重,没有足够的资源(通常是 CPU)来跟上。
更多追踪
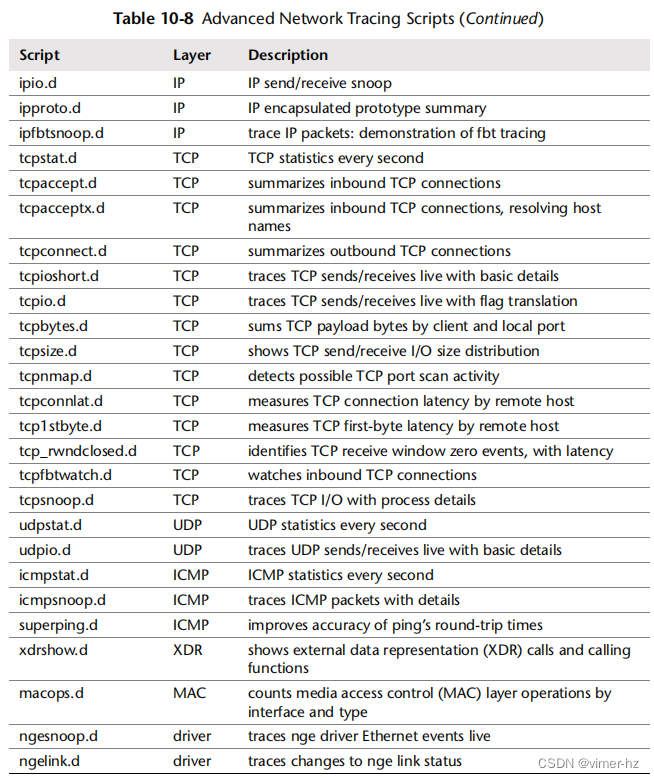
在需要时,动态追踪可以以其他方式和更详细的方式探索网络。为了提供对其功能的一个概念,表10.8 显示了来自 DTrace 的《网络底层协议》章节(158 页)中的脚本[Gregg 11]。这些脚本也可以在线查阅 [7]。

DTrace 书中还有一个关于应用层协议的章节,提供了许多用于跟踪 NFS、CIFS、HTTP、DNS、FTP、iSCSI、FC、SSH、NIS 和 LDAP 的更多脚本。尽管这种可观测性的程度令人难以置信,但其中一些动态跟踪脚本与特定的内核内部绑定在一起,需要进行维护以适应较新内核版本中的更改。另一些基于特定的 DTrace 提供程序,这些提供程序可能尚未在您的操作系统上可用。
10.6.14 SystemTap
SystemTap 也可以在 Linux 系统上用于动态跟踪文件系统事件。有关将先前的 DTrace 脚本转换的帮助,请参阅第 4 章“可观测性工具”的第 4.4 节“SystemTap”,以及附录 E。
10.6.15 perf
在第6章“CPU”中介绍的LPE工具集也可以提供一些网络事件的静态和动态跟踪。它可以用于识别在内核中导致网络活动的堆栈跟踪,就像以前使用DTrace进行数据包传输和重传跟踪一样。更高级的工具也可以使用后处理来开发。
例如,以下示例使用perf(1)为tcp_sendmsg()内核函数创建一个动态跟踪点,然后在5秒内跟踪它以及调用图(堆栈跟踪):
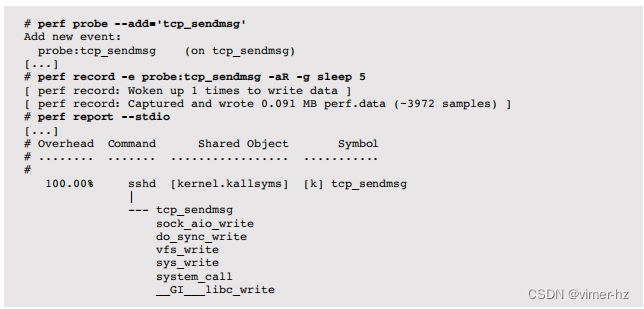
输出显示了导致内核调用tcp_sendmsg()发送数据的sshd的堆栈跟踪,以便通过TCP连接发送数据。
还有一些预定义的用于网络的跟踪点事件:

skb跟踪点用于套接字缓冲区事件,net用于网络设备。
这些也可以用于网络调查。
10.6.16 Other Tools
其他 Linux 网络性能工具包括:
- strace(1):用于跟踪与套接字相关的系统调用并检查所使用的选项(注意,strace(1)的开销较大)。
- lsof(8):按进程ID列出打开的文件,包括套接字详细信息。
- ss(8):套接字统计信息。
- nfsstat(8):NFS 服务器和客户端统计信息。
- iftop(8):按主机汇总网络接口吞吐量(嗅探器)。
- /proc/net:包含许多网络统计文件。
对于 Solaris:
- truss(1):用于跟踪与套接字相关的系统调用并检查所使用的选项(注意,truss(1)的开销较大)。
- pfiles(1):用于检查进程正在使用的套接字,包括选项和套接字缓冲区大小。
- routeadm(1M):用于检查路由和 IP 转发的状态。
- nfsstat(1M):NFS 服务器和客户端统计信息。
- kstat:提供来自网络堆栈和网络设备驱动程序的更多统计信息(其中许多在源代码之外未记录)。
还有许多网络监控解决方案,要么基于 SNMP,要么运行其自己的定制代理。
10.7 Experimentation
除了ping(8)、traceroute(8)和之前介绍过的pathchar之外,用于网络性能分析的其他实验性工具包括微基准测试。这些工具可以用于确定主机之间的最大吞吐量,有助于在调试应用程序性能问题时确定端到端网络吞吐量是否存在问题。
可以选择许多网络微基准测试工具。本节演示了流行且易于使用的iperf。另一个值得一提的是netperf,它也可以测试请求/响应性能。
10.7.1 iperf
iperf是一个用于测试最大TCP和UDP吞吐量的开源工具。它支持各种选项,包括并行模式:可以使用多个客户端线程,这可能对将网络推向极限是必要的。iperf必须在服务器和客户端上都执行。
例如,在服务器上执行iperf:

这将套接字缓冲区大小增加到128 KB(-l 128k),默认值为8 KB。
在客户端上执行以下操作:
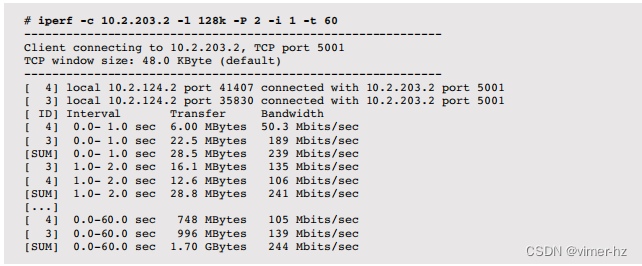
这使用了以下选项:
-c host:连接到主机名或IP地址
-l 128k:使用128 KB套接字缓冲区
-P 2:以两个客户端线程并行模式运行
-i 1:每秒打印间隔摘要
-t 60:测试的总持续时间:60秒
最后一行显示了测试期间的平均吞吐量,总和计算了所有并行线程:244 Mbits/s。
可以检查每个间隔摘要以查看随时间的变化。--reportstyle C选项可用于输出CSV格式,以便其他工具(如绘图软件)导入数据。
10.8 Tuning
网络可调参数通常已经调优,以提供高性能。网络栈通常也设计成能够动态响应不同的工作负载,从而提供最佳性能。
在尝试调整可调参数之前,首先了解网络使用情况是值得的。这可能还会识别出可以消除的不必要工作,从而带来更大的性能提升。尝试使用前一节中介绍的工具进行工作负载特性化和静态性能调优方法。
可用的可调参数在操作系统的不同版本之间会有所不同。请参阅它们的文档。接下来的各节提供了可能可用的内容以及它们如何进行调整的想法;它们应被视为根据您的工作负载和环境进行修订的起点。
10.8.1 Linux
可调参数可以使用sysctl(8)命令进行查看和设置,并写入/etc/sysctl.conf。它们也可以从/proc文件系统的/proc/sys/net目录下进行读取和写入。
例如,要查看当前TCP可用的参数,可以从sysctl(8)中搜索包含文本tcp的参数:


在这个内核(3.2.6-3)中,有63个包含tcp的参数,以及更多位于net目录下的参数,包括IP、以太网、路由和网络接口的参数。
具体调优的例子将在以下各节中进行介绍。
套接字和TCP缓冲区
所有协议类型的最大套接字缓冲区大小,包括读取(rmem_max)和写入(wmem_max),可以通过以下方式进行设置:

该值以字节为单位。为了支持全速的10 GbE连接,可能需要将其设置为16兆字节或更高。
启用TCP接收缓冲区的自动调优:
![]()
设置TCP读取和写入缓冲区的自动调优参数:

每个参数都有三个值:使用的字节数的最小值、默认值和最大值。使用的大小是根据默认值自动调整的。为了提高TCP吞吐量,尝试增加最大值。增加最小值和默认值将会消耗更多的内存每个连接,这可能是不必要的。
TCP队列
第一个队列是用于半开放连接的backlog队列:
![]()
第二个队列是用于传递连接到accept()的监听backlog队列:
![]()
这两个队列的大小可能需要从它们的默认值增加,例如,增加到4,096和1,024,或更高,以更好地处理负载突发情况。
设备队列
增加每个CPU的网络设备backlog队列的长度:
![]()
这可能需要增加,例如,对于10 GbE网卡,可以增加到10,000。
TCP拥塞控制
Linux支持可插拔的拥塞控制算法。列出当前可用的算法:

有些可能是可用的,但当前没有加载。例如,添加htcp算法:

当前的算法可以使用以下方式进行选择:
![]()
TCP选项
其他可以设置的TCP参数包括

SACK和FACK扩展,它们可以在高延迟网络上提高吞吐性能,但会增加一些CPU成本。
tcp_tw_reuse参数允许在看起来安全时重用TIME-WAIT会话。这可以允许两个主机之间的连接速率更高,例如在Web服务器和数据库之间,而不会因为TIME-WAIT状态的会话达到16位临时端口限制。
tcp_tw_recycle是另一种重用TIME-WAIT会话的方法,虽然不像tcp_tw_reuse那样安全。
网络接口
可以使用ifconfig(8)来增加TX队列长度,例如:
![]()
这对于10 GbE网卡可能是必要的。该设置可以添加到/etc/rc.local中,以便在启动时应用。
资源控制
容器组(cgroups)网络优先级(net_prio)子系统可用于为出站网络流量的进程或进程组应用优先级。
这可以用于优先处理高优先级的网络流量,例如生产负载,而不是低优先级的流量,例如备份或监控。配置的优先级值被转换为IP ToS级别(或使用相同位的更新方案)并包含在数据包中。
10.8.3 Configuration
除了可调参数之外,以下配置选项也可以用于调整网络性能:
以太网巨帧:将默认的MTU从1,500增加到约9,000可以提高网络吞吐量性能,如果网络基础设施支持巨帧。
链路聚合:多个网络接口可以组合在一起,以使它们作为一个单一的接口,并具有组合的带宽。这需要交换机的支持和配置才能正常工作。
套接字选项:应用程序可以使用setsockopt()来调整缓冲区大小,增加它(最多达到先前描述的系统限制)以提高吞吐量性能。这些对于两种操作系统类型都是通用的。
















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









