







 本文深入探讨JVM的线程私有区,包括虚拟机栈、本地方法栈和程序计数器。详细阐述了程序计数器在多线程中的作用,栈溢出问题,以及栈中存储的对象和操作数栈的运行机制。同时讲解了方法调用的本质,重写与重载的区别,并分析了方法返回地址在异常处理中的角色。
本文深入探讨JVM的线程私有区,包括虚拟机栈、本地方法栈和程序计数器。详细阐述了程序计数器在多线程中的作用,栈溢出问题,以及栈中存储的对象和操作数栈的运行机制。同时讲解了方法调用的本质,重写与重载的区别,并分析了方法返回地址在异常处理中的角色。
概述
上一篇学习了JVM的类加载子系统,这次就到JVM的核心内容之一——运行时数据区。因其内容较多,本篇先学习线程私有区部分。上图:

运行时数据区可分为两部分:线程私有区和线程共享区。线程私有区主要包含三个区域:虚拟机栈,本地方法栈,程序计数器。线程共享区主要包含:堆区,方法区。这次主要学习线程私有区,再上图看下线程私有区的内容。
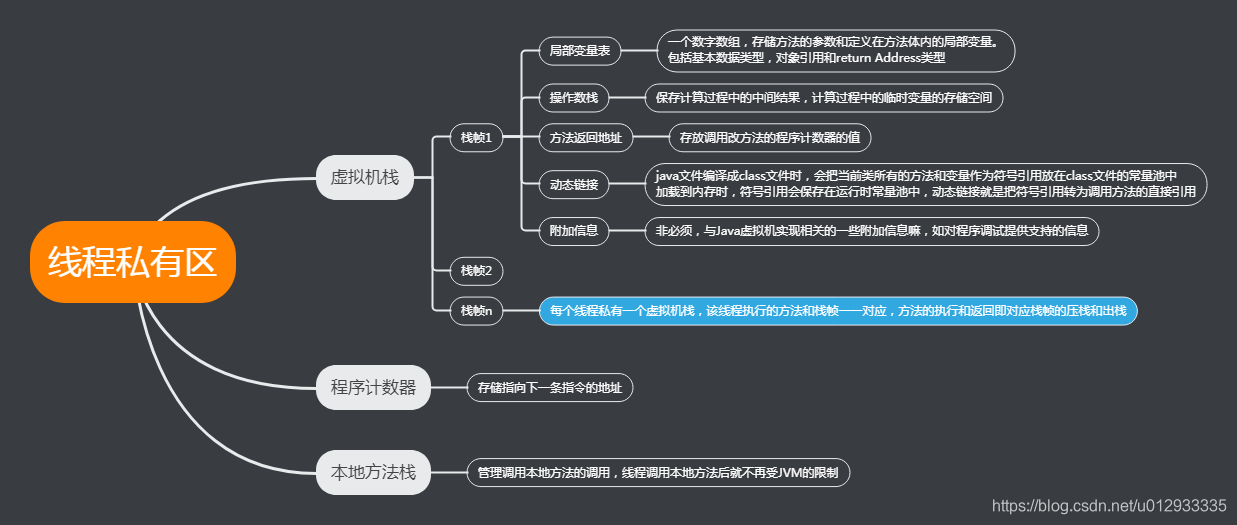
图中基本解释了线程私有区的划分和作用,接下来就通过问题的方式对每个区域进行深入的了解。
问题
1.为什么会有运行时数据区的概念呢?
JVM为Java程序提供了内存管理的功能:当我们启动一个Java程序,或者说JVM程序时,就开辟了运行时数据区这一块内存空间(逻辑上),当我们new一个对象时,所有申请内存,分配,赋值等操作JVM都帮我们完成了。为了更好的管理Java程序的内存空间,JVM会把这一块内存空间划分了不同区域和制定了相应的规则,所以就有了运行时数据区。
在Java程序中可以通过Runtime实例与JVM沟通。
/**
* Every Java application has a single instance of class
* <code>Runtime</code> that allows the application to interface with
* the environment in which the application is running. The current
* runtime can be obtained from the <code>getRuntime</code> method.
* <p>
* An application cannot create its own instance of this class.
*
* @author unascribed
* @see java.lang.Runtime#getRuntime()
* @since JDK1.0
*/
public class Runtime {
}
PS: JVM提供了内存管理的功能,无需像C语言一样申请,释放内存空间,减少了开发人员额外的工作量。但是呢,我们更需要对运行时数据区有更深的了解,否则在遇到问题的时候我们一无所知,就很难定位问题原因。
2. 为什么需要程序计数器(program counter register)?
1). 程序计数器是存储下一条指令的地址,分支,循环,跳转,异常处理,线程恢复等基础功能都是依赖它完成的。
2). 程序计数器在多线程并发的场景里十分必要,在CPU不断切换线程执行时,切换到当前线程的话,CPU就可以通过程序计数器存储的地址读取到下一条要执行的指令。这也是为什么程序计数器是线程私有的,可以保证在CPU不断切换过程中,保证每个线程的执行不会出错。
示例:
public int testPcCount() {
int a = 1;
int b = 2;
int c = 0;
if (a == 1) {
c = a + b;
} else {
c = b - a;
}
return c;
}
public int testPcCount();
descriptor: ()I
flags: ACC_PUBLIC
Code:
stack=2, locals=4, args_size=1
0: iconst_1
1: istore_1
2: iconst_2
3: istore_2
4: iconst_0
5: istore_3
6: iload_1
7: iconst_1
8: if_icmpne 18
11: iload_1
12: iload_2
13: iadd
14: istore_3
15: goto 22
18: iload_2
19: iload_1
20: isub
21: istore_3
22: iload_3
23: ireturn
代码中写了个简单的if-else判断逻辑,可以看到指令前面的1,2,3,4…就是指令地址,而在第8条指令if_icmpne时,后面带了一个18的指令地址,也就是说如果判断条件不符合的话,程序计数器的值就会变成18,执行引擎也就会去执行第18行的指令。第15行的goto语句也是类似。PS:如果是native方法的话,会变成undefined。
总结:程序计数器是对物理PC寄存器的抽象模拟,所以其空间很小,但运行速度最快,他也是唯一没有OutOfMemory的区域。
3. StackOverflow是什么?
首先,我们得明确StackOverflow中的stack其实就是虚拟机栈,StackOverflow也就是虚拟机栈空间不足溢出。虚拟机栈中保存的是和方法一一对应的栈帧,执行一个方法即对应一个栈帧的压栈,方法执行完毕对应栈帧的出栈。那么就可以知道StackOverflow出现的原因就是栈帧太多,导致内存不足。最容易想到的场景那就是递归了,递归没有跳出语句时,就会出现StackOverflow。那么如何解决呢?
解决方案:当然就是扩大虚拟机栈大小。如何扩?JVM规范允许虚拟机栈的大小是动态的或固定不变的。
固定大小:可以在Java程序启动时,设置虚拟机栈大小。使用 -Xss 设置, 作为Java后端开发者对-Xss应该都很熟悉。现在应该会更清楚-Xss的意思。-Xss 512k扩展:-Xmx -Xms是经常与-Xss一起出现的两个参数,后续也会学习。
动态扩展:在内存不足时,可以尝试进行扩展。如果在尝试扩展时发现无法申请到足够内存,则也会报出OutOfMemory。
4. 栈中可以存储对象嘛?
这好像是以前面试常问到的问题。栈其实是泛指,实际指的应该是局部变量表中可以存储对象嘛?答案是不可以,局部变量表是一个数字数组,存储方法参数和定义在方法内的局部变量。包括8种基本数据类型和对象引用,以及returnAddress类型。这也就是常说的栈存的是引用,堆存的是对象。
示例:
public void testLocalVariables(){
int a = 3;
boolean b = true;
byte c = 10;
double d = 1.00;
long e = 5;
Book book = new Book();
}
public void testLocalVariables();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=3, locals=9, args_size=1
0: iconst_3
1: istore_1
2: iconst_1
3: istore_2
4: bipush 10
6: istore_3
7: dconst_1
8: dstore 4
10: ldc2_w #37 // long 5l
13: lstore 6
15: new #39 // class com/yu/other/TestJvm$Book
18: dup
19: aload_0
20: invokespecial #40 // Method com/yu/other/TestJvm$Book."<init>":(Lcom/yu/other/TestJvm;)V
23: astore 8
25: return
LineNumberTable:
line 83: 0
line 84: 2
line 85: 4
line 86: 7
line 87: 10
line 88: 15
line 89: 25
LocalVariableTable:
Start Length Slot Name Signature
0 26 0 this Lcom/yu/other/TestJvm;
2 24 1 a I
4 22 2 b Z
7 19 3 c B
10 16 4 d D
15 11 6 e J
25 1 8 book Lcom/yu/other/TestJvm$Book;
testLocalVariables是我写的方法,编译后对class进行javap -v,就可以看到LocalVariableTable。知识点来了。
知识点1: 表头的含义
Start和Length: Start是指该变量的起始位置,Length可以理解为作用长度,就是说这个变量可以在多长的范围内使用。
Slot:中文翻译:槽,是局部变量填充的基本单位。
Name:很好理解,就是局部变量的名字
Signature: 以前还叫descriptor,就是变量类型的标记
| 变量类型 | Signature |
|---|---|
| int | I |
| boolean | Z |
| short | S |
| byte | B |
| float | F |
| char | C |
| double | D |
| long | J |
| reference | L+类的全路径名(eg: Lcom/yu/other/TestJvm) |
知识点2: this
局部变量表中第一位是this,当前方法是构造方法或实例方法的话,局部变量表中的对象就是this引用,其实也很好理解,我们经常在实例方法中通过this获取当前类的实例变量,所以this引用要放在当前方法中。
知识点3: Start&Length
我们通过this来进一步了解下Start和Length,this初始位置是0,作用域长度是26。我们最后一条指令地址是25,所以总长度就是26,this从初始位置到方法结束都可以使用,那么作用域也就是从0开始,长度为26。再看一个作用域的例子
public void testLocalStartAndLength(){
{
int a = 3;
int b = 5;
int c = a + b;
System.out.println(c);
}
int d = 10;
}
public void testLocalStartAndLength();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=2, locals=4, args_size=1
0: iconst_3
1: istore_1
2: iconst_5
3: istore_2
4: iload_1
5: iload_2
6: iadd
7: istore_3
8: getstatic #16 // Field java/lang/System.out:Ljava/io/PrintStream;
11: iload_3
12: invokevirtual #42 // Method java/io/PrintStream.println:(I)V
15: bipush 10
17: istore_1
18: return
LineNumberTable:
line 96: 0
line 97: 2
line 98: 4
line 99: 8
line 101: 15
line 102: 18
LocalVariableTable:
Start Length Slot Name Signature
2 13 1 a I
4 11 2 b I
8 7 3 c I
0 19 0 this Lcom/yu/other/TestJvm;
18 1 1 d I
}
从上面的例子就能更清楚的理解作用域的含义,a,b,c三个字段是无法在括号之外使用的,所以作用域都是在指令地址15之前可用。
知识点4 : Slot的重复利用
根据知识点3可知,局部变量是有作用域的,出了作用域,局部变量即失效。而Slot是用来存储局部变量的,那么出了作用域的局部变量就可以废弃了,也就引出了Slot的重复利用。当局部变量失效后,所占的Slot也就空闲了,后续声明的变量就可以使用之前的Slot了。看知识点3在括号外,声明的int d变量,可以看到所占Slot是1,而1之前是变量a的Slot。这也就是Slot的重复利用。
另外,这里也看到this所在位置并不是第一位,但是呢,可以看到,其实际位置,作用域,Slot是放在初始位置的。为什么不把this放到第一位呢?我们再看个例子,我也是在测试中发现这个原因的。
首先普及一下,一个Slot大小是32位,基本数据类型中double,long是64位,占2个Slot,其余都是32位,占1一个Slot。那么问题来了,当一个int值出了作用域之后,声明了一个long值,slot会复用嘛?JVM很巧妙的解决了这个问题。我们举个例子
public void testLocalStartAndLengthV2(){
int b;
int c = 2;
{
int a = 1;
b = 3;
c = a + b;
}
long d = 10;
}
LocalVariableTable:
Start Length Slot Name Signature
4 6 3 a I
0 15 0 this Lcom/yu/other/TestJvm;
6 9 1 b I
2 13 2 c I
14 1 3 d J
作用域小的a被放在了局部变量表第一位,同时被赋予了最后一个Slot。这样后续声明long值时,就可以复用a的slot加上后面的slot。
故:可以理解到JVM会优先把作用域小的变量优先处理,并置于最后的Slot,以便后续Slot的复用。
知识点5: locals=9
在知识点1中,code下面有这么一段语句:stack=3, locals=9, args_size=1。
这里locals就是局部变量表的大小,也就是slot的数量。可以理解到局部变量表的大小在编译时就已经确定!
知识点6:局部变量表会被GC嘛?
局部变量表是线程私有的,和线程的生命周期保持一致。所以不会被GC。但局部变量表是GC的重要根节点。GC的引用计数法,就是根据局部变量表中的引用是否还存在,此外这里还涉及到四大引用,强引用,软引用,弱引用,虚引用。也是GC的重要依据,后续会再做进一步的解释。
4. 操作数栈是如何运行的?
直接上代码:
public void testOperandStack() {
int a = 3;
int b = 5;
int d = 6;
int c = a * (b + d);
}
public void testOperandStack();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=3, locals=5, args_size=1
0: iconst_3 //声明int变量3
1: istore_1 //存储到局部变量表位置1中
2: iconst_5
3: istore_2
4: bipush 6 //声明int变量6
6: istore_3 //存储到局部变量表位置3中
7: iload_1 //从局部变量表位置1的变量加载到操作数栈
8: iload_2 //从局部变量表位置1的变量加载到操作数栈
9: iload_3
10: iadd //栈顶两元素相加,放在栈顶
11: imul //栈顶两元素相乘,放在栈顶
12: istore 4 //将栈顶元素存到局部变量表位置4中。
14: return
从字节码指令的注释中,就可以看到iload操作就是把需要进行运算的值加载到操作数栈。iadd,imul就是对操作数栈中的值进行运算。并把临时运算结果存储在操作数栈中。
ps:这里有个小知识点,细心的朋友可能会看到,声明d变量的时候用的是bipush,而不是iconst,这是因为JVM对于int不同范围的取值使用了不同的指令:当int取值-1~5采用iconst指令,取值-128~127采用bipush指令,取值-32768~32767采用sipush指令,取值-2147483648~2147483647采用 ldc 指令。有兴趣的可以研究下。
5.栈顶缓存技术
操作数都是存储在内存中的,因此频繁地执行内存读写操作必然会影响执行速度,Hotspot的设计者提出了栈顶缓存:将栈顶元素全部缓存在物理CPU的寄存器中,降低对内存的读写次数,提高执行引擎的执行效率。
6. 方法的重写和重载的区别
方法调用示例
了解重写和重载之前,先从JVM角度看下方法的实质,看下常见方法调用的字节码:
private void testPrivate() {
}
public void testPublic() {
}
private static void testStatic() {
}
public final void testFinal() {
}
public void testMethod() {
testPrivate();
testPublic();
testStatic();
testFinal();
}
public void testMethod();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #2 // Method testPrivate:()V
4: aload_0
5: invokevirtual #3 // Method testPublic:()V
8: invokestatic #4 // Method testStatic:()V
11: aload_0
12: invokevirtual #5 // Method testFinal:()V
15: return
从字节码指令能看到调用方法时,有以下几个指令:invokespecial,invokevirtual,invokestatic,指令后面跟着#2,#3等序号。所以基本可以确定字节码里方法调用分为两部分:指令+序号。我们先深入了解下这两块。
知识点1 调用方法的字节码指令
调用方法的字节码指令分为下面5个指令,6种情况。其中invokedynamic是在jdk1.7时才出现。
| 指令 | 描述 | 备注 |
|---|---|---|
| invokespecial | 实例构造器,私有实例方法,父类实例方法 | 静态解析 |
| invokestatic | 静态方法 | 静态解析 |
| invokevirtual | 非私有实例方法 final修饰 | 静态解析 |
| invokevirtual | 非私有实例方法 非final修饰 | 动态分派 |
| invokeinterface | 接口方法 | 动态分派 |
| invokedynamic | 动态方法 | 动态分派 |
现在我们先总结出一点:不同类型的方法在调用时,对应JVM不同的字节码指令
知识点2 符号引用
字节码指令后面都会跟上一个地址:#2,#3,#4…很明显这是个索引序号。从动态链接里,我们知道Java文件在编译成class文件时,会把所有的成员变量和方法转做符号引用存储在class文件的常量池,在class文件加载时,会把这部分信息加载到运行时常量池中。
那就先到常量池中看下索引序号的信息,如下(javap反编译后的字节码文件的最上方就是常量池信息):
Constant pool:
#1 = Methodref #23.#68 // java/lang/Object."<init>":()V
#2 = Methodref #22.#69 // com/yu/other/TestMethod.testPrivate:()V
#3 = Methodref #22.#70 // com/yu/other/TestMethod.testPublic:()V
#4 = Methodref #22.#71 // com/yu/other/TestMethod.testStatic:()V
#5 = Methodref #22.#72 // com/yu/other/TestMethod.testFinal:()V
我们之前的序号是从2开始的,看常量池就明白了原来类的构造函数方法排在第一位。
序号后面是Methodref,表示是方法引用,指向的就是对应的方法。当然,并没这么简单。我们先来剖析一下后面注释的内容: com/yu/other/TestMethod.testPrivate:()V,这个在JVM中就叫做符号引用。存储在常量池中的也就是这个内容。那我们来看下符号引用的组成结构:

符号引用,顾名思义仅仅是个符号,那么调用方法时,如何找到实际方法呢?再次回顾下动态链接的作用:把符号引用转为调用方法的直接引用。那就续上了。小结:方法调用的本质是根据方法的符号引用确定方法的直接引用(入口地址)
知识点3 符号引用到直接引用
方法调用根据调用方法能否在编译期间确定分为两种方式:静态解析,动态分派。下面是一些概念,主要记住静态解析,动态分派;非虚方法和虚方法。
| 调用方法可以在编译期间确定 | 调用方法无法在编译期间确定 | |
|---|---|---|
| 方法调用 | 静态解析 | 动态分派 |
| 符号引用转为直接引用 | 静态链接 | 动态链接 |
| 方法的绑定机制 | 早期绑定 | 晚期绑定 |
| 方法类型 | 非虚方法 | 虚方法 |
符号引用转为直接引用会因为调用方法是否可以在编译期间确定而有不同。回看知识点1中字节码指令表格内的备注,不同的字节码指令就已经确定了是静态链接还是动态链接,除了invokevirtual,这个方法需要区分是否方法是否是final方法来确定是静态链接还是动态链接。
静态链接对应的方法:static,private,构造函数,final,super。
静态链接加载过程
类加载解析阶段:如果对类的加载还有印象的话,记得在链接的解析的作用就是将常量池的符号引用转换为直接引用。过程:根据符号引用中的类名,找到类中简单方法名和方法描述符一致的方法,找到的话就转为直接引用。否则依次向上到父类中查找。
调用阶段:已转为直接引用,直接调用即可。invokestatic,invokespecial的区别在于:invokespecial调用前,需要将实例对象加载到操作数栈,invokestatic不用。
invokevirtual过程:
类加载解析阶段:解析类的继承关系,生成类的虚方法表。
虚方法表:类中声明的虚方法的入口地址会按固定顺序存放在虚方法表中。虚方法表会继承父类的虚方法表,顺序与父类保持一致,子类新增的方法按顺序添加到虚方法末尾,子类重写的父类方法,则重写方法位置的入口地址修改为子类实现。
调用阶段: 动态分派,根据变量的实际类型,查找实际类的虚方法表,并且根据索引找到对应方法的实际地址。
invokeinterface与invokevirtual类似,但因为Java接口是可以多继承的,虚拟机提供了itable(interface method table)来支持多接口,itable由偏移量表offset table与方法表method table两部分组成。当需要调用某个接口方法时,虚拟机会在offset table查找对应的method table,随后在该method table上查找方法。
知识点4 重载和重写
现在我们再回头看看重载和重写,先从表现角度看看:
重载:相同的函数名,不同的参数类型或个数
重写:子类集成父类,重新父类的方法,函数名相同,参数类型和个数均一致。
重载方法在编译成class文件生成符号引用时,会因为方法描述符的不同而区分为不同的符号引用,从JVM的角度来看就是不同的方法,和其他方法无任何区别。
重写方法:在加载解析阶段,生成虚方法表或接口方法表;在调用阶段,查询虚方法表或者接口方法表才能取得方法的入口地址。
7. 方法返回地址的作用
方法返回地址:存储调用该方法的程序计数器的值。
作用:方法的调用和完成从JVM来看就是栈帧的压栈和出栈。在出栈时,需要恢复调用该方法的上层方法的运行信息。
1.将程序计数器的值设置为方法返回地址,以便上层方法继续执行;
2.若当前方法有返回值,会将返回值压入上层方法的操作数栈
上述都是在方法正常直接结束的情况,那如果抛了异常呢?当Java代码被编译成class文件时,会生成一个异常表。
当方法出现异常时,会遍历异常表中的所有条目,当触发异常的字节码的索引值在某个异常表条目的监控范围内,JVM会判断抛出的异常和想要捕获的异常进行匹配,若匹配,则将程序计数器的值转为该条目的target的值。反之,则继续查找,直到结束。
若结束也没有匹配上的话,当前栈帧出栈时,不会给上层方法传递相关值,而上层方法会重复前面的步骤,去做异常的匹配。最坏的情况,JVM会遍历当前线程所有栈帧的异常表。
异常表示例如下:方法声明中throws的异常是不在异常表的。
public void testException() throws IndexOutOfBoundsException, FileNotFoundException {
try {
System.out.print("1111");
} catch (NumberFormatException e) {
System.out.print("2222");
}
try {
System.out.print("1111");
} catch (ArithmeticException e) {
System.out.print("2222");
}
}
public void testException() throws java.lang.IndexOutOfBoundsException, java.io.FileNotFoundException;
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=2, locals=2, args_size=1
0: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #3 // String 1111
5: invokevirtual #4 // Method java/io/PrintStream.print:(Ljava/lang/String;)V
8: goto 20
11: astore_1
12: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
15: ldc #6 // String 2222
17: invokevirtual #4 // Method java/io/PrintStream.print:(Ljava/lang/String;)V
20: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
23: ldc #3 // String 1111
25: invokevirtual #4 // Method java/io/PrintStream.print:(Ljava/lang/String;)V
28: goto 40
31: astore_1
32: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
35: ldc #6 // String 2222
37: invokevirtual #4 // Method java/io/PrintStream.print:(Ljava/lang/String;)V
40: return
Exception table:
from to target type
0 8 11 Class java/lang/NumberFormatException
20 28 31 Class java/lang/ArithmeticException
异常表中from,to就是异常捕获的字节码指令地址范围,target就是捕获到异常后跳转到的指令地址。
总结
JVM运行时数据区分为线程私有区和共享区,线程私有区的重点就是我们常说虚拟机栈。当然其中细节很多,也很复杂,妄图通过一篇文章学完也是不现实的事情,至少可以记得其大概组成结构,每个结构的大概作用。在和其他程序员交谈时,总不会显得自己还是个不懂JVM的初级程序员吧!
参考链接:
https://www.jianshu.com/p/b5b919f24f82

















 1656
1656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









