








作为一名大数据开发工程师,经常需要处理和优化分布式计算任务。最近,我在处理一个复杂的 Spark 作业时,遇到了一个棘手的问题:容器因为内存超限被 YARN 终止。
这次经历让我深刻理解了内存管理的重要性,也学到了许多实用的技巧。下面,我将分享这次排查和解决问题的全过程。
起因:意外的中断
那天,我接到一个紧急任务,需要处理一组巨大的日志数据来生成每日业务报表。这份报表对于公司的业务决策至关重要,需要在几个小时内完成。于是,我将任务提交到 Amazon EMR 上的 Spark 集群,希望能快速完成计算。然而,不久后,我收到了错误通知:“Container killed by YARN for exceeding memory limits”。任务中断了,我必须找到解决方案。
初步调查:日志分析

第一步,我深入查看了 YARN 日志,确认了内存超限是导致容器被终止的原因。显然,默认的内存设置不足以支撑这个高负载任务。于是,我决定从几个方面逐步优化,确保作业顺利运行。
提高内存开销
我的第一个尝试是提高内存开销。内存开销是分配给每个执行者的外堆内存量,用于 Java NIO 直接缓冲区、线程堆栈等。默认情况下,内存开销是执行程序内存的 10% 或 384MB,以较高者为准。我逐步将内存开销提高到 25%,希望能缓解内存压力。

-
在正在运行的集群上修改配置:
sudo vim /etc/spark/conf/spark-defaults.conf spark.driver.memoryOverhead 512 spark.executor.memoryOverhead 512 -
在新的集群上启动时添加配置:
[ { "Classification": "spark-defaults", "Properties": { "spark.driver.memoryOverhead": "512", "spark.executor.memoryOverhead": "512" } } ] -
对于单个作业,在运行 spark-submit 时增加内存开销:
spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --conf spark.driver.memoryOverhead=512 --conf spark.executor.memoryOverhead=512 /usr/lib/spark/examples/jars/spark-examples.jar 100
遗憾的是,尽管内存开销增加了,问题依然存在。我意识到需要进一步优化。
减少执行程序内核数量
接下来,我考虑减少执行程序的内核数量。这意味着每个执行程序可以执行的任务数量减少,从而降低内存需求。我将驱动程序和执行程序的内核数量减少到 3 核。

-
在正在运行的集群上修改配置:
sudo vim /etc/spark/conf/spark-defaults.conf spark.driver.cores 3 spark.executor.cores 3 -
在新的集群上启动时添加配置:
[ { "Classification": "spark-defaults", "Properties": { "spark.driver.cores": "3", "spark.executor.cores": "3" } } ] -
对于单个作业,在运行 spark-submit 时减少内核数量:
spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --executor-cores 3 --driver-cores 3 /usr/lib/spark/examples/jars/spark-examples.jar 100
即使这样调整,任务仍然因为内存问题而失败。看来需要更彻底的解决方案。
增加分区数量
考虑到任务的规模,我决定增加分区数量,以减少每个分区的内存负担。我修改了 spark.default.parallelism 的值,并在代码中使用 .repartition() 操作,成功减少了每个分区的内存需求。然而,问题依然未能完全解决。

提高驱动程序和执行程序内存
最后,我决定提高驱动程序和执行程序的内存,但不能同时增加两者。确保总内存开销不超过实例的限制是关键。

-
在正在运行的集群上修改配置:
sudo vim /etc/spark/conf/spark-defaults.conf spark.executor.memory 1g spark.driver.memory 1g -
在新的集群上启动时添加配置:
[ { "Classification": "spark-defaults", "Properties": { "spark.executor.memory": "1g", "spark.driver.memory": "1g" } } ] -
对于单个作业,在运行 spark-submit 时提高内存:
spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --executor-memory 1g --driver-memory 1g /usr/lib/spark/examples/jars/spark-examples.jar 100
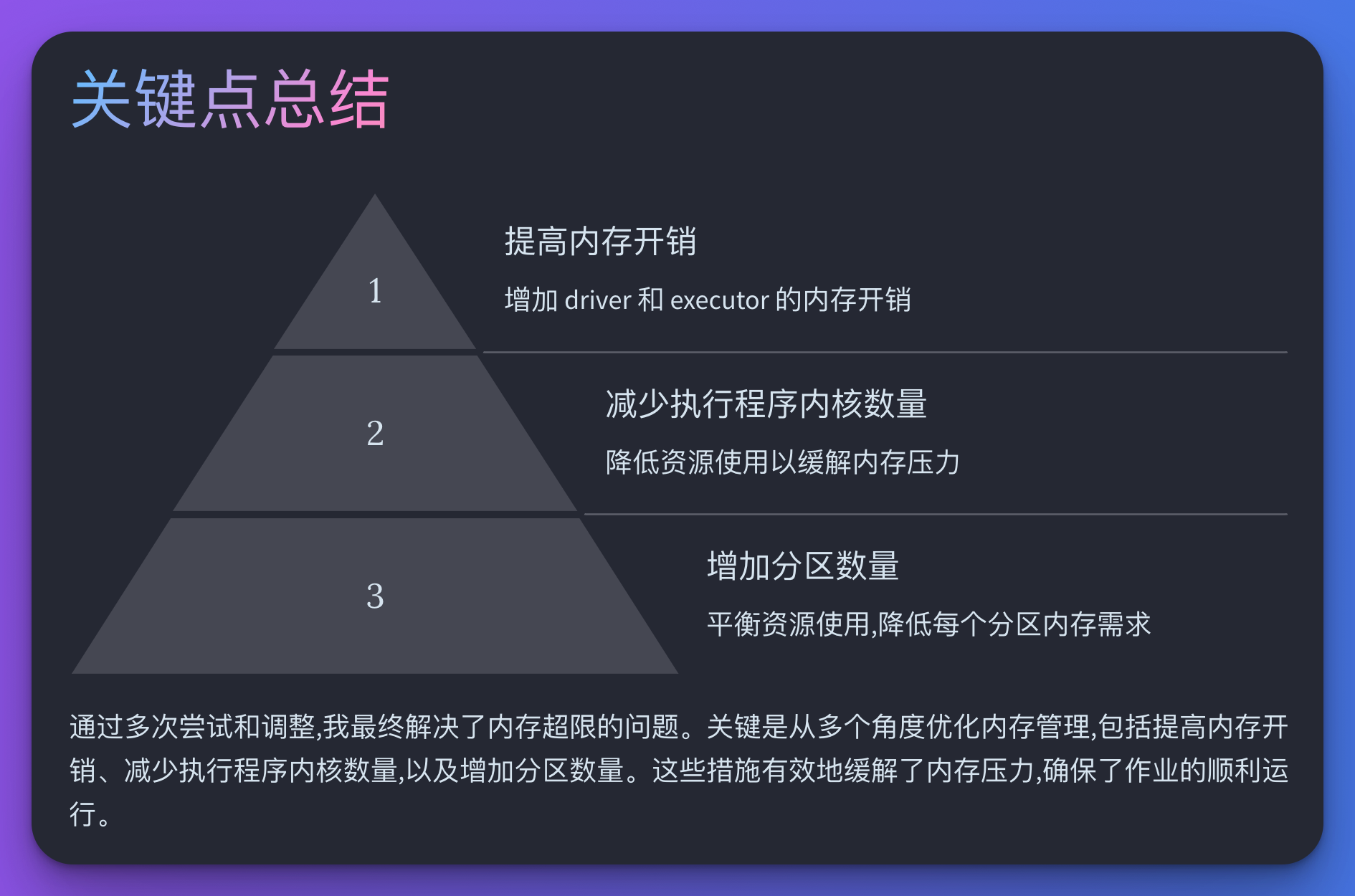
总结:最终解决方案
经过多次尝试和调整,我终于解决了内存超限的问题。总结起来,以下几点是关键:
基准测试
使用示例数据集运行应用程序,识别潜在的内存问题。

数据筛选
确保处理最少量的数据,避免多余数据拖慢应用程序。

分区策略
使用合理的分区策略,避免大型分区和数据倾斜。

EC2 实例类型
选择更大的内存优化型实例,以满足工作负载需求。

通过这些方法,我成功优化了 Spark 任务,确保了业务报表的及时生成。这次经历不仅提升了我的技术能力,也让我深刻体会到内存管理的重要性。

希望这些经验对大家有所帮助,在面对类似问题时,能够快速找到合适的解决方案。
















 5740
5740

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











