








作为一名大数据开发,我深知学习新技术的重要性。今天,我想和大家分享如何高效学习Flink这个强大的流处理框架。
目录
Flink是什么?

Apache Flink是一个开源的分布式大数据处理引擎,用于对无界和有界数据流进行有状态的计算。它提供了数据流上的精确一次处理语义,以及事件时间和处理时间的灵活窗口机制。
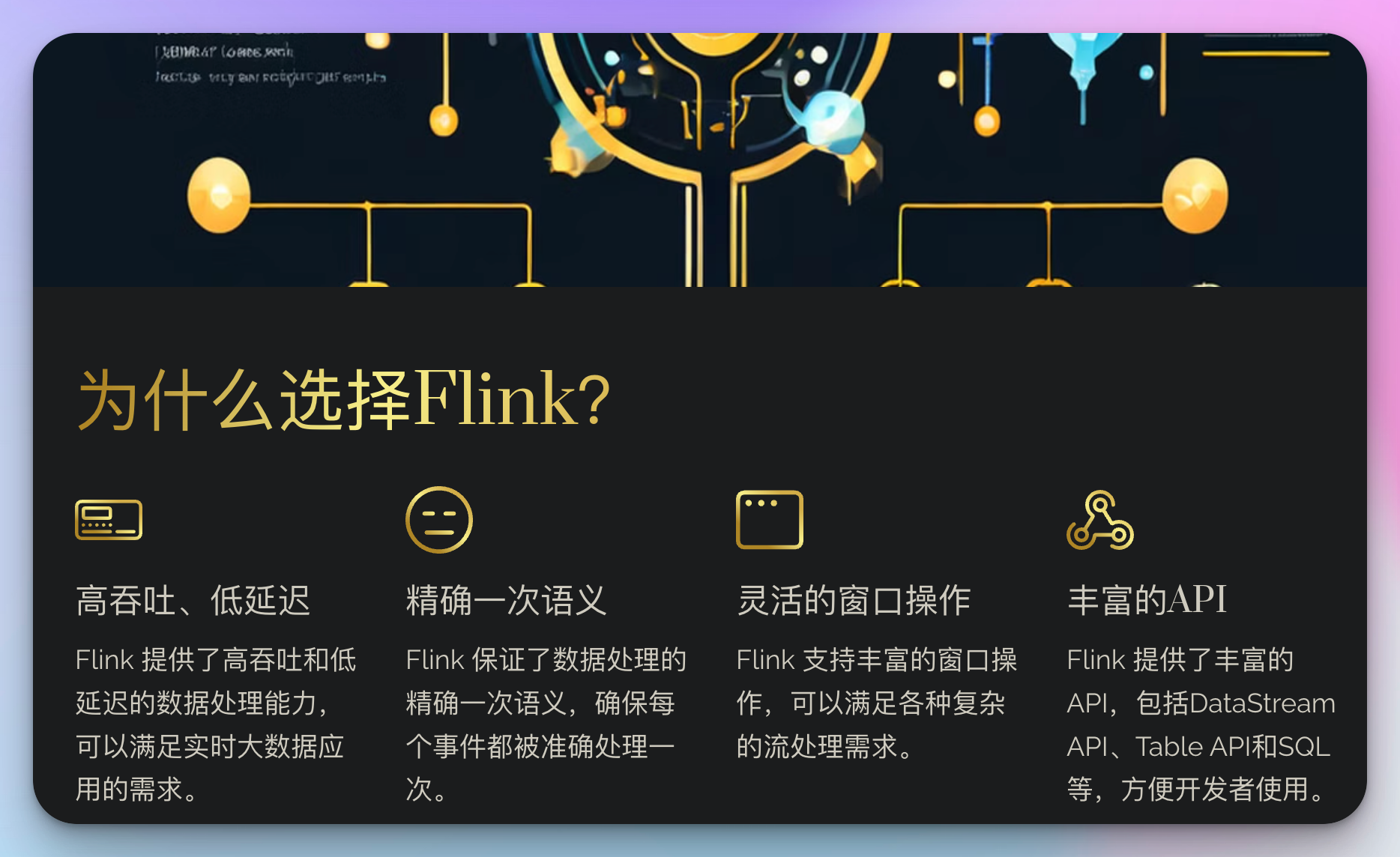
为什么选择Flink?
- 高吞吐、低延迟
- 精确一次语义
- 灵活的窗口操作
- 丰富的API
学习Flink的糙快猛之路
1. 建立概念框架
首先,我们需要对Flink的核心概念有一个大致了解:
- DataStream API
- 窗口操作
- 状态管理
- 时间语义

不要一开始就追求完全理解每个细节,先建立一个框架,后续再填充。
2. 动手实践
记得我刚开始学习Flink时,连Java都不太熟悉。但我没有被这些困难吓倒,而是选择直接上手写代码。
这里有一个简单的WordCount示例:
public class WordCount {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> text = env.fromElements(
"To be, or not to be,--that is the question:--",
"Whether 'tis nobler in the mind to suffer"
);
DataStream<Tuple2<String, Integer>> counts = text
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
for (String word : value.toLowerCase().split("\\W+")) {
out.collect(new Tuple2<>(word, 1));
}
}
})
.keyBy(0)
.sum(1);
counts.print();
env.execute("Word Count Example");
}
}
这段代码可能看起来很复杂,但不要被吓到。先运行起来,看看结果,然后逐步理解每一部分的作用。
3. 利用大模型助手

在学习过程中,遇到不懂的概念或代码,可以随时询问AI助手。比如:
“请解释一下Flink中的KeyBy操作是什么意思?”
AI助手可以给出清晰的解释,帮助你快速理解概念。

4. 构建小项目
学习了基础知识后,尝试构建一个小项目。比如,一个实时统计网站访问量的应用。这将帮助你将零散的知识点串联起来。

5. 阅读官方文档
在实践中遇到问题时,查阅官方文档。这不仅能解决问题,还能加深对Flink的理解。

6. 参与社区
加入Flink的GitHub仓库,阅读issues和PR,甚至尝试解决一些简单的bug。这将极大地提升你的技能。

进阶学习:深入Flink核心概念
让我们继续深入探讨如何更有效地学习和应用Flink。
1. 时间语义
Flink提供了三种时间语义:事件时间、摄入时间和处理时间。理解这些概念对于处理实时数据流至关重要。

例如,考虑一个实时订单处理系统:
DataStream<Order> orders = ...
DataStream<Order> lateOrders = orders
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<Order>forBoundedOutOfOrderness(Duration.ofMinutes(5))
.withTimestampAssigner((order, timestamp) -> order.getEventTime())
)
.keyBy(Order::getUserId)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.process(new LateOrderDetector());
这段代码使用事件时间语义,允许处理最多5分钟的乱序数据,并在1小时的滚动窗口内检测迟到订单。
2. 状态管理

Flink的状态管理是其强大功能之一。理解如何使用和管理状态可以帮助你构建复杂的流处理应用。
这里有一个使用状态的简单示例:
public class StatefulCounter extends KeyedProcessFunction<String, Long, Long> {
private ValueState<Long> countState;
@Override
public void open(Configuration parameters) {
countState = getRuntimeContext().getState(new ValueStateDescriptor<>("count", Long.class));
}
@Override
public void processElement(Long value, Context ctx, Collector<Long> out) throws Exception {
Long currentCount = countState.value();
if (currentCount == null) {
currentCount = 0L;
}
currentCount += value;
countState.update(currentCount);
out.collect(currentCount);
}
}
这个例子展示了如何使用ValueState来维护每个key的计数。
实战项目:实时用户行为分析
让我们通过一个稍微复杂一点的项目来巩固所学知识。假设我们要为一个电商平台构建实时用户行为分析系统。
项目需求
- 实时统计每个商品类别的浏览量
- 检测用户的异常行为(如短时间内多次加入购物车)
- 计算每小时的销售额

代码框架
public class UserBehaviorAnalysis {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 假设我们有一个用户行为事件流
DataStream<UserBehaviorEvent> events = env.addSource(new UserBehaviorSource());
// 1. 实时统计每个商品类别的浏览量
DataStream<Tuple2<String, Long>> categoryViews = events
.filter(event -> event.getEventType() == EventType.VIEW)
.keyBy(UserBehaviorEvent::getCategory)
.window(TumblingProcessingTimeWindows.of(Time.minutes(5)))
.sum("count");
// 2. 检测用户的异常行为
DataStream<String> suspiciousUsers = events
.keyBy(UserBehaviorEvent::getUserId)
.process(new SuspiciousBehaviorDetector());
// 3. 计算每小时的销售额
DataStream<Double> hourlySales = events
.filter(event -> event.getEventType() == EventType.PURCHASE)
.keyBy(event -> event.getTimestamp().getHour())
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.process(new HourlySalesCalculator());
// 输出结果
categoryViews.print("Category Views");
suspiciousUsers.print("Suspicious Users");
hourlySales.print("Hourly Sales");
env.execute("User Behavior Analysis");
}
}
这个项目框架涵盖了Flink的多个核心概念,包括数据流转换、窗口操作、处理函数等。

高级特性:Flink的精华所在
让我们继续深入探讨Flink的学习之路,着重关注一些更高级的主题和实际应用场景。
1. 复杂事件处理(CEP)
Flink的复杂事件处理库允许你在数据流中检测复杂的事件模式。这在欺诈检测、交易监控等场景中非常有用。

来看一个简单的例子,我们检测用户的连续登录失败:
Pattern<LogEvent, LogEvent> pattern = Pattern.<LogEvent>begin("first")
.where(new SimpleCondition<LogEvent>() {
@Override
public boolean filter(LogEvent event) {
return event.getType().equals("LOGIN_FAILED");
}
})
.next("second")
.where(new SimpleCondition<LogEvent>() {
@Override
public boolean filter(LogEvent event) {
return event.getType().equals("LOGIN_FAILED");
}
})
.within(Time.seconds(10));
PatternStream<LogEvent> patternStream = CEP.pattern(input, pattern);
DataStream<Alert> alerts = patternStream.process(
new PatternProcessFunction<LogEvent, Alert>() {
@Override
public void processMatch(Map<String, List<LogEvent>> match, Context ctx, Collector<Alert> out) {
out.collect(new Alert("Two consecutive login failures detected"));
}
});
这段代码检测10秒内的两次连续登录失败,并生成一个警报。
2. 表API和SQL
Flink的表API和SQL支持为开发人员提供了更高级的抽象,使得某些复杂的数据处理任务变得简单。

例如,我们可以使用SQL来实现earlier的用户行为分析:
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 注册表
tableEnv.createTemporaryView("user_behaviors", events);
// SQL查询
Table result = tableEnv.sqlQuery(
"SELECT category, COUNT(*) as view_count " +
"FROM user_behaviors " +
"WHERE event_type = 'VIEW' " +
"GROUP BY category, " +
" TUMBLE(event_time, INTERVAL '5' MINUTE)"
);
// 转换回DataStream
tableEnv.toRetractStream(result, Row.class).print();
这个例子展示了如何使用SQL查询来计算每5分钟的商品类别浏览量。
3. 机器学习集成

Flink还可以与机器学习框架集成,实现实时预测和模型更新。例如,我们可以使用Flink和TensorFlow结合,实现实时推荐系统:
public class RealtimeRecommender extends RichFlatMapFunction<UserAction, Recommendation> {
private transient Predictor predictor;
@Override
public void open(Configuration parameters) {
// 加载TensorFlow模型
predictor = new Predictor(getRuntimeContext().getDistributedCache().getFile("model"));
}
@Override
public void flatMap(UserAction action, Collector<Recommendation> out) {
// 使用模型进行预测
float[] features = action.toFeatures();
float[] predictions = predictor.predict(features);
// 输出推荐结果
out.collect(new Recommendation(action.getUserId(), predictions));
}
}
实战项目:实时数据湖构建
让我们通过一个更复杂的项目来巩固所学知识:构建一个实时数据湖系统。
项目需求
- 从多个来源实时接入数据
- 对数据进行实时ETL处理
- 将处理后的数据写入到Hudi表中
- 提供实时查询接口

代码框架
public class RealTimeDataLake {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 1. 从Kafka读取数据
DataStream<String> kafkaStream = env
.addSource(new FlinkKafkaConsumer<>("topic", new SimpleStringSchema(), properties));
// 2. 实时ETL处理
DataStream<Row> processedStream = kafkaStream
.map(new JsonToRowMapper())
.keyBy(row -> row.getField(0))
.process(new ETLProcessor());
// 3. 写入Hudi
HoodieStreamer<Row> streamer = HoodieFlinkStreamer
.builder()
.config(getHoodieConfig())
.source(processedStream)
.build();
streamer.scheduleCompaction();
streamer.scheduleClustering();
// 4. 提供实时查询接口
Table hudiTable = tableEnv.sqlQuery("SELECT * FROM hudi_table");
tableEnv.toRetractStream(hudiTable, Row.class).print();
env.execute("Real-time Data Lake");
}
}
这个项目涵盖了数据接入、处理、存储和查询的全流程,是一个典型的实时数据湖应用场景。

Flink 生态系统:beyond 核心 API
让我们继续深入探讨Flink的学习之路,这次我们将聚焦于一些更加高级和实用的主题。
1. Flink CDC (Change Data Capture)
Flink CDC 是一个强大的工具,用于捕获数据库的变更并将其转换为 Flink 数据流。这在构建实时数据管道时特别有用。

示例:从 MySQL 读取变更数据
public class MySqlCDCExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
SourceFunction<String> sourceFunction = MySqlSource.<String>builder()
.hostname("localhost")
.port(3306)
.databaseList("mydb")
.tableList("mydb.users")
.username("root")
.password("password")
.deserializer(new StringDebeziumDeserializationSchema())
.build();
env
.addSource(sourceFunction)
.print().setParallelism(1);
env.execute("MySQL CDC Example");
}
}
这个例子展示了如何使用 Flink CDC 从 MySQL 数据库捕获变更数据。
2. Flink ML (Machine Learning)
Flink ML 提供了在 Flink 中进行机器学习的能力。它支持训练和推理,使得在流处理中集成机器学习变得更加容易。

示例:使用 Flink ML 进行在线学习
public class OnlineLearningExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<LabeledVector> trainingData = env.addSource(new TrainingDataSource());
OnlineLogisticRegression learner = new OnlineLogisticRegression()
.setLearningRate(0.1)
.setRegularizationConstant(0.01);
DataStream<Model> model = learner.fit(trainingData);
model.print();
env.execute("Online Learning Example");
}
}
这个例子展示了如何使用 Flink ML 进行在线逻辑回归学习。
高级优化技巧
1. 背压处理

背压是流处理系统中常见的问题。理解和处理背压对于构建高性能的 Flink 应用至关重要。
public class BackpressureHandling {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置缓冲超时,有助于减少背压
env.setBufferTimeout(100);
DataStream<String> stream = env.addSource(new FastSource())
.map(new HeavyMapper())
.setParallelism(4) // 增加并行度来处理背压
.filter(new BackpressureFilter());
stream.print();
env.execute("Backpressure Handling Example");
}
static class BackpressureFilter implements FilterFunction<String> {
@Override
public boolean filter(String value) throws Exception {
// 模拟一个耗时的操作
Thread.sleep(100);
return true;
}
}
}
这个例子展示了几种处理背压的方法,包括设置缓冲超时和增加并行度。
2. 状态优化
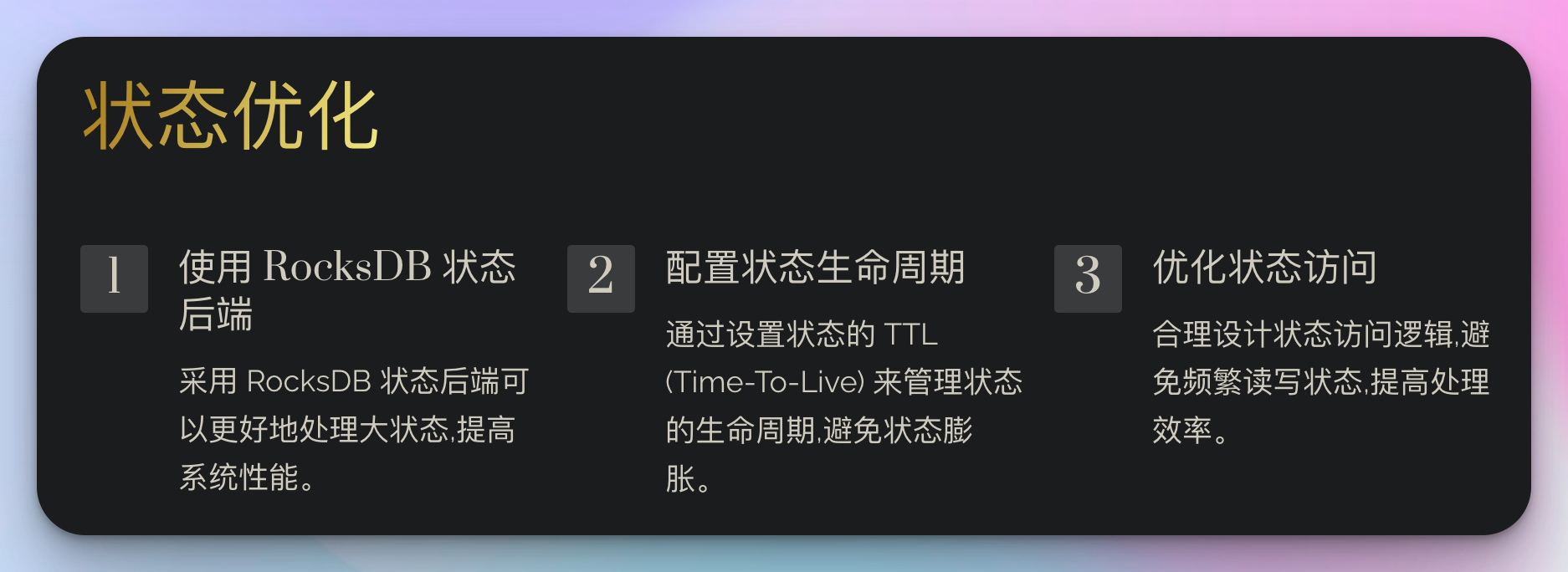
对于有状态的操作,正确管理状态大小对于性能至关重要。
public class StateOptimizationExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 使用 RocksDB 状态后端来处理大状态
env.setStateBackend(new EmbeddedRocksDBStateBackend());
DataStream<Tuple2<String, Integer>> stream = env.addSource(new DataSource())
.keyBy(t -> t.f0)
.process(new StatefulProcessor());
stream.print();
env.execute("State Optimization Example");
}
static class StatefulProcessor extends KeyedProcessFunction<String, Tuple2<String, Integer>, Tuple2<String, Integer>> {
private ValueState<Integer> state;
@Override
public void open(Configuration parameters) {
// 使用 TTL 来管理状态生命周期
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.hours(1))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();
ValueStateDescriptor<Integer> descriptor = new ValueStateDescriptor<>("myState", Integer.class);
descriptor.enableTimeToLive(ttlConfig);
state = getRuntimeContext().getState(descriptor);
}
@Override
public void processElement(Tuple2<String, Integer> value, Context ctx, Collector<Tuple2<String, Integer>> out) throws Exception {
Integer current = state.value();
if (current == null) {
current = 0;
}
current += value.f1;
state.update(current);
out.collect(new Tuple2<>(value.f0, current));
}
}
}
这个例子展示了如何使用 RocksDB 状态后端和 TTL 配置来优化状态管理。
实战项目:实时异常检测系统
让我们通过一个更加复杂的项目来综合运用我们所学的知识:构建一个实时异常检测系统。
项目需求
- 从多个数据源实时接入日志数据
- 使用 Flink CEP 检测复杂的异常模式
- 利用 Flink ML 进行异常评分
- 将检测结果实时写入到 Kafka 和 Elasticsearch
代码框架
public class RealTimeAnomalyDetection {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 1. 数据接入
DataStream<LogEvent> logStream = env
.addSource(new FlinkKafkaConsumer<>("logs", new LogEventDeserializationSchema(), properties));
// 2. CEP 异常模式检测
Pattern<LogEvent, LogEvent> pattern = Pattern.<LogEvent>begin("start")
.where(new SimpleCondition<LogEvent>() {
@Override
public boolean filter(LogEvent event) {
return event.getSeverity().equals("ERROR");
}
})
.next("middle")
.where(new SimpleCondition<LogEvent>() {
@Override
public boolean filter(LogEvent event) {
return event.getSeverity().equals("ERROR");
}
})
.within(Time.seconds(10));
PatternStream<LogEvent> patternStream = CEP.pattern(logStream, pattern);
DataStream<AnomalyEvent> anomalies = patternStream.process(
new PatternProcessFunction<LogEvent, AnomalyEvent>() {
@Override
public void processMatch(Map<String, List<LogEvent>> match, Context ctx, Collector<AnomalyEvent> out) {
out.collect(new AnomalyEvent(match));
}
});
// 3. 机器学习评分
OnlineLogisticRegression model = new OnlineLogisticRegression()
.setLearningRate(0.1)
.setRegularizationConstant(0.01);
DataStream<ScoredAnomalyEvent> scoredAnomalies = model.transform(anomalies);
// 4. 结果输出
FlinkKafkaProducer<ScoredAnomalyEvent> kafkaProducer = new FlinkKafkaProducer<>(
"anomalies",
new AnomalyEventSerializationSchema(),
properties,
FlinkKafkaProducer.Semantic.EXACTLY_ONCE
);
ElasticsearchSink.Builder<ScoredAnomalyEvent> esSinkBuilder = new ElasticsearchSink.Builder<>(
httpHosts,
new ElasticsearchSinkFunction<ScoredAnomalyEvent>() {
@Override
public void process(ScoredAnomalyEvent element, RuntimeContext ctx, RequestIndexer indexer) {
indexer.add(createIndexRequest(element));
}
}
);
scoredAnomalies
.addSink(kafkaProducer)
.name("Kafka Sink");
scoredAnomalies
.addSink(esSinkBuilder.build())
.name("Elasticsearch Sink");
env.execute("Real-time Anomaly Detection");
}
}
这个项目综合了我们之前讨论的多个高级特性,包括 CEP、机器学习、多种 Sink 等。
结语
通过这个系列的探讨,我们从 Flink 的基础概念,一直深入到了高级特性和实战项目。记住,成为一个优秀的 Flink 开发者是一个持续学习和实践的过程。
"糙快猛"的学习方式让我们能够快速上手,但真正的掌握需要不断的思考和实践。。
最后,我想用一句话来总结我们的 Flink 学习之旅:
“在数据的海洋中,Flink 是你的航船。熟悉它,运用它,你将能够驾驭任何数据的风浪。”
祝你在 Flink 的学习之路上一帆风顺,早日成为独当一面的大数据工程师!加油!
















 765
765











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











