







目录
🛠️ 爬虫程序之一:爬取图片(批量下载图片)
这是一个Python编写的爬虫入门程序,用于从图片网站爬取目标类别(例如:"美女"、"火焰"、"烟雾")的图片,并自动生成对应的标签文件。
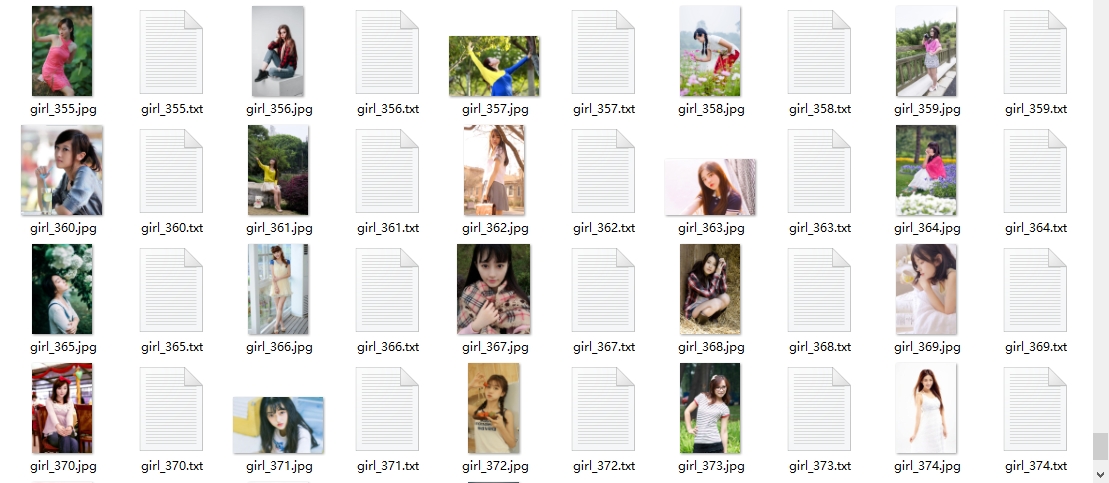
爬取结果部分展示:pqmn.png (1109×483)
🎯 1. 功能特性
- 使用Selenium模拟浏览器滚动加载更多图片
- 通过BeautifulSoup解析网页内容
- 自动创建保存目录
- 下载图片并保存,文件名自动有序编号
- 为每张图片生成对应的标签文件(YOLO格式)
📁 2. 项目结构
CrawlImages/
├── README.md
├── crawlGirls.py
├── crawlFire.py
├── crawlSmoke.py
├── chromedriver/
│ ├── chromedriver.exe
│ ├── LICENSE.chromedriver
│ └── THIRD_PARTY_NOTICES.chromedriver
├── girl_images/
│ ├── girl_0.jpg
│ ├── girl_0.txt
│ ├── girl_1.jpg
│ ├── girl_1.txt
│ ├── girl_2.jpg
│ ├── girl_2.txt
│ ├── girl_3.jpg
│ ├── girl_3.txt
│ ...
├── fire_images/
│ ├── fire_0.jpg
│ ├── fire_0.txt
│ ├── fire_1.jpg
│ ├── fire_1.txt
│ ...
└── smoke_images/
⚙️ 3. 环境要求
- Python 3.x
- 所需库:
```bash
pip install requests beautifulsoup4 selenium
🚀 4. 快速开始
- 确保已安装Chrome浏览器
- 下载对应版本的ChromeDriver并放在./chromedriver/目录下
已提供版本为v134.0.6998.90
- 运行爬虫:
```bash
python crawlGirls.py
⚠️ 5. 注意事项
- 本项目仅供学习交流使用
- 不要频繁请求,以免被封IP
🔍 源码下载
《爬虫程序之一:爬取图片》源码下载
下一篇:《爬虫程序之二:爬取音频🎵下载MP3》https://blog.csdn.net/u012958854/article/details/147573394

















 1231
1231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}