









首先我们来了解一下“指标”(metrics)的概念,简单讲一个指标就是一个需要收集的数据项,
但是只有指标是不能全面地描述出一条数据产生的相关背景信息的,比如:如果我们要统计cpu的使用率,我们可以建立一下名为proc.stat.cpu 的 metrics,
如果我们从不同的机器和用户下收集了大量的cpu信息,如果没有对一条信息进行一定地标识,我们是无法区分出哪些数据来自哪台机器的哪个用户,所以我们还需要
建立一些“标签”(Tag)来标识一条数据。严格地说,指标和标签之间并没有必然的从属关系,就像两个不同的指标的数据可能都有指示其来自哪台主机的host标签一样,
但是有一点是确定的,即:对于一条数据来说,应该至少含有一个指标和一个标签,这样的数据才是有意义的,因此,在OpenTSDB的表设计上,就把“指标”(metrics)
和“标签”(Tag)统一放在了tsdb-uid表中存储,
格式为:RowKey(自增ID,3字节数组):name:metrics,name:tagk,name:tagv,同时对它们之间的反向关联关系也作了展开存储。
一个单独的较小的表叫做tsdb-uid用来存储UID映射,包括正向的和反向的。存在两列族,
一列族叫做name用来将一个UID映射到一个字符串,
另一个列族叫做id,用来将字符串映射到UID。
列族的每一行都至少有以下三列中的一个:
metrics 将metric的名称映射到UID
tagk 将tag名称映射到UID
tagv 将tag的值映射到UID
下图是存储的数据样例:
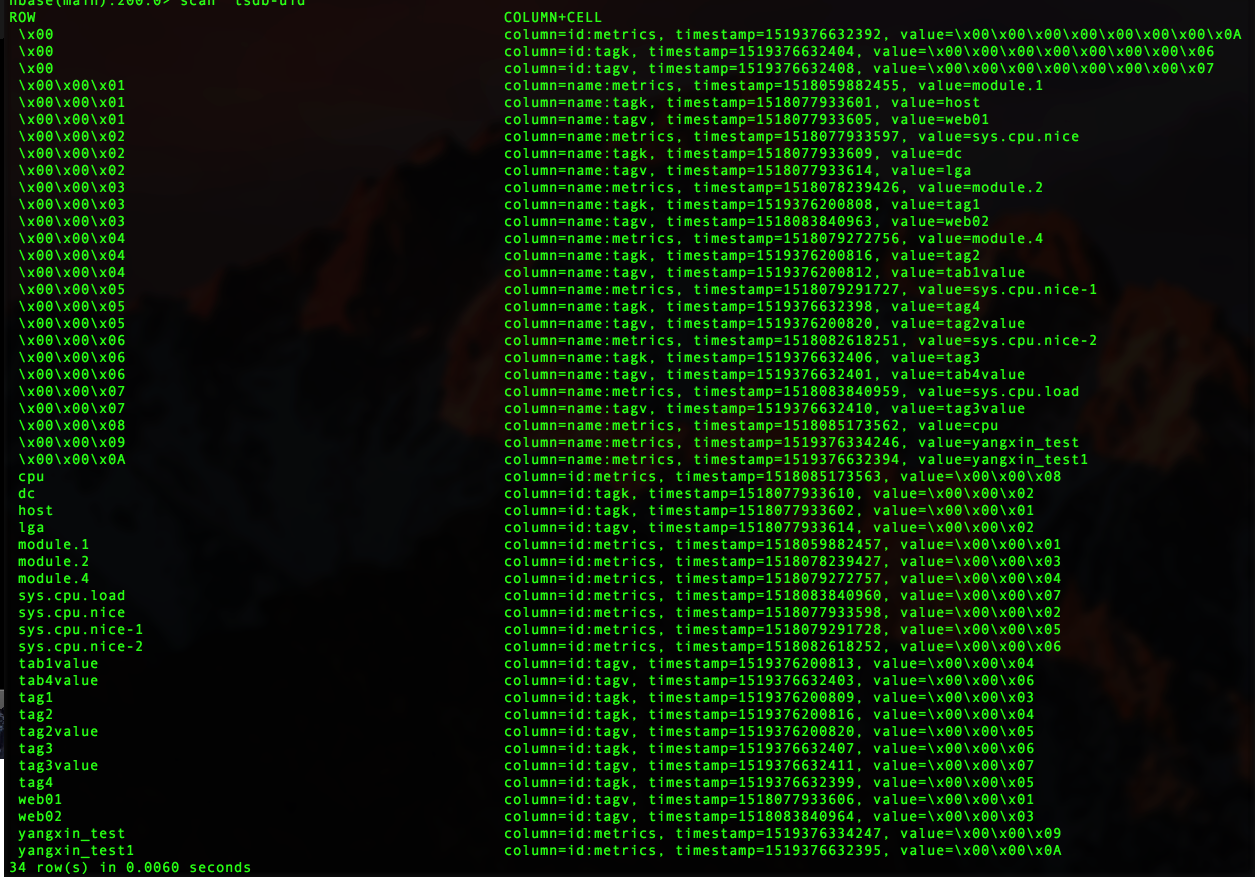
第一条记录:rowkey为\x00,含3个字段:metrics, tagk, tagv,
其值分别是已经添加的
metric 所有指标的数量
tagk 标签名的数量
tagv 标签值的数量
这一条数据是系统生成和维护的。这里有多个metric, tagk, tagv,
所以 rowkey为\x00的三个数据
mertics 是 10个
tagk 是 6个
tagv是7个
在OpenTSDB中,每一个metric、tagk或者tagv在创建的时候被分配一个唯一标识叫做UID,
它们组合在一起可以创建一个序列的UID或者TSUID。在OpenTSDB的存储中,对于每一个metric、tagk或者tagv都存在从0开始的计数器,
每来一个新的metric、tagk或者tagv,对应的计数器就会加1。
当data point写到TSD时,UID是自动分配的。你也可以手动分配UID,前提是auto metric被设置为true。
















 2253
2253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











