









如下图是tsdb的数据:
hbase(main):003:0> scan 'tsdb' ROW COLUMN+CELL \x00\x00\x01U\x9C\xAEP\x00\x column=t:q\x80,timestamp=1436350142588, value=\x17 00\x01\x00\x00\x01\x00\x00\x 02\x00\x00\x02 1 row(s) in 0.2800 seconds
可以看出,该表只有一条数据,我们先不管rowid,只来看看列,只有一列,值为0x17,即十进制23,即该metric的值。
左面的row key则是 OpenTSDB 的特点之一,其规则为:
metric + timestamp + tagk1 + tagv1… + tagkN + tagvN以上属性值均为对应名称的uid。
我们上面添加的metric为:
sys.cpu.user 1436333416 23 host=web01 user=10001
一共涉及到5个uid,即名为sys.cpu.user的metric,以及host和user两个tagk及其值web01和10001。
上面数据的row key为:
\x00\x00\x01U\x9C\xAEP\x00\x00\x01\x00\x00\x01\x00\x00\x02\x00\x00\x02
具体这个row key是怎么算出来的,我们来看看tsdb-uid表。
tsdb-uid:存储name 和 uid的映射关系
下面tsdb-uid表的数据,各行之间人为加了空行,为方便显示。
tsdb-uid 用来保存 名字 和 UID(metric,tagk,tagv)之间互相映射的关系,
都是成组出现的,即给定一个 name 和 uid,会保存(name, uid)和(uid, name)两条记录。
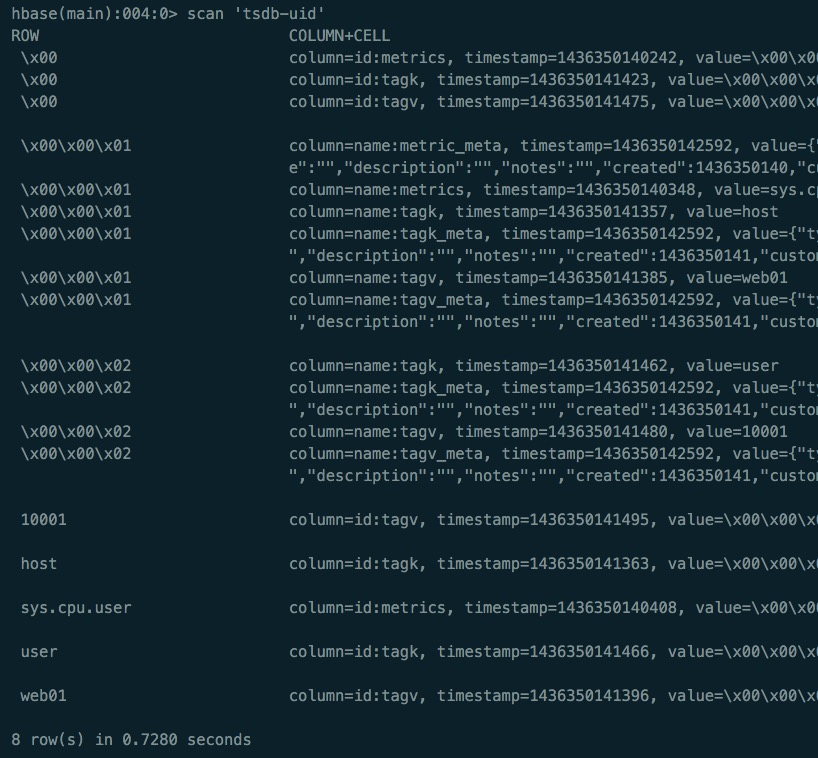
我们一共看到了8行数据。
前面我们在tsdb表中已经看到,metric数据的row key为
\x00\x00\x01U\x9C\xAEP\x00\x00\x01\x00\x00\x01\x00\x00\x02\x00\x00\x02,我们将其分解下,
用+号连起来(从name到uid的映射为最后5行):
\x00\x00\x01 + U + \x9C\xAE + P + \x00\x00\x01 + \x00\x00\x01 + \x00\x00\x02 + \x00\x00\x02
sys.cpu.user 1436333416 host = web01 user = 10001
可以看出,这和我们前面说到的row key的构成方式是吻合的。
反过来,从 uid 到 name 也一样,比如找 uid 为 \x00\x00\x02 的 tagk,
我们从上面结果可以看到,该rowkey(\x00\x00\x02)有4列,而column=name:tagk的value就是user,非常简单直观。
重要:我们看到,上面的metric也好,tagk或者tagv也好,uid只有3个字节,这是 OpenTSDB 的默认配置,
三个字节,应该能表示1600多万的不同数据,这对metric名或者tagk来说足够长了,对tagv来说就不一定了,
比如tagv是ip地址的话,或者电话号码,那么这个字段就不够长了,这时可以通过修改源代码来重新编译
OpenTSDB 就可以了,同时要注意的是,重编以后,老数据就不能直接使用了,需要导出后重新导入。
















 6708
6708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











