







Java Servlet 中文乱码详解
在进行Java web开发时,常常会遇到中文乱码问题,特地总结一下产生乱码的原因和解决方法。
URL地址中文乱码
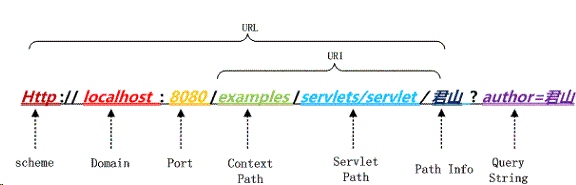
一个完整的URL地址如图所示。
通常中文字符出现在URI或者QueryString部分,由于Tomcat服务器对URI和QueryString是分别解析的,所以下面分别介绍。
当URL地址中包含中文字符时,分两种情况,一是经过URL编码的,如“中文”二字经URL编码成为%E4%B8%AD%E6%96%87,二是未经URL编码的,如通过超链接或者sendRedirect()方法转向的另一个页面,其URL地址中包含明文中文。
URI中含有中文
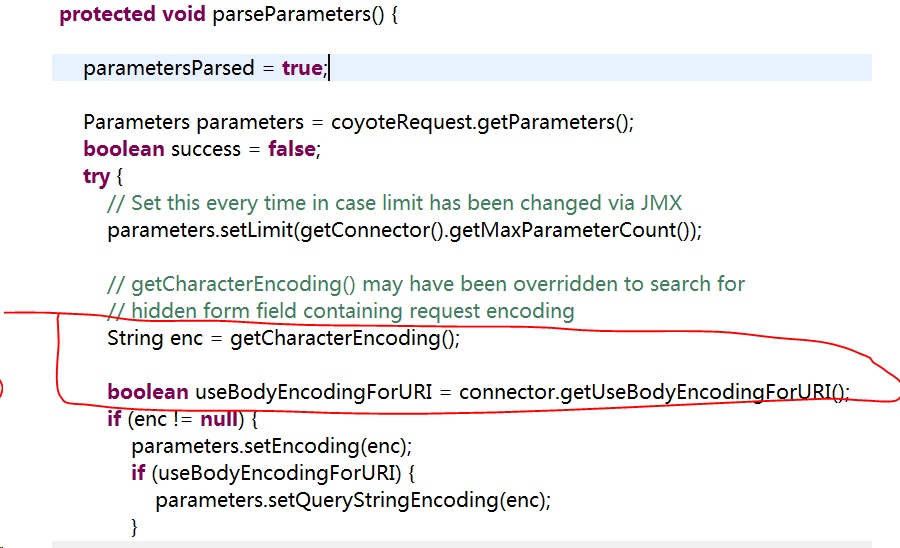
我们以Tomcat服务器为例,该服务器默认以ISO-8859-1编码来解析URL地址,所以当URL地址的中文被服务器解析时会发生乱码。通过查看Tomcat源码可以知道,解析请求的 URL 是在 org.apache.coyote.HTTP11.InternalInputBuffer 的 parseRequestLine 方法中,这个方法把传过来的 URL 的 byte[] 设置到 org.apache.coyote.Request 的相应的属性中。这里的 URL 仍然是 byte 格式,转成 char 是在 org.apache.catalina.connector.CoyoteAdapter 的 convertURI 方法中完成的:
protected void convertURI(MessageBytes uri, Request request) throws Exception {
ByteChunk bc = uri.getByteChunk();
int length = bc.getLength();
CharChunk cc = uri.getCharChunk();
cc.allocate(length, -1);
String enc = connector.getURIEncoding();
if (enc != null) {
B2CConverter conv = request.getURIConverter();
try {
if (conv == null) {
conv = new B2CConverter(enc);
request.setURIConverter(conv);
}
} catch (IOException e) {...}
if (conv != null) {
try {
conv.convert(bc, cc, cc.getBuffer().length -
cc.getEnd());
uri.setChars(cc.getBuffer(), cc.getStart(),
cc.getLength());
return;
} catch (IOException e) {...}
}
}
// Default encoding: fast conversion
byte[] bbuf = bc.getBuffer();
char[] cbuf = cc.getBuffer();
int start = bc.getStart();
for (int i = 0; i < length; i++) {
cbuf[i] = (char) (bbuf[i + start] & 0xff);
}
uri.setChars(cbuf, 0, length);
}从上面的代码中可以知道对 URL 的 URI 部分进行解码的字符集是在 Connector 的 <Connector URIEncoding=”UTF-8”/> 属性中定义的,如果没有定义,那么将以默认编码 ISO-8859-1 解析。
因此,当URI含有中文时,可以通过设置URIEncoding属性解决乱码问题。
QueryString中含有中文
通过查看源码可知,GET 方式 HTTP 请求的 QueryString 与 POST 方式 HTTP 请求的表单参数都是作为 Parameters 保存,都是通过 request.getParameter 获取参数值。对它们的解码是在 request.getParameter 方法第一次被调用时进行的。
而request.getParameter方法又调用了org.apache.catalina.connector.Request 的 parseParameters 方法,如图所示:
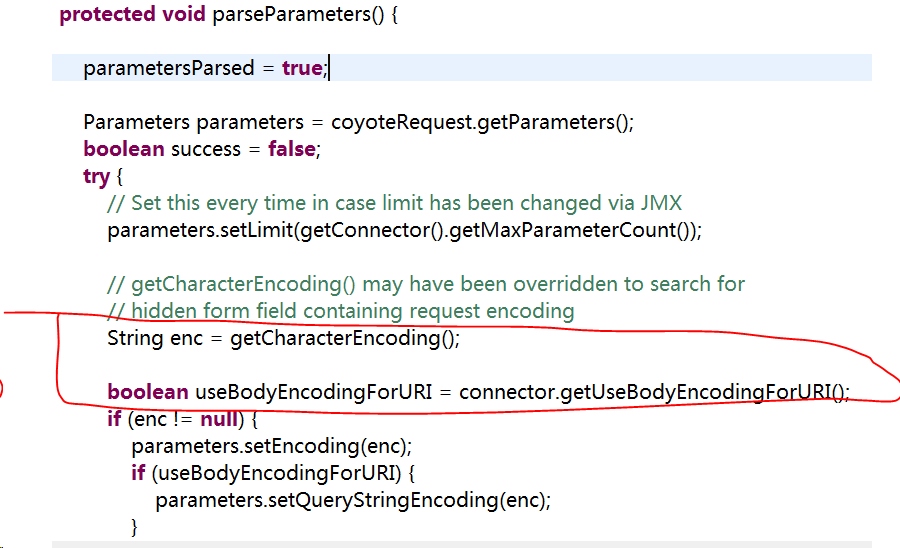
注意到红线圈起的语句,getCharacterEncoding()方法返回Parameters的编码格式。我们进入这个方法:

可以看到,编码格式保存在charEncoding变量中,如果该变量为空,则从ContentType中读取charset值进行设置。
我们知道,Request有一个方法request.setCharacterEncoding(“编码格式”),如图所示,该方法就是设置charEncoding的值。

所以,对于QueryString中含有中文的情况,可以通过request.setCharacterEncoding方法改变默认的编码格式。
另一方面,如果没有定义charEncoding,则从ContentType中读取charset值进行设置,还要设置 Connector 节点中的useBodyEncodingForURI 设置为 true。这时,服务器会根据请求header的charset属性进行解码,从而解决了用get方式传输表单的中文误码问题。
useBodyEncodingForURI这个配置项的名字有点让人产生混淆,它并不是对整个 URI 都采用 BodyEncoding 进行解码而仅仅是对 QueryString 使用 BodyEncoding 解码,这一点还要特别注意。
值得注意的是,很多情况下如通过超链接传中文参数给另一个Servlet,此时Header里面是没有charset属性的,所以以默认编码解析时会发生乱码。解决这种问题,只能使用request.setCharacterEncoding来设定接收时的编码格式。
综上所述,由于Tomcat服务器对URI和QueryString分别解析,所以出现乱码的原因有很多,在实际开发中尽量避免用中文。解决措施有:
1.调用request.setCharacterEncoding()方法
2.在connector 中设置 URIEncoding=”UTF-8”和 useBodyEncodingForURI=”true”,同时要保证请求的Header中包含charset属性
URL编码
中文的乱码问题本质上是编码和解码的不一致导致的,因此一种更加方便简单的方法是把中文再经过URL编码,变成纯Ascii码在网络中传播,然后接收时再经过URL解码恢复中文。
即调用URLEncoder.encode(params,”utf-8”)进行编码,调用URLDecoder.decode(params,”utf-8”)进行解码。其中第一个参数是中文的字符,第二个参数是使用的编码格式。
HTTP Header 的编解码
当客户端发起一个 HTTP 请求除了上面的 URL 外还可能会在 Header 中传递其它参数如 Cookie、redirectPath 等,这些用户设置的值很可能也会存在编码问题,Tomcat 对它们又是怎么解码的呢?
对 Header 中的项进行解码也是在调用 request.getHeader 是进行的,如果请求的 Header 项没有解码则调用 MessageBytes 的 toString 方法,这个方法将从 byte 到 char 的转化使用的默认编码也是 ISO-8859-1,而我们也不能设置 Header 的其它解码格式,所以如果你设置 Header 中有非 ASCII 字符解码肯定会有乱码。
我们在添加 Header 时也是同样的道理,不要在 Header 中传递非 ASCII 字符,如果一定要传递的话,我们可以先将这些字符用 org.apache.catalina.util.URLEncoder 编码然后再添加到 Header 中,这样在浏览器到服务器的传递过程中就不会丢失信息了,如果我们要访问这些项时再按照相应的字符集解码就好了。
特别注意,当调用sendRedirect()方法时,实际上是调用了setHeader方法设置了Location属性,所以此时的路径中不能出现中文,否则Tomcat服务器会以默认编码来解析,从而发生误码。如果一定要用中文,则要经过URL编码。
一个不推荐的解决乱码方法
由于大部分的乱码是由服务器以默认ISO-8859-1格式解析造成的,所以在我们通过 request.getParameter 获取参数值时,当我们直接调用
String value = request.getParameter(name);会出现乱码,但是如果用下面的方式
String value = new String(request.getParameter(name).getBytes("ISO-8859-1"),"utf-8");解析时取得的 value 会是正确的汉字字符。这是因为先把ISO-8859-1编码后的乱码重新变回字节流,再通过utf-8解码得到的正确字符。然而这种方法并不推荐,因为服务器先进行了一次错误的译码,影响性能。















 4592
4592











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









