







代码地址:
https://code.csdn.net/u012995856/javacrawler/tree/master
效果:

新闻:

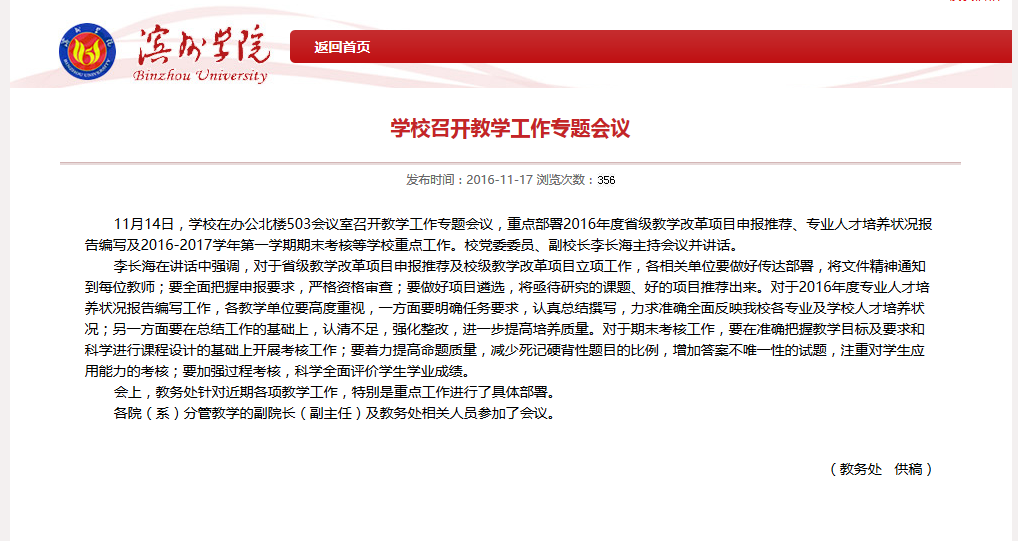
pdf:

这里还没有做处理分页。
使用WebCollector爬虫框架,iText7输出PDF
其实爬虫没什么神秘的,只是要自己分析网页,写正则表达式匹配url.然后让其他大牛写好的爬虫按照你的规则去分析抓取网页页面.
1.选取自己要抓取的页面
滨州学院新闻主页
http://www.bzu.edu.cn/s/1/t/84/p/12/i/194/list.htm2.分析要抓取的页面的URL有什么规律
这是部分链接
http://www.bzu.edu.cn/s/1/t/84/bf/49/info48969.htm
http://www.bzu.edu.cn/s/1/t/84/bf/4e/info48974.htm
http://www.bzu.edu.cn/s/1/t/84/bd/ba/info48570.htm
...差不多都是一个样式的,这里写一个正则表达式来匹配这种链接
http://www.bzu.edu.cn/\\w/\\d/\\w/\\d+/\\w+/\\w+/.*htm这样这个正则表达式就能匹配新闻页面所有链接了
3.分析单个新闻页面,找到标题和内容
在单个新闻页面右键查看源代码
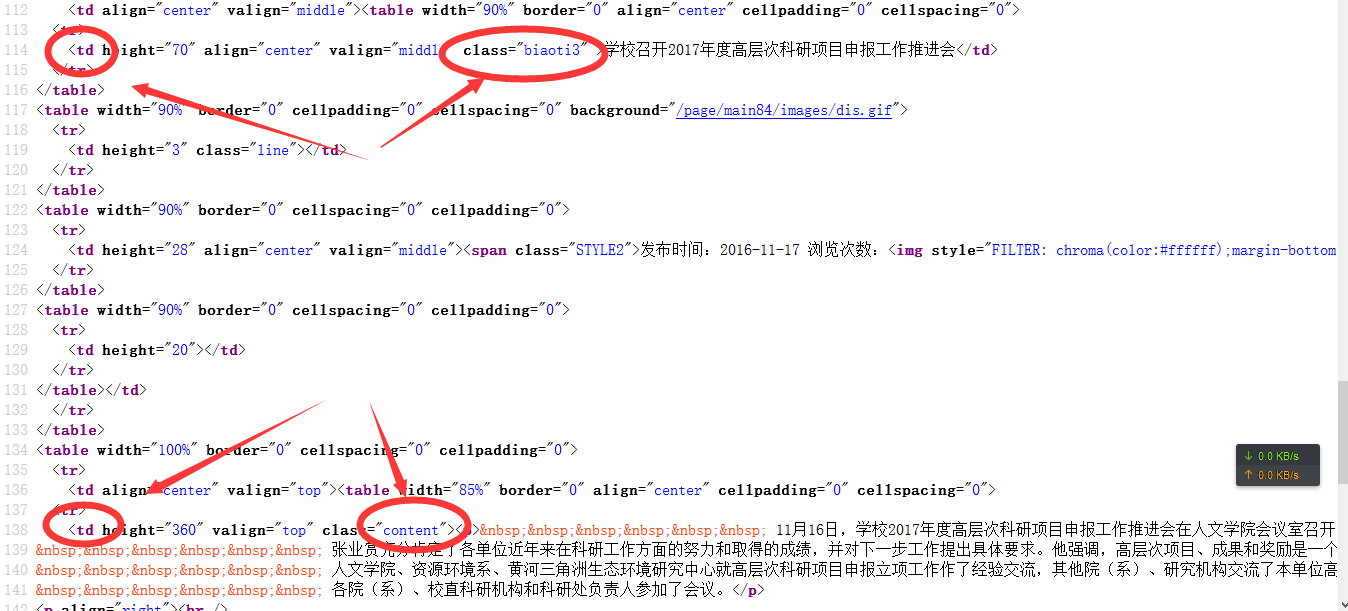
根据WebController的规则
就可以写
//页面标题
String title = page.select("td[class=biaoti3]").text();
//页面主题内容
String content = page.select("td[class=content]").text();4.代码
BZUNews.java
package com.huijiasoft.pangPython.test;
import java.io.FileNotFoundException;
import cn.edu.hfut.dmic.webcollector.model.CrawlDatums;
import cn.edu.hfut.dmic.webcollector.model.Page;
import cn.edu.hfut.dmic.webcollector.plugin.berkeley.BreadthCrawler;
/**
* @author pangPython
* 抓取滨州学院新闻导出pdf
*/
public class BZUNews extends BreadthCrawler{
public BZUNews(String crawlPath, boolean autoParse) {
super(crawlPath, autoParse);
//设置开始爬取的页面
this.addSeed("http://www.bzu.edu.cn/s/1/t/84/p/12/i/194/list.htm");
//设置爬取规则 使用正则表达式
this.addRegex("http://www.bzu.edu.cn/\\w/\\d/\\w/\\d+/\\w+/\\w+/.*htm");
this.addRegex("http://www.bzu.edu.cn/\\w/\\d/\\w/\\d+/\\w/\\d+/\\w/\\d+/.*htm");
/*不要爬取 jpg|png|gif*/
this.addRegex("-.*\\.(jpg|png|gif).*");
}
@Override
public void visit(Page page, CrawlDatums arg1) {
//页面地址
String url = page.getUrl();
//页面标题
String title = page.select("td[class=biaoti3]").text();
//页面主题内容
String content = page.select("td[class=content]").text();
//输出到pdf中
try {
CreatePDF.createPdf(title, content);
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public static void main(String[] args) throws Exception {
BZUNews bzunews = new BZUNews("bzunews", true);
//多线程
bzunews.setThreads(50);
//设置每次迭代中爬取数量的上限
bzunews.setTopN(5000);
//开始爬取
bzunews.start(4);
}
}
CreatePDF.java
package com.huijiasoft.pangPython.test;
import java.io.FileNotFoundException;
import java.io.IOException;
import com.itextpdf.io.font.PdfEncodings;
import com.itextpdf.kernel.font.PdfFont;
import com.itextpdf.kernel.font.PdfFontFactory;
import com.itextpdf.kernel.pdf.PdfDocument;
import com.itextpdf.kernel.pdf.PdfWriter;
import com.itextpdf.layout.Document;
import com.itextpdf.layout.element.Paragraph;
/**
* @author pangPython
* 用于生成PDF
*
* 处理中文问题
*/
public class CreatePDF {
public static void createPdf(String title,String content) throws FileNotFoundException{
// String file_name = Math.random()+"1.pdf";
String file_name = title+"1.pdf";
PdfFont font =null;
//处理中文问题
try {
// font = PdfFontFactory.createFont("MSung-Light", "UniGB-UCS2-H", false);
font = PdfFontFactory.createFont("C:\\Windows\\Fonts\\STKAITI.TTF", PdfEncodings.IDENTITY_H, true);
} catch (IOException e) {
e.printStackTrace();
}
PdfWriter writer = new PdfWriter(file_name);
PdfDocument pdf = new PdfDocument(writer);
Document document = new Document(pdf);
Paragraph p1 = new Paragraph(title);
Paragraph p2 = new Paragraph(content);
p1.setFont(font);
p2.setFont(font);
document.add(p1);
document.add(p2);
document.close();
}
}















 2024
2024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









