






RAID(独立硬盘冗余阵列)
RAID中的两个概念:
条带(strip):硬盘中单个或者多个连续的扇区构成一个条带,他是一块硬盘上进一次数据读写的最小单元。 它是组成分条的元素。
分条(stipe):同一硬盘阵列中的多个硬盘驱动器上的相同“位置”(或者说是相同编号)的条带。
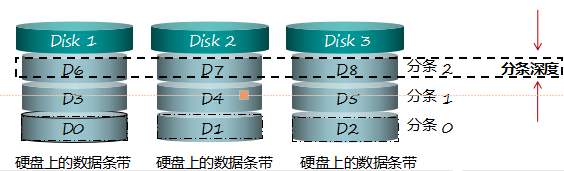
注意:组成RAID的所有盘的各种参数都需要一样,包括盘的转速,大小,分条,和条带深度。
RAID中使用的数据保护方式:
一,镜像:在另外一个盘中将数据备份起来。
二,保存校验值:使用RAID中的盘来保存一个校验值,在出现问题的时候,使用校验值来将数据恢复(通常使用XOR(异或运算))。
RAID0:简单的使用几个盘构成一个RAID,不提供数据保护,不提供数据保护也就是但任何一个盘损坏之后,数据是没法恢复的。
RAID示意图:
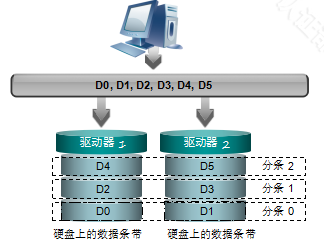
由于RAID的数据支持并行读取和写入(D0和D1同时写入和读取,完了之后,D2和D3同时写入和读取)所以RAID 0的数据读取和写入速度理论上来说是单个盘的N倍,N指的是构成RAID的盘的数目。
RAID1:
定义:RAID1:用一个盘用来存储数据的时候,同时将数据做一个镜像,备份保存在另一个盘中,组成一个RAID1最少需要2块盘。
数据保护:RAID通过使用两块相同的磁盘同时保存相同的数据,来做数据保护。当一块盘失效的时候,可以通过另一块盘来读取数据。
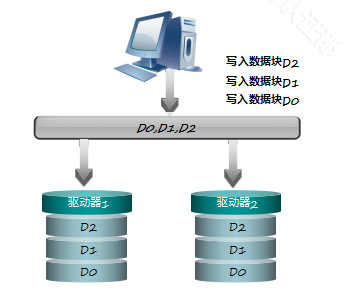
RQID1的写入:RAID1写入数据的时候,同时将数据写入备份中,它的写速率和单块硬盘写速率相同。
RAID1的读取:RAID1数据读取的时候,可以两个盘同时使用,所以它的读取速度是两块硬盘的性能之和。
数据恢复:当一块盘失效的时候,使用一块新的盘来将坏盘替换,并从硬盘二复制数据到新硬盘。
RAID3:
定义:RAID 3与RAID 0类似,不同之处在于RAID 3带有专用的奇偶校验的分条。在RAID 3中,一块专用硬盘(校验盘)用来保存同一分条上其他硬盘上的相应的条带中的数据的奇偶校验值。如果检测到不正确的数据或硬盘出现故障,我们可以利用奇偶校验信息来恢复故障硬盘上的数据。RAID 3适用于数据密集型或单用户环境,需要长期、连续访问的数据块。RAID 3将数据写入操作分配给RAID组内的数据成员盘。但是,当有新数据需要写入时,无论写入哪个硬盘,RAID 3都需要重新计算并重写校验信息。因此,当某个应用程序需要大量写入时,RAID 3的奇偶校验盘将有很大的工作量。因为需要等待奇偶校验,所以会对RAID 3组的读写性能有一定影响。此外,因为校验盘有较高的工作负载,它往往是RAID 3里最容易失效的硬盘。这就是为什么校验盘被称为RAID 3的瓶颈的原因。
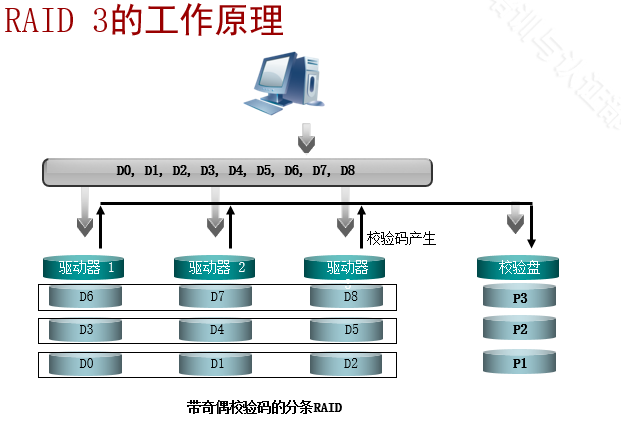
数据保护:通过计算一个奇偶校验值单独保存的方法来做数据保护。
数据写入:
(1)RAID 3采用单硬盘容错和并行数据传输。换句话说,RAID 3采用分条技术将数据分块,这些块进行异或算法,并将奇偶校验数据写到最后一个盘——RAID 3组的奇偶校验硬盘。当硬盘出现故障时,数据被写入到那些没有故障的硬盘上,奇偶校验继续。
(2)RAID 3采用单硬盘容错和并行数据传输。换句话说,RAID 3采用分条技术将数据分块,这些块进行异或算法,并将奇偶校验数据写到最后一个盘——RAID 3组的奇偶校验硬盘。当硬盘出现故障时,数据被写入到那些没有故障的硬盘上,奇偶校验继续。
(3)RAID 3的写入性能取决于更改数据的数量、硬盘的数目、以及计算和存储奇偶校验信息所需的时间。假定一个RAID 3的硬盘数为N,当所有成员盘的转速相同时,在不考虑写惩罚,满分条写的情况下,RAID 3的顺序IO写性能理论上略小于 N-1倍单个硬盘的性能(计算冗余校验需要额外的计算时间)。
数据读取:在RAID 3中,数据以分条的方式进行读取。RAID中的每个硬盘的硬盘驱动器被控制,所以RAID 3里同一条带上的数据块可以并行读取。所以,RAID 3的每一个硬盘被充分利用,提升了读取性能。
RAID 3使用并行数据读(写)模式。
RAID 3的读取性能取决于读取的数据量和RAID 3阵列的硬盘数量。
数据恢复:
(1)对于数据恢复,RAID 3通过对数据硬盘和奇偶校验硬盘进行异或运算来恢复故障硬盘上丢失的数据。
(2)如图所示,当硬盘2失败,数据块A1,B1,C1丢失。恢复这些数据块,首先要恢复A1,可以对硬盘1的A0、硬盘3上的A2、校验硬盘上的P1运用异或操作得到A1。B1和C1也用同样的方法恢复。在结束时,所有丢失的数据在硬盘2上恢复。
(3)在数据恢复过程中,由于所有操作在一个单独的硬盘上运行,给数据恢复硬盘上造成沉重的压力,同时降低了RAID的性能。
RAID5:
原理:RAID 5是改进版的RAID 3,使用条带化并计算奇偶校验信息。在RAID 3中有一块专用硬盘负责奇偶校验数据的写入和读取,这导致了我们前面提到的性能瓶颈问题。RAID 5使用的是分布式奇偶校验,每个成员硬盘将用于存储用户数据和奇偶校验数据。所以RAID 5没有瓶颈或热点。
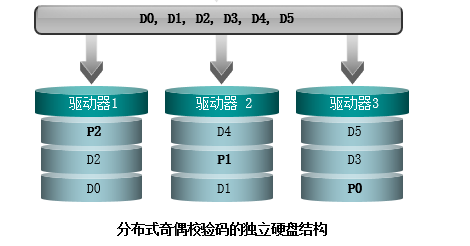
数据保护:RAID5和RAID3使用的都是计算校验值的方式来保护数据。当有一个盘失效的时候,可以使用其他的盘,通过计算来将数据恢复出来。
数据读取:RAID 5组的读取性能取决于所写的数据量和RAID组中的硬盘数量。
数据写入:
(1)在RAID 5中,数据以分条的形式写入硬盘组中。硬盘组中的每个硬盘都存储数据块和校验信息,数据块写一个分条时,奇偶信息被写入相应的校验硬盘。在RAID 5进行连续写入的时候,不同分条用来存储奇偶校验的硬盘是不同的。因此RAID 5的不同分条的奇偶校验数据不是单独存在一个固定的校验盘里的,而是按一定规律分散存放的。
(2) RAID 3在少量的数据被写入时有写惩罚,RAID 5类似。
(3)RAID 5的写入性能取决于所写的数据量和RAID 5组中硬盘的数量。假定一个RAID 5的硬盘数为N,当所有成员盘的转速相同时,在不考虑写惩罚,满分条写的情况下,RAID 5的顺序IO写性能理论上略小于 N-1倍单个硬盘的性能(计算冗余校验需要额外的计算时间)。
数据恢复:
RAID5中的任何其中一个盘损坏的时候,都可以使用其他的盘来通过计算校验值的方式来还原数据。RAID5虽然和RAID3使用的都是计算校验值的方式来恢复数据,但是RAID5相对于RAID3来说,它将数据校验信息保存到不同的盘里面,避免了单个盘的压力。
RAID6:
原理:
(1)RAID 6采用P+Q校验时,P和Q是2个彼此独立的校验值。它们使用不同的算法,用户数据和校验数据分布在同一分条的所有硬盘上。
(2)P是用户数据块的简单的异或运算得到的。Q是对用户数据进行GF(GF =伽罗瓦域)变换再异或运算得到,α,β和γ为常量系统,由此产生的值是一个所谓的“芦苇码”。该算法将数据硬盘相同分条的所有数据进行转换和异或运算。
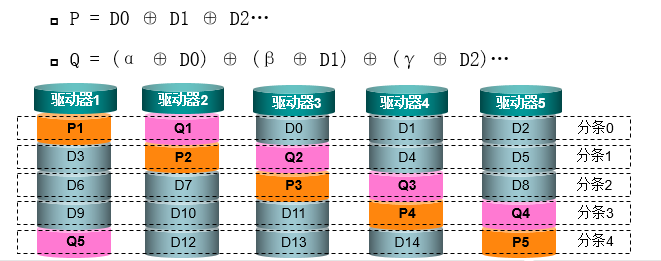
(3)如图所示,P1是通过对D0,D1,D2所在的分条0进行异或操作获得的,P2是对D3,D4,D5所在的分条1异或操作实现的,P3则是对D6,D7,D8 所在的分条2条进行异或操作。
(4)Q1是对D0,D1,D2 所在的分条0条进行GF变换再异或操作实现的,Q2是对D3,D4,D5 所在的分条1进行GF变换再异或运算, Q3实现对D6,D7,D8分条2进行GF变换再异或。
(5)如果一个硬盘中的一个分条失效,只需有P校验值即可恢复失效硬盘上的数据,异或运算在P校验值和其它数据硬盘间执行。如果同一个分条有2个硬盘同时故障,不同的场景有不同的处理方法。如果Q校验值不在失效的一个硬盘上,数据可以被恢复到数据盘上,然后重新计算校验信息。如果Q在其中一个失效的硬盘上,两个的公式都需要使用才能恢复两个失效硬盘上的数据。
(6)另一种算法是RAID 6 DP。RAID 6 DP也有两个独立的校验数据块。第一个校验信息与RAID 6 P+Q的第一个校验值是相同的,第二个不同于RAID 6 P+Q,采用的是斜向异或运算得到行对角奇偶校验数据块。行奇偶校验值是同一分条的用户数据异或运算获得到,所图所示:P0是由分条0上的D0,D1,D2和D3异或运算得到,P1由分条1上的D4,D5,D6,D7异或运算,等等。所以,P0 = D0 ⊕D1⊕ D2⊕D3,P1 = D4⊕D5⊕D6⊕D7,如此类推。
(7)第二个校验数据块是由阵列的对角线数据块进行异或运算。数据块的选择过程比较复杂。DP0是由硬盘1 的分条0上的D0,硬盘2的分条1上的D5,硬盘3上的分条2的D10,和硬盘上4 分条3上的D15异或操作得到。DP1是对硬盘2 的分条0上的D1,硬盘3的分条1上的D6,硬盘4上分条2的 D11,和的第一块校验硬盘上分条3 上的P3进行异或运算得到。DP2是硬盘3 分条0上的D2,硬盘4上的分条1的 D7,奇偶硬盘分条2的P2,和硬盘1 分条3上的D12进行异或运算得到。所以,DP0 = D0⊕D5⊕D10⊕D15,DP1 = D1⊕D6⊕D11⊕P3,如此类推。
(8)一个RAID 6阵列能够容忍双硬盘失效。如上图所示,如果硬盘1和2失效,上面的所有数据会丢失,但其他硬盘上的数据和奇偶校验信息是有效的,我们了解一下阵列数据是如何恢复的。恢复D12采用DP2和斜向校验(D12 = D2⊕D7⊕P2⊕DP2);恢复D13利用P3和横向校验(D13 = D12⊕D14⊕D15⊕P3),通过使用DP3和斜向校验恢复D8(D8 = D3⊕P1⊕DP3⊕D13),使用P2和横向校验得到D9(D9 = D8⊕D10⊕D11⊕P2),恢复D4采用DP4和斜向校验,利用P1和横向校验得到D5等。这些操作是重复的,直到所有数据在故障盘被恢复。
(9)一个RAID 6组的性能,无论算法是DP还是P+Q,相对都比较慢。因此,RAID 6适用两种场景:
1、数据非常重要,需要尽可能长的时间处于在线和可使用的状态。
2、使用的硬盘容量非常大(通常超过2T)。大容量硬盘的重建时间较长,两个硬盘都失效是会造成数据较长时间不能访问。在RAID 6中,可以实现一个硬盘重构时另一个硬盘失效。一些企业希望在使用大容量硬盘后,存储阵列的供应商使用一个双重保护的RAID组。
数据保护:使用计算校验值的办法来对数据做保护,不过RAID6使用了两种算法。
RAID10:
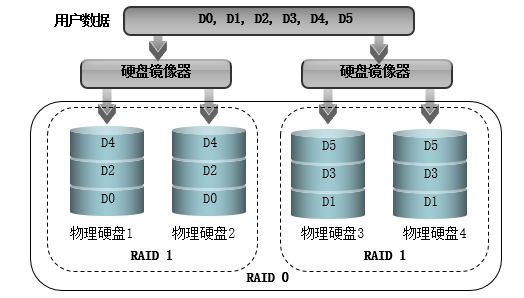
使用两个盘组成一个组,用来做RAID1,然后组和组之间再做一次RAID0.这样的RAID就叫做RAID10
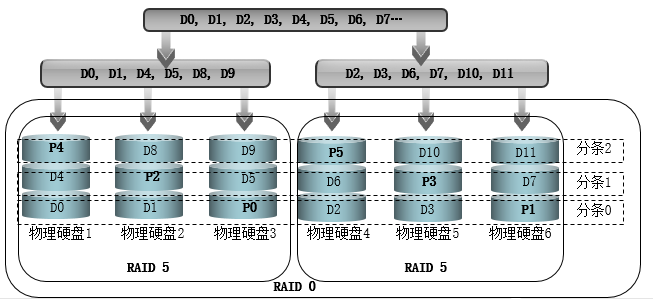
RAID50:
使用多个盘组成一个组做RAID5,然后组和组之间再做RAID0,这样的RAID叫做RAID50.
RAID性能比较:
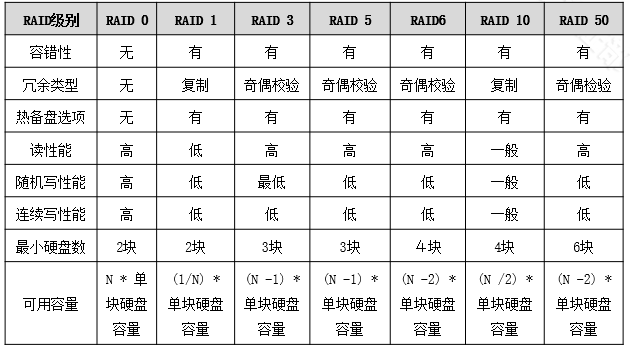
不同的RAID级别适用的不同场景:

热备:当RAID组中某个硬盘失效时,在不干扰当前RAID系统正常使用的情况下,用该RAID组外一个正常的备用硬盘顶替失效硬盘。
热备通过配置热备盘实现,热备盘分为全局热备盘和局部热备盘。
有两种类型热备盘,全局热备盘和局部热备盘。
不同RAID组共用一个热备盘,此热备盘称为全局热备盘。它将替换任何硬盘组中的任何失效硬盘。热备盘要求:热备盘的容量需要比失效的硬盘具有相同的大小或更大,类型要和失效RAID组中的硬盘类型相同!
仅被某一特定的RAID组使的热备盘是一个局部热备盘,如果有其它RAID组里的硬盘失效,局部热备盘不会投入使用。
预拷贝:预测到数据要坏的时候,将数据预先拷贝到热备盘里面
重构:RAID阵列中的故障盘中的数据和校验数据重新生成,并将这些设局写到热备盘上的过程。
重构不一定要有热备盘,也可以是使用新盘。
重构的过程是一个降级的状态,降级的状态不一定重构。
RAID和LUN的关系:
RAID由几个硬盘组成,整体上看相当于由多个硬盘组成的一个物理卷。
LUN:在物理卷的基础上,重新分出来的逻辑卷。LUN的存在可以提高物理卷的利用率。
RAID2.0+技术:
一个硬盘域可以由不同的盘构成(SSD,SAS,SATA,NL SAS),相同类型。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
256M
CKG:多个CK构成CKG,其中每一个CK来自于不同的盘(保证安全性)
Extent:在CKG下面又划分Extent,其默认大小为4M。
在RAID2.0+这种技术中,热备空间是取CK构成的。















 913
913

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









