









注册服务到zookeeper大致就几个方式,引自知乎的内容:点击

流程:
1.服务提供者启动时向/dubbo/com.foo.BarService/providers目录下写入URL
2.服务消费者启动时订阅/dubbo/com.foo.BarService/providers目录下的URL向/dubbo/com.foo.BarService/consumers目录下写入自己的URL
3.监控中心启动时订阅/dubbo/com.foo.BarService目录下的所有提供者和消费者URL
支持以下功能:
1.当提供者出现断电等异常停机时,注册中心能自动删除提供者信息。
2.当注册中心重启时,能自动恢复注册数据,以及订阅请求。
3.当会话过期时,能自动恢复注册数据,以及订阅请求。
4.当设置<dubbo:registry check="false" />时,记录失败注册和订阅请求,后台定时重试。
5.可通过<dubbo:registry username="admin" password="1234" />设置zookeeper登录信息。
6.可通过<dubbo:registry group="dubbo" />设置zookeeper的根节点,不设置将使用无根树。
7.支持*号通配符<dubbo:reference group="*" version="*" />,可订阅服务的所有分组和所有版本的提供者。------------------------分割线------------------------
不过,他这里还是比较粗略的,而且下面的高票评论里甚至有误导性的模糊不清的概念。
对我这个刚刚接触zk的人来说,还不够细致,今早自己动手做了几个实验才最终搞清楚。
再克隆一段下面我比较认可的评论:
zookeeper实现的是资源的订阅发布基本原理就是,分布式的环境下服务方实际上是资源,每个服务方把自己的服务的节点信息,注册在zk上,消费者通过zk获取到所需要的服务的相关信息,比如url之类。
但是zk有个很重要的功能,会主动通知消费者所订阅资源的变化信息,比如,同一个服务 某台机器相关进程关闭后,zk会通知消费者,资源的变化情况,这样,就实现了服务的动态添加减少。
这一点在分布式环境下非常重要,设想如下场景
某网站在做抢购活动,突然发现,后台某个服务资源吃紧,需要增加服务器,而又不能影响当前业务,
简单来说他的功能类似于注册中心。
dubbo的服务提供者会在zookeeper上面创建一个临时节点,表明自己的IP和端口,当消费者需要使用服务时,会先在zookeeper上面查询,找到服务提供者,做一些负载的选择(比如随机、轮流),然后按照这些信息,访问服务提供者。
zookeeper负责保存了服务提供方和服务消费方的的URI(dubbo自定义的一种URI),服务消费方找到zookeeper,向zookeeper要到服务提供方的URI,然后就找到提供方,并调用提供方的服务。解耦,分布式,failover。
dubbo是管理中间层的工具,在业务层到数据仓库间有非常多服务的接入和服务提供者需要调度,dubbo提供一个框架解决这个问题。
注意这里的dubbo只是一个框架,至于你架子上放什么是完全取决于你的,就像一个汽车骨架,你需要配你的轮子引擎。这个框架中要完成调度必须要有一个分布式的注册中心,储存所有服务的元数据,你可以用zk,也可以用别的,只是大家都用zk。
zookeeper用来注册服务和进行负载均衡,哪一个服务由哪一个机器来提供必需让调用者知道,简单来说就是IP地址和服务名称的对应关系。当然也可以通过硬编码的方式把这种对应关系在调用方业务代码中实现,但是如果提供服务的机器挂掉调用者无法知晓,如果不更改代码会继续请求挂掉的机器提供服务。zookeeper通过心跳机制可以检测挂掉的机器并将挂掉机器的IP和服务对应关系从列表中删除。至于支持高并发,简单来说就是横向扩展,在不更改代码的情况通过添加机器来提高运算能力。通过添加新的机器向zookeeper注册服务,服务的提供者多了能服务的客户就多了。但是!!还是有很多东西不清楚,经过早上的几个实验证实。
这里的注册中心指的是zk,而dubbo-admin只是一个web界面来读取修改zk的内容。
服务的发现和订阅广播完全是zk做,默认完全可以不启动dubbo-admin。
动态加减生产者、消费者,都是zk通过心跳包去发现有增减事件,然后去广播同步所有节点状态。
admin的修改接口配置仅仅就把在zk里对应接口的节点信息维护上配置信息。
前段是对应的接口,然后跟着例如版本号、重试次数、payload之类设置的信息。组成一个很长的地址。
这样dubbo就知道每个接口权重啊,payload这些设置了。
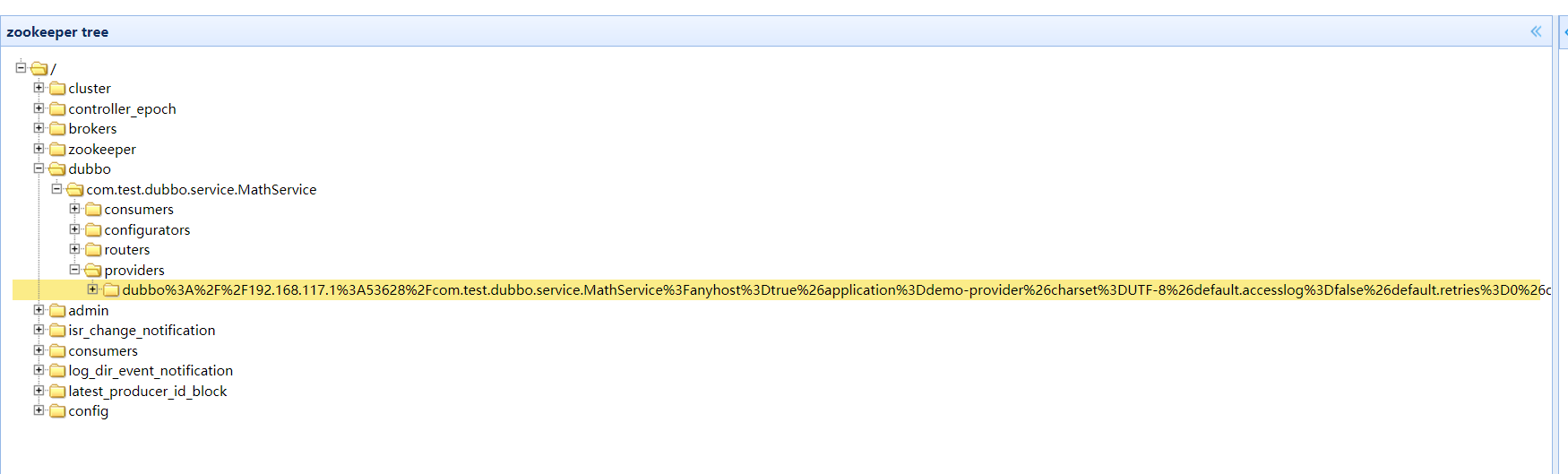
上图zk里的生产者注册是接口事例,中文乱码了还是能看的到一些配置信息的。















 1916
1916

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









