






一、表连接查询:
1、INNER JOIN(内连接):只查匹配行,不匹配行将会删除,数据会丢失。
2、LEFT OUTER JOIN,简称LEFT JOIN,左外连接(左连接):结果保留左表中的所有行,右表中未匹配行以null代替。
3、RIGHT OUTER JOIN,简称RIGHT JOIN,右外连接(右连接):结果保留右表中的所有行,左表中未匹配行以null代替。
4、FULL OUTER JOIN,简称FULL JOIN,全外连接,包含两个表中的所有行,没有数据部分,null代替
5、CROSS JOIN交叉连接(笛卡尔积)效率低;返回左表中的所有行,左边中的所有行与右表中所有行的组合
例题:TabA表有三个字段Id,Col1,Col2 且里面有一条数据1,1,2;;http://www.cnblogs.com/ASPNET2008/p/3308601.html
TabB表有两个字段Id,Col1且里面有四条数据
- 1,1
- 2,2
- 3,2
- 4,2
| Select* fromTabA a LeftjoinTabB b1 ona.Col1=b1.Col1 LeftjoinTabB b2 ona.Col2=b2.Col1 |
执行以上语句,结果是什么?()第二次join的关联的是哪张表?
现在表A多增加一条数据2,3,4,继续执行如上脚本,结果是什么???
二、declear的用法:用于定义变量
1、声明是需要制定变量的类型 例如:declear @id(变量名id) int(变量类型)
2、变量赋值: declear @id int=3
3、用set或者select赋值:set @id=3 或者 select @id=3;
4、用declear声明变量时未提供值,初始化为null;
三、nolock用法
1、SELECT PaymentInfoID FROM InfoSecurity_PaymentInfo p (nolock)
WHERE reqid IN (10199467,10199470)
nolock:用于防止查询锁表。
p:无实际意义,别名。可省略!
四、索引
1、SQL索引学习-索引结构 - min.jiang - 博客园
SQL Server 2008索引使用技巧_kuangxiang_panpan的博客-CSDN博客
索引是什么:
索引是与表或视图关联的磁盘上结构,可以加快从表或视图中检索行的速度。索引包含由表或视图中的一列或多列生成的键。这些键存储在一个结构(B 树)中,使 SQL Server 可以快速有效地查找与键值关联的行。
索引分类:
唯一(UNIQUE)索引: 创建唯一约束会自动创建唯一索引。 它对应的列中仅允许有一个null值。
主键(PK)索引: 是唯一索引的一种特殊类型。创建主键会自动创建主键索引。 要求主键中的每个值是非空,唯一的。
聚集索引: 表中各行的物理顺序与键值的逻辑顺序相同。(例如按拼音查字典,内容本身具有逻辑顺序)
非聚集索引: 表中各行数据存放的物理顺序与键值的逻辑顺序不匹配。聚集索引比非聚集索引有更快的数据访问速度。(按偏旁部首查字典,毫无规律可言,只是简单的映射)
复合索引: 将多个列组合作为索引
全文索引: 是一种特殊类型的寄语标记的功能型索引,由SQL server 中全文引擎服务创建和维护
sql中存储数据的基本单位就是页,一页有8k。数据库可将数据从逻辑上分成页。页包括三项内容
1):96字节大小的表头,存储统计信息,包括:页码,页类型,页的可用空间以及拥有该页的对象的分配单元ID
页的类型,数据页--除了大型对象的数据列之外的数据存储页(int,float。varchar),索引页--存放索引条目;大型对象数据类型(text,image,nvarchar(max))
2):数据行;3)行偏移量。
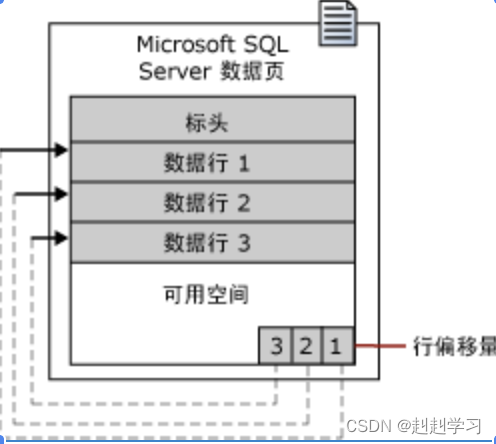
一个区包括8个页分为统一区和混合区;
- 一般情况下,给表或者索引申请新的空间时,从混合区分配,当这个表或者索引的空间超过8个页大小时,会将原本在混合区的页转移到统一区管理
表包含一个或多个分区,每个分区在一个堆或一个聚集索引结构中包含数据行,,,,索引的重要结构B-树
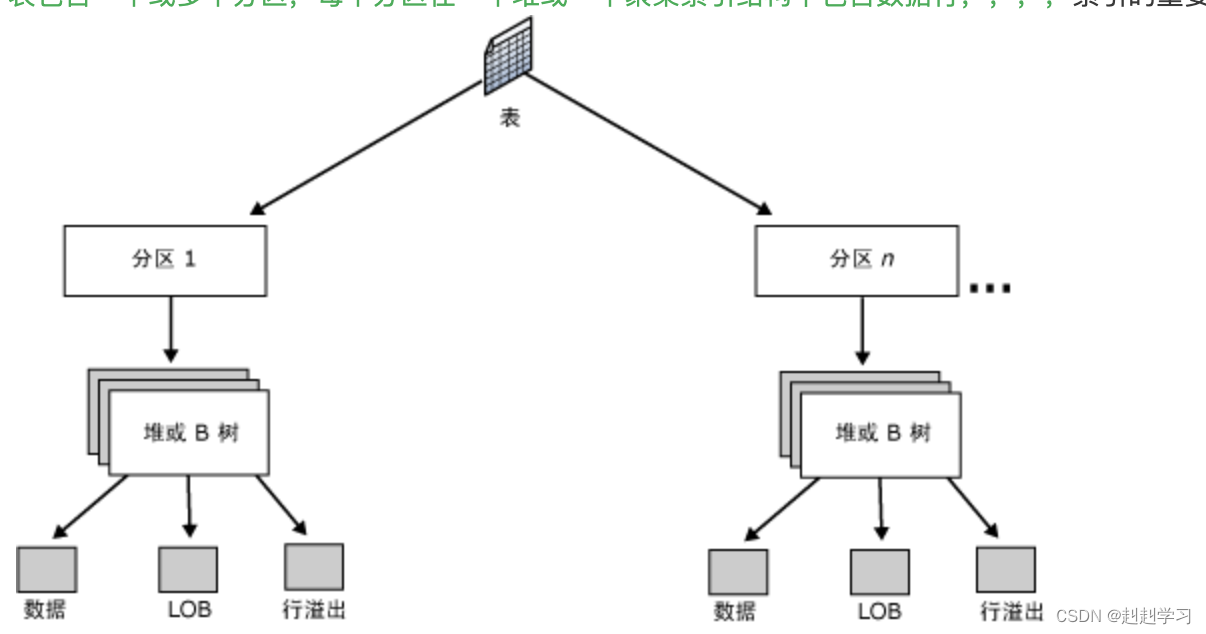
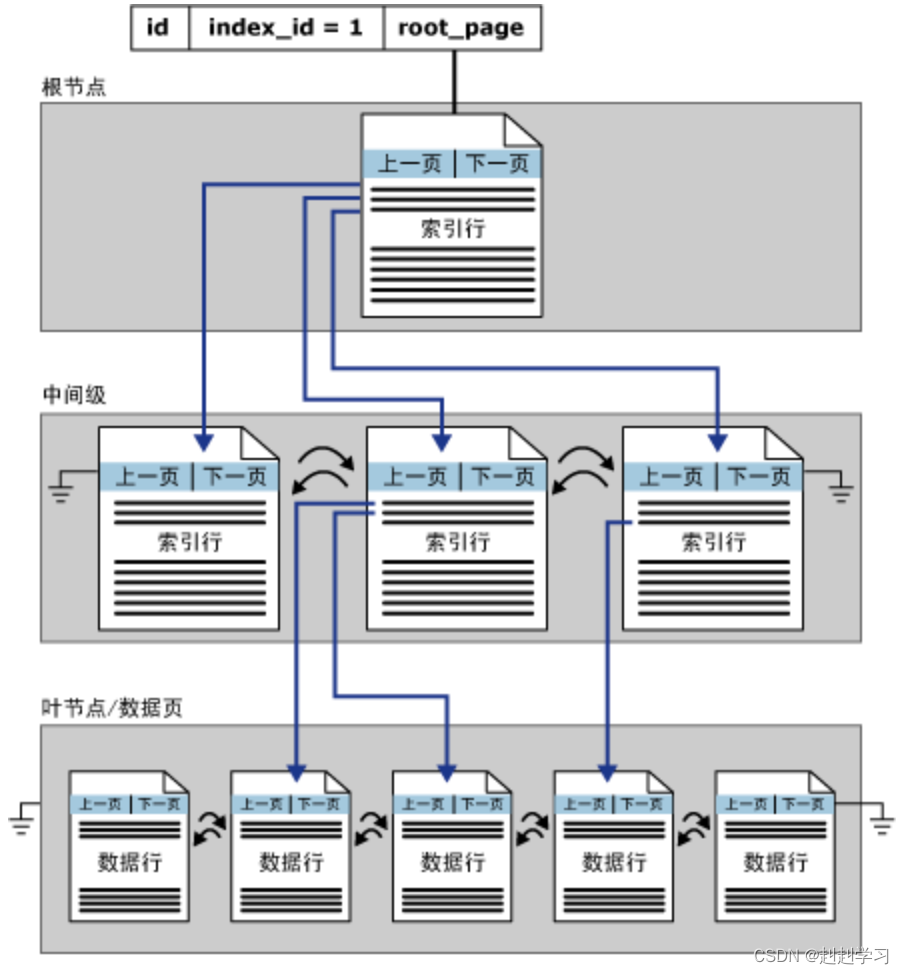
聚集索引结构(Clustered)
::索引中的底层节点称为叶节点。根节点与叶节点之间的任何索引级别统称为中间级。在聚集索引中,叶节点包含基础表的数据页。根节点和中间级节点包含存有索引行的索引页。每个索引行包含一个键值和一个指针,该指针指向 B -树上的某一中间级页或叶级索引中的某个数据行。每级索引中的页均被链接在双向链接列表中
非聚集索引结构(Non-clustered):
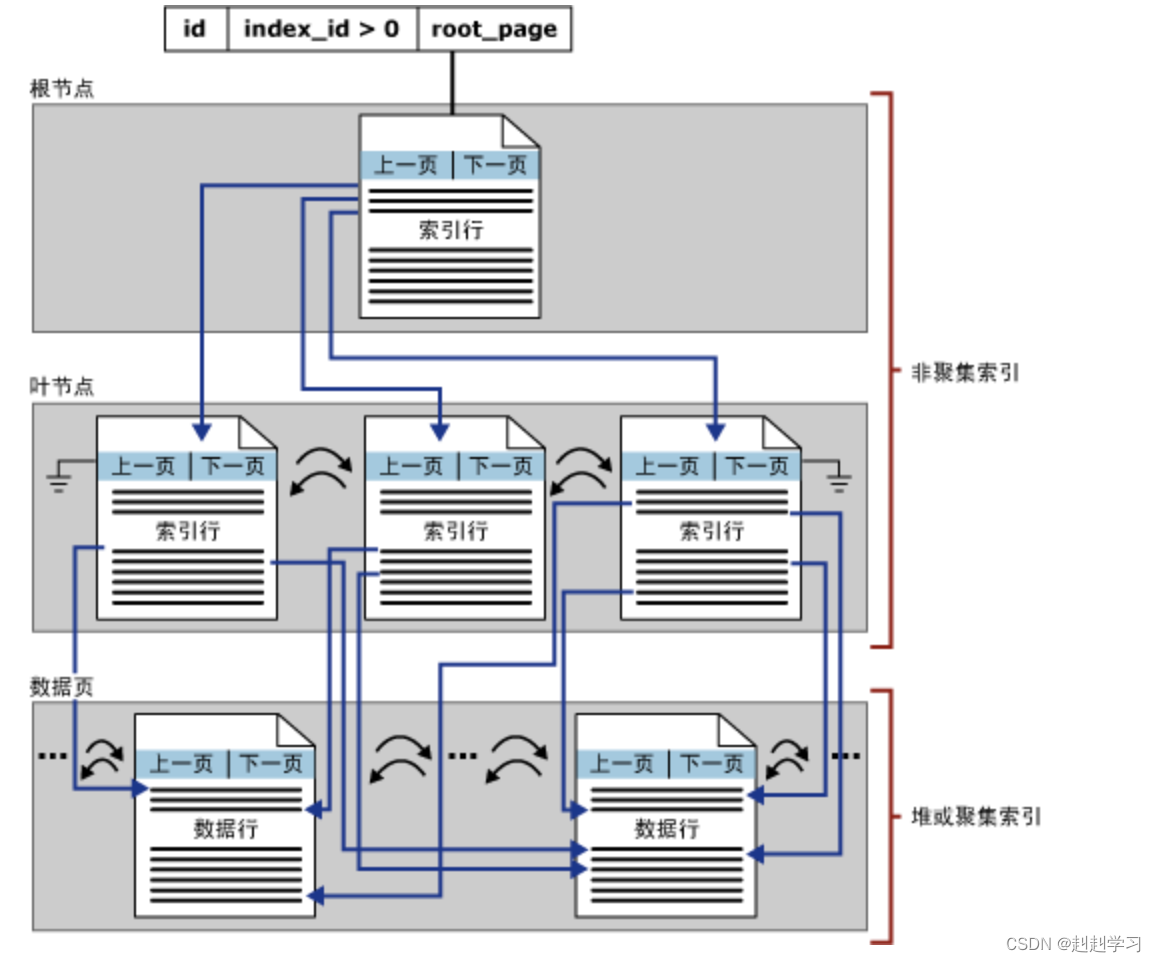
非聚集索引与聚集索引之间的显著差别在于以下两点:
- 基础表的数据行不按非聚集键的顺序排序和存储。
- 非聚集索引的叶层是由索引页而不是由数据页组成
注意:
1、建立聚集索引要求的:“既不能绝大多数都相同,又不能只有极少数相同”的规则
2、无论您是否经常使用聚合索引的其他列,但其前导列(第一个查询条件查询条件)一定要是使用最频繁的列。
3、用聚合索引比用不是聚合索引的主键速度快
4、不要索引常用的小型表
5、使用系统生成的主键
6、不要把社会保障号码(SSN)或身份证号码(ID)选作键
7、聚集索引一定要建立在---您最频繁使用的、用以缩小查询范围的字段上; 您最频繁使用的、需要排序的字段上。
创建索引:
| 评分 |
| CREATE [UNIQUE] [CLUSTERED|NONCLUSTEREN] INDEX idex_name ON table_name (column_name[,column_name]) [WITH FILLFACTOR=X] 其中: UNIQUE 指定唯一索引,可选 CLUSTERED,NONCLUSTEREN指定是聚集索引还是非聚集索引,可选 FILLFACTOR 表示填充因子,指定一个0-100的值,该值指示索引页填满的空间所占的百分比 |
五、高效的top
在查询和提取超大容量的数据集选择top
例如:
selecttop 10000 gid,fariqi,title from tgongwen
where neibuyonghu='办公室'order by gid desc) as a
order by gid asc
六、存储过程
什么是存储过程?
存储过程(procedure)类似于C语言中的函数
用来执行管理任务或应用复杂的业务规则
存储过程可以带参数,也可以返回结果
存储过程可以包含数据操纵语句、变量、逻辑控制语句等
存储过程的优点
(1)执行速度快。
存储过程创建是就已经通过语法检查和性能优化,在执行时无需每次编译。存储在数据库服务器,性能高。
(2)允许模块化设计。
只需创建存储过程一次并将其存储在数据库中,以后即可在程序中调用该过程任意次。并可独立于程序源代码而单独修改。
(3)提高系统安全性。
可将存储过程作为用户存取数据的管道。可以限制用户对数据表的存取权限,建立特定的存储过程供用户使用,完成对数据的访问。
存储过程的定义文本可以被加密,使用户不能查看其内容。
(4)减少网络流量:
一个需要数百行Transact-SQL代码的操作由一条执行过程代码的单独语句就可实现,而不需要在网络中发送数百行代码。
存储过程的分类
系统存储过程
由系统定义,存放在master数据库中
类似C语言中的系统函数
系统存储过程的名称都以“sp_”开头或”xp_”开头
用户自定义存储过程
由用户在自己的数据库中创建的存储过程
类似C语言中的用户自定义函数
七、查询数据库中指定字段在那张表。
----通用查字段(sql server)
use cardriskdb
select [name] '字名',object_name(object_id) '表名', type_name(system_type_id) '类型',max_length '最大长度' from sys.all_columns where [name] in ('TotalPrice') Order by [name]
(mysql)
***
SELECT c.TABLE_Name AS '数据库表名',c.`TABLE_SCHEMA` AS '数据库',c.`DATA_TYPE` AS '字符类型',c.COLUMN_TYPE AS '数据类型'
FROM information_schema.`COLUMNS` AS c WHERE c.`COLUMN_NAME`='activityName'
*****(查询表结构)
SELECT * FROM information_schema.columns
WHERE table_schema = 'bt_mkt_005' #表所在数据库
AND table_name = 'activity_rule_package' #表名
八、更新
UPDATE CardRiskDB..INFOSECURITY_CONTACTINFO
SET ContactName='contactname1' WHERE reqid ='11808032'
八、获取当前时间函数
sql server 获取当前日期利用 convert 来转换成我们需要的datetime格式.
select CONVERT(varchar(12) , getdate(), 112 )
20040912
------------------------------------------------------------
select CONVERT(varchar(12) , getdate(), 102 )
2004.09.12 (对应的格式)
------------------------------------------------------------
select CONVERT(varchar(12) , getdate(), 101 )
09/12/2004
------------------------------------------------------------
select CONVERT(varchar(12) , getdate(), 103 )
12/09/2004
------------------------------------------------------------
select CONVERT(varchar(12) , getdate(), 104 )
12.09.2004
------------------------------------------------------------
select CONVERT(varchar(12) , getdate(), 105 )
12-09-2004
------------------------------------------------------------
select CONVERT(varchar(12) , getdate(), 106 )
12 09 2004
------------------------------------------------------------
select CONVERT(varchar(12) , getdate(), 107 )
09 12, 2004
------------------------------------------------------------
select CONVERT(varchar(12) , getdate(), 108 )
11:06:08
------------------------------------------------------------
select CONVERT(varchar(12) , getdate(), 109 )
09 12 2004 1
------------------------------------------------------------
select CONVERT(varchar(12) , getdate(), 110 )
09-12-2004
------------------------------------------------------------
select CONVERT(varchar(12) , getdate(), 113 )
12 09 2004 1
------------------------------------------------------------
select CONVERT(varchar(12) , getdate(), 114 )
11:06:08.177
| convert( varchar(10), --只取前10位,相当于yyyy-mm-dd getdate() - 2, --前天的日期 120 --转换为格式:yyyy-mm-dd hh:MM:ss) |
mysq获取当前时间函数:
now() 获取当前时间 2008-08-08 22:28:21
curdate() 获取当前日期 2008-08-08
curtime() 获取当前时间 22:28:21
MySQL Extract() 函数,可以上面实现类似的功能:
set @dt = '2008-09-10 07:15:30.123456';
select extract(year from @dt); -- 2008
select extract(quarter from @dt); -- 3
select extract(month from @dt); -- 9
select extract(week from @dt); -- 36
select extract(day from @dt); -- 10
select extract(hour from @dt); -- 7
select extract(minute from @dt); -- 15
select extract(second from @dt); -- 30
select extract(microsecond from @dt); -- 123456
select extract(year_month from @dt); -- 200809
select extract(day_hour from @dt); -- 1007
select extract(day_minute from @dt); -- 100715
select extract(day_second from @dt); -- 10071530
select extract(day_microsecond from @dt); -- 10071530123456
select extract(hour_minute from @dt); -- 715
select extract(hour_second from @dt); -- 71530
select extract(hour_microsecond from @dt); -- 71530123456
select extract(minute_second from @dt); -- 1530
select extract(minute_microsecond from @dt); -- 1530123456
select extract(second_microsecond from @dt); -- 30123456
分别返回日期参数,在一周、一月、一年中的位置。
set @dt = '2008-08-08';
select dayofweek(@dt); -- 6
select dayofmonth(@dt); -- 8
select dayofyear(@dt); -- 221
九:存储过程讲解
你真的会玩SQL吗?玩爆你的数据报表之存储过程编写(上) - 欢醉 - 博客园
十,group by ,having 用法:

使用group by 子句对数据进行分组;对group by 子句形成的组运行聚集函数计算每一组的值;最后用having 子句去掉不符合条件的组。
--having 子句中的每一个元素也必须出现在select列表中。有些数据库例外,如oracle.
--having子句和where子句都可以用来设定限制条件以使查询结果满足一定的条件限制。
--having子句限制的是组(group),而不是行。where子句中不能使用聚集函数,而having子句中可以。
执行顺序:
1.FROM: from子句中的两个表首先进行交叉连接(笛卡尔积), 生成虚拟表VT1。
2.ON: on条件作用在VT1上, 将条件为True的行生成VT2。
3.OUTER: 如果outer join被指定, 则根据外连接条件, 将左表or右表or多表的未出现在VT2查询结果中的行加入到VT2后生成VT3。
4.WHERE: VT3表中应用Where条件, 结果为真的行用来生成VT4。
5.GROUP BY: 根据Group by指定的列, 将VT4的行组织到不同的组中, 生成VT5。
6.CLUB|ROLLUP: 超级组(分组之后的分组)被添加到VT5中, 生成VT6。
7.HAVING: Having用来筛选组, VT6上符合条件的组将用来生成VT7。
8.SELECT: select子句用来选择指定的列, 并生成VT8。
9.DISTINCT: 从VT8中删除重复的行后, VT9被生成。
10.ORDER BY: 根据Order by子句, VT9中的行被排序, 生成游标10。
十一:数据库连接类型
1. 交叉联接 得到所连接表的所有组合 (笛卡儿集)cross join
2. 内联接得到连接表的满足条件的记录组合inner join on(仅显示两个联接表中的匹配行的联接)
3. 外联接(左、右)得到一个表的所有行,及其余表满 足连接条件的行 full | left | right outer join on
left outer join on, 包括第一个命名表("左"表,出现在 JOIN 子句的最左边)中的所有行。不包括右表中的不匹配行。
right outer join on 包括第二个命名表("右"表,出现在 JOIN 子句的最右边)中的所有行。不包括左表中的不匹配行
full outer join on 完全外部连接,包括所有联接表中的所有行,不论它们是否匹配
十二;范式
第一范式:属性不可分,每一列都是不可分割的原子数据项
第二范式:要有主键,在第一范式的基础上,实体属性完全依赖于主关键字,
第三范式:在第一范式基础上,要求一个数据库表中不包含已在其它表中已包含的非主关键字信息,任何非主属性不依赖于其它非主属性[在第二范式基础上消除传递依赖]
十三:数据完整性
1,实体完整性:保证每一行都能别由称为主键的属性来标识
2,域完整性:保证在有效范围内的值才能存入到相应列中
3,引用完整性:确保外键的值必须与相关主键相匹配,禁止向表中插入包含主表中不存在的关键字的数据行
4,用户定义完整性:由用户指定的一组规则
实现数据完整性的主要方式是约束
1. 主键约束 primary key 确保字段值不重复不为NULL
2. 唯一约束 unique 确保字段值不重复
3. 外键约束 foreign key 确保字段值必须来自于指定表
4. 检查约束 check 确保字段值的取值范围
5. 缺省约束 default 给相应字段提供默认值
十四:三值逻辑ture false 和unknown
查询删选null的时候使用的是is null 或者is not null。
EXISTS和IN之间的区别
1.EXISTS只返回TRUE或FALSE,不会返回UNKNOWN。
2.IN当遇到包含NULL的情况,那么就会返回UNKNOWN。
十五:case用法;
简答case函数,,case搜索函数
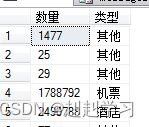
1,对已知数据库进行另一种分组查看

结果

结果
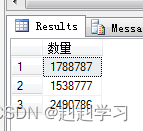
为了在 GROUP BY 块中使用 CASE,查询语句需要在 GROUP BY 块中重复 SELECT 块中的 CASE 块

结果
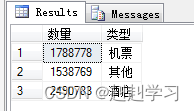
2.根据条件有选择的UPDATE。

结果

(0没有定义,没有变化)
3 ,可以使用BETWEEN,LIKE,IS NULL,IN,EXISTS等等
十六,表表达式,用于临时存储某些结果集
表表达式
1. 期待单个值的地方可以使用标量子查询
2. 期待多个值的地方可以使用多值子查询
3. 在期待出现表的地方可用表值子查询或表表达式
1,公用表表达式
公用表达式的定义非常简单,只包含三部分:
1. 公用表表达式的名字(在WITH之后)
2. 所涉及的列名(可选)
3. 一个SELECT语句(紧跟AS之后)
4.
非递归公用表达式
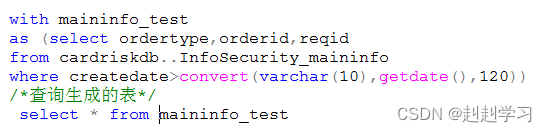
仅仅一次性返回一个结果集用于外部查询调用
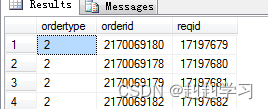
好处:可以在接下来的一条语句中多次引用
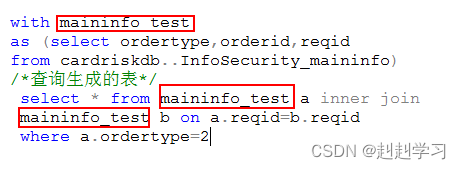
结果

一个with可以定义多个,中间用逗号隔开
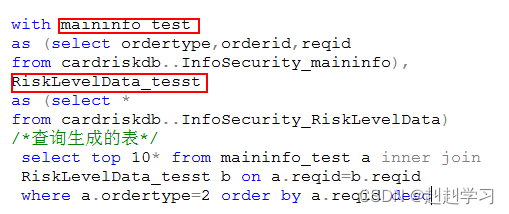
递归公用表达式

十七,排名函数
1,row_number()生成连续行号。
2,rank() 查询结果返回的相同条件的数据,赋予相同的排名数值,(Ranking作为计同排名,当Department的值相同时,Ranking中的值保持不变,当Ranking中的值发生变化时,Ranking列中的值将跳跃到正确的排名数值)
3,dense_rank(),实现了并列排名。
4,ntile(),抓取等量数据分组。
例:row_number()和 rank() 和dense_rank()

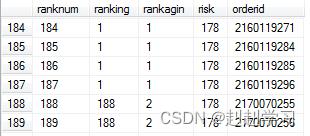
十八,表复制语句
1.INSERT INTO SELECT语句
Insertinto Table2(a, c, d) select a,c,5from Table1
将table1中的数据a,c和常量5,复制到table2中的a,c,d中
2.SELECT INTO FROM
selecta,c INTO#Table2/*临时表不存在*/ from Table1
3.delete from 基于连接的delete
DELETEFROM od /*删除表*/
/*创建连接表,判断条件*/
FROMsales.orderdetails AS od JOIN sales.orders AS o
ON od.orderid = o.orderid
WHEREo.orderdate >= '20080506'
4.update from基于链接的更新
UPDATE o
SET shipcountry = c.country ,
shipregion = c.region ,
shipcity = c.city
FROM sales.orders AS o
JOIN sales.customers AS c ON o.custid = c.custid
WHERE c.country = 'usa'
十九,数据聚合
1,聚合函数:
COUNT:统计行数量
SUM:获取单个列的合计值
AVG:计算某个列的平均值
MAX:计算列的最大值
MIN:计算列的最小值
函数的执行顺序 where过滤——>分组(group by)——>聚合函数
SELECT student_class,COUNT(student_name) AS 总人数 FROM t_student WHERE student_age >20 GROUPBY (student_class); where后面不能加聚合函数
SELECT student_class,AVG(student_age) AS 平均年龄 FROM t_student GROUPBY (student_class) HAVING AVG(student_age)>20; 可以用having实现
二十,cast函数: cast(expression AS date_type)
用于将某种数据类型的表达式显示转换为另一种数据类型(前后两个表达书数据类型必须一致)
expression:任何可接受的sql语句
date_type:可接受的数据类型
不能四舍五入操作
二十一,sql data()函数
DATEDIFF() 函数返回两个日期之间的天数。
语法:DATEDIFF ( datepart/*参数类型*/, date-expression-1/*开始时间*/, date-expression-2/*结束时间*/ )
DATE() 函数返回日期或日期/时间表达式的日期部分。语法:DATE(date)
DATEADD() 函数在日期中添加或减去指定的时间间隔。
语法:DATEADD(datepart/*参数类型*/,number/*间隔数*/,date/*合法的日期表达式*/)
datepart:year | quarter | month | week | day | hour | minute | second | millisecond
例:DATEADD(day,2,OrderDate)时间增加两天,负数为减少
二十二,数据类型
NUMERIC(12, 2)表示数据为数字型,长度12,小数2位。
二十三,APPLY表运算符:将右边的表达式应用到左表的每一行
APPLY必须先逻辑地计算左表达式。这种计算输入的逻辑顺序允许把右表达式关联到左表表达式
1,cross apply形式
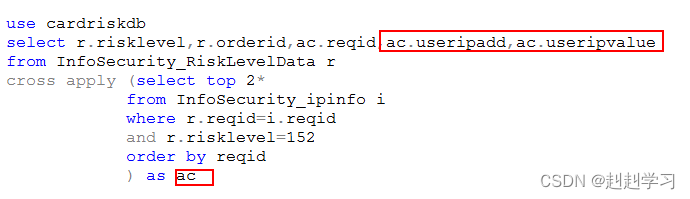
从左表中取出数据,然后一条一条的放到右表中
2,out apply形式与cross apply相比,如果右表为空,则out apply依然与之匹配,并返回改行,cross apply不反会改行
二十三,日期表达式
性能优化 数据库SQL优化大总结之 百万级数据库优化方案_帅性而为1号的博客-CSDN博客
二十四,数据库错误
Host is blocked because of many connection errors;unblock with 'mysqladmin flush-hosts'
原因:一个ip在短时间内产生(超过mysql数据库max_connection_errors的最大值)太多终端的数据库连接
解决办法:进入到数据库中 执行下面的命令 flush hosts;















 1532
1532











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









