







前言
曾经在一个项目中遇到了中文编码的问题,花了好长时间才搞定,当时的需求是要根据前端传的参数(里面有中文)直接从后台导出excel,因为涉及二进制数据,所以不能用ajax,直接跳转页面用户体验好差,所以就在js端生成一个表单传给后台,设置表单action的url时遇到了这个问题,当时的解决方案是对中文参数两次encodeURL进行编码encodeURIComponent(encodeURIComponent($('input[name=name]').val())),问题虽然解决了,但是什么原因一直不懂。直到看到许大神的这一章,才豁然开朗,所以将这些记录下来,和大家分享。
一、几种编码格式的简单比较
(几种编码格式详细介绍,请参考《深入分析java web技术内幕》第三章)
相对来说UTF-16编码效率最高,字符到直接相互转换更简单,进行字符串操作也更好。适合在本地磁盘和内存之间使用,可以进行字符和字节之间的快速切换。如:java的内存编码就采用UTF-16。但它不适合在网络之间传输,因为网络传输容易损坏字节流。一旦字节流损坏将很难恢复
UTF-8更适合网络传输,对ASCII字符采用单字节存储,另外单个字符损坏也不会影响后面的其他字符,在编码效率上结语GBK和UTF-16之间,所以UTF-8在编码效率上和编码安全上做了平衡,是理想的中文编码格式方式。
二、Java Web中涉及的编解码
对于使用中文来说,有I/O的地方就会涉及编码,前面已经提到了I/O操作会引起编码,而大部分I/O引起的乱码都是网络I/O,因为现在几乎所有的应用都涉及网络操作,而数据经过网络传输都是以字节为单位的,所以所有的数据都必须能够被序列化为字节。在java中数据要被序列化必须继承Serializable接口
所谓的压缩,只是将多个单字节字符通过编码转换成一个多字节字符。减少的是string.length(),而并没有减少最终的字节数。所以看一段文本的大小,看字符本身是没有意义的,即使是一样的字符采用不同的编码最终存储的大小也会不同,所以从字符到字节一定要看编码类型。
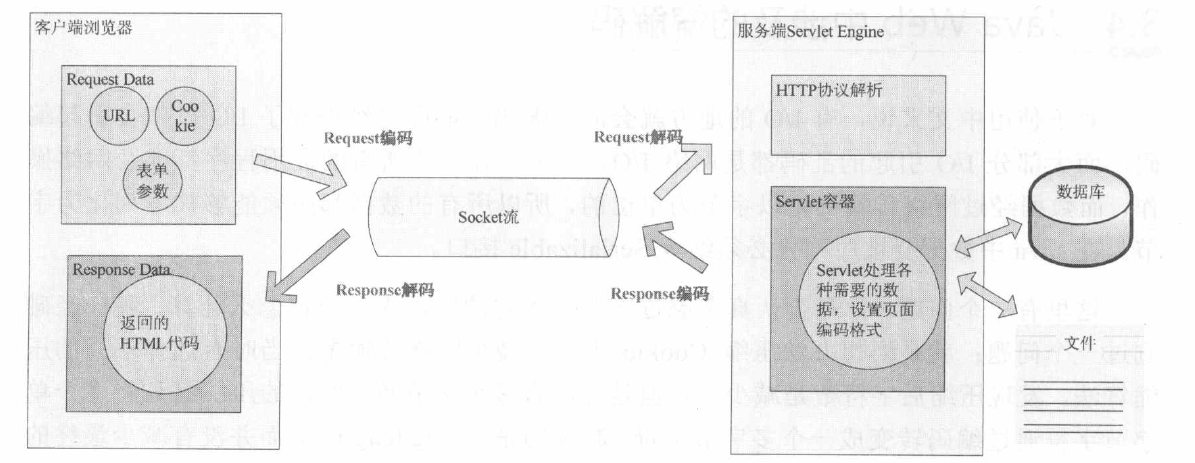
在java web中存在编码转换的地方有以下几处(从请求到返回如下图):
1.用户从浏览器端发起一个HTTP请求,需要存在编码的地方是URL,Cookie,Paramiter。
2.服务器端介绍HTTP请求后要解析HTTP协议,其中URI,Cookie,和POST表单参数需要解码
3.服务器端可能还需要读取数据库中的数据——本地或网络中其他地方的文本文件,这些数据可能存在编码问题
4.档Servlet处理完所有请求的数据后,需要将这些数据再编码通过Socket发送到用户请求的浏览器中
5.浏览器经过解码称为文本
(一)URL的编解码
用户提交一个URL,这个URL中可能存在中文,因此需要编码。一个URL通常由以下几个部分组成,如下图
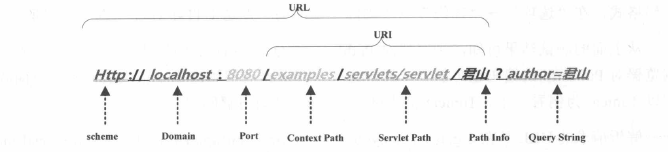
以Tomcat作为Servlet Engine为例,它们分别对应到下面这些配置文件中:
1.Port在Tomcat的< Connector port=”8080”>中配置(该connector在%CATALINA_HOME%/conf/server.xml中< Service>下)
2.Context Path在< Context path=”/examples”>中配置(该context配置在%CATALINA_HOME%/conf/server.xml中< host>下)
3.Servlet Path 在Web应用的web.xml中的< url-pattern>中配置
4.PathInfo是我们请求的具体的Servlet
5.QueryString是要传递的参数
在编码方面,浏览器对PathInfo和QueryString的编码是不一样的,而不同浏览器对PathInfo的编码也可能不一样。
至于解码,对URL的URI部分进行解码的字符集实在connector的< Connector URIEncoding=“UTF-8”>中定义的,如果没有定义,那么将以默认编码ISO-8859-1解析。所以如果有中文URL时最好把URIEncoding设置成UTF-8编码。
QueryString又如何解析呢?GET方式HTTP请求的QueryString于POST方式HTTP请求的表单参数都是作为Parameters保存的,都通过request.getParameter获取参数值。对它们的解码是在request.getParameter方法第一次被调用的时进行的。POST表单的解码在后面介绍,先看GET方式的QueryString的解码字符集要么是在Header中ContentType定义的Charset,要么就是默认的ISO-8859-1,要使用ContentType中定义的编码,就要将connect的< Connector URIEncoding=”UTF-8” useBodyEncodingForURI=”true”/>中的useBodyEncodingForURI设置为true。这个配置项的名字有点容易让人产生混淆,它并不是对整个URI都采用BodyEncoding进行解码,而仅仅是对QueryString使用BodyEncoding解码,这一点要特别注意。
由此来看,在URL中也只有QueryString的解码是我们能在程序里控制的。(再服务器端最好设置< Connector/>中的URIEncoding和useBodyEncodingForURI两个参数)
(二)HTTP Header的编解码
对header中的项进行编码也是在调用request.getHeader时进行的,如果请求的Header项没有解码,则调用MessageBytes的toString方法,这个方法从byte到char的转化时使用的默认编码也是ISO-8859-1,而我们也不能设置Header的其他解码格式
由此看来,不要在Header中传递非ASCII字符,如果一定要传递,可以先将这些字符用org.apache.catalina.util.URLEncoder编码,然后再添加到Header中,我们要访问这些项时再按照相应的字符集解码就好了。
(三)POST表单的编解码
前面提到了POST表单提交参数解码实在第一次调用request.getParameter时发生的,POST表单参数传递方式与QueryString不同,它是通过HTTP的BODY传递到服务端的。
当我们在网页上单击提交按钮时,浏览器首先根据ContentType (在jsp中是通过<%@ page contentType=”text/html;charset=UTF-8”%>来设置的)的Charset编码格式对表单天的参数进行编码,然后提交到服务器端,在服务器端同样也是用ContentType中的字符集进行解码的。所以通过表单提交的参数一般不会出现问题,而且这个字符集编码是我们自己设置的,可以通过request.setCaracterEncoding(charset)来设置
注意,你一定要在第一次调用request.getParameter方式之前就设置request.setCaracterEncoding(charset),否则你的POST表单提交上来的数据也可能出现乱码
针对multipart/form-data类型的参数,也就是上传的文件编码,同样也使用ContentType定义的字符集编码。这里有一个值得注意的地方是,上传文件是用字节流的方式传输到服务器的本地临时目录,这个过程并没有涉及字符编码,而真正编码是在将文件内容添加到parameters中时进行的,如果用这个不能编码将会用默认编码ISO-8859-1来编码
(四)HTTP BODY的编解码
当用户请求的资源已经成功获取后,这些内容将通过Response返回给客户端浏览器,这个过程要经过编码再到浏览器进行解码,编解码字符集可以通过response.setCaracterEncoding(charset)来设置,它将会覆盖request.getCharacterEncoding的值,并且通过Header的Content-Type返回客户端,浏览器接收到返回的Socket流时将通过Content-Type来解码。如果返回的HTTP Header中Content-Type没有设置charset,那么浏览器将根据HTML的< meta HTTP-equiv=”Content-Type” content=”text、html; charset=GBK” />中的charset来解码。如果这里面也没有定义,那么浏览器将使用默认的编码来解码
(五)数据库的编解码
访问数据库都是通过客户端JDBC驱动来完成的,用JDBC来存取数据要和数据的内容编码保持一致,可以通过设置JDBC URL来指定,如:MySQL: url=”jdbc:mysql://localhost:3306/DB?useUnicode=true&characterEncodin=GBK”
三、JS中的编码问题
(一)外部引入JS文件
如果在一个单独的js文件包含字符串输入的情况,如:
<html>
<head>
<script src="statics/javascript/script.js" charset="gbk"></script>引入一个script.js脚本,这个脚本中有如下代码:
document.srite("这是一段中文"); 如果外部的JS文件的编码格式与当前页面的编码格式一致,那么可以不设置这个charset。但是如果script.js文件的编码格式与当前页面的不一致
(二)JS的URL编码
实际上JS中处理URL编码的有三个函数,只要掌握着三个函数,基本上就能正确处理JS的URL乱码问题了
1、escape()
这个已从ECMAScript v3删除,编解码参看下面两个
2、encodeURL()
它是js真正用来对URL编码的函数,它可以将整个URL中的字符(除了一些特殊字符,如!#$'()*+,-.:;/=?@~0-9 a-z A-Z)进行UTF-8编码,在每个码值前加上”%”,如下图:
解码通过decodeURI函数,如图:

3、encodeURIComponent()
encodeURIComponent()这个函数比encodeURL()编码还要彻底,它除了对!'()*_.:;/=?@~0-9 a-z A-Z 这几个字符不编码外,其他所有字符都编码,这个函数通常将一个URL当做一个参数放在另一个URL中,如下图:

它可以将HTTP://localhost/servlet/君山?a=c&a=b作为一个参数放到另一个URL中,如果不进行encodeURIComponent()编码,后面URL中的&将会影响前面的URL的完整性,解码通过decodeURIComponent(),如下图

4、Java与JS编解码问题
java端处理URL编解码有两个类,分别是java.net.URLEncoder 和 java.net.URLDecoder。这两个类可以将所有“%”加UTF-8码值用URT-8解码,从而得到原始的字符。值得注意的是,如果前段用encodeURIComponent编码后,到服务器端用URLDecoder解码可能会出现乱码,这是因为两个字符编码类型不一致导致的,JS编码默认是UTF-8,而服务端中文解码一般都是GBK或者GB2313,所以用encodeURIComponent编码后是UTF-8,而java用GBK解码显然不对。解决方案是用encodeURIComponent两次编码,如encodeURIComponent(encodeURIComponent(str)),这样在java端通过request.getParamter()yong GBK解码后取得的就是UTF-8编码的字符串,如果java端需要使用这个字符串,再用UTF-8解码一次,如果是将这个结果直接通过js输出到前端,那么这个UTF-8字符串可以直接在前端正常显示。
(三)其他需要编码的地方
除了URL和参数编码问题外,在服务端还有很多地方可能存在编码,如可能需要读取XML,Velocity模板引擎,JSP或者从数据库读取数据等。
XML文件可以通过设置头来制定编码格式:
<?xml version="1.0" encoding="UTF-8"?>Velocity模板设置编码格式:
services.VelocityService.input.encoding=UTF-8JSP设置编码格式:
<% @page contentType="text/html; charset=UTF-8"%>参考:
《深入分析java web技术内幕》 许令波















 107
107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









