







XML现在已经成为一种通用的数据交换格式,平台的无关性使得很多场合都需要用到XML。小编将将简单介绍一下Java解析XML的四中方法。
基本的解析方式有两种,一种叫DOM,另一种叫SAX。SAX是基于事件流的解析,DOM是基于XML文档树结构的解析。假设我们XML的内容和结构如下:
<?xml version="1.0" encoding="UTF-8"?>
<config>
<db-info>
<driver-name>com.mysql.jdbc.Driver</driver-name>
<url>jdbc:mysql://localhost:3306/drp</url>
<user-name>root</user-name>
<password>123</password>
</db-info>
</config>
DOM解析是把整个XML文档当做一个对象来处理,首先把整个文档读入到内存中,然后构建一个驻留内存的树结构,然后代码就可以使用 DOM 接口来操作这个树结构。虽然整个文档都在内存中,易操作,可随机访问,但是浪费时间和空间,需要硬件资源充足。
DomReader类代码:
package com.bjpowernode.drp.util;
import java.io.File;
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class DomReader {
public void readXML(File file) {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
try {
DocumentBuilder builder = factory.newDocumentBuilder();
// 获得文档对象--
Document doc = builder.parse(file);
// 获得根元素
Element element = doc.getDocumentElement();
// 用方法遍历递归打印根元素下面所有的ElementNode(包括属性,TextNode非空的值),用空格分层次显示.
listAllChildNodes(element, 0);// 参数0表示设定根节点层次为0
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
/*
* 递归遍历并打印所有的ElementNode(包括节点的属性和文本节点的有效内容),按一般的xml样式展示出来(空格来表示层次)
*/
public void listAllChildNodes(Node node, int level) {
if (node.getNodeType() == Node.ELEMENT_NODE) {
boolean hasTextChild = false;
String levelSpace = "";
for (int i = 0; i < level; i++) {
levelSpace += " ";
}
// 先打印ElementNode的开始标签
System.out.print(levelSpace + "<" + node.getNodeName()
+ (node.hasAttributes() ? " " : ">"));
// 遍历打印节点的所有属性
if (node.hasAttributes()) {
NamedNodeMap nnmap = node.getAttributes();
for (int i = 0; i < nnmap.getLength(); i++) {
System.out.print(nnmap.item(i).getNodeName() + "=\""
+ nnmap.item(i).getNodeValue() + "\""
+ (i == (nnmap.getLength() - 1) ? "" : " "));
}
System.out.print(">");
}
// 该ElementNode包含子节点de时候
if (node.hasChildNodes()) {
level++;
// 获得所有的子节点列表
NodeList nodelist = node.getChildNodes();
// 循环遍历取到所有的子节点
for (int i = 0; i < nodelist.getLength(); i++) {
if (nodelist.item(i).getNodeType() == Node.TEXT_NODE
&& (!nodelist.item(i).getTextContent()
.matches("\\s+"))) {
hasTextChild = true;
System.out.print(nodelist.item(i).getTextContent());
} else if (nodelist.item(i).getNodeType() == Node.ELEMENT_NODE) {
System.out.println();
listAllChildNodes(nodelist.item(i), level);
}
}
level--;
}
System.out.print(((hasTextChild) ? "" : "\n" + levelSpace) + "</"
+ node.getNodeName() + ">");
}
}
}
package com.bjpowernode.drp.util;
import java.io.File;
import java.io.IOException;
import javax.xml.parsers.ParserConfigurationException;
import org.xml.sax.SAXException;
/**
* 解析sys-config.xml文件
*
* @author happy
*
*/
public class XmlConfigReader {
public static void main(String[] args) throws ParserConfigurationException,
SAXException, IOException {
// 获取需要解析的文档
File file = new File("src/sys-config.xml");
(new DomReader()).readXML(file);
}
}
【SAX解析】
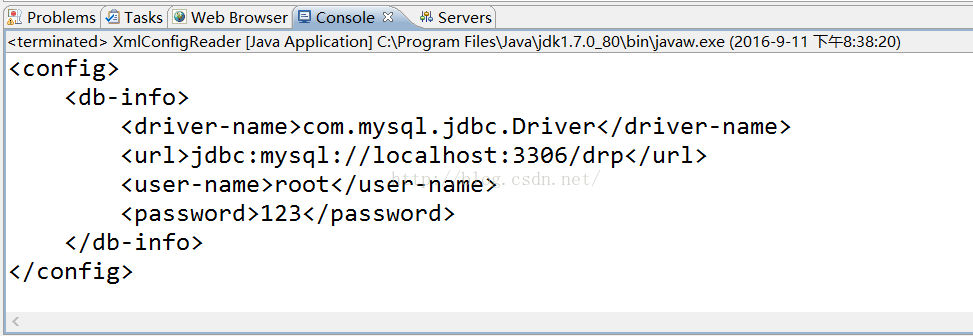
为解决DOM的问题,出现了SAX。SAX,事件驱动。SAX主要是有四个方法,startDocument(),startElement(),endDocument(),endElement(),SAX是按照xml文件的顺序依次解析的,即当xml文件开始的时候,调用startDocument(),当读到一个节点时,调用startElement(),当结束节点时,调用endElement(),结束xml文件时,调用endDocument()。
SaxHandler类代码:
package com.bjpowernode.drp.util;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class SaxHandler extends DefaultHandler {
@Override
public void characters(char[] arg0, int arg1, int arg2) throws SAXException {
System.out.print(new String(arg0, arg1, arg2));
super.characters(arg0, arg1, arg2);
}
@Override
public void startDocument() throws SAXException {
System.out.println("开始解析");
String s = "<?xml version=\"1.0\" encoding=\"UTF-8\"?>";
System.out.println(s);
super.startDocument();
}
@Override
public void startElement(String arg0, String arg1, String arg2,
Attributes arg3) throws SAXException {
System.out.print("<");
System.out.print(arg2);
if (arg3 != null) {
for (int i = 0; i < arg3.getLength(); i++) {
System.out.print(" " + arg3.getQName(i) + "=\""
+ arg3.getValue(i) + "\"");
}
}
System.out.print(">");
super.startElement(arg0, arg1, arg2, arg3);
}
@Override
public void endElement(String arg0, String arg1, String arg2)
throws SAXException {
System.out.print("</");
System.out.print(arg2);
System.out.print(">");
super.endElement(arg0, arg1, arg2);
}
@Override
public void endDocument() throws SAXException {
System.out.println("\n结束解析");
super.endDocument();
}
}
package com.bjpowernode.drp.util;
import java.io.IOException;
import java.io.InputStream;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.SAXException;
/**
* 解析sys-config.xml文件
*
* @author happy
*
*/
public class XmlConfigReader {
public static void main(String[] args) throws ParserConfigurationException,
SAXException, IOException {
// 1.实例化SAXParserFactory对象
SAXParserFactory factory = SAXParserFactory.newInstance();
// 2.创建解析器
SAXParser parser = factory.newSAXParser();
// 3.获取需要解析的文档,生成解析器,最后解析文档
InputStream is = Thread.currentThread().getContextClassLoader()
.getResourceAsStream("sys-config.xml");
SaxHandler dh = new SaxHandler();
parser.parse(is, dh);
}
}
【JDOM解析】
为减少DOM、SAX的编码量,出现了JDOM。JDOM文档声明其目的是“使用20%(或更少)的精力解决80%(或更多)Java/XML问题”(根据学习曲线假定为20%)。JDOM对于大多数Java/XML应用程序来说当然是有用的,并且大多数开发者发现API比DOM容易理解得多。
package com.bjpowernode.drp.util;
import java.io.IOException;
import java.util.List;
import org.jdom2.Document;
import org.jdom2.Element;
import org.jdom2.JDOMException;
public class JDOMReader {
// 读取xml文件
@SuppressWarnings("unchecked")
public void ReadXml(Document document) throws JDOMException, IOException {
Element root = document.getRootElement();// 获得根节点<bookstore>
List<Element> list = root.getChildren();// 获得根节点的子节点
for (Element e : list) {
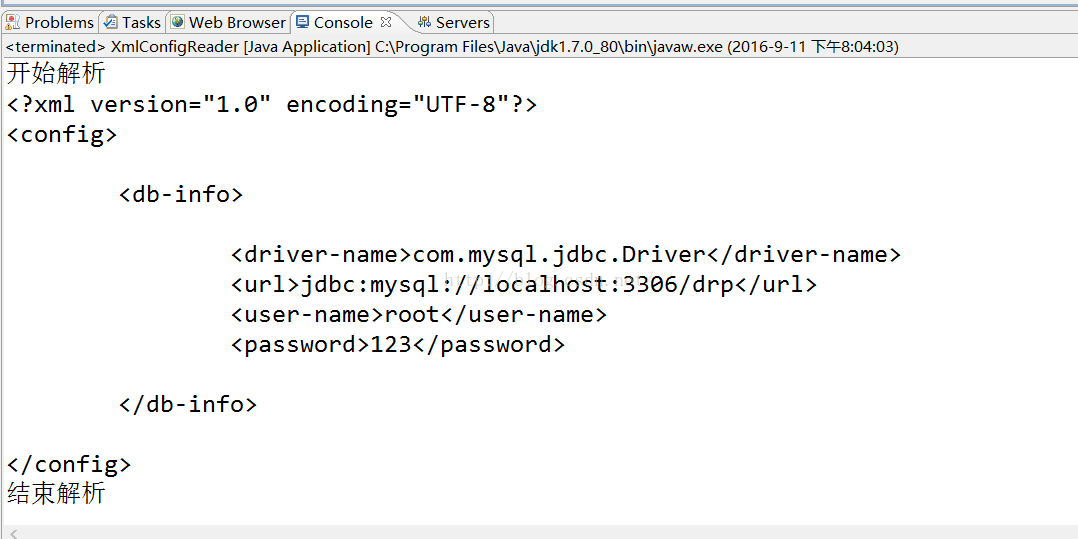
System.out.println("驱动名称:" + e.getChildText("driver-name"));
System.out.println("url:" + e.getChildText("url"));
System.out.println("用户名:" + e.getChildText("user-name"));
System.out.println("密码:" + e.getChildText("password"));
System.out.println("==========================================");
}
}
}
package com.bjpowernode.drp.util;
import java.io.IOException;
import javax.xml.parsers.ParserConfigurationException;
import org.jdom2.Document;
import org.jdom2.JDOMException;
import org.jdom2.input.SAXBuilder;
import org.xml.sax.SAXException;
/**
* 解析sys-config.xml文件
*
* @author happy
*
*/
public class XmlConfigReader {
public static void main(String[] args) throws ParserConfigurationException,
SAXException, IOException {
SAXBuilder builder = new SAXBuilder();// 实例JDOM解析器
try {
// 读取xml文件
Document document = builder.build("src/sys-config.xml");
(new JDOMReader()).ReadXml(document);
} catch (JDOMException e) {
e.printStackTrace();
}
}
}
【DOM4J解析】
DOM4J是一个非常非常优秀的Java XML API,具有性能优异、功能强大和极端易用使用的特点,同时它也是一个开放源代码的软件虽然它代表了完全独立的开发结果,但是最初,它是JDOM的一种智能分支,它合并了许多超出基本XML文档表示的功能,包括集成的XPath支持、XMLSchema支持以及用于大文档或流化文档的基于事件的处理。它还提供了构建文档表示的选项,它通过DOM4J API和标准DOM接口具有并行访问功能。
package com.bjpowernode.drp.util;
import java.io.InputStream;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
/**
* 解析sys-config.xml文件
*
* @author happy
*
*/
public class XmlConfigReader {
public static void main(String[] args) {
SAXReader reader = new SAXReader();
InputStream in = Thread.currentThread().getContextClassLoader()
.getResourceAsStream("sys-config.xml");
try {
Document doc = reader.read(in);
Element driverNameElt = (Element) doc
.selectObject("/config/db-info/driver-name");
Element urlElt = (Element) doc.selectObject("/config/db-info/url");
Element userNameElt = (Element) doc
.selectObject("/config/db-info/user-name");
Element passwordElt = (Element) doc
.selectObject("/config/db-info/password");
String driverName = driverNameElt.getStringValue();
String url = urlElt.getStringValue();
String userName = userNameElt.getStringValue();
String password = passwordElt.getStringValue();
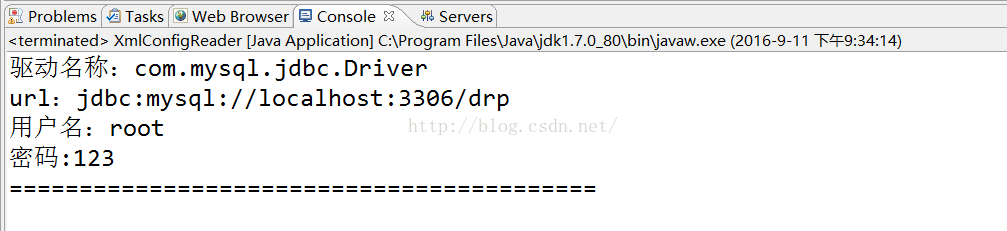
System.out.println(driverName);
System.out.println(url);
System.out.println(userName);
System.out.println(password);
} catch (DocumentException e) {
e.printStackTrace();
}
}
}
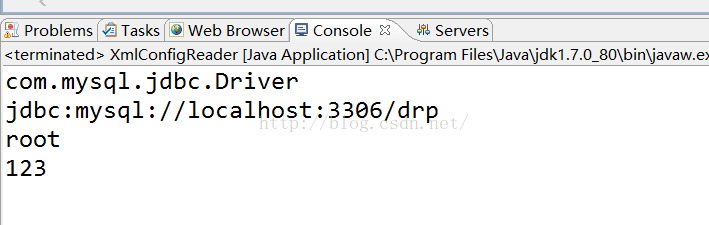
运行效果图如下:
【比较】
①SAX表现较好,这要依赖于它特定的解析方式-事件驱动。一个SAX检测即将到来的XML流,但并没有载入到内存。
②JDOM和DOM在性能测试时表现不佳,在测试10M文档时内存溢出。在小文档情况下还值得考虑使用DOM和JDOM。
③DOM实现广泛应用于多种编程语言。它还是许多其它与XML相关的标准的基础,因为它正式获得W3C推荐,所以在某些类型的项目中可能也需要它(如在JavaScript中使用DOM)。
④DOM4J性能最好,Sun的JAXM也在用DOM4J。目前许多开源项目中大量采用DOM4J,例如大名鼎鼎的Hibernate也用DOM4J来读取XML配置文件。如果不考虑可移植性,那就采用DOM4J。















 1204
1204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









