







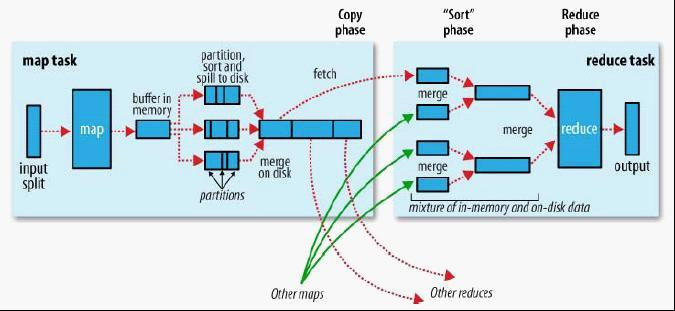
一个Mapper对应一个碎片段。
import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.util.StringUtils; import java.io.IOException; /** * author: test * date: 2015/1/25. */ public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { /** * 输入: * 行所在的下标为key,类型为LongWritable * 行的内容为value,类型为Text * * 输出: * key: Text * value: IntWritable */ //此方法循环调用,从文件的split中,读取每行调用一次,把该行所在的下标为key,以该行的值(内容)为value,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 425
425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









