







本文展示了在之前搭建的Hadoop分布式集群的基础上如何搭建Spark分布式集群环境
一、已有环境
ubuntu 14.04
hadoop 2.7.1 集群安装参考
三台机器
master、slave1、slave2
二、scala安装
1.Scala官网下载地址:http://www.scala-lang.org/download/
2.安装步骤
tar -zxvf scala-2.11.8.tgz
sudo mv scala-2.11.8 /home/cms/
修改/etc/profile
export SCALA_HOME=$HOME/scala-2.11.8export PATH=$SCALA_HOME/binexport CLASSPATH=$SCALA_HOME/lib
立即生效
source /etc/profile
3.测试
scala -version

三、安装spark
1.Spark官方下载链接:
http://spark.apache.org/downloads.html
2.解压安装
tar -zxvf spark-2.0.1-bin-hadoop2.7
spark-2.0.1-bin-hadoop2.7 /home/cms/
修改/etc/profile
export SPARK_HOME=$HOME/scala-2.11.8export PATH=$SPARK_HOME/bin:$SPARK_HOME/sbinexport CLASSPATH=$SPARK_HOME/lib
立即生效
source /etc/profile
3.修改权限
sudo chown -R cms spark-2.0.1-bin-hadoop2.7
4.配置spark,进入到conf目录
cp spark-env.sh.template spark-env.sh
添加内容
export SCALA_HOME=$HOME/scala-2.11.8
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
export HADOOP_HOME=$HOME/hadoop-2.7.1
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
SPARK_MASTER_IP=master
#SPARK_LOCAL_DIRS=$HOME/spark-2.0.1-bin-hadoop2.7
SPARK_DRIVER_MEMORY=1GJAVA_HOME 指定 Java 安装目录;
SCALA_HOME 指定 Scala 安装目录;
SPARK_MASTER_IP 指定 Spark 集群 Master 节点的 IP 地址;
SPARK_WORKER_MEMORY 指定的是 Worker 节点能够分配给 Executors 的最大内存大小;
HADOOP_CONF_DIR 指定 Hadoop 集群配置文件目录。
vim slaves
在slaves文件下填上slave主机名:
slave1
slave2四、配置slave机器
将配置好的spark、scala文件夹分发给所有slaves吧
sudo scp -r spark-2.0.1-bin-hadoop2.7 cms@slave1:/home/cms
sudo scp -r spark-2.0.1-bin-hadoop2.7 cms@slave2:/home/cms
sudo scp -r scala-2.11.8 cms@slave1:/home/cms
sudo scp -rscala-2.11.8 cms@slave2:/home/cms修改/etc/profile,不再累述
五、启动spark
start-all.sh 启动hadoop集群
start-master.sh start-slaves.sh
启动主节点和从节点
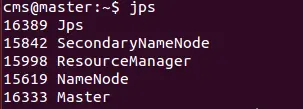
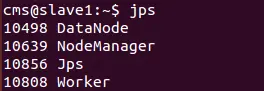
jps
六、测试
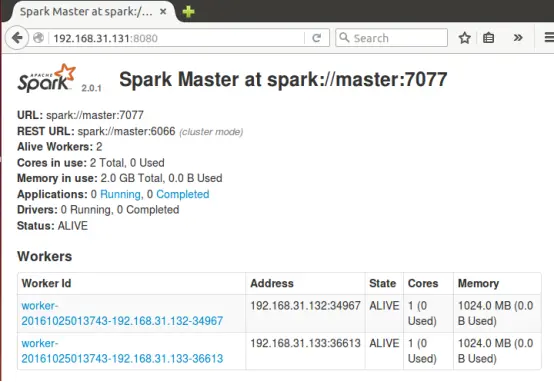
进入Spark的Web管理页面: http://master:8080
七、运行实例
1.准备
在HDFS上放置文件1.txt
cat 1.txtwe rj lo
we ko ls
we rt ouhadoop fs -put 1.txt /tmp/1.txt
2.spark-shell运行
是Spark自带的一个Scala交互Shell,可以以脚本方式进行交互式执行
进入Spark-Shell
只需要执行spark-shell即可:
在Spark-Shell中我们可以使用scala的语法进行简单的测试
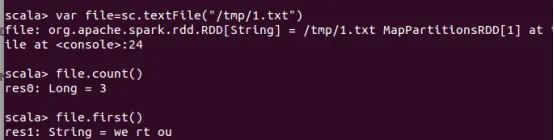
上面的操作中创建了一个RDD file,执行了两个简单的操作:
count()获取RDD的行数
first()获取第一行的内容
操作完成后,Ctrl D组合键退出Shell。
3.pyspark
pyspark类似spark-shell,是一个Python的交互Shell。
执行pyspark启动进入pyspark:

操作完成后,Ctrl D组合键退出Shell。
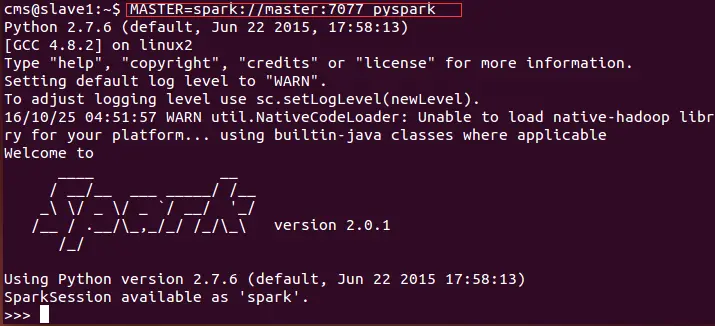
3.使用pyspark连接master再次进行上述的文件行数测试,如下图所示,注意把MASTER参数替换成你实验环境中的实际参数:
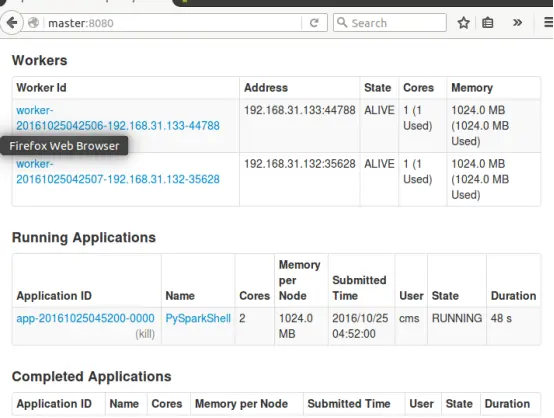
刷新master的web页面,可以看到新的Running Applications
,如下图所示:
八、停止服务
stop-master.sh stop-slaves.sh
九、参考文档
作者:玄月府的小妖在debug
链接:http://www.jianshu.com/p/2f6a85fe7b92
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。















 2016
2016

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









