






目录
1 文件的读写
with open("文件路径", “打开模式”, encoding="操作文件的字符编码") as f:
f.读写操作()
例:
with open("E:\ipython\测试文件.txt", "r", encoding="gbk") as f:
text = f.read()1.1 打开模式

1.2 操作文件的字符编码
utf-8: 万国码
gbk: 中文编码
缺省则默认为“gbk”,尽量不缺省
1.3 f.读写操作()
1.3.1 读取
f.read() 全部读取
f.readline() 逐行读取
f.readlines() 以每行为元素,形成一个列表
【注1:每行文字最后有换行符,print()每次输出时默认有换行,去除可使用print(text, end="") 】
【注2:文件较大时,read()和readlines()占用内存过大,不推荐使用,readline使用起来又不方便,可用如下代码】
with open("三国演义.txt", "r", encoding="gbk") as f:
for text in f: #f本身就是可迭代对象,每次读取一行
print(text)1.3.2 写入
f.write() 写入字符串内容,注意文件的写入格式【w:覆盖写(完全清空文件再写), a:追加写】
f.writelines() 将列表写入文件
1.3.3 既读又写
r+ 读上加写,指针在开始,直接写则不清空文件,从第一行开始逐行覆盖,指针移到末尾则追加写
w+ 覆盖写上加读,指针在末尾,移到开始才能读,写时清空全部内容再写(覆盖写)
a+ 追加写上加读,指针在末尾,写时追加写



1.4 数据存储与读取
1.4.1 csv格式——表格
用逗号将数据分隔开,可用excel打开
- 写入
ls = [["编号", "数学成绩", "语文成绩"], ["1", "100", "98"], ["2", "99", "97"], ["3", "96", "100"]]
with open("score.csv", "w", encoding="gbk") as f:
for row in ls: #逐行写入
f.write(",".join(row)+"\n") #用逗号将各行字符串连起来,末尾加换行符运行结果:
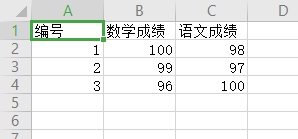
- 读取
with open("score.csv", "r", encoding="gbk") as f:
text = f.read()
print(text)1.4.2 json格式——字典

2 异常
- try-except Exception(用于错误检测)
如果try内代码块顺利执行,except不被触发,
如果try内代码块发生错误,触发except,执行except内代码块

- try-except Exception as e(捕获异常值)

- try-except-else

- try-except-finally

3 模块
分类:python内置、第三方库、自定义文件
导入方式:
1.import 模块名——导入整个模块
调用方式:模块名.函数名或类名
2.from 模块名 import 函数名或类名——导入模块中指定函数和类
调用方式:函数名或类名
3.from 模块名 import *——导入模块中所有函数和类
调用方式:函数名或类名
4 习题
一、文件的读写
读取某文件,统计文本中所有字符的出现频次,将结果按频次由高直低保存到另一文件中。
如:令:4452,
狐:2562,
冲:927,
def count_charac_num(f):
#统计文本中每个字符的个数,换行符和空格除外
dict = {}
for row in f:
for i in row:
if i == " " or i =="\n":
continue
else:
dict[i] = dict.get(i, 0) + 1
return dict
with open("吴恩达目录.txt", "r", encoding="gbk") as f:
dict = count_charac_num(f)
#根据各字符的出现频次由高至低排列
list_sort_down = sorted(list(dict.items()), key = lambda x: x[1], reverse = True)
with open("吴恩达目录字符频次.txt", "w", encoding="gbk") as f1:
for k,v in list_sort_down:
f1.write(k+":"+str(v)+"\n")二、模块自定义,导入及调用
- 构造一个筛选n以内所有素数的函数,保存在screening_prime.py中
- 在新的py文件中导入并调用该函数,输出1000以内所有素数
screening_prime.py
from math import sqrt
def is_prime(n):
#判断一个数字n是否为素数,若能被2~根号n内某一数字整除则为素数
if n == 1:
return False
for i in range(2, int(sqrt(n))+1):
if n % i == 0:
return False
return Truefrom screening_prime import is_prime
n = 1000
prime = []
for i in range(1,n+1):
if is_prime(i):
prime.append(i)
else:
continue
print(prime)















 1412
1412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









