







1.1 需求
实现一个资源管理器的搜索功能,通过关键字搜索,凡是文件名或文件内容包括关键字的文件都要找出来。
注意:该入门程序只对文本文件(.txt)搜索。
1.2 开发环境
Jdk:1.7.0_72以上的版本
Lucene包:
lucene-core-4.10.3.jar
lucene-analyzers-common-4.10.3.jar
lucene-queryparser-4.10.3.jar
其它:
commons-io-2.4.jar
junit-4.9.jar
或者 pom.xml
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>6.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-highlighter</artifactId>
<version>6.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>6.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>6.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-smartcn</artifactId>
<version>6.3.0</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.4</version>
</dependency>
1.3 Index索引
1.3.1 创建数据源目录 存放文档的目录
创建数据源目录D:\LucentTest\luceneFile,该目录存放要搜索的原始文件。
1.3.2 创建索引目录 存放索引的目录
创建索引目录D:\LucentTest\luceneIndex ,该目录存放创建的索引文件。
1.3.3 Document和Field
索引的目的是为了搜索,索引前要对搜索的内容创建成
Document和Field。Document文档是Lucene搜索的单位,最终要将文档中的数据展示给用户,文档中包括多个Field,在设计文档对象时,可以将一个Document对应关系数据库的一条记录,字段对应Field,但是要注意:Document结构属于NOSql(非关系),不同的Document包括不同的Field,建议将相同类型数据的Document保持Field一致,方便管理维护,避免将不同类型Field数据融合在一个Document中。
比如:
文件信息Document,Field包括:文件名称、文件类型、文件大小、文件路径、文件内容等,避免加入非文件信息Field。
1.3.3.1 Field属性
Field是文档中的域,包括Field名和Field值两部分,一个文档可以包括多个Field,Document只是Field的一个承载体,
Field值即为要索引的内容,也是要搜索的内容。
1、 是否分析(tokenized)
是:将Field值分析出语汇单元即作分词处理,将词进行索引
比如:商品名称、商品简介等,这些内容用户要输入关键字搜索,由于搜索的内容格式大、内容多需要分析后将语汇单元索引。
否:不作分词处理
比如:商品id、订单号、身份证号等
2、 是否索引(indexed)
是:将Field分析后的词或整个Field值进行索引,只有索引方可搜索到。
比如:商品名称、商品简介分析后进行索引,订单号、身份证号不用分析但也要索引,这些将来都要作为查询条件。
否:不索引无法搜索到
比如:商品id、文件路径、图片路径等,不用作为查询条件的不用索引。
3、 是否存储(stored)
是:将Field值存储在文档中,存储在文档中的Field才可以从Document中获取
比如:商品名称、订单号,凡是将来要从Document中获取的Field都要存储。
否:不存储Field值,不存储的Field无法通过Document获取
比如:商品简介,内容较大不用存储。如果要向用户展示商品简介可以从系统的关系数据库中获取商品简介。
1.3.3.2 Field常用类型
下边列出了开发中常用 的Filed类型,注意Field的属性,根据需求选择:
| 名称 | 说明 |
| IntPoint | 对int型字段索引,只索引不存储,提供了一些静态工厂方法用于创建一般的查询,提供了不同于文本的数值类型存储方式,使用KD-trees索引 |
| FloatPoint | 对float型字段索引,其它同上 |
| LongPoint | 对long型字段索引,其它同上 |
| DoublePoint | 对double型字段索引,其它同上 |
| BinaryDocValuesField | 只存储不共享,例如标题类字段,如果需要共享并排序,推荐使用SortedDocValuesField |
| NumericDocValuesField | 存储long型字段,用于评分、排序和值检索,如果需要存储值,还需要添加一个单独的StoredField实例 |
| SortedDocValuesField | 索引并存储,用于String类型的Field排序,需要在StringField后添加同名的SortedDocValuesField |
| StringField | 只索引但不分词,所有的字符串会作为一个整体进行索引,例如通常用于country或id等 |
| TextField | 索引并分词,不包括term vectors,例如通常用于一个body Field |
| StoredField | 存储Field的值,可以用 IndexSearcher.doc和IndexReader.document来获取存储的Field和存储的值 |
1.3.4 IndexWriter和Directory
IndexWriter是索引过程的核心组件,通过IndexWriter可以创建新索引、更新索引、删除索引操作。IndexWriter需要通过Directory对索引进行存储操作。
Directory描述了索引的存储位置,底层封装了I/O操作,负责对索引进行存储。它的子类常用的包括FSDirectory(在文件系统存储索引)、RAMDirectory(在内存存储索引)。
1.3.5 索引程序代码
分析:
确定文档的各各域的属性和类型:
文件名称:不分析、索引、存储,使用StringField方法
文件路径:不分析、不索引、存储,使用StoredField方法
文件大小:分析、索引、存储,使用LongField方法
文件内容:分析,索引,不存储,使用TextField方法
代码如下:
/**
* 创建索引
*/
@Test
public void createIndex() throws Exception {
//1、指定索引存放的路径 ,lucene特点,创建一次索引,可多次使用
//方式有两种,一种是放在内存中的, 也就是我们通过new 的方式去实现,另一种是生成文件。
//Directory directory=new RAMDirectory(); //内存的方式 RAM 表示内存
Directory directory=FSDirectory.open(Paths.get("D:\\LucentTest\\luceneIndex"));
//分析器对象
Analyzer analyzer = new StandardAnalyzer();
//创建一个IndexwriterConfig对象
//第一个参数:lucene的版本,第二个参数:分析器对象
IndexWriterConfig config=new IndexWriterConfig(analyzer);
//创建一个Indexwriter对象
IndexWriter indexWriter = new IndexWriter(directory, config);
indexWriter.deleteAll();//清除以前的index
//读取文件信息
//原始文档存放的目录
File path = new File("D:\\LucentTest\\luceneFile");
for (File file:path.listFiles()) {
if (file.isDirectory()) continue;
//读取文件信息
//文件名
String fileName = file.getName();
//文件内容
String fileContent = FileUtils.readFileToString(file);
//文件的路径
String filePath = file.getPath();
//文件的大小
long fileSize = FileUtils.sizeOf(file);
//创建文档对象
Document document = new Document();
//创建域
//三个参数:1、域的名称2、域的值3、是否存储 Store.YES:存储 Store.NO:不存储
Field nameField = new TextField("name", fileName, Field.Store.YES);
Field contentField = new TextField("content", fileContent, Field.Store.YES);
Field pathField = new StoredField("path", filePath);
//把域添加到document对象中
document.add(nameField);
document.add(contentField);
document.add(pathField);
//把document写入索引库
indexWriter.addDocument(document);
}
indexWriter.close();
}
1.4 Search 搜索
1.4.1 索引结构
Lucene的索引结构为倒排索引,倒排文件或倒排索引是指索引对象是文档或者文档集合中的单词等,用来存储这些单词在一个文档或者一组文档中的存储位置,是对文档或者文档集合的一种最常用的索引机制。
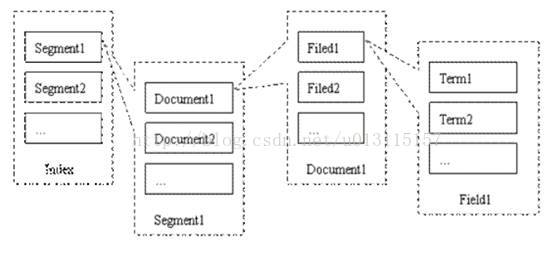
Lucene索引index由若干段(segment)组成,每一段由若干的文档(document)组成,每一个文档由若干的域(field)组成,每一个域由若干的项(term)组成。
项是最小的索引单位,如果Field进行分析,可能会分析出多个语汇单元(词),每个词就是一个Term项,如果Field不进行分析,整个Field就是一个Term项。
项直接代表了一个字符串以及其在文件中的位置、出现次数等信息。域将项和文档进行关联。
1.4.2 使用Luke查看索引
Luke作为Lucene工具包中的一个工具(http://www.getopt.org/luke/),用于查询、修改lucene的索引文件。
打开Luke方法:
cmd运行:java -jar lukeall-4.10.3.jar
如果需要加载第三方分词器,如果需要加载第三方分词器,需通过java.ext.dirs加载jar包:
可简单的将第三方分词器和lukeall放在一块儿,cmd下运行:。
java -Djava.ext.dirs=. -jar lukeall-4.10.3.jar
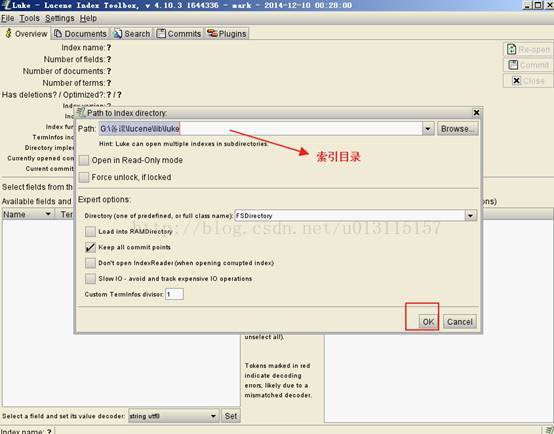
1.4.3 确定索引目录
搜索是要从索引中查找,确定索引目录即上边创建的索引目录 D:\LucentTest\luceneIndex。
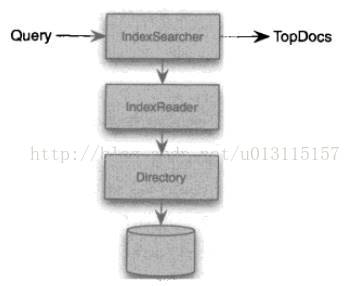
1.4.4 IndexSearcher和IndexReader
通过IndexSearcher执行搜索,构建IndexSearcher需要IndexReader读取索引目录,如下图:
代码如下:
// 指定 目录
File folder = new File(indexFolder);
Directory directory = FSDirectory.open(folder);
// indexReader
IndexReader indexReader = DirectoryReader.open(directory);
// 定义indexSearcher
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
需要注意:
Indexreader打开需要耗费很大的系统资源,
建议使用一个IndexReader,如果索引进行添加、修改或删除需要打开新的Reader才可以搜索到。
IndexSearcher搜索方法如下:
| 方法 | 说明 |
| indexSearcher.search(query, n) | 根据Query搜索,返回评分最高的n条记录 |
| indexSearcher.search(query, filter, n) | 根据Query搜索,添加过滤策略,返回评分最高的n条记录 |
| indexSearcher.search(query, n, sort) | 根据Query搜索,添加排序策略,返回评分最高的n条记录 |
| indexSearcher.search(booleanQuery, filter, n, sort) | 根据Query搜索,添加过滤策略,添加排序策略,返回评分最高的n条记录 |
1.4.5 搜索程序代码
/**
* 查询索引
* @throws Exception
*/
@Test
public void searchIndex() throws Exception {
//打开索引库
//指定索引库存放的位置
Directory directory = FSDirectory.open(Paths.get("D:\\LucentTest\\luceneIndex"));
//创建一个IndexReader对象
IndexReader indexReader = DirectoryReader.open(directory);
//创建IndexSearcher对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//创建查询对象
//参数:1、要搜索的域2、搜索的关键词
Query query = new TermQuery(new Term("content", "253"));
//执行查询
//第一个参数:查询对象,第二个参数:返回结果的最大值。
TopDocs topDocs = indexSearcher.search(query, 10);
//取总共查询的结果数量
System.out.println("查询结果总数量:" + topDocs.totalHits);
//文档的ID列表
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
//遍历列表
for (ScoreDoc scoreDoc : scoreDocs) {
//文档的id
int doc = scoreDoc.doc;
//根据文档的id取document对象
Document document = indexSearcher.doc(doc);
//取文档中的域的内容
System.out.println(document.get("name"));
System.out.println(document.get("content"));
System.out.println(document.get("path"));
}
//关闭indexreader对象
indexReader.close();
}
1.4.6 TopDocs
Lucene搜索结果可通过TopDocs遍历,TopDocs类提供了少量的属性,如下:
| 方法或属性 | 说明 |
| totalHits | 匹配搜索条件的总记录数 |
| scoreDocs | 顶部匹配记录 |
注意:
Search方法需要指定匹配记录数量n:indexSearcher.search(query, n)
TopDocs.totalHits:是匹配索引库中所有记录的数量
TopDocs.scoreDocs:匹配相关度高的前边记录数组,scoreDocs的长度小于等于search方法指定的参数n
下面是小编的微信转帐二维码,小编再次谢谢读者的支持,小编会更努力的

----请看下方↓↓↓↓↓↓↓
百度搜索 Drools从入门到精通:可下载开源全套Drools教程

深度Drools教程不段更新中:

更多Drools实战陆续发布中………
扫描下方二维码关注公众号 ↓↓↓↓↓↓↓↓↓↓

















 2684
2684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









