







中期检查顺利通过,因为要赶在新版本的系统集成前完成,所以这两天加紧进度,为词典scope 添加了例句和自动纠错的功能,分别用两个类实现。
例句功能:
一开始的想法是通过合适的接口返回例句,但是不幸的是,现有的翻译接口都不返回例句,返回例句的接口早就已经停止了服务,这个方法行不通,那就只有爬去网页然后解析html的内容,python3中的原生类是HTMLparser,继承这个类然后重写其中的方法。通过看有道词典的html源码,发现里面的例句都在<div class=examples>标签里,而且又在<p>标签中,所以我们就处理这两个标签的内容
class get_examples(HTMLParser):
def __init__(self):
self.data=[]
self.showlist = []
self.flag=0
self.getdata=0
HTMLParser.__init__(self)
def handle_starttag(self,tag,attrs):
if tag =='div':
for name,value in attrs:
if name == 'class' and value == 'examples':
self.flag=1
if tag == 'p':
if self.flag == 1:
self.getdata = 1
return
def handle_data(self,data):
if self.getdata:
self.data.append(data)
def handle_endtag(self,tag):
if tag=='p':
self.getdata = 0
if tag =='div':
self.flag=0
def getresult(self):
data_len = len(self.data)
if data_len <= 4:
for i in self.data:
self.showlist.append(i)
else:
for i in range(0,4):
if self.data[i]:
self.showlist.append(self.data[i])
return self.showlist strUrl = 'http://dict.youdao.com/search?q=%s&keyfrom=dict.index' % query
req = urllib.request.urlopen(strUrl)#通过网络获取网页
the_page = req.read()
geter = get_examples()
geter.feed(the_page.decode('utf-8'))
examples_list = geter.getresult()
自动纠错的话我选择了使用别的现成的算法,即最小距离法,就是根据原单词经过对字母的增删改几次变化变成目的单词,进行概率的估计,不过算法这个我不擅长,就靠拿来主义了:
class correct_word():
def __init__(self):
self.alphabet = 'abcdefghijklmnopqrstuvwxyz'
def words(self,text): return re.findall('[a-z]+', text.lower())
def train(self,features):
model = collections.defaultdict(lambda: 1)
for f in features:
model[f] += 1
return model
def NWORDS(self): return self.train(self.words(open('/usr/share/unity-scopes/isgd/big.txt').read()))
#NWORDS = self.train(words(open('big.txt').read()))
def edits1(self,word):
n = len(word)
return set([word[0:i]+word[i+1:] for i in range(n)] + # deletion
[word[0:i]+word[i+1]+word[i]+word[i+2:] for i in range(n-1)] + # transposition
[word[0:i]+c+word[i+1:] for i in range(n) for c in self.alphabet] + # alteration
[word[0:i]+c+word[i:] for i in range(n+1) for c in self.alphabet]) # insertion
def known_edits2(self,word):
nwords = self.NWORDS()
return set(e2 for e1 in self.edits1(word) for e2 in self.edits1(e1) if e2 in nwords)
def known(self,words):
nwords = self.NWORDS()
return set(w for w in words if w in nwords)
def correct(self,word):
candidates = self.known([word]) or self.known(self.edits1(word)) or self.known_edits2(word) or [word]
nwords = self.NWORDS()
return max(candidates, key=lambda w: nwords[w])然后在search中调用,整体的逻辑是首先进行一次查询,如果返回的结果和查询的单词是一样的,说明单词有错误,就进行纠错,然后再一次查询,如果是中文的翻译,那么就正常进行处理,得到结果如下:
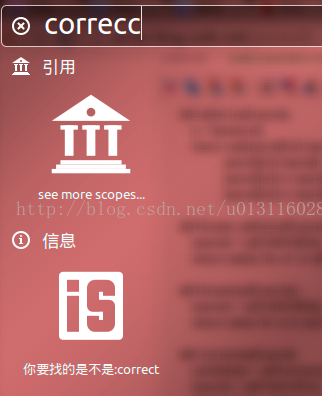
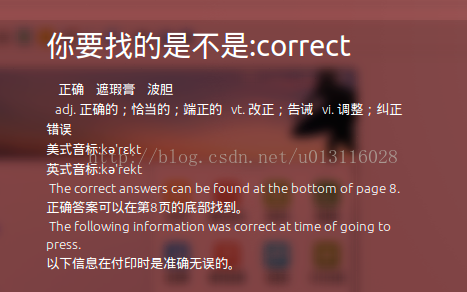















 397
397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









