







 本文针对SQL初学者,通过一系列实例加深对SQL关键字的理解,包括查询每门课成绩大于80分的学生、删除冗余信息、行转列、复制表结构和数据,以及处理关联表的删除操作。建议读者亲手实践以巩固知识。
本文针对SQL初学者,通过一系列实例加深对SQL关键字的理解,包括查询每门课成绩大于80分的学生、删除冗余信息、行转列、复制表结构和数据,以及处理关联表的删除操作。建议读者亲手实践以巩固知识。
本文适合将w3school的SQL教程(http://www.w3school.com.cn/sql/sql_create_table.asp)都基本看过一遍的猿友阅读。
说说博主的情况吧。毕业找工作之前确实有大概看过w3school的SQL教程,然后参加校园招聘,每次遇到一些SQL笔试题,立马懵逼了(大写的)。其实我那时候大概知道怎么写的,只是总是写不正确,或者是对一些特定的而且没有见过的场景的SQL语句,根本写不出来。相信不少猿友工作之后,其实挺多都用得不熟吧(如果白板编写的话)。
因为大部分Java猿友工作做的事情,其实比较少情况自己去动手写特定场景的SQL(可能有也是百度,接触过一个会一个),简单SQL也是直接由框架(hibernate和Mybatis)提供接口。当然,那种专门做后台,经常跟数据打交道的Java猿友除外,因此只能说大部分。
如果还是继续保持这样的状态的话,下次自己找工作遇到SQL笔试题,估计也会继续懵逼(大写的)。
下面小宝鸽整理了一些实例(实例主要来自网上),以提升自己写SQL的某些关键字的理解。
1、用一条SQL 语句 查询出每门课都大于80 分的学生姓名。(表结构如下图)
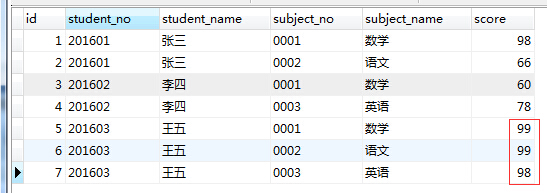
答案可以有如下两种:
select distinct student_name from table_test_one where student_name not in
(select distinct student_name from table_test_one where score<=80);或者
select student_name from table_test_one group by student_name having min(score)>80;第二种方法是group by 、min函数 结合 having的使用,w3school教程里面也提到过(在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与合计函数一起使用)
似乎看懂了,但是还是没有自己运行一遍深刻!!!自己能动手敲一遍就更好了!
下面我们自己造数据,后面的例子也会用到。
建表然后倒入初始数据:
DROP TABLE IF EXISTS `table_test_one`;
CREATE TABLE `table_test_one` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`student_no` varchar(10) NOT NULL,
`student_name` varchar(10) NOT NULL,
`subject_no` varchar(10) NOT NULL,
`subject_name` varchar(10) NOT NULL,
`score` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8;INSERT INTO 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1046
1046











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









