






词法分析是编译程序第一个阶段,它的主要任务是从左到右逐个字符地对源程序进行扫描,产生一个个单词序列,用于语法分析,执行词法分析的程序称为词法分析程序或扫描程序,本章我们将讨论词法分析程序的设计原理,单词的描述技术,识别机制及词法分析程序的自动构造原理。
词法分析程序的设计
词法分析程序与语法分析程序的接口方式
词法分析程序完成的是编译程序第一阶段的工作,词法分析工作可以独立的一遍,把字符流的源程序变成单词序列,输出在一个中间文件上,这个文件成为语法分析程序的输入而继续进行编译过程。然而,更一般的情况,常将词法分析程序设计成一个子程序,每当语法分析程序需要一个单词时,就调用这个子程序,而词法分析程序每得到一次调用,便从源程序文件中读入一些字符,直到识别出一个单词,或说直到下一个单词的第一字符为止,这种设计方案中,词法分析程序和语法分析程序是放在同一遍中,而省掉了中间文件
词法分析程序的输出
词法分析程序的功能是读取源程序,输出单个的单词符号。单词符号是一个程序设计语言的基本语法符号,程序设计语言的单词符号基本上可以分为5种
关键字
标识符
常数
运算符
界符
词法分析程序所输出的单词符号常常采用以下的二元式表示,单词的种别是语法分析程序需要的信息,而单词本身的值是编译程序其他阶段需要的信息,有时,对于某些单词而言,不仅仅需要它的值,还需要其他一些信息以便编译进行,比如,对于标识符,还需要记载它的类别,层次还有其他属性,如果这些属性统统在符号表中,则可以将单词的二元式表示设计成如下形式(标识符,指向该标识符所在符号表中位置的指针)
词法分析工作分离的考虑
按说,词法也是语法的一部分,词法描述完全可以归并到语法描述中,只不过词法规则更简单,在后面的章节中,可以看出,为什么将词法分析作为一个独立的阶段,为什么把编译过程的分析工作划分成词法分析和语法分析两个阶段,主要考虑下列因素。
使整个编译程序的结构更简洁,清晰和条理化,
编译程序的效率会改进;
增加程序的可移植性
词法分析程序的主要功能是从字符流的源程序中识别单词,它要从左到右逐个字符地扫描源程序,因此还可以完成其他的一些任务,比如,滤过程序的注释与空白,(由制表符,空格,回车换行引起的空白),又比如,为了使编译程序能将发现的错误信息与源程序的出错位置联系起来,词法分析程序负责记录新读入的字符行的行号,以便将行号与出错信息相连,再有,在支持宏处理的源语言中,可以由词法分析程序完成其预处理,很多工作与源程序的具体要求以及编译程序的整个设计有关,不一一列举。
单词的描述工具
程序设计语言中的单词的基本语法符号,单词符号的语法分析可以用有效的工具加以描述,并且这种描述工具,可以建立词法分析程序,进而建立词法分析程序的自动构造方法,多数程序设计语言的单词的语法都能用正规文法或3型文法来描述
正规文法

最复杂的一类单词要属于无符号实数,比如25.55e+2和2.1
正规式
正规式也称为正规表达式,也是表示正规集的工具,也是我们用以描述单词符号的方便工具。
下面是正规式和它所表示的正规集的递归定义。

注意,闭包即为任意有限次非重复连接。
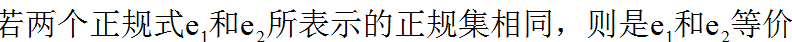
正规式满足的代数规律有交换律,结合律,分配律,空的连接,以及或的抽取律
程序设计语言的单词都能用正规式来定义,
正规文法和正规式的等价性
一个正规语言可以由正规文法定义,也可以由正规式定义,对任意一个正规文法,存在一个定义同一语言的正规式,反之,对于每一个正规式,存在一个生成同一语言的正规文法,有些正规语言很容易用文法定义,有些语言更容易用正规式来定义,本节将介绍两者之间的转换,从结构上建立两者之间的等价性。
有穷自动机
有穷自动机(也称为有限自动机)作为一种识别装置,它能准确识别正规集,即识别正规文法所定义的语言和正规式所表示的集合,引入有穷自动机这个理论,正是词法分析程序的自动构造寻找特殊的方法和工具。
有穷自动机分为两类,确定的有穷自动机和不确定的有穷自动机,下面我们分别给出确定的有穷自动机和不确定的有穷自动机定义,相关概念,及不确定有穷自动机的确定化,确定的有穷自动机的化简等算法。
确定的有穷自动机(DFA)
一个确定的有穷自动机M是一个五元组,
。。。。。。。。。。
对于字母表中的任何符号串t,若存在一条从初始结点到终态结点的道路,且这条道路上的所有弧的标记符连接成的符号串等于t,则称t为DFA M所接收,若M的初始结点同时等于终止结点,则空字符可以被M所识别。
DFA的确定性表现在转换函数f是一个单值符号,从状态转换图上来看,若字母表含有n个输入符号,那么任意一个状态结点最多有n个弧射出,而且每条弧以一个不同的输入符号标记。
不确定的有穷自动机(NFA)
一个不确定的有穷自动机M是一个五元组,
。。。。。。。
一个含有m个状态和n个输入符号的NFA可表示成如下的一张状态转换图,这张图有m个状态结点,每个结点可射出若干个箭弧与别的结点相连接,每条弧用字母表的克林闭包
中的一个串做标记,整张图至少含有一个初始结点以及若干个终态结点。
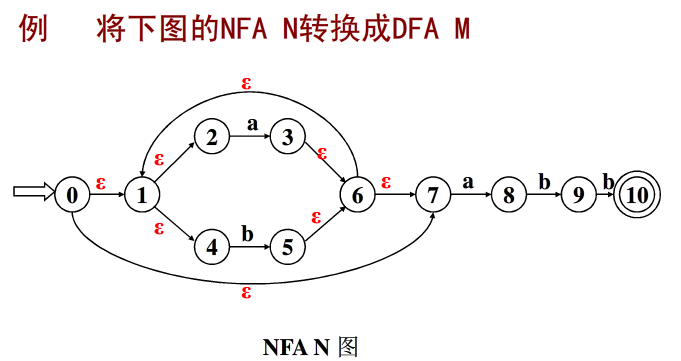
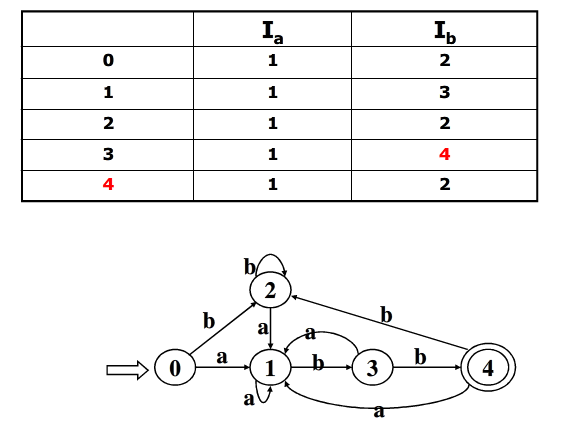
NFA转换为等价的DFA
在有穷自动机的理论中,有这样的定理,设L为一个不确定的有穷自动机接受的集合,则存在一个接受L的确定的有穷自动机。我们不对这个定理进行证明,而只介绍一种算法,将NFA转换为同样语言的DFA,这种算法称为子集法。
将NFA转换为DFA的精髓在于将集合转换为状态

确定的有穷自动机的化简
我们说一个有穷自动机是化简的,即是说,它没有多余的状态并且没有多余的状态并且它的状态中没有两个状态是互相等价的,一个有穷自动机可以确定通过消除无用状态和合并等价状态转换成一个最小的与之等价的有穷自动机。
所谓有穷自动机的无用状态,是指这样的状态,即从自动机的开始状态开始,任何输入串不能到达的那个状态,或者从这个状态没有通路到达的状态,对于给定的自动机,如果它含有无用状态,可以非常简单的将无用状态消除,而得到与之等价的有穷机。
在有穷自动机中,两个状态是等价的,如果满足条件:一致性条件和蔓延性条件。
一致性:状态s和t必须同时为可接受状态和不可接受状态
蔓延性:对于所有的输入符号,状态s和状态t必须转换为等价的状态里。
可以介绍一种分割的方法,将一个DFA中的状态分成一些不相交的子集,使得任何不同子集中的状态都是可区分的。
词法分析程序的自动构造工具
我们已经看到,正规式用于说明单词的结构十分清晰,而把一个正规式编译(或转换为)一个NFA进 而转换为响应的DFA.这个NFA或DFA正是识别该正规式所表示的语言的句子的识别器,基于这种方法构造的词法分析程序的工具很多,我们以LEX为例介绍如何从正规式产生识别该正规式所描述的单词的词法分析程序。
LEX是一个广泛使用的工具,unix使用lex命令调用。它用于构造各种各样语言的词法分析程序,我们称这种工具为LEX编译系统,它的源语言成为LEX语言,














 913
913











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









