







<input type="text" name="" onkeyup="regExp =/[^a-z]/g;this.value = this.value.replace(regExp,'')">
<!-- 引入jquery -->
<!-- <script type="text/javascript" src="./js/index.js"></script> -->
<script type="text/javascript">
// 测试 regexp
var test = new RegExp("zhuowenxuan");
// RegExp 对象方法
// 1:: complie 编译正则表达式,把正则表达式编译为内部格式
// 2:exec 检测字符串中制定的值,返回找到的值,并确定其位置
// 3:test 检索字符串中是否存在模式 ,返回true 或 false
var str ="abc123";
var regExp = /[a-z]+/;
var regExp2 = /[0-9]+/;
regExp.compile("[0-9]+");
console.log(regExp2.exec(str));
console.log(regExp);
console.log(regExp.test("1"));
// RegExp 修饰符
// 1:i 设置匹配对大小写不敏感
// 2:g 设置匹配为全局 ,类似查找所有
// 3:m 设置多行匹配
var str = "ABCabc";
var regExp3 = /[a-z]/i;
console.log(regExp3.exec(str));
var regExp4 = new RegExp("[a-z]","i");
console.log(regExp4.exec(str));
var str5 ="a123a123A";
var regExp5 = new RegExp("[a-z]","gi");
console.log(str5.replace(regExp5,"zhuowenxuan"));
// 两个特殊的符号
// ^ 指出一个字符串开始
// $ 指出一个字符串结束
// ^$ 中间检测的字符串就是唯一的
var str6 = "a0";
var regExp6 = new RegExp("^a0$");
console.log(str6.replace(regExp6,"h"));
// 方括号
// 用于超找某个范围内的字符
// /[hello]/ 匹配hello
// /[^hello]/ 匹配不是hello的
// /^[0-9]$/ 匹配 0-9 的数字
// /^[a-z]$/ 匹配a-z 的字母
// 预定义类
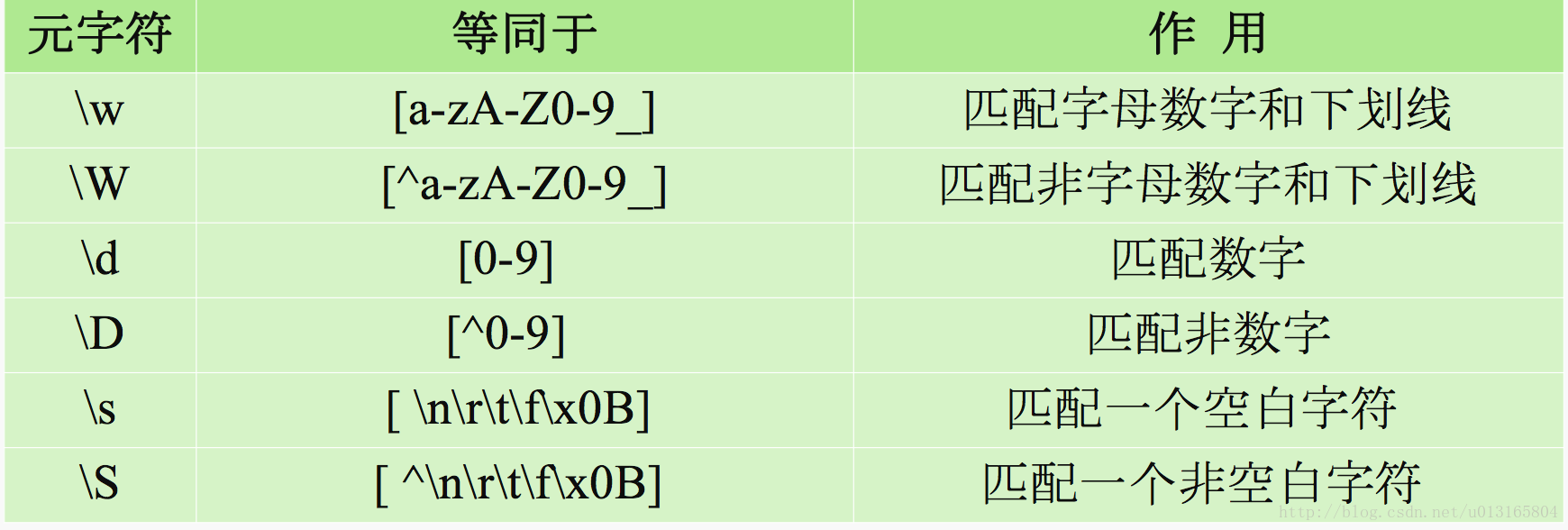
// 元字符 等同于 作用
// \w [a-zA-Z0-9_] 匹配字母数字下划线
// \W [^a-zA-z0-9)_] 匹配非字母数字下划线
// \d [0-9] 匹配数字
// \D [^0-9] 匹配非数字
// \s [\n\r\f\X0B] 匹配一个空白字符
// \S [^\n\r\t\f\x0B] 匹配一个非空白字符
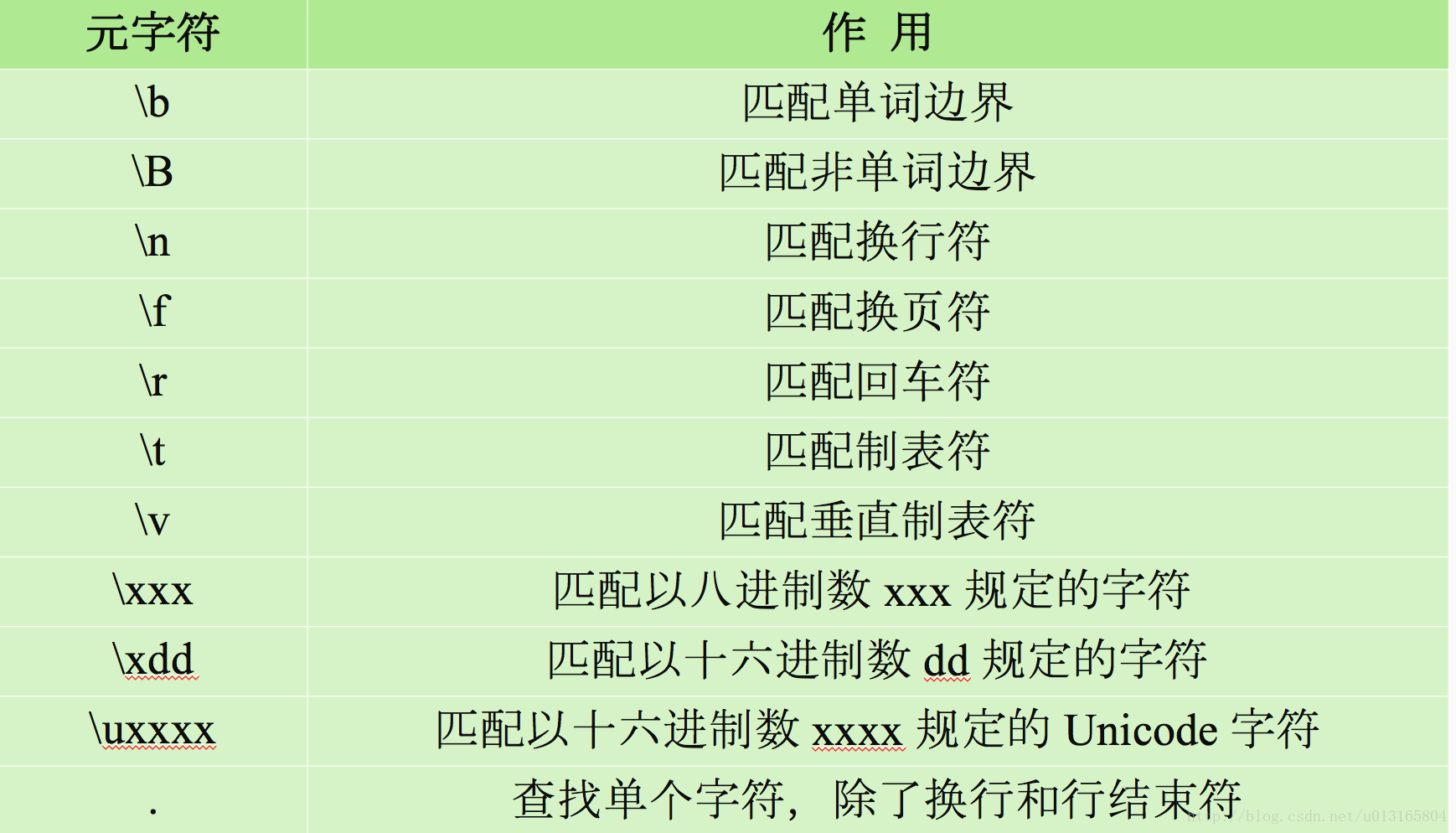
// \b 匹配单词边界
// \B 匹配非单词边界
// \n 匹配换行符
// \f 匹配换页符
// \r 匹配回车符
// \t 匹配制表符
// \v 匹配垂直制表符
// \xxx 匹配以八进制数XXX规定的字符
// \xdd 匹配以十六进制数dd规定的字符
// \uxxxx 匹配以十六进制数xxxx规定的Unicode字符
// . 查找单个字符 除了换行和行结束符号
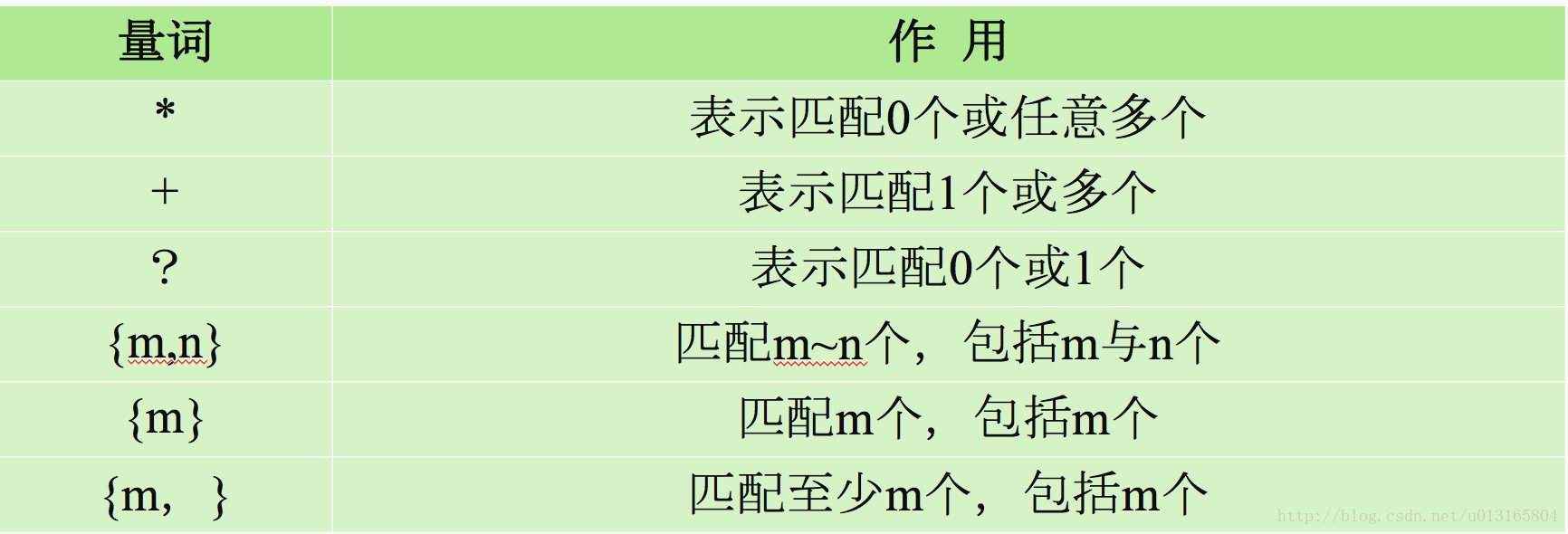
// 量词
// * 表示匹配0个或者任意多个
// + 表示匹配一个或多个
// ? 表示匹配1个或多个
// {m,n} 匹配m-n个 ,包括m于n个
// {m} 匹配m个 包括m个
// {m,} 匹配至少m个, 包括m个
//其他
//?=n 匹配任何其后紧接指定字符串n的字符串
//?!n 匹配任何其后紧接没有指定字符串n的字符串
//()+ 匹配至少一个模式
// | 或的模式匹配
// (.*) 替代字符,除了换行和行结束符
// (.*?) 惰性模式 ,上一个为贪婪模式
// $1-$... 获取替代字符查找到的字符串


分组 语法:()

(\d{4})-(\d{1,2}-(\d\d?))匹配 2019-04-22 的结果

命名捕获组
/(?<year>\d{4})-(?<month>\d{1,2}-(?<day>\d\d?))/ig.exec("2015-10-10").groups
分支结构(Alternation)
语法 |
/a|b|c/.exec('abc')
当一个字符串的某一子串具有多种可能时,采用分支结构来匹配.
“|”表示多个子表达式之间或的关系,“|”可以用()限定范围的
如果在“|”的左右两侧没有()来限定范围,那么它的作用范围即为“|”左右两侧整体

反向引用
语法: \n (n代表捕获位置)
/(\d)\1/
- 捕获组捕获到的内容,不仅可以在正则表达式外部通过程序进行引用,也可以在正则表达式内部进行引用,这种引用方式就是反向引用。
- 能在正则表达式内部使用的引用只有『反向引用』,其格式为+数字 ,通常用于匹配不同位置相同部分的子串
将字符串中连续出现的多个相同字符替换为一个。如:将aaaabbbccd替换为abcd
'aaaabbbcccd'.replace(/(\w)\1+/ig, '$1');
环视( Lookaround )
环视只进行子表达式的匹配,不占有字符,匹配到的内容不保存到最终 的匹配结果,是零宽度的。环视匹配的最终结果就是一个位置。
环视按照方向划分有顺序和逆序两种,按照是否匹配有肯定和否定两种,组合起来就有四种环视。

环视( Lookaround )-示例
- 获取不带后缀的文件名(test.html)
/.*(?=\.html)/ - 获取Url参数中的值(key=360)
/(?<=key=).+/ - 将数字转换为美元(3000转换为3,000)
/(?<=\d)(?=(\d{3})+($|\.))/
转义字符 \
^ $ . * + ? | \ / ( ) [ ] { } = ! : - ,
比如字符串如:$1,000 正则表达式如下:
/\$[\d,]/.exec('$1,000')

四种操作
验证 切分 提取 替换
//验证begin
//使用search
var regex = /\d/;
var string = "love360";
console.log( !!~string.search(regex) );
// => true
//使用test
var regex = /\d/;
var string = "love360";
console.log( regex.test(string) );
// => true
//使用match
var regex = /\d/;
var string = "love360";
console.log( !!string.match(regex) );
// => true
//使用exec
var regex = /\d/;
var string = "love360";
console.log( !!regex.exec(string) );
// => true
//验证end
//切分
var regex = /\D/;
console.log( "2019/04/22".split(regex) );
console.log( "2019.04.22".split(regex) );
console.log( "2019-04-22".split(regex) );
// => ["2019", "04", "22"]
// => ["2019", "04", "22"]
// => ["2019", "04", "22"]
//提取
var regex = /^(\d{4})\D(\d{2})\D(\d{2})$/;
var string = "2019-04-22";
console.log( string.match(regex) );
// =>["2019-04-22", "2019", "04", "22", index: 0, input: "2019-04-22"]
//替换
var string = "2019-04-22";
var today = string.replace(/-/g, "/");
console.log( today );
var string = "2019-04-22";
string = string.replace(/(\d+)-(\d+)-(\d+)/g, function(m, m1, m2, m3){
return `${m1}年${m2}月${m3}日`
});
console.log(string);
//=> 2019年04月22日
匹配原理
正则引擎
- 一般分为两种类型 DFA和NFA
- NFA分为传统NFA和POSIX NFA
- POSIX NFA主要指符合POSIX标准的NFA引擎,它的特点主要是longest-leftmost匹配,也就是在找到最左侧最长匹配之前,它将继续回溯
- 非贪婪模式或者说忽略优先量词对于POSIX NFA同样是没有意义的

- 占有字符&零宽度
- 控制权&传动
- 回溯
占有字符&零宽度

控制权&传动
- 第一子表达式获取控制权,从字符串的某一位置开始尝试匹配。
- 下一子表达式从前一表达式成功的位置再开始匹配
- 对于整个表达式来说,通常是由字符串位置0开始尝试匹配的
- 如果在位置0开始的尝试,匹配到字符串某一位置时整个表达式匹配失败,那么引擎会使正则向前传动,整个表达式从位置1开始重新尝试匹配,依此类推,直到报告匹配成功或尝试到最后一个位置后报告匹配失败。
回溯
- NFA引擎最重要的性质是,它会依次处理各子表达式或组成元素,遇到需要在成功的可能中进行选择的时候,它会选择其一,同时记住另一个,以备稍候可能的需要。
- 两种需要做出选择的情形: 量词(是否尝试再次匹配)&条件分支(优先匹配哪个分支)
- 不管选择哪一种途径,如果匹配成功,并且其后的正则表达式也匹配成功,匹配宣告完成。如果其后的表达式最终匹配失败,引擎会知道需要回溯到之前做出选择的地方,选择备用分支继续尝试。直到匹配完表达式的所有可能途径
匹配优先量词

忽略优先量词

回溯-练习

开题正则解密
题目:密码长度6-12位,由数字、小写字符和大写字母组成,但必须至少包括2种字符
- step1、不考虑“但必须至少包括2种字符”这一条件
let reg = /^[0-9A-Za-z]{6,12}$/ - step2、判断是否包含有某一种字符
reg = /(?=.*[0-9])^[0-9A-Za-z]{6,12}$/; - step3、最终版本。
- 同时包含数字和小写字母
- 同时包含数字和大写字母
- 同时包含数字和大写字母
- 同时包含数字、小写字母和大写字母
var reg = /((?=.*[0-9])(?=.*[a-z])|(?=.*[0-9])(?=.*[A-Z])|(?=.*[a-z])(?=.*[A-Z]))^[0-9A-Za-z]{6,12}$/;
console.log( reg.test("1234567") ); // false 全是数字
console.log( reg.test("abcdef") ); // false 全是小写字母
console.log( reg.test("ABCDEFGH") ); // false 全是大写字母
console.log( reg.test("ab23C") ); // false 不足6位
console.log( reg.test("ABCDEF234") ); // true 大写字母和数字
console.log( reg.test("abcdEF234") ); // true 三者都有
技术书籍推荐
精通正则表达式















 1447
1447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









