







简述
- 每一步都做出当时看起来最佳选择,希望局部最优解导致全局最优解。
- 贪心算法不保证得到最优解,但是很多问题确实可以得到最优解。.
贪心算法设计步骤:
- 确定问题的最优子结构,最优解包含子问题的最优解
- 设计一个递归算法。
- 证明如果我们做出一个贪心选择,则只剩下一个子问题
- 证明贪心选择总是安全的(步骤 3、4 的顺序可以调换)。
- 设计一个递归算法实现贪心策略。
- 将递归算法转换为迭代算法。
赫夫曼编码
使用贪心算法压缩文件数据,节省20%-90%空间。可以用不同的方法表示文件信息,下表使用了二进制编码表示。一个100000个字符的文件,定长编码压缩成300000个二进制位,变长编码压缩成224000个二进制位。
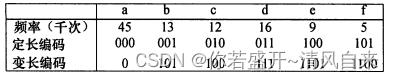
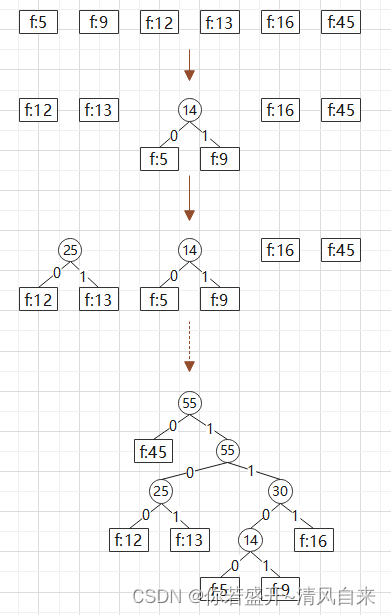
使用贪心方法构建二叉树,每次合并最小的两个节点生成父节点,左孩子为0,右孩子为1,最终从根节点到个也子节点的路径即为对应字符的二进制编码。
package s23;
import java.util.Comparator;
import java.util.TreeSet;
public class Huffman {
class Node{
Node left; //左孩子
Node right; //右孩子
String character; //字符串
Integer frequency; //频率
private Node(){}
private Node(Node left,Node right,Integer frequency, String character){
this.left = left;
this.right = right;
this.frequency = frequency;
this.character = character;
}
}
private Node head;
private TreeSet<Node> originalSet;
//初始化,原始数据按字符频率升序
public Huffman(){
originalSet = new TreeSet<>(new Comparator<Node>() {
@Override
public int compare(Node o1, Node o2) {
return o1.frequency - o2.frequency;
}
});
}
//添加字符及其频率
public void add(String key,Integer frequency){
Node node = new Node(null,null,frequency,key);
originalSet.add(node);
}
//生成树
public void generate(){
while(!originalSet.isEmpty()) {
//贪心算法,前两个最小的节点出队列
Node node1 = originalSet.pollFirst();
Node node2 = originalSet.pollFirst();
if(node2==null) {//最后一个节点出队列,即根节点
head = node1;
return;
}
//节点相加,加入队列,自动排序
Node sumNode = new Node(node1,node2, node1.frequency+node2.frequency,null);
originalSet.add(sumNode);
}
}
public void printAll(){
print(head,"");
}
private void print(Node node,String str){
//递归遍历打印,左孩子为0,右孩子为1,叶子节点没有孩子即最终字符
if(node.left != null){
String lStr = str + "0";
print(node.left,lStr);
}
if(node.right != null){
String rStr = str + "1";
print(node.right,rStr);
}
if(node.left == null && node.right == null)
System.out.println(node.character + ":" + str);
}
public static void main(String[] args) {
Huffman huffman = new Huffman();
huffman.add("a",45);
huffman.add("b",13);
huffman.add("c",12);
huffman.add("d",16);
huffman.add("e",9);
huffman.add("f",5);
huffman.generate();
huffman.printAll();
/*
a:0
c:100
b:101
f:1100
e:1101
d:111
*/
}
}
拟阵
一个拟阵就是一个满足如下条件的序偶M=(S,I)
- S是一个有限集。
- I是S的子集的一个非空族,这些子集称为 S 的独立子集,使得如果 B∈I且A⊆B,则A∈I。如果I满足此性质,则称之为遗传的。注意,空集必然是I的成员。
- 若A∈I、B∈I且|A|<|B|,那么存在某个元素x∈B-A,使得AU(x)∈I,则称M满足交换性质。
最小生成树
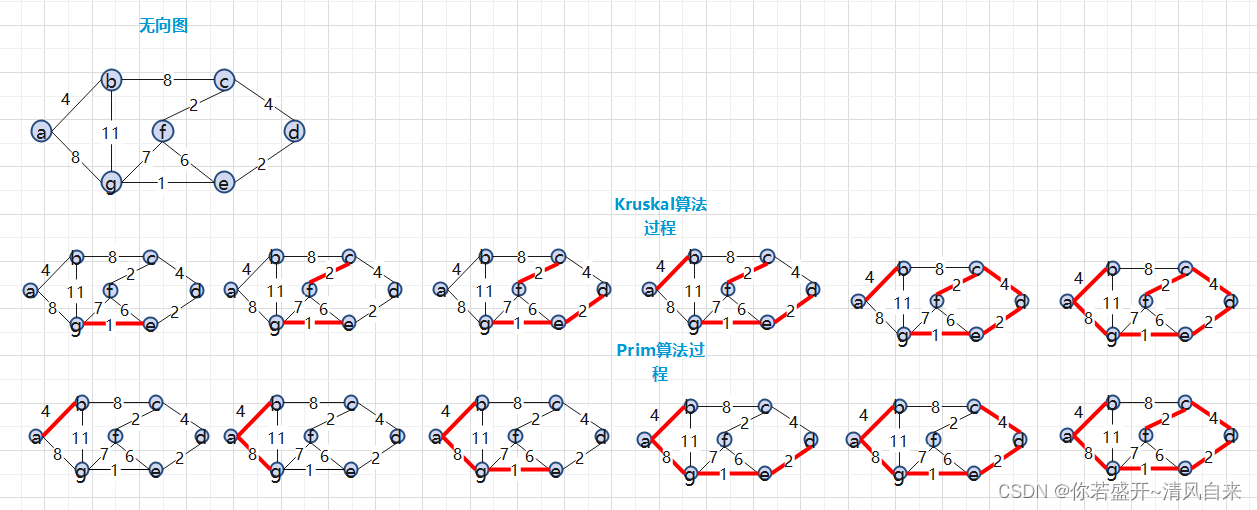
Kruskal算法:每次选择一条权重最小的边
Prim算法:选定开始节点,保证后续每一步已选节点都是一颗树,确保下一步选择的节点到已选树的边权重最小
package s23;
import java.util.*;
import java.util.function.BiConsumer;
public class MinimumTree {
class Edge{ //边
private Character node1; //节点1
private Character node2; //节点2
private Integer wight; //权重
private Edge(Character node1,Character node2, Integer wight){
this.node1 = node1;
this.node2 = node2;
this.wight = wight;
}
}
LinkedHashMap<Character, TreeSet<Edge>> graph; //图链表,节点内按权重排序边
ArrayList<Edge> edgeList; //边集
HashSet<Character> nodeSet; //节点集
public MinimumTree(LinkedHashMap<Character, HashMap<Character,Integer>> graph){
nodeSet = new HashSet<>();
edgeList = new ArrayList<>();
this.graph = new LinkedHashMap<>();
//迭代树链表
Iterator<Map.Entry<Character,HashMap<Character,Integer>>> itr = graph.entrySet().iterator();
while(itr.hasNext()){
Map.Entry<Character,HashMap<Character,Integer>> entry = itr.next();
//每个节点的边集,按权重升序
TreeSet<Edge> treeSet = new TreeSet<>(new Comparator<Edge>() {
@Override
public int compare(Edge o1, Edge o2) {
return o1.wight - o2.wight;
}
});
entry.getValue().forEach(new BiConsumer<Character, Integer>() {
@Override
public void accept(Character character, Integer integer) {
Edge edge = new Edge(entry.getKey(),character,integer);
treeSet.add(edge);
if(!nodeSet.contains(character)) //边集,排除反向,如ab已归集,排除ba
edgeList.add(edge);
}
});
this.graph.put(entry.getKey(),treeSet);
nodeSet.add(entry.getKey());
}
}
public void kruskal(){
//边集排序
Collections.sort(edgeList, new Comparator<Edge>() {
@Override
public int compare(Edge o1, Edge o2) {
return o1.wight-o2.wight;
}
});
LinkedHashMap<Character,TreeMap<Character,Integer>> minTree = new LinkedHashMap<>();//最小树链表
HashSet<StringBuffer> treeEdge = new HashSet<>();
List<HashSet<Character>> forest = new ArrayList<>(); //森林节点集,最终所有节点归集到forest[0]
edgeList.forEach(edge -> {
HashSet<Character> cList = new HashSet<>();
cList.add(edge.node1);
cList.add(edge.node2);
boolean flag = true; //判断当前边是否归集
boolean flag1 = true; //判断当前边的一个节点是否已包含在森林中,如果在加入对应森林,否则构建新森林
for(int i = 0; i < forest.size(); i++) {
//如果边的两个节点都属于每个森林,则舍弃
if (forest.get(i).contains(edge.node1) && forest.get(i).contains(edge.node2)) {
flag = false;
flag1 = false;
break;
}
if (forest.get(i).contains(edge.node1) || forest.get(i).contains(edge.node2)) {
if (i != 0 && (forest.get(0).contains(edge.node1) || forest.get(0).contains(edge.node2))) {
//将后面的森林归集到forest[0]中
forest.get(0).addAll(forest.get(i));
forest.remove(i);
} else
forest.get(i).addAll(cList);
flag1 = false;
}
}
if (flag1)//构建新森林
forest.add(cList);
if(flag) { //构建最小树链表
TreeMap<Character, Integer> treeMap;
if (minTree.containsKey(edge.node1)) {
treeMap = minTree.get(edge.node1);
} else {
treeMap = new TreeMap<>();
minTree.put(edge.node1, treeMap);
}
treeMap.put(edge.node2, edge.wight);
}
});
System.out.println("------------kruskal算法-----------");
minTree.forEach((key,value)->{
value.forEach((subKey,subValue)->{
System.out.println("[" + key + "-" + subKey + ":" + subValue + "]");
});
});
}
public void prim(){
LinkedHashMap<Character,TreeMap<Character,Integer>> minTree = new LinkedHashMap<>();//最小树链表
ArrayList<Character> treeNode = new ArrayList<>(); //节点集
treeNode.add('a');//第一个节点
while(treeNode.size() < graph.size()){ //存在节点未归集
Edge min = null;
for(Character c:treeNode){ //循环当前树中节点,找到权重最小的边
//删除已包含的边
while(!graph.get(c).isEmpty() && treeNode.contains(graph.get(c).first().node2) && treeNode.contains(c))
graph.get(c).pollFirst();
if(graph.get(c).size()!=0) { //比较每个节点未归集的最小边
if (min == null)
min = graph.get(c).first();
else {
if (graph.get(c).first().wight < min.wight)
min = graph.get(c).first();
}
}
}
//最小边节点归集
if(!treeNode.contains(min.node1))
treeNode.add(min.node1);
if(!treeNode.contains(min.node2))
treeNode.add(min.node2);
//构建最小树
TreeMap<Character,Integer> treeMap;
if(minTree.containsKey(min.node1)){
treeMap = minTree.get(min.node1);
}else {
treeMap = new TreeMap<>();
minTree.put(min.node1, treeMap);
}
treeMap.put(min.node2, min.wight);
}
System.out.println("------------prim算法-----------");
minTree.forEach((key,value)->{
value.forEach((subKey,subValue)->{
System.out.println("[" + key + "-" + subKey + ":" + subValue + "]");
});
});
}
public void buildLinkedTable(Character character,Integer integer){
}
public static void main(String[] args) {
LinkedHashMap<Character, HashMap<Character,Integer>> graph = new LinkedHashMap<>();
HashMap<Character,Integer> map = new HashMap<>();
map.put('b',4);
map.put('g',8);
graph.put('a',map);
HashMap<Character,Integer> map1 = new HashMap<>();
map1.put('a',4);
map1.put('c',8);
map1.put('g',11);
graph.put('b',map1);
HashMap<Character,Integer> map2 = new HashMap<>();
map2.put('b',8);
map2.put('d',4);
map2.put('f',2);
graph.put('c',map2);
HashMap<Character,Integer> map3 = new HashMap<>();
map3.put('c',4);
map3.put('e',2);
graph.put('d',map3);
HashMap<Character,Integer> map4 = new HashMap<>();
map4.put('d',2);
map4.put('f',6);
map4.put('g',1);
graph.put('e',map4);
HashMap<Character,Integer> map5 = new HashMap<>();
map5.put('c',2);
map5.put('e',6);
map5.put('g',7);
graph.put('f',map5);
HashMap<Character,Integer> map6 = new HashMap<>();
map6.put('a',8);
map6.put('b',11);
map6.put('f',7);
map6.put('e',1);
graph.put('g',map6);
MinimumTree minimumTree = new MinimumTree(graph);
minimumTree.prim();
minimumTree.kruskal();
}
}
输出
------------prim算法-----------
[a-b:4]
[a-g:8]
[g-e:1]
[e-d:2]
[d-c:4]
[c-f:2]
------------kruskal算法-----------
[e-g:1]
[c-d:4]
[c-f:2]
[d-e:2]
[a-b:4]
[a-g:8]
















 7260
7260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









