









PySpark入门:键值对RDD操作
RDD基本转换运算
创建RDD最简单的方式是使用SparkContext的parallelize方法
intRDD=sc.parallelize([3,1,2,5,5])
intRDD.collect()由于spark的惰性,转化操作并不会马上执行,而collect()是一个“动作”,spark立刻执行,RDD转换为list
关于collect,在shell环境可以直接显示结果,在eclipse中需要用print 将其打印
[3, 1, 2, 5, 5]
stringRDD=sc.parallelize({"Apple","Orange","Banana","Grape"})
stringRDD.collect()
['Orange', 'Grape', 'Banana', 'Apple']map
map运算使用具体函数
intRDD=sc.parallelize([3,1,2,5,5])
def add1(x):
return (x+1)
intRDD.map(add1).collect()map 是一个转化运算,命令将每一个元素加上1,生成新的RDD
map运算使用匿名函数
intRDD.map(lambda x:x+1).collect()两种方法结果相同
[4, 2, 3, 6, 6]
对stringRDD所有字符串元素前面加上“fruit”,产生新的RDD
stringRDD.map(lambda x:"fruit:"+x).collect()
['fruit:Orange', 'fruit:Grape', 'fruit:Apple', 'fruit:Banana']
filter
intRDD.filter(lambda x:x<3).collect()
intRDD.filter(lambda x:x>3).collect()
intRDD.filter(lambda x:x<3 or x>=5).collect()其功能如其名,筛选过滤
stringRDD.filter(lambda x:"ra"in x).collect()['Orange', 'Grape']
distinct
删除重复的元素
intRDD.distinct().collect()[1, 2, 3, 5]
randomSplit
sRDD=intRDD.randomSplit([0.4,0.6])
sRDD[0].collect()
sRDD[1].collect()将整个集合元素以随机数的方式按比例分为多个RDD
[1, 2, 5]
[3, 5]
groupBy
gRDD=intRDD.groupBy(lambda x:"even"if(x%2==0)else "odd").collect()
print(gRDD[0][0],sorted(gRDD[0][1]))('even', [2])
产生了奇数与偶数两个list。
对一个RDD的操作总结如下:

多个RDD转换运算
intRDD1=sc.parallelize([3,1,2,5,5])
intRDD2=sc.parallelize([5,6])
intRDD3=sc.parallelize([2,7])
intRDD1.union(intRDD2).union(intRDD3).collect()使用union函数进行并集运算
[3, 1, 2, 5, 5, 5, 6, 2, 7]
intRDD1.intersection(intRDD2).collect()intersection交集运算
[5]
intRDD1.subtract(intRDD2).collect()subtract差集运算
[2, 1, 3]
intRDD1.cartesian(intRDD2).collect()cartesian笛卡儿积运算
[(3, 5), (3, 6), (1, 5), (1, 6), (2, 5), (2, 6), (5, 5), (5, 6), (5, 5), (5, 6)]
对多个RDD的操作总结如下:

RDD基本动作运算
intRDD.first()
intRDD.take(2)
intRDD.takeOrdered(3)
intRDD.takeOrdered(3,key=lambda x:-x)1.取出第一项元素
2.去除第二项数据
3.从小到大排序,取出前三项
4.从大到小排序,取出前三项
intRDD.stats()得到统计结果
(count: 5, mean: 3.2, stdev: 1.6, max: 5.0, min: 1.0)
对一个RDD的行动总结如下:
 RDD Key-Value 基本转换运算
RDD Key-Value 基本转换运算
kvRDD1=sc.parallelize([(3,4),(3,6),(5,6),(1,2)])
kvRDD1.keys().collect()
kvRDD1.values().collect()列出全部的key值
[3, 3, 5, 1]
列出全部的value值
[4, 6, 6, 2]
kvRDD1.filter(lambda keyValue:keyValue[0]<5).collect()
kvRDD1.filter(lambda keyValue:keyValue[1]<5).collect()筛选key小于5
[(3, 4), (3, 6), (1, 2)]
筛选value小于5
[(3, 4), (1, 2)]
kvRDD1.mapValues(lambda x:x*x).collect()对RDD内每一组keyvalue进行运算,并产生另外一个RDD
[(3, 16), (3, 36), (5, 36), (1, 4)]
kvRDD1.sortByKey(ascending=True).collect()按照key排序,传入参数默认为true,从小到大排序
[(1, 2), (3, 4), (3, 6), (5, 6)]
kvRDD1.sortByKey(ascending=False).collect()从大到小排序
[(5, 6), (3, 4), (3, 6), (1, 2)]
kvRDD1.reduceByKey(lambda x,y:x+y).collect()按照key值进行reduce运算,将相同key的数据value合并,合并后产生新的RDD
[(1, 2), (3, 10), (5, 6)]
多个RDD Key-Value 基本转换运算
创建RDD
kvRDD1=sc.parallelize([(3,4),(3,6),(5,6),(1,2)])
kvRDD2=sc.parallelize([(3,8)])keyvalueRDD join
kvRDD1.join(kvRDD2).collect()[(3, (4, 8)), (3, (6, 8))]
leftOuterJoin
kvRDD1.leftOuterJoin(kvRDD2).collect()从左边的集合对应到右边的集合,显示所有左边集合中的元素
[(1, (2, None)), (3, (4, 8)), (3, (6, 8)), (5, (6, None))]
subtractByKey
kvRDD1.subtractByKey(kvRDD2).collect()删除key值相同的数据
[(1, 2), (5, 6)]
Key-Value 动作运算
kvRDD1.first()
kvRDD1.take(2)
kvFirst=kvRDD1.first()
kvFirst[0]获取第一个数据的第一个元素即Key值
kvFirst[1]获取第一个数据的第二个元素即Value值
kvRDD1.countByKey()计算每一个Key值得项数
defaultdict(int, {1: 1, 3: 2, 5: 1})
KV=kvRDD1.collectAsMap()创建kv字典
kvRDD1.lookup(3)输入key值来查找value
[4, 6]
Pair RDD的行动操作

Broadcast广播变量
广播变量使用规则:
1.可以使用SparkContext.broadcast创建
2.使用.value方法来读取广播变量的值
3.Broadcast广播变量被创建后不能修改
Broadcast广播变量的范例
kvFruit=sc.parallelize([(1,"apple"),(2,"orange"),(3,"banana"),(4,"grape")])
fruitMap=kvFruit.collectAsMap()
print"对照表:"+str(fruitMap)创建fruitMap字典
fruitMap=kvFruit.collectAsMap()
bcFruitMap=sc.broadcast(fruitMap)
print"字典:"+str(fruitMap)将fruitMap字典转化为转化为bcFriotMap广播变量
fruitIds=sc.parallelize([2,4,1,3])创建fruitIds
fruitNames=fruitIds.map(lambda x:bcFruitMap.value[x]).collect()
print str(fruitNames)使用bcFruitMap.value字典进行转换
['orange', 'grape', 'apple', 'banana']
accumulator累加器
在task中,例如foreach循环中,不能读取累加器的值
只有驱动程序,也就是循环外,才可以使用.value来读取累加器的值
total=sc.accumulator(0.0)
num=sc.accumulator(0)
intRDD.foreach(lambda i:[total.add(i),num.add(1)])
avg=total.value/num.value
print str(total.value)+" "+str(num.value),str(avg)
16.0 5 3.2
RDD持久化
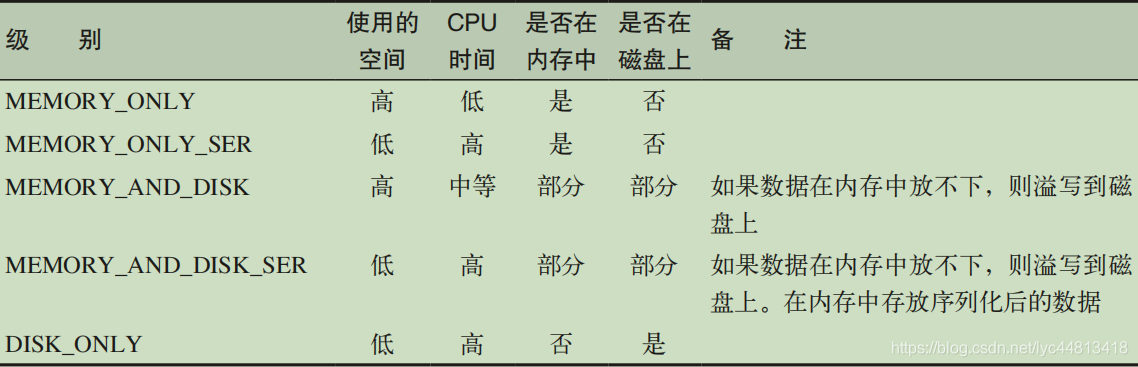
【转载】: https://blog.csdn.net/lyc44813418/article/details/86611402














 1725
1725











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









