






5.个性化性能指南
本文的目前是帮助客户再给定的NVMe系统中实现最佳的总体性能,而不是每个设备的最大可能性能。优化NVMe子系统的整体性能需要仔细的预分析,并综合考虑实际应用中的多个因素及其相互作用,本节讨论了这些因素以及如何利用它们来最大化性能。
5.1 CPU和NVMe分配
为特定的I/O操作配置IO深度或队列深度取决于NVMe设备本身,因为厂商已经优化他们的控制器架构和固件以实现和维持最高的性能。一些NVMe设备可能具有更高的队列深度能力,允许更多并发的I/O操作,而其他设备可能具有较低的队列深度限制。建议从厂商提供的推荐设置开始,逐渐增加或减少线程和I/O深度的数量,找到最大化性能的配置。
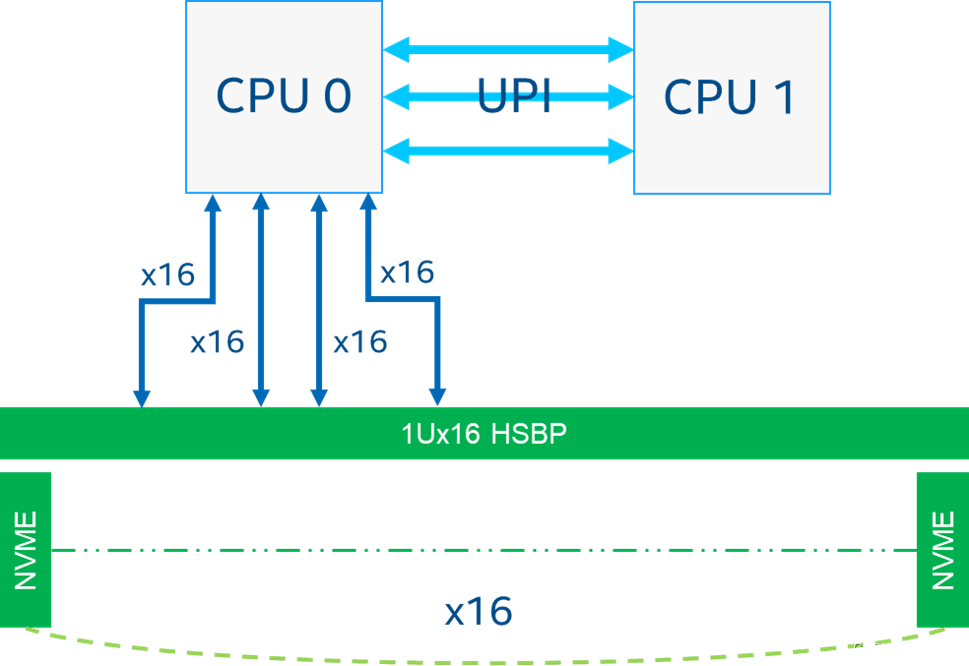
建议我们将CPU核心分配到访问NVMe设备相同的socket,避免远程socket访问。由于libaio是中断驱动的,并且需要对提交队列和完成队列进行内存复制,因此通过将具有相同缓存的CPU核心分配给它来最小化缓存到缓存的延迟,进一步提高性能(例如最佳分配给将基于主/兄弟核心对)。
这可以在FIO作业中进行配置,例如,对于一个由16个NVMe设备组成的并发读取作业,挂载在Socket0上,使用4K随机读模式,厂商建议使用8个线程和IO深度为64来实现最佳性能。
[global]
ioengine=libaio
direct=1
time_based=1
bs=4k
numjobs=8
iodepth=64
rw=randread
ramp_time=60
runtime=300
thread=1
norandommap
cpus_allowed_policy=split
group_reporting=1
[nvme0n1]
new_group
filename=/dev/nvme0n1
cpus_allowed=0-3,112-115
[nvme1n1]
new_group
filename=/dev/nvme1n1
cpus_allowed=4-7,116-119
… [nvme11n1]
new_group
filename=/dev/nvme11n1
cpus_allowed=44-47,156-159
[nvme12n1]
new_group
filename=/dev/nvme12n1
cpus_allowed=48-51,160-163
[nvme13n1]
new_group
filename=/dev/nvme13n1
cpus_allowed=52-55,164-167
[nvme14n1]
new_group
filename=/dev/nvme14n1
cpus_allowed=56-59,168-171
[nvme15n1]
new_group
filename=/dev/nvme15n1
cpus_allowed=60-63,172-175
5.2 NVMe聚合性能评估
5.2.1 初始化测试结果
如前面所述,操作系统和IO引擎libaio使用异步API允许应用程序与包括NVMe在内的块设备进行交互,得益于其灵活性和较高的性能。测试结果表明,当同时访问现代的Gen4 x4或Gen5 x4 NVMe设备时,每个设备可以产生数百万的IOPS,这可能会导致严重的性能限制。
在这个基准工作负载中,FIO将触发对最多16块NVMe设备并发访问,每个设备从随机地址读取4KB块大小,每个设备将从8个CPU核心接收I/O请求(如NVMe0n1核心数0-3,112-115;nvme1n1 4-7,116-119),并同时接收最多64个请求(iodepth=64),根据性能规格,预计每个NVMe设备在这个基准测试中可提供高达2M IOPS的性能(例如,每个设备的吞吐量应该达到系统主机缓存/内存子系统的8GBps).下图来自Intel的文档:
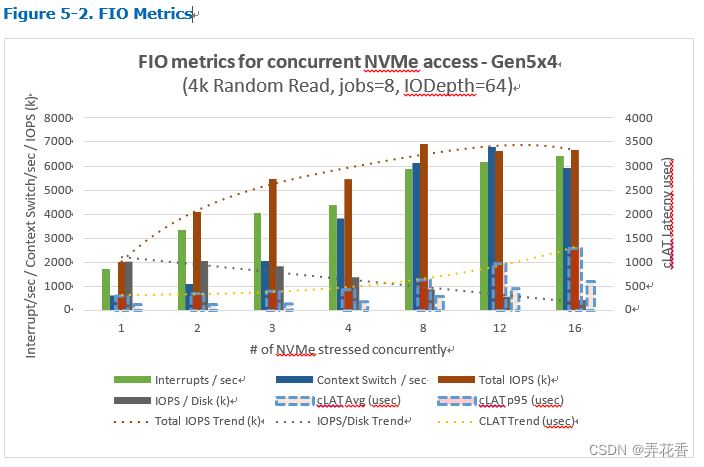
从上面的图表可以看出,当最多同时访问2个NVMe时,性能几乎成线性增长,对完成时延(cLAT平均值或cLAT p95)影响不大。但是,当同时访问3个或更多的NVMe Gen5 x4时,性能下降了,且系统的总IOPS在访问更多盘的提升很小。系统资源无法应对不断增加的I/O操作触发的系统调用、上下文切换和中断数量,导致性能达到了一个极限。增加更多的IO请求将进一步加重这些症状,并且每块盘的性能会受到相当大的影响。
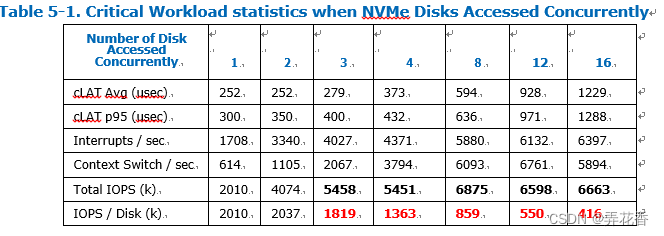
note:预计随着更多NVMe同时访问,系统处理更多I/O操作,一些资源可能会给耗尽,导致cLAT(完成延迟)会变得更糟。
5..2.2 减少MSI-X中断的数量
正如前面所述,每个NVMe设备有多个提交队列和完成队列对,大多数IO访问将接受多个CPU核心(根据FIO numjobs参数的定义)放置的条目,以最大化吞吐量。在现代处理器系统中,具有多个队列的能力允许每个处理器(核心)拥有一个提交队列和一个完成队列对。每个核心都有一对唯一的队列,使得驱动程序可以在处理I/O初始化和完成时不必担心其他处理器的竞争,并且几乎完全不需要获得和持有任何锁。NVMe强烈推荐使用MSI-X进行中断,这使得NVMe设备可以将中断定向到特定的核心。因此,在给定CPU核心上由NVMe驱动程序提交的请求将在同一CPU核心(或其兄弟核心)上产生表示其完成的中断。
这样,可以更有效地利用系统资源并减少中断开销。中断合并使得NVMe设备可以将多个中断合并到一个中断,从而使CPU的利用率更高,因为每个中断的处理需要花费一定的CPU时间和内存带宽。中断合并需要在NVMe驱动程序中进行配置。Linux NVMe驱动程序在/sys/class/nvme//interrupt、/sys/module/nvme_core/parameters/irq_poll 和 sys/class/nvme//features/interrupt_coalescing文件中提供了与此相关的设置,我们将在下面讨论这些文件和它们的使用。
在下面的章节中,我们将介绍如何使用中断合并来优化NVMe性能并减少中断开销。
5.3 调整Gen5 x4 NVMe设备上的中断计数聚合阈值
中断合并仅提供了2个参数:时间阈值和中断计数。默认的时间阈值是100微秒,也是最小值。在此研究中不会更改,因为我们的目的是首先减少由NVMe控制器生成的中断,同时最小化对cLAT延迟的影响。
表格中断合并——聚合阈值对IPOS / 硬盘的影响
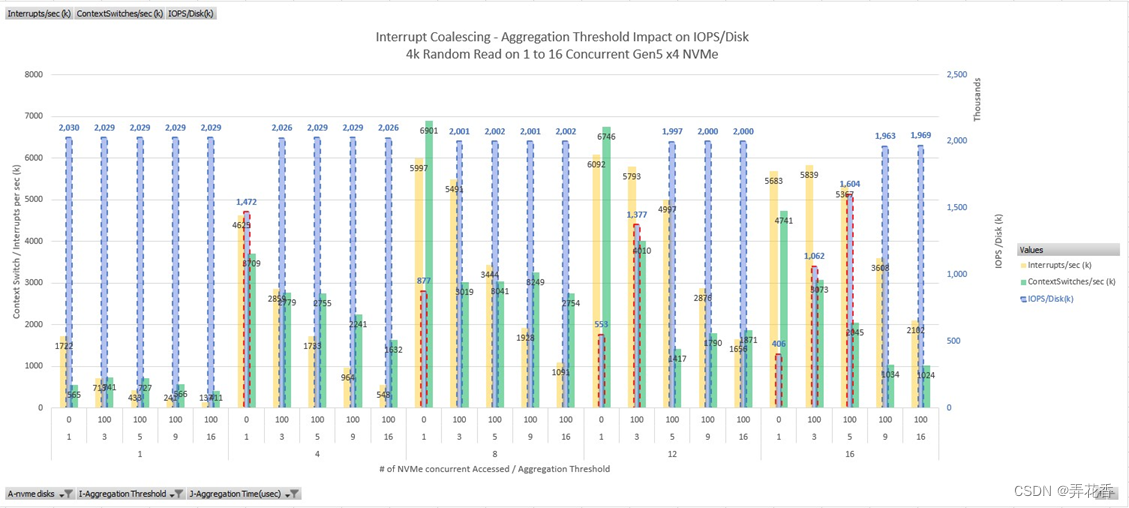
上图突出显示了工作负载期间MSI-X中断计数的显著降低,以及在这种高吞吐量场景下主要瓶颈的上下文切换的更显著降低。测试结果显示,对于8个NVMe设置中断聚合阈值为3就能足以恢复完整性能;而对于同时访问的12个或16个NVMe的4K随机读,需要将聚合阈值设置为5或9。采用更激进的阈值(如较大的值)将没有任何积极的影响,因为这时我们已经达到了每个NVMe可以提供的最大性能,例如2M IOPS.
要在CentOS上启用和配置中断合并,我们只需要启动NVMe驱动程序功能,并在我们需要评估的每个NVMe设备上设置聚合时间和聚合阈值。例如,在我们的16个NVMe测试设备上启动它,将聚合阈值设置为9,聚合超时时间为100微秒:
#for dev in $(seq 0 15);do nvme set-feature /dev/nvme${dev}n1 -feature-id 0x08 --value 0x0109;done
set-feature:0x08 (Interrupt Coalescing中断合并), value:0x00000109, cdw12:00000000, save:0
....
检查配置是否正确应用:
#nvme get-feature /dev/nvme0 -feature-id 0x08
get-feature:0x8 (Interrupt Coalescing), Current value:0x000109
Aggregation Time (TIME): 100 usec Aggregation Threshold (THR): 9
5.4 评估NVMe队列完成延迟的潜在影响
由于NVMe控制器不再在新的完成队列条目上触发MSI-x,因此有人可能会担心cLAT延迟收到重大影响,先前测试报告显示,如果同时访问16个NVMe设备,则最多需9个完成队列条目或100微秒的超时才能实现最大IOPS。FIO还能监控提交延迟(sLAT)和完成延迟(cLAT),测试数据确实表明启用中断合并并不会对cLAT p95产生影响,但只会稍微影响cLAT p99.00。
Test Data shows that on 16 NVMe concurrent access:
- IOPS improve by 484% (406k IOPS/Disk to 1969k IOPS/Disk)
- cLAT p95 gets better by 44% (971 usec -> 541 usec)
- cLAT p99.99 gets worse by 29% (1431 usec -> 1857 usec)
5.5 扩展评估至其他传输大小和访问类型
由于多个CPU核心执行I/O访问请求导致上下文切换的指数增长,NVMe聚合性能受到影响。我们验证了在这个NVMe Gen5 盘上对最具有压力的I/O访问模式(如4KB的随机访问)中中断合并的积极影响。由于NVMe驱动程序尚不能动态调整中断聚合阈值或NVMe设备的超时值;因此验证其他I/O访问是否能够容忍这样的配置是非常重要的,无论是较小的还是较大的块大小,以提供一致的用户体验。
下表摘自Intel的文档:
Baseline for comparison基准测试未启动中断合并的情况下测试性能。
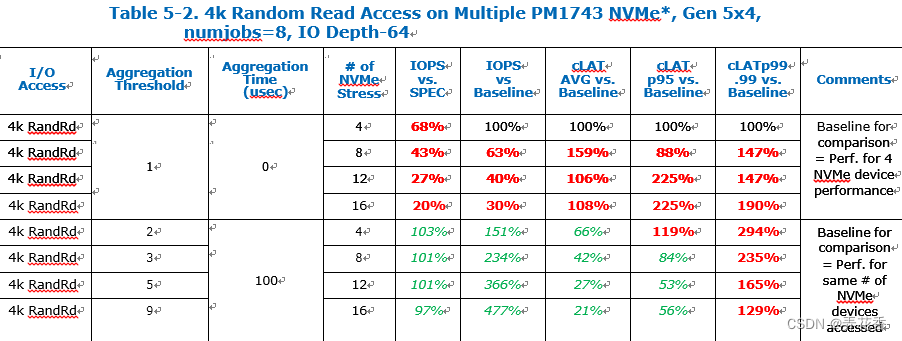
总的来说,对于4K随机读NVMe设备并发访问的越多,NVMe聚合阈值应该设置的越大,以维持更高的IOPS性能。平均来说,cLAT最大延迟得到了改善,尤其对于cLAT p95.
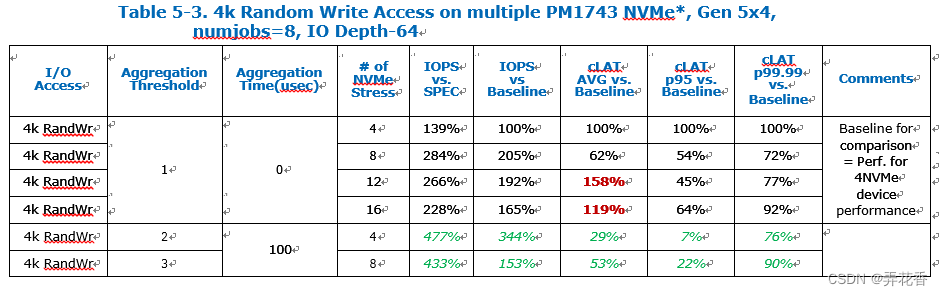
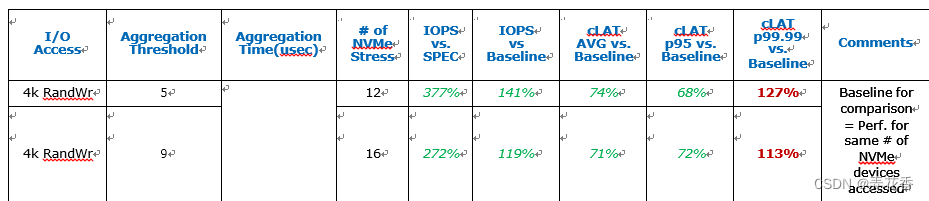
对于4K随机写操作,多个NVMe的并发访问并不会对IOPS性能产生太大影响, 因为瓶颈主要在于NAND媒体的编程喝擦除操作上,但启用中断聚合保持与其他I/O操作相同的聚合阈值,不会对性能产生负面影响,每个磁盘的IOPS增加,平均和p95 cLAT也得到改善,而p99.99 cLAT仅略有下降。
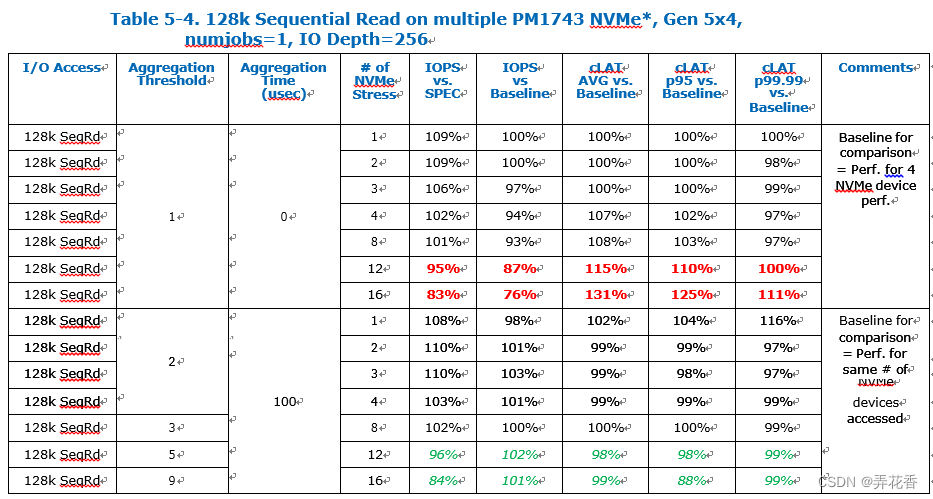
与4K 随机写操作类似,对于128K 顺序读并发访问多个NVMe不会对IOPS性能产生太大影响,因为中断和上下文切换的开销并不明显,每个NVMe仅有一个CPU核心发送IO请求。但启用中断聚合并保持与其他I/O操作相同的聚合阈值不会影响性能;IOPS、平均值/p95和p99.99 cLAT都非常相似,并不会受到聚合阈值的影响, 因为无论再哪种情况下,系统的响应都非常灵敏。
在同时访问超过12个NVMe设备时,无论在基准情况下还是测试项目中,都观察到了吞吐量下降的现象。
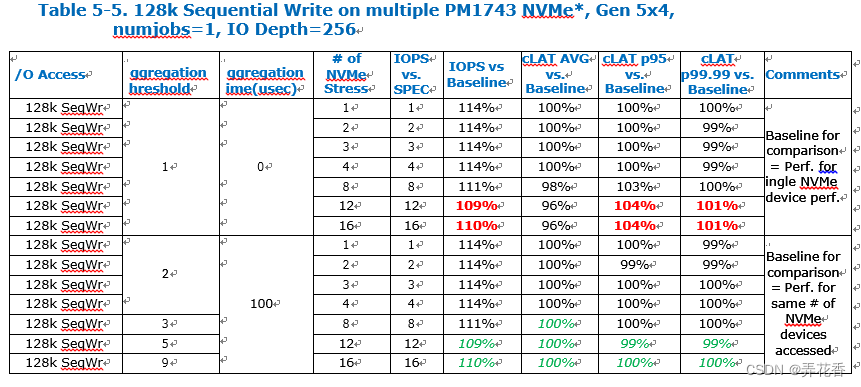
与128K 顺序读类似,128K顺序写并发访问多个NVMe不会对IOPS性能产生太大影响,因为中断和上下文切换的开销并不显著,每个NVMe仅有一个CPU核心发送IO请求。
5.5.1 基于NVMe Gen5 x4 PM1743 3D NAND的设备结论
对于NVMe Gen5 x4,当多个CPU核心同时访问多个NVMe设备时,我们观察到性能下降的现象,性能下降程度会随着同时访问的NVMe设备数量增加而增加。为受影响的每个NVMe启动NVMe驱动程序的中断聚合,并设置合理的聚合阈值。评估显示,性能得到了很大的恢复,cLAT显著降低,只有少数 IO访问可能会出现更高的延迟。
5.6 扩展评估到Gen4 Intel P5800X Optane NVMe SSD
Intel P5800X具有独特的特性,因此验证我们的解决方案是否可以在这些NVMe设备上实现是相关的。这些设备提供非常小的blocksize访问用于随机IOPS,低延迟以及非常短的IO深度,这可能会对IO提交产生限制。
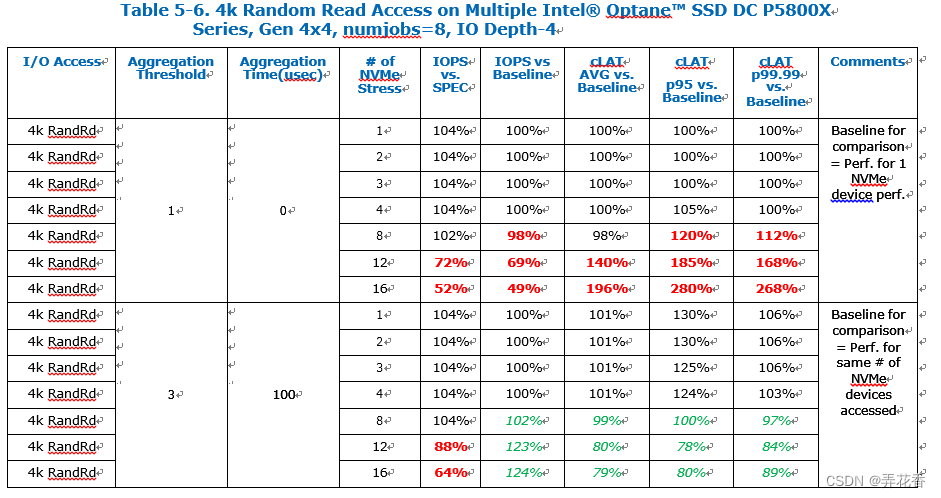
当同时访问12/16个NVMe设备时(分别时/dev/nvme11-15和/dev/nvme8-15),可以观察到性能不均衡的现象,根据核心分配在“CPU和NVMe分配”部分中介绍的情况,以及在“设置队列和队列深度”部分中描述的NVMe驱动程序队列映射机制所导致。
对于那些高端Gen4 x4设备,性能也在提高,IOPS增加延迟降低。然而,由于这些NVMe设备的IO-Depth大小有限,这就对系统中的IO请求提交量产生了限制,独立于完成请求的处理,对于拥有4个Optane NVMe设备的更典型的客户群体,没有观察到性能下降的情况。
70/30 4K随机读写如下,摘自Intel的文档:
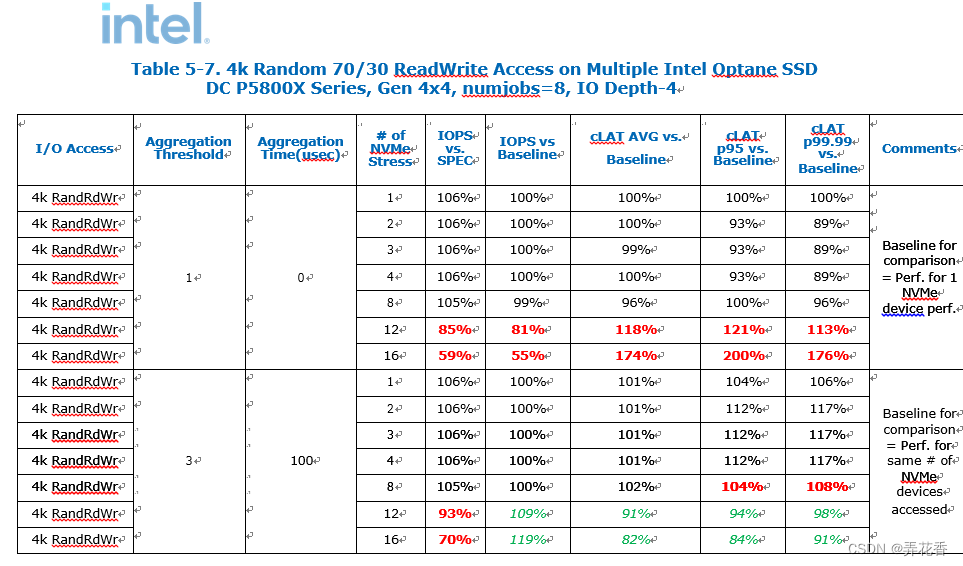
注意:在同时访问12/16个NVMe设备时(分别在设备/dev/nvme11-15和/dev/nvme8-15上),根据在“CPU和NVMe分配”部分中介绍的CPU核心分配和在“设备的队列和队列深度”部分中描述的NVMe驱动队列映射机制,可以观察到性能不平衡的现象。
对于那些高端的Gen4x4设备,性能也在提升,IOPS增加,延迟减少。然而,由于这些NVMe设备的IO深度限制,它在系统中创建了一个IO请求提交的限制,这与完成请求的处理无关。对于一般的4个Optane NVMe设备的典型客户群体,没有观察到性能下降。
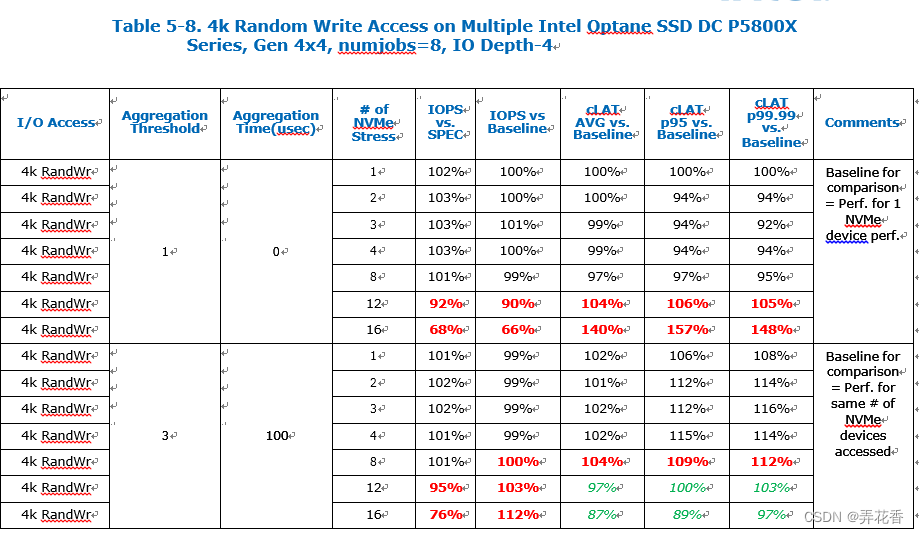
与4K随机读一样,4k随机写也在提出的解决方案下看到了一些性能恢复,但小的IO深度仍是一个限制因素。
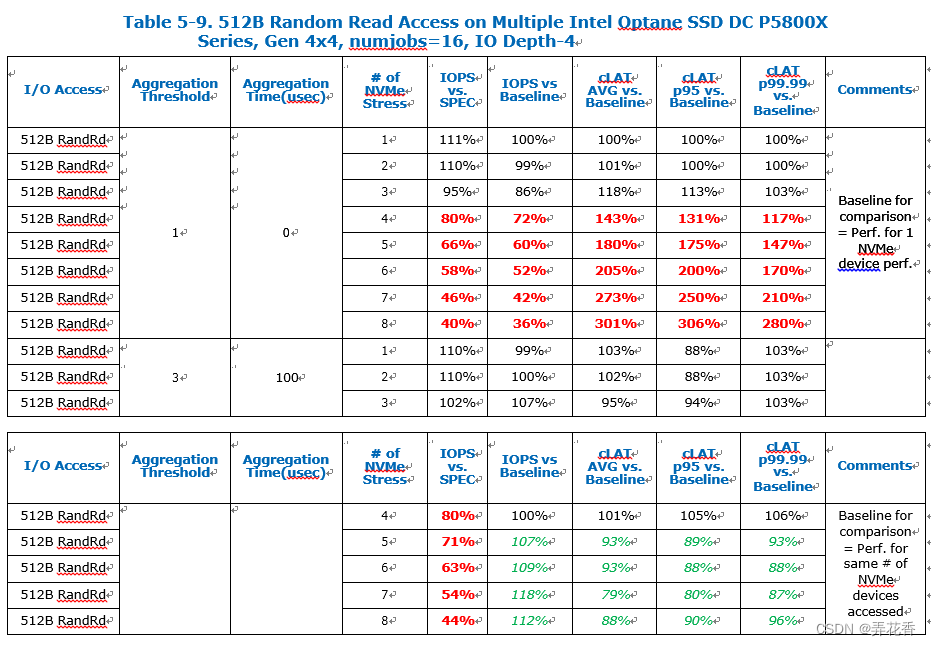
块大小访问是小块的,需要大量的CPU核心来提交IO请求以达到最高吞吐量,有限的NVMe队列IO深度大小限制了系统中IO请求提交的数量,与完成请求的处理无关。对于一般的4个Optane NVMe设备的典型客户群体来说,性能下降较小。
所提出的解决方案也适用于在具有超过12个Intel Optane SSD的系统上使用P5800X,对于更典型的配置,其中1-4个Optane SSD主要用作缓存或写入缓冲区,Intel Optane SSD的性能非常好,这要归功于其优越的媒介。
6.总结
Intel致力于为客户提供高性能和高可靠性的产品。在本技术论文中,英特尔建议客户采取最佳实践措施以实现更好的吞吐量性能,并评估潜在的延迟和权衡。这旨在帮助客户以最佳方式配置其NVMe子系统,以满足其需求。
Linux NVMe驱动程序默认情况下禁用中断聚合。对于受到IOPS性能限制的NVMe设备启用中断聚合可以提供更高的聚合性能,改善NVMe队列完成延迟:在大多数情况下,完成延迟cLAT p95得到改善,而cLAT p99可能会因较高的吞吐量而受到影响。
此外,在操作系统级别上可以按NVMe磁盘进行逐个启用和调优,为希望在其应用程序上保持良好QoS的客户提供进一步增值。















 5391
5391











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









