






 本文介绍一种利用实体信息增强预训练模型BERT的方法,以提高关系分类任务的性能。通过在目标实体位置插入特殊标记,使模型能捕捉实体位置信息,结合实体编码和句子编码进行关系分类,实现在SemEval-2010Task8数据集上超越现有方法。
本文介绍一种利用实体信息增强预训练模型BERT的方法,以提高关系分类任务的性能。通过在目标实体位置插入特殊标记,使模型能捕捉实体位置信息,结合实体编码和句子编码进行关系分类,实现在SemEval-2010Task8数据集上超越现有方法。
利用实体信息丰富预训练模型以进行关系分类
Enriching Pre-trained Language Model with Entity Information for Relation Classification
摘要
关系分类是抽取实体间关系的一个重要的NLP任务。关系抽取中的SOTA方法主要基于卷积神经网络或者循环神经网络。最近,预训练的BERT模型在NLP分类和序列标注任务上取得了非常成功的结果。关系分类同上述任务不同,它依赖于句子和两个目标实体的信息。在这篇文章中,我们提出了一个模型,既利用预训练的bert语言模型,又结合来自目标实体的信息来解决关系分类任务。我们定位目标实体的位置,并通过预训练架构传递信息,而且结合两个实体的相关编码。与SemEval-2010任务8关系抽取数据集上的SOTA方法相比,我们取得了显著的改进
1. 引言
关系分类的任务是预测名词对之间的语义关系。给定一个文本序列(通常是一个句子)s和一对名词 e 1 e_1 e1和 e 2 e_2 e2,目标是识别 e 1 e_1 e1和 e 2 e_2 e2之间的关系。关系分类是一个重要的NLP任务,通常作为各种NLP应用的中间步骤。下面示例就展示了名词对"kitchen"和"house"之间的"Component-Whole"关系:kitchen是house的一部分。
深度神经网络也已经被应用在关系分类任务上( Socher et al., 2012; Zeng et al., 2014; Yu et al., 2014; dos Santos et al., 2015;Shen and Huang,2016;Lee et al.,2019)。但这些方法通常使用从词汇资源中获取的特征,如Word-Net或者NLP工具如依赖解析和NER。
语言模型预训练在改善自然语言处理任务上已经显示出很好的效果。预训练模型BERT也有特别重要的影响。BERT已经被应用在多个NLP任务上,并且在7个任务上取得了SOTA结果。BERT所应用的任务都是能够被建模为典型的分类问题和序列标注问题。他也被应用在SQuAD问答问题上,该问题的目标是找出答案范围的起点和终点。
据我们所知,BERT模型尚未应用在关系分类任务上,关系分类不仅依赖整个句子的信息,也依赖具体的目标实体的信息。在这篇文章里,我们将BERT模型应用在关系分类上。我们先在目标实体的位置前后插入特殊的标记(token),然后将文本输入BERT进行fine-tuning,以识别两个目标实体的位置并将信息传给BERT模型。然后,我们在BERT模型的输出embeddings中找到两个目标实体的位置。我们使用他们的embeddings和sentence编码(在BERT中设置的一个特色token的嵌入)作为多层神经网络分类的输入。通过这种方式,能捕获句子和两个目标实体的语义信息,以更好地适应关系分类任务。
本文贡献如下:
(1)提出一个创新性的方法:将实体级别的信息整合进预训练语言模型用于关系分类任务。
(2)在关系分类任务上取得新的state-of-the-art
2.相关的工作
MVRNN模型(Socher el al.,2012)将递归神经网络应用于关系分类。它为解析树中的每个节点分配一个矩阵向量表示,并根据解析树的句法结构从下至上计算完整句子的表示形式。
(Zeng et al.2014)通过结合词嵌入和位置特征作为输入,提出了一个CNN模型。然后将词法特征和CNN的输出连接到单个向量中,并将起输入softmax层进行预测。
(Yu et al., 2014)提出了一种基于因子的组合嵌入模型(FCM),该模型用过依存树和命名实体从单词嵌入构建句子级和子结构嵌入。
(Santos el al.,2015)通过使用名为CR-CNN的卷积神经网络进行排名来解决关系分类任务,他们的损失函数基于成对排名。
在我们的工作中,充分利用预训练模型的优势进行关系分类,而不依赖CNN或者RNN结构。(Shen and Huang,2016)将CNN编码器与句子表示结合使用,该句子表示通过关注目标实体和句子中的单词之间的注意力对单词进行加权,以执行关系分类。
(Wang et al.,2016)为了捕获异构上下文中的模式以对关系进行分类,提出了一种具有两层注意力级别的卷积神经网络体系结构。
(Lee et al.,2019)开发了一个端到端的循环神经网络模型,该模型结合了实体感知的注意力机制和潜在的实体类型以进行关系分类。
也有一些工作使用远程监督进行关系分类,如(Mintz et al., 2009; Hoffmann et al., 2011; Lin et al., 2016; Ji et al., 2017; Wu et al., 2019).使用常规数据和远程监督数据进行关系分类之间的差异在于:后者包含大量的噪声标签。在这篇论文中,我们仅关注常规的关系分类问题,没有噪声标签。
3.方法
3.1 预训练模型BERT
预训练模型bert是一个多层双向Transformer 编码器。BERT的输入表示能够在一个token序列中表示单个文本或者一对文本。每个token的输入表示由相应的token、segment和位置编码向量的总和构成。
"[CLS]“符号被添加到每个输入语句的开始作为第一个字符。Transformer输出的相对于第一个token的最终隐藏状态向量用于表示整个输入语句以进行分类任务。如果在一个任务中由两个语句,则”[SEP]"符号用于分隔两个语句。
BERT使用以下预训练目标来预训练模型参数:the masked language model(MLM),它会从输入中随机掩盖一些token,并设置优化目标以根据其上下文预测被掩盖词的原始ID。不同于left-to-right语言模型预训练,MLM目标可以帮助状态输出同时利用左右上下文,从而允许预训练系统应用深度双向Transformer。除了MLM外,BERT也训练一个“NSP”任务。
3.2 模型架构
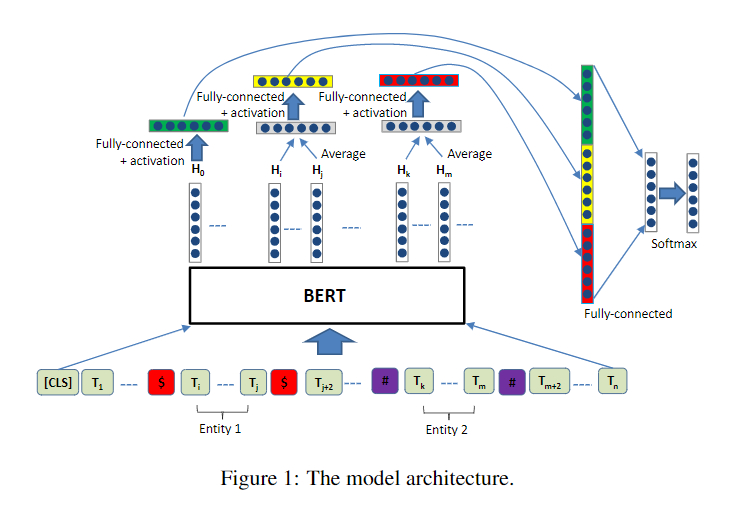
上图1为本文的方法结构。对于有两个目标实体 e 1 e_1 e1和 e 2 e_2 e2的语句 s s s来说,为了让BERT模块能够获取两个实体的位置信息,在第一个位置实体的前后插入"$“符号,在第二个实体的前后插入”#“符号。每个句子开始也会添加”[CLS]"符号。举例说明,在插入一个特殊的分隔符后,一个拥有两个实体"kitchen"和"house"的语句将变成:\
“[CLS] The $ kitchen $ is the last renovated part of the # house # . ”
给定一个包含实体 e 1 e_1 e1和 e 2 e_2 e2的语句 s s s,假设根据BERT获取它的最终隐藏状态为 H H H,假设实体 e 1 e_1 e1的隐藏向量为 H i H_i Hi到 H j H_j Hj,实体 e 2 e_2 e2的隐藏向量为 H k H_k Hk和 H m H_m Hm。我们对每个实体的所有向量进行求平均。然后再添加激活函数并添加一个全连接层。于是 e 1 e_1 e1和 e 2 e_2 e2转换为 H 1 ′ H^{'}_1 H1′,如下:
H 1 ′ = W 1 [ t a n h ( 1 j − i + 1 ∑ t = i j H t ) ] + b 1 H^{'}_1=W_1[tanh(\frac{1}{j-i+1}\sum_{t=i}^jH_t)]+b_1 H1′=W1[tanh(j−i+11t=i∑jHt)]+b1
H 2 ′ = W 2 [ t a n h ( 1 m − k + 1 ∑ t = k m H t ) ] + b 2 H^{'}_2=W_2[tanh(\frac{1}{m-k+1}\sum_{t=k}^mH_t)]+b_2 H2′=W2[tanh(m−k+11t=k∑mHt)]+b2
其中,
W
1
W_1
W1和
W
2
W_2
W2共享参数,
b
1
b_1
b1和
b
2
b_2
b2共享参数,即
W
1
=
W
2
,
b
1
=
b
2
W_1=W_2,b_1=b_2
W1=W2,b1=b2。对于第一个token([CLS])所表示的最终隐藏状态向量,也添加一个激活函数和全连接层。
H
0
′
=
W
0
(
t
a
n
h
(
H
0
)
)
+
b
0
H_0^{'}=W_0(tanh(H_0))+b_0
H0′=W0(tanh(H0))+b0
其中, W 0 ∈ R d × d , W 1 ∈ R d × d , W 2 ∈ R d × d W_0 \in R^{d \times d},W_1 \in R^{d \times d},W_2 \in R^{d \times d} W0∈Rd×d,W1∈Rd×d,W2∈Rd×d, d d d表示BERT的hidden_size.
将 H 0 ′ , H 1 ′ , H 2 ′ H_0^{'},H_1^{'},H_2^{'} H0′,H1′,H2′进行concatenate,然后添加全连接层和softmax层。
h
′
′
=
W
3
[
c
o
n
c
a
t
(
H
0
′
,
H
1
′
,
H
2
′
)
]
+
b
3
p
=
s
o
f
t
m
a
x
(
h
′
′
)
h^{''}=W_3[concat(H_0^{'},H_1^{'},H_2^{'})]+b_3 p=softmax(h^{''})
h′′=W3[concat(H0′,H1′,H2′)]+b3p=softmax(h′′)
其中,
W
3
∈
R
L
×
3
d
W_3 \in R^{L \times 3d}
W3∈RL×3d,
L
L
L为关系数量,
p
p
p为概率输出,
b
0
,
b
1
,
b
2
,
b
3
b_0,b_1,b_2,b_3
b0,b1,b2,b3是偏置向量。
使用交叉熵作为损失函数,在每个全连接层前应用dropout。我们称本文使用的方法为R-BERT。
4.实验
4.1 数据集和评估指标
我们使用SemEval-2010 Task 8数据集进行实验,该数据集包含9个语义关系类型和1个人工关系类型"Other",该关系类型表示所有不属于那9个类型的关系。9个关系类型为:
Cause-Effect, Component-Whole, Content-Container, Entity-Destination, Entity-Origin, Instrument-Agency, Member-Collection, Message-Topic and Product-Producer.
该数据集有10717条样本,每个样本包含两个实体
e
1
e_1
e1和
e
2
e_2
e2以及他们的关系类型。关系是有方向的,意味着Component-Whole
(
e
1
,
e
2
)
(e_1, e_2)
(e1,e2)和 Component-Whole
(
e
2
,
e
1
)
(e_2, e_1)
(e2,e1)是不同的。数据集划分为训练集8000和测试集2717。使用SemEval-2010 Task 8官方评分脚本进行评估。为9中关系类型计算宏平均F1分数,并且要考虑方向性。
4.2 参数设置
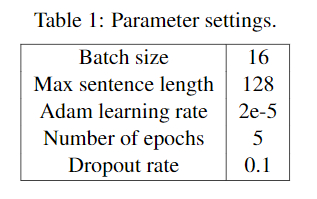
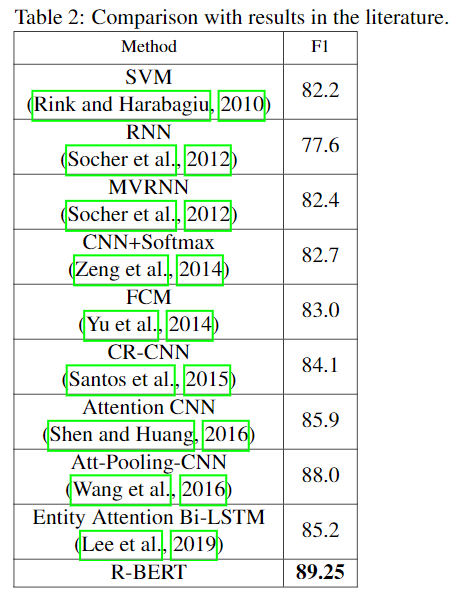
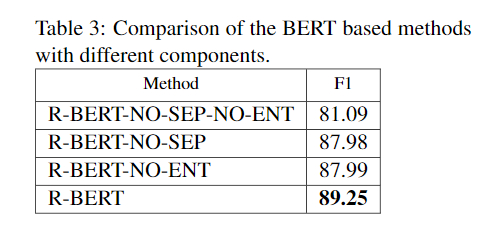
4.3 与其他方法的比较



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









