






环境:sqlite3,嵌入式设备,假设表名为my_table,数据量不大,一般也就几千,多的时候也就几万条,查询语句:select * from my_table order by (startTime +0) DESC limit 0,100;
问题:该语句以startTime排序,并使用limit限制排序后的0到100行的结果,在嵌入式设备上测试查询耗时需要几秒。
排查:
将表导入到windows上,使用SQLiteStudio(或者其它工具都可以)打开,然后执行相同的语句,发现只需要100多毫秒。因为嵌入式设备和pc主机的性能差距,且现场环境的程序还有其它资源开销,肯定是不能完全复现出几秒的耗时。那就多造点数据,把数据造到60w条后,再执行select * from my_table order by (startTime +0) DESC limit 0,100;测试:
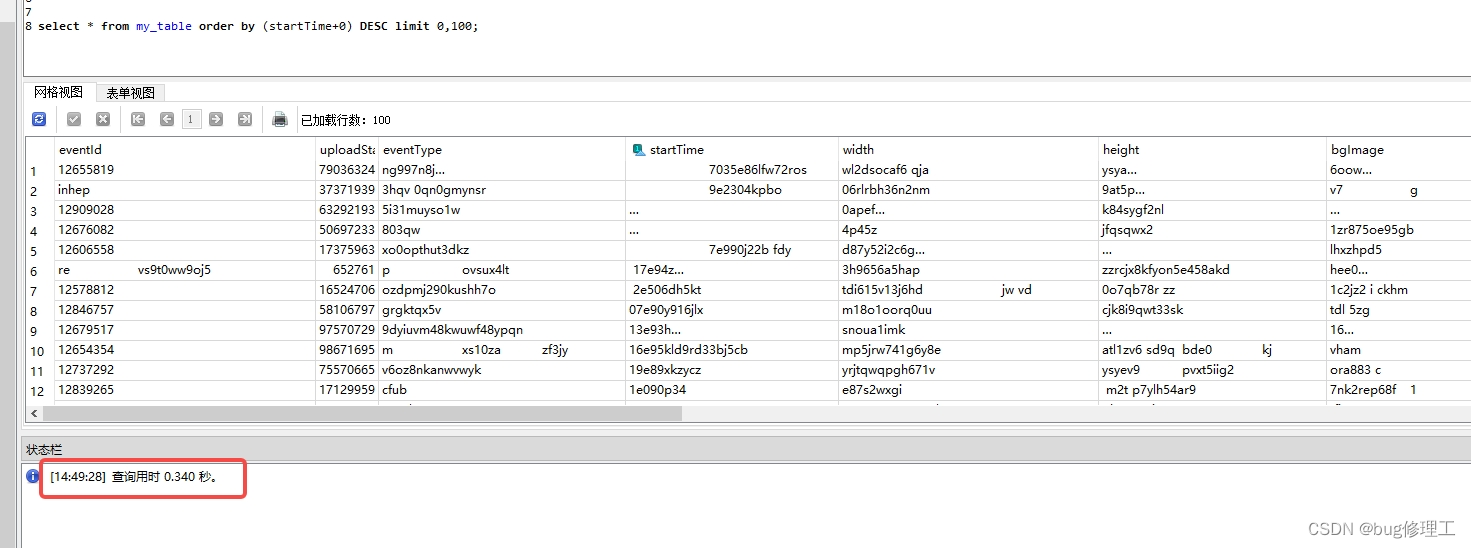
发现耗时达到了300多毫秒,这样即使在windows下也有很大优化的空间,那就基于这个样本数据在windows下进行优化测试。
在sql语句前加上EXPLAIN QUERY PLAN,也就是EXPLAIN QUERY PLAN select * from t_event order by (startTime+0) DESC limit 0,100;
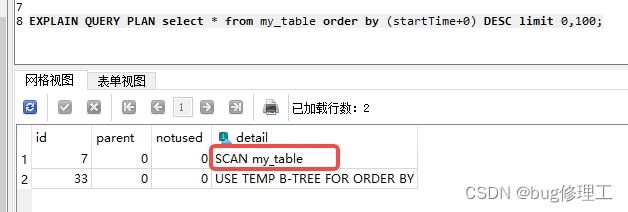
可以看到遍历了整个表,也就是没有走索引,那我加上索引startTime后再测试,发现还是这样。到这里startTime+0引起了我的注意,这里+0的原因,是因为startTime是text类型,+0可以将其转换成整型,但是startTime就是时间戳,只是类型为text,没有必要转换成整型就能排序, 删掉startTime后的"+0"试试:
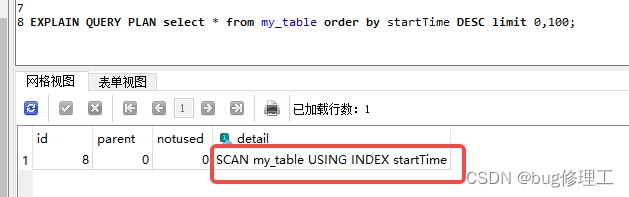
可以看到走了索引。
那我们再执行select * from my_table order by startTime DESC limit 0,100;测试一下:
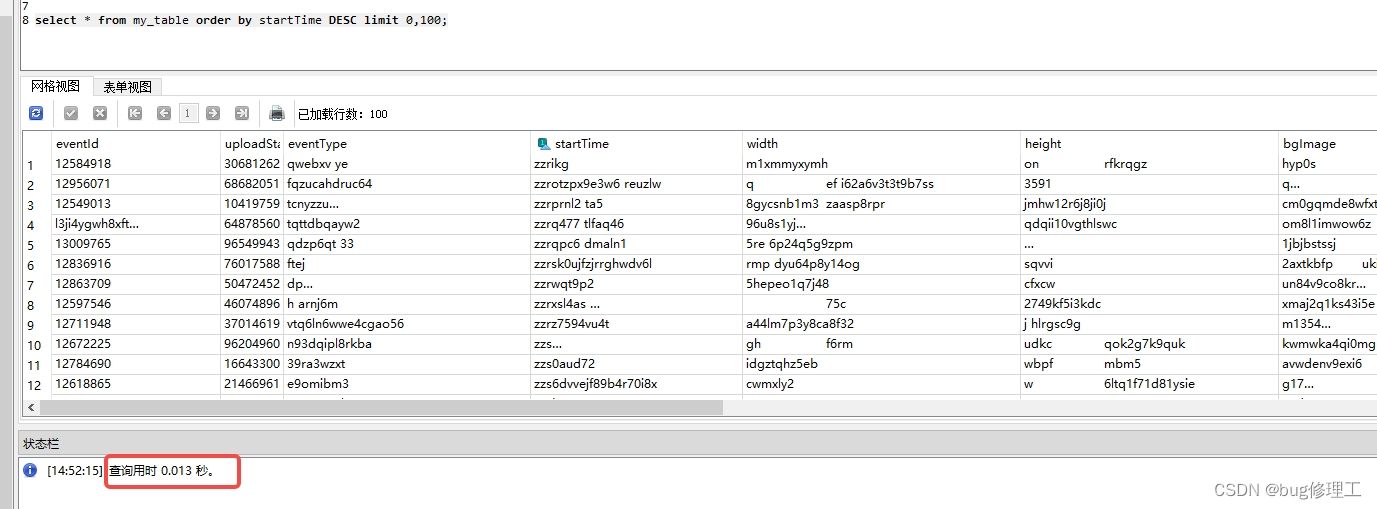
速度由340多毫秒优化到了13豪秒!
最后在嵌入式设备上同样修改后,执行速度从3~4秒优化到到30毫秒左右,将近100倍的提升。
总结:
1.针对具体场景建立合适的索引;
2.使用EXPLAIN 和 EXPLAIN QUERY PLAN 来分析查询计划和性能;
3.对于可以使用整型的列,尽量使用整型;
4.对索引字段额外的操作可能导致索引失效,比如"+0",需要测试确认















 539
539











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









