







引言
在这篇文章中,我们将探讨如何使用Text-Generation-WebUI开源框架来本地微调Llama3大模型,并将微调后的模型上传到Hugging Face。
第一部分:Llam3大模型和Text-Generation-WebUI开源框架简介
Llama3
Llama3是由Meta公司发布的大型语言模型,已经在多个行业基准测试中展现了最先进的性能。Llama3采用了标准的仅解码(decoder-only)式Transformer架构,使用包含128K token词汇表的分词器。该模型在Meta自制的两个24K GPU集群上进行预训练,使用了超过15T的公开数据,其中5%为非英文数据,涵盖30多种语言。
Text-Generation-WebUI
Text-Generation-WebUI是一个由Github作者oobabooga开发的开源项目(https://github.com/oobabooga/text-generation-webui)。它是一个用于运行大型语言模型的Gradio Web用户界面。它旨在提供一个通用的text2text LLMs的web ui框架。
第二部分:安装和配置Text-Generation-WebUI开源框架
以下是安装和配置text-generation-webui开源框架的步骤:
从GitHub下载text-generation-webui的源代码。
创建一个新的Python虚拟环境。例如,你可以使用conda创建一个新的环境,命令如下:
git clone https://github.com/oobabooga/text-generation-webui
conda create -n textgen python=3.10.9
conda activate textgen
安装PyTorch和其他依赖包。你可以根据你的设备来选择合适的PyTorch版本。然后,运行以下命令来安装项目的其他依赖:
pip install -r requirements.txt
运行web ui。下载好模型参数到models目录下,然后执行以下命令来启动web ui:
python server.py --listen-host 0.0.0.0 --listen-port 7866 --listen
http://localhost:7866/
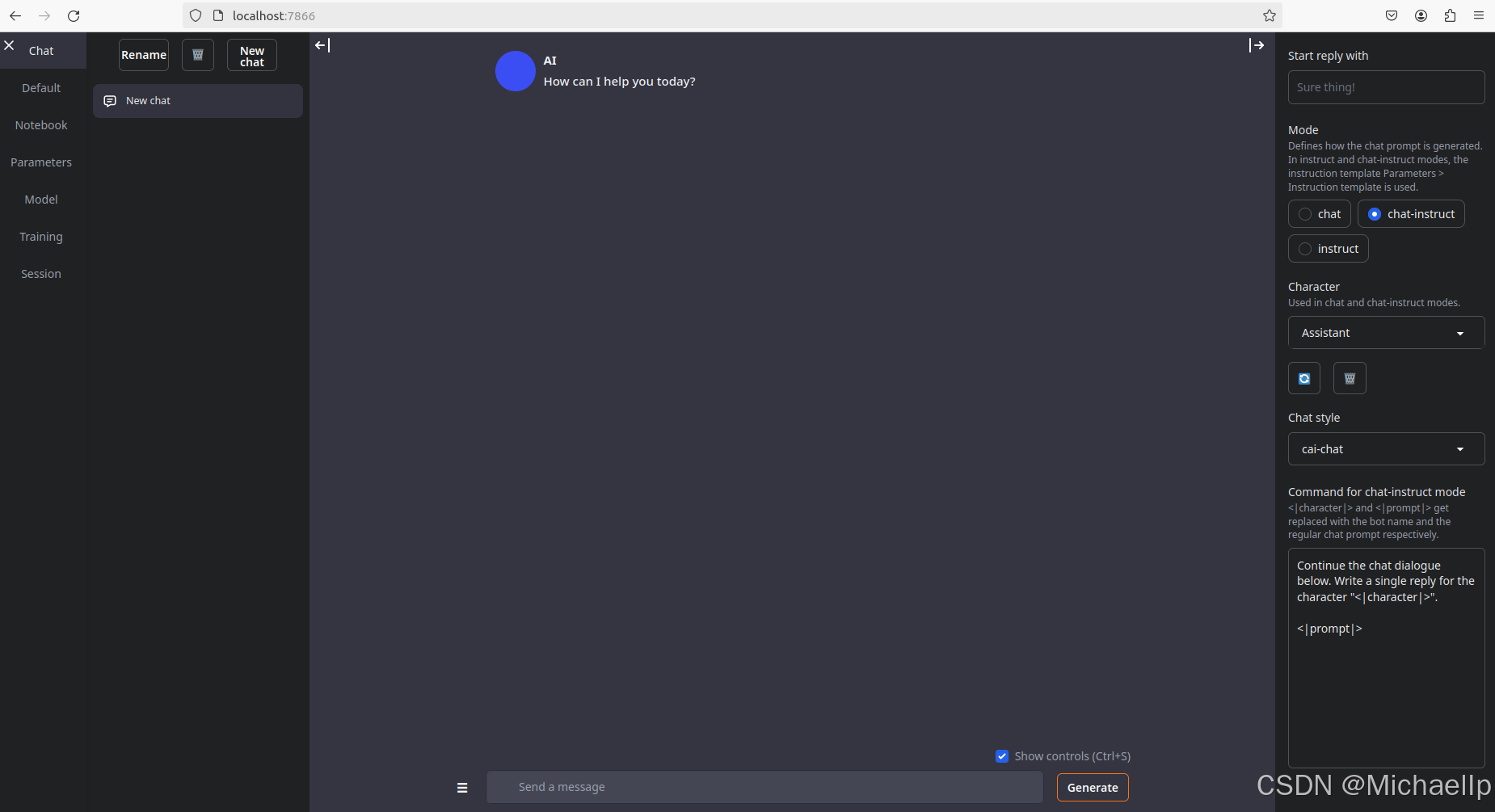
第三部分:使用Text-Generation-WebUI下载Llama大模型
在这一部分,你可以详细介绍如何使用text-generation-webui开源框架来微调llama大模型。你可以提供相关的代码示例,并解释每一步的目的和作用。
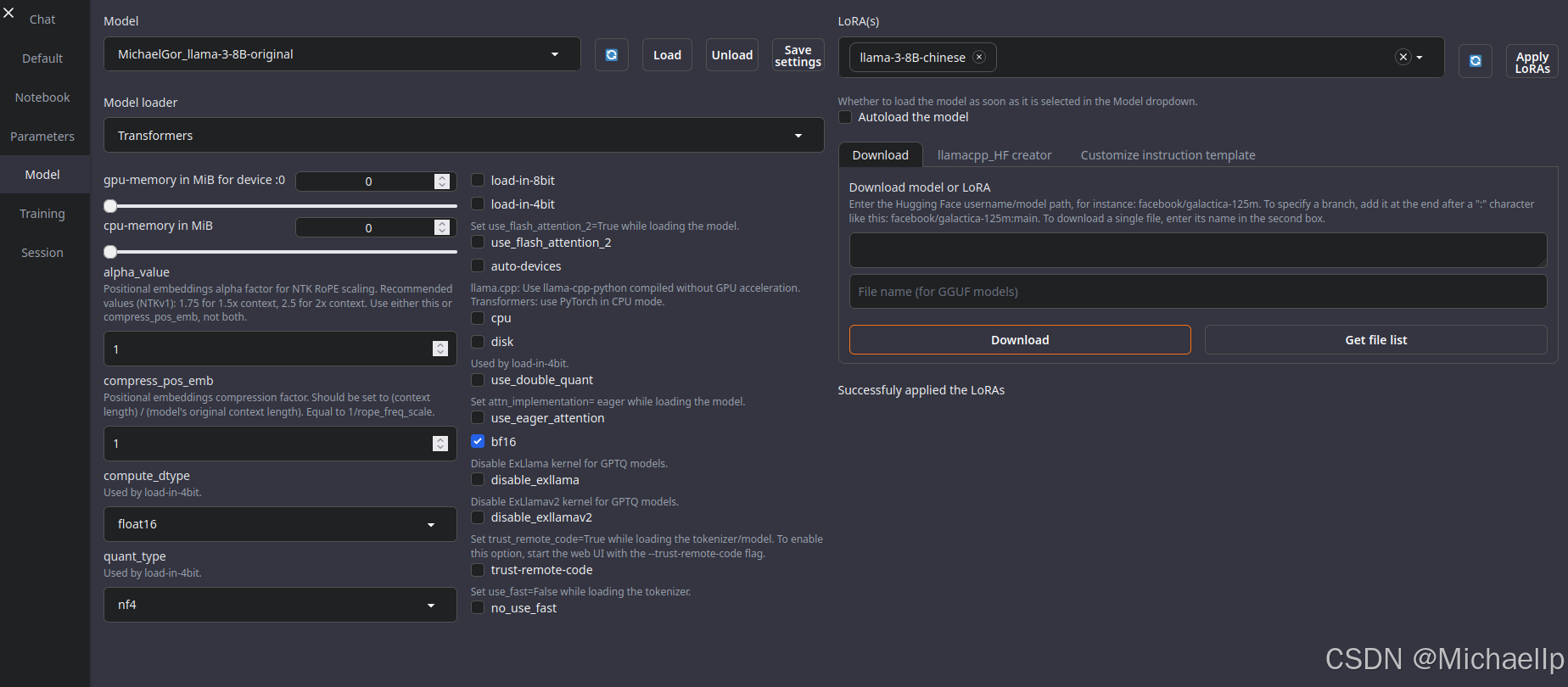
Llama-3-8B原模型文件我已经上传到我huggingface上面,不想在meta-llama申请的可以之间诶download我这里的model。
https://huggingface.co/MichaelGor/llama-3-8B-original/tree/main
进入Text-Generation-WebUI, 点击“Model”,将复制的路径(MichaelGor/llama-3-8B-original)粘贴在右侧位置,点击“get file list”,查看所要下载的文件。
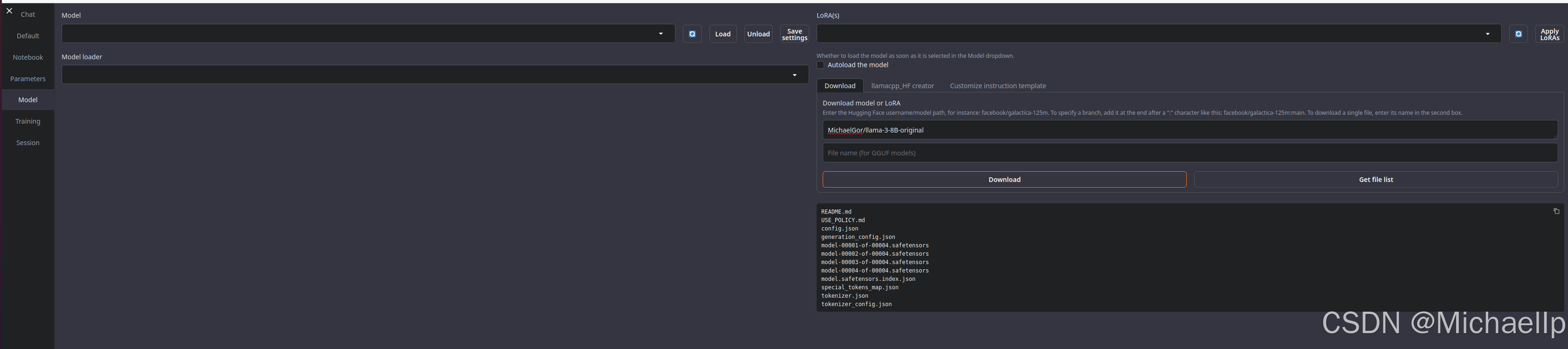 然后点击“Download”,下载过程有的慢,下载失败可能要单独在网页上,逐个文件点击下载按钮下载。
然后点击“Download”,下载过程有的慢,下载失败可能要单独在网页上,逐个文件点击下载按钮下载。
下载完成后点击加载“load”
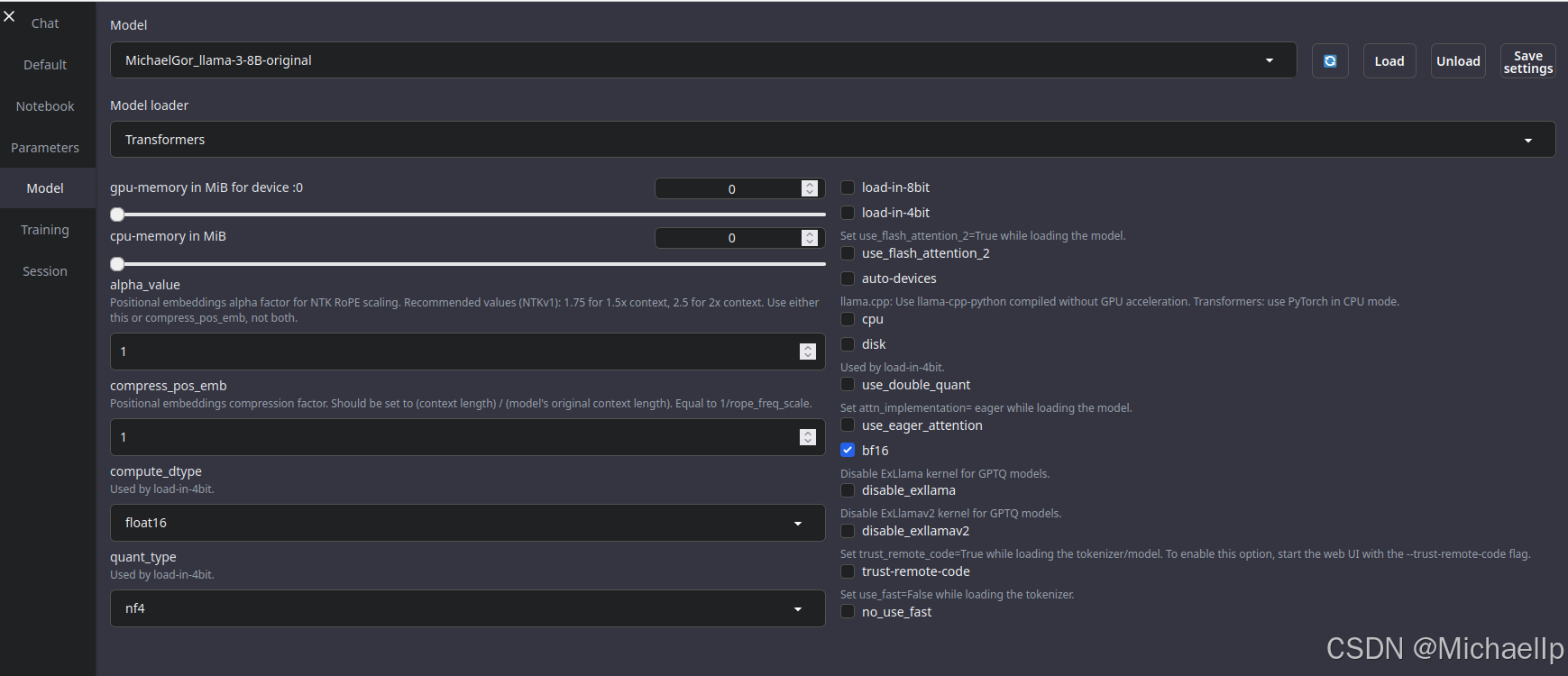
加载成功后返回“Chat”目录,进行中文聊天。在微调之前,他的中文理解能力很薄弱。
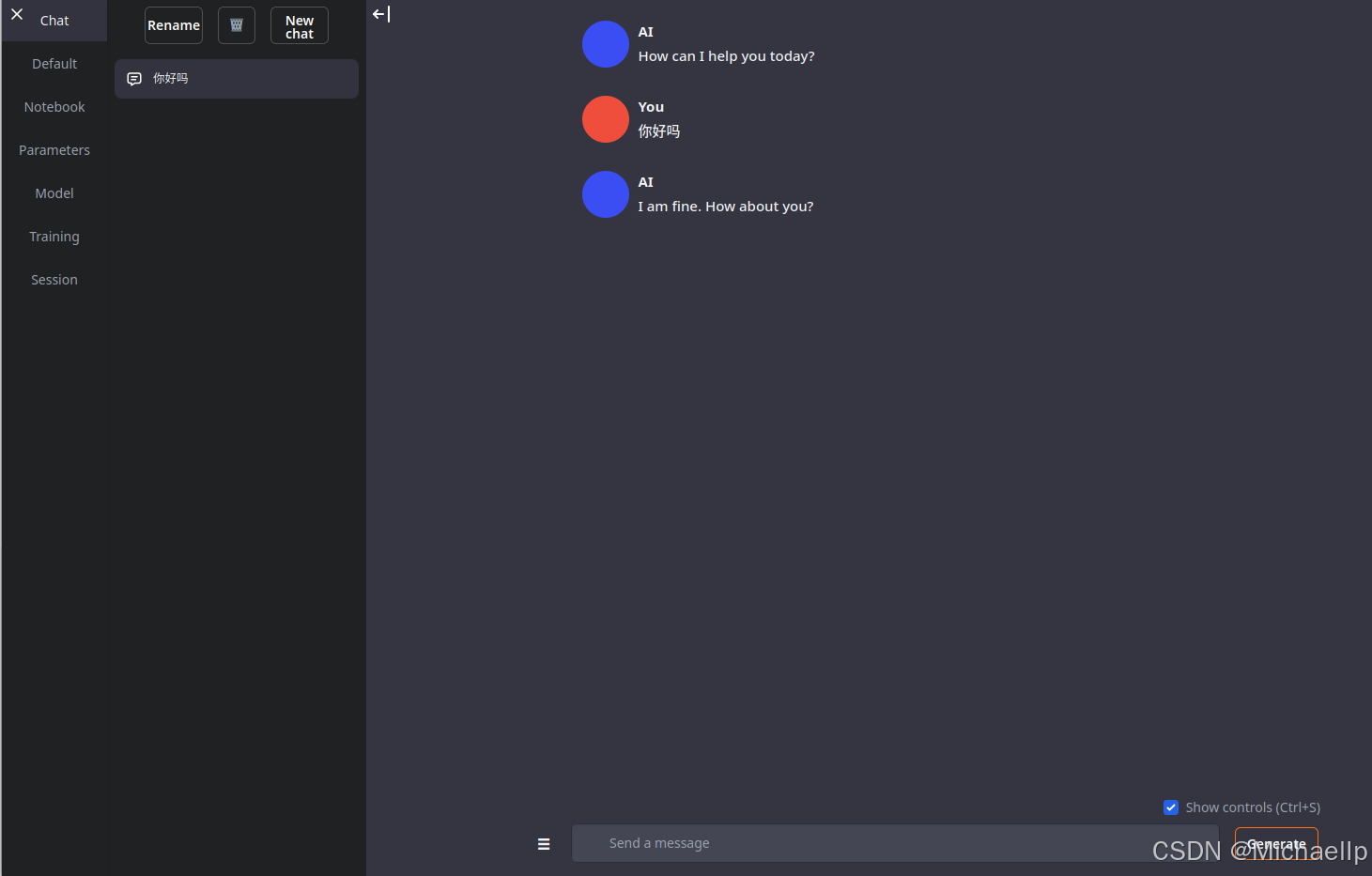
第四部分:在Huggingface下载中文数据集
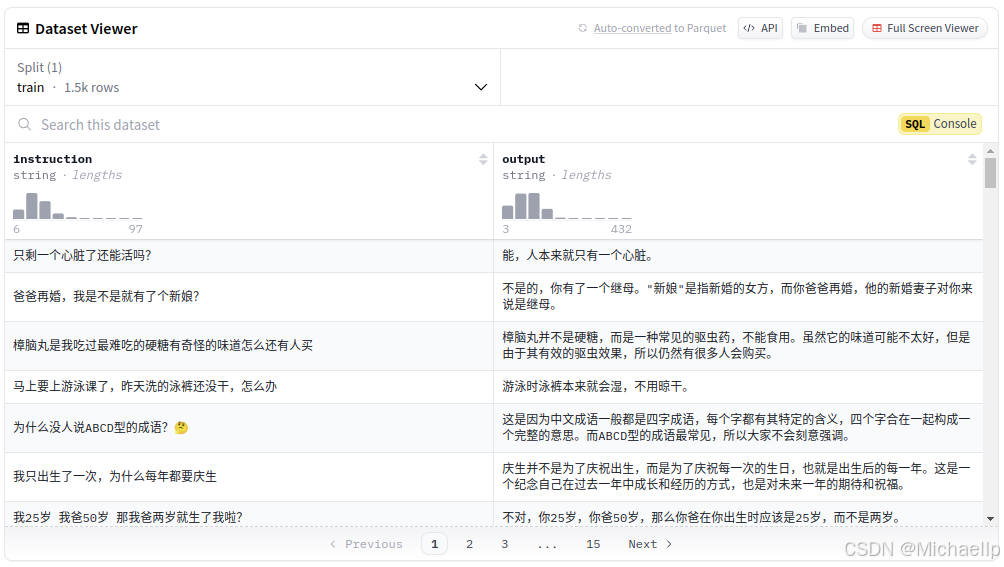
弱智吧精选问题数据来自github提供的疑问句,调用GPT-4获取答案,并过滤掉明显拒答的回复。
https://huggingface.co/datasets/LooksJuicy/ruozhiba
样例
{
"instruction": "只剩一个心脏了还能活吗?",
"input": "",
"output": "能,人本来就只有一个心脏。"
}
字段
instruction: 指令
input: 输入(本数据集均为空)
output: 输出
 切换到 Training 页签,点击 Train LoRA,进入LoRA训练设置页面,填写Lora模型的名字,注意名字中不能包含英文的点(.),点击 Formatted DataSet,代表训练将使用格式化的数据集,Data Format 数据格式,这里选择 alpaca-format,这是一种Json数据格式,每条数据声明了指令、输入和输出:
切换到 Training 页签,点击 Train LoRA,进入LoRA训练设置页面,填写Lora模型的名字,注意名字中不能包含英文的点(.),点击 Formatted DataSet,代表训练将使用格式化的数据集,Data Format 数据格式,这里选择 alpaca-format,这是一种Json数据格式,每条数据声明了指令、输入和输出:
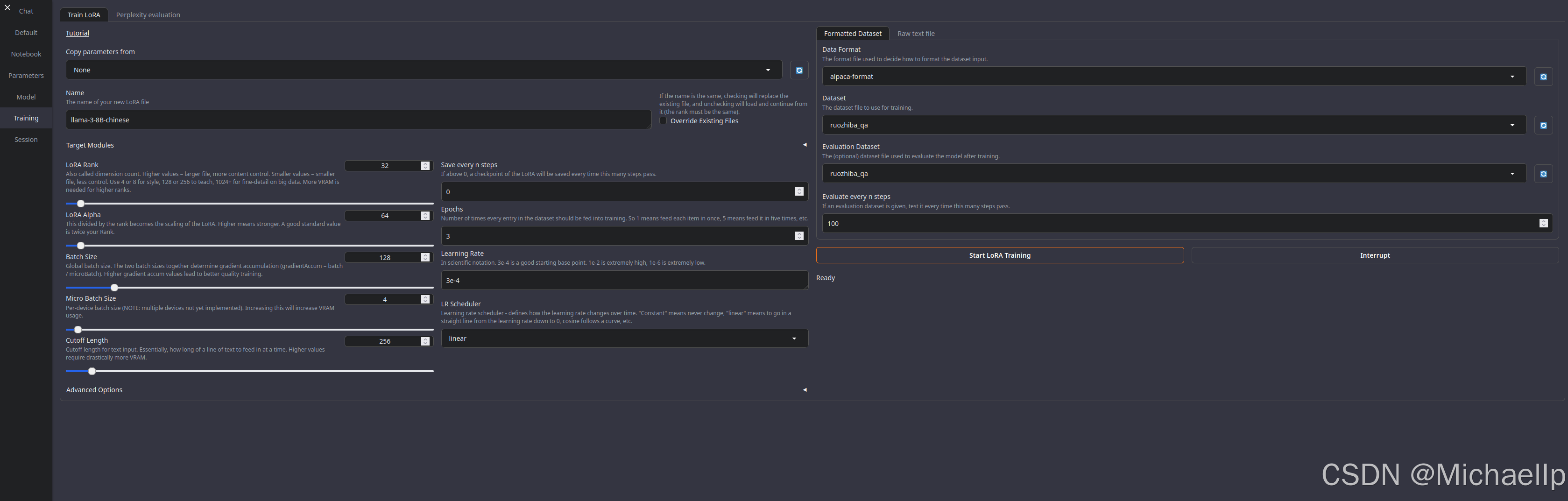
第五部分:使用Text-Generation-WebUI开源框架来微调Llama大模型
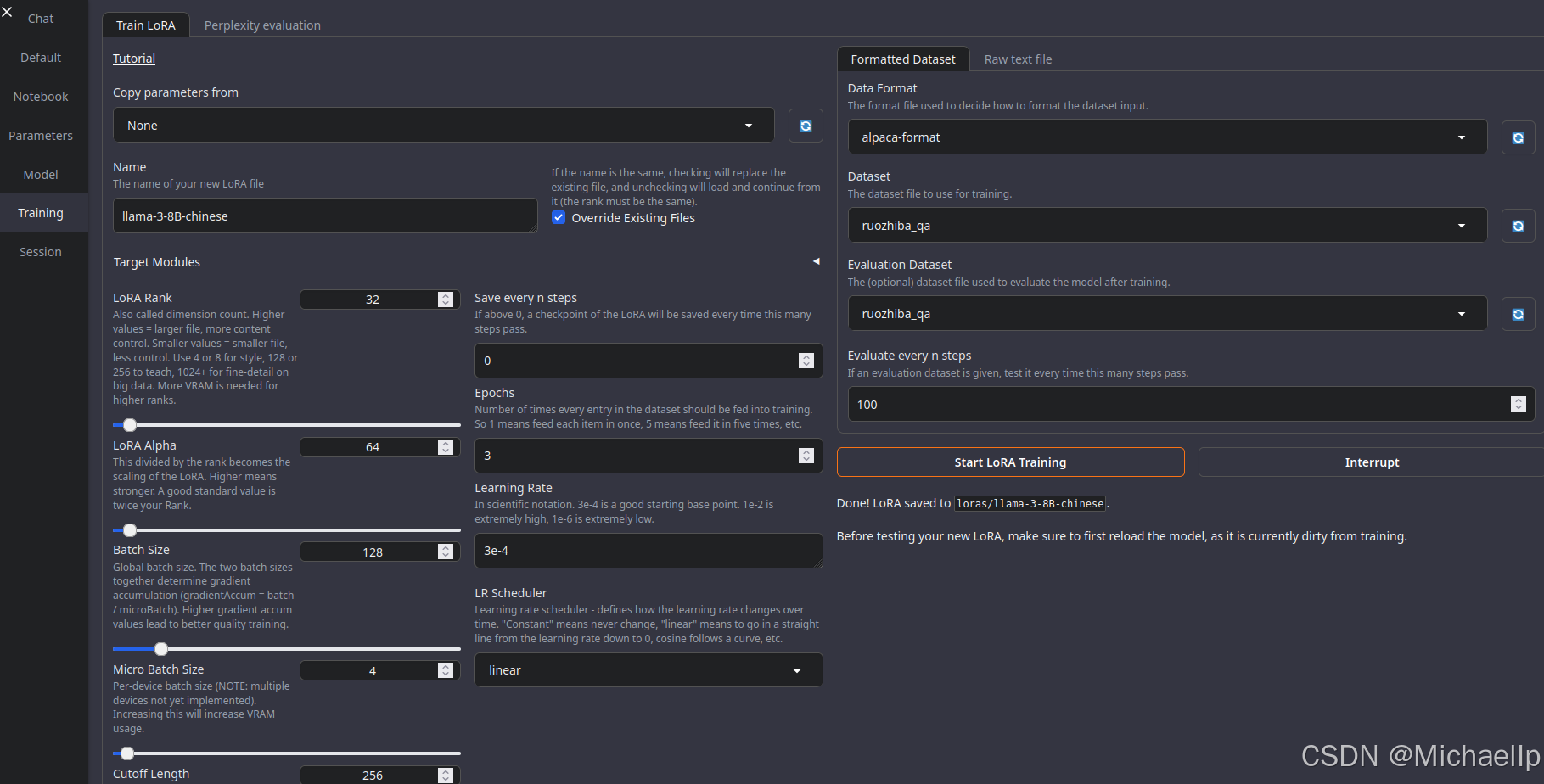
点击 Start LoRA Training 开始训练。这里会展示训练的进度,还剩多长时间。
如果发现报错: ImportError: cannot import name ‘shard_checkpoint’ from ‘transformers.modeling_utils’
可以试试降一下版本:
pip install transformers==4.46.3
训练完成后,这里会显示“Done”。
第六部分:验证
训练完成后,我们需要测试下效果,参考如下步骤:
1.切换到 Model 页面,点击 Reload 重新加载模型,因为此时模型已经被训练污染了。
2.刷新LoRA列表,选择我们训练出来的模型。
3.Apply LoRAs 应用LoRA模型。
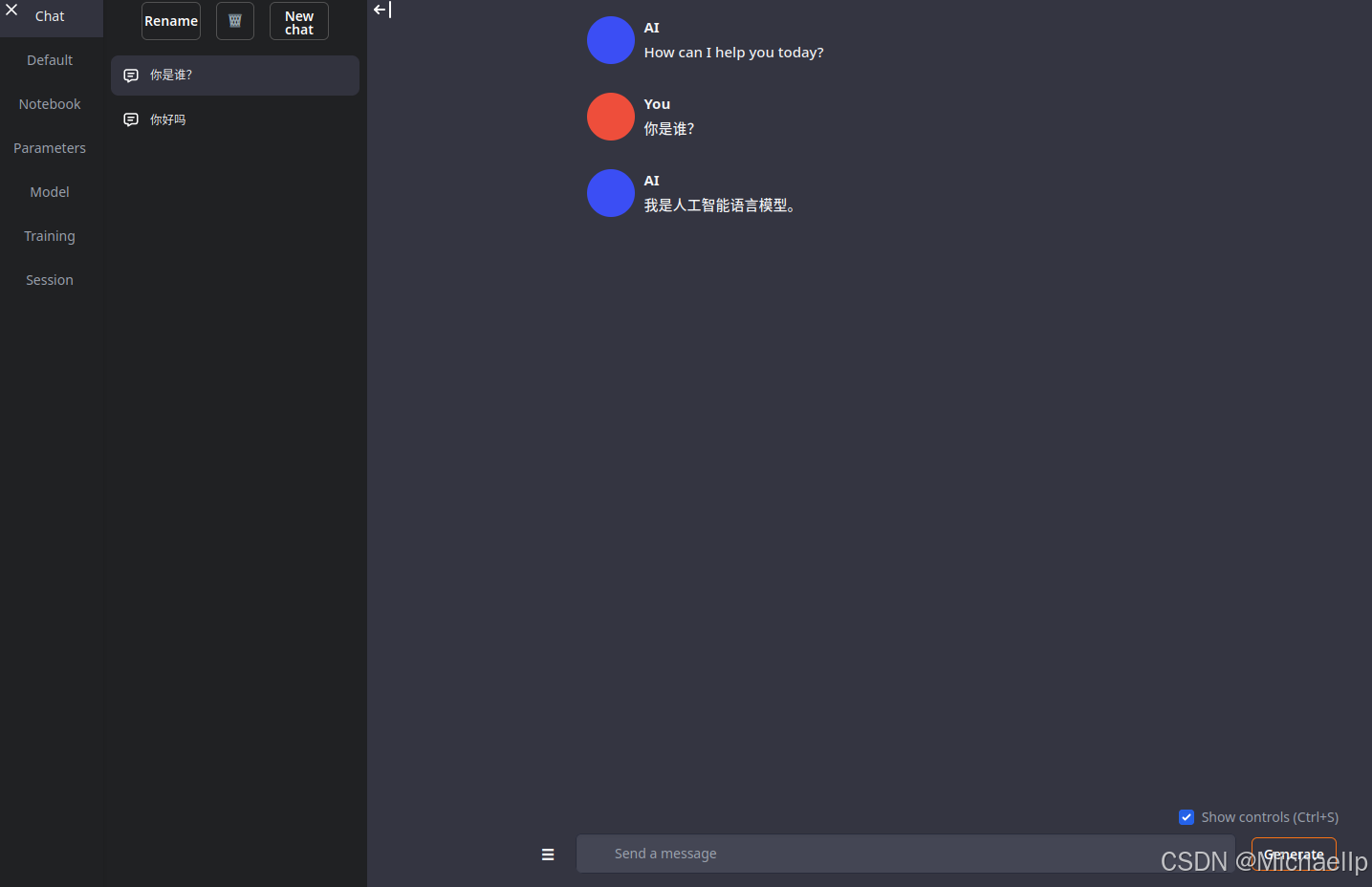
 返回Chat页面
返回Chat页面
总结
测试部分没法做到每次都能回答中文,有时会回答英文,有可能训练集太少。
这里的训练集和验证集我偷懒, 全部用一种。训练集通常占比75%,验证集占比25%。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









