









文章导航
一、 jdbc -> dbUtils -> myBatis
1.传统jdbc
主要问题:数据库连接频繁创建和释放浪费资源影响性能;sql语句硬编码不易维护;手动封装结果集。
// 代码示例
public class javaTest {
public static void main(String[] args) {
String URL="jdbc:mysql://127.0.0.1:55111/softiptdb?useUnicode=true&characterEncoding=utf-8";
String USER="admin";
String PASSWORD="12345";
//1.加载驱动程序
Class.forName("com.mysql.jdbc.Driver");
//2.获得db连接
Connection conn=DriverManager.getConnection(URL, USER, PASSWORD);
//3.通过数据库的连接操作db,实现CRUD(使用Statement类)
Statement st=conn.createStatement();
String sql = "select * from uc_operate_log limit 100";
ResultSet rs=st.executeQuery(sql);
//4.手动封装返回结果(使用ResultSet类)
FsiptUser fu = new FsiptUser();
while(rs.next()){
fu.setId(rs.getInt("id"));
fu.setUserCode(rs.getString("emp_code"));
fu.setUserAccount(rs.getString("module"));
...
}
//关闭db连接、释放资源
rs.close();
st.close();
conn.close();
}
}
2.dbUtils
common-dbutils是Apache提供的一个开源jdbc类库。对jdbc进行了简单的封装,极大简化了jdbc编码的工作量,成为很多公司的选择。但是dbutils对sql语句的操作仍然是硬编码,仍然需要手动封装结果集。
dbutils的使用:
- 需要导入的jar包:mysql驱动+c3p0包+DbUtils包;
- 添加c3p0配置文件;
- 可以自行添加一个jdbcUtils类用来获取c3p0连接池对象。(c3p0是一个开源jdbc连接池,与dbcp的主要区别是有自动回收空闲连接功能)
// 代码示例
public class javaTest {
public static void main(String[] args) {
// 首先创建一个QueryRunner对象,传入参数为连接池(例如c3p0连接池)
QueryRunner runner = new QueryRunner(JdbcUtils.getDataSource());
String sql = "select * from uc_operate_log limit 100";
// 执行SQL语句,并且针对不同的SQL语句使用不同的结果集处理器
// QueryRunner对象会自动关闭db连接
Object result[] = (Object[]) runner.query(sql, new ArrayHandler());
System.out.println(result[0) + "-" + result[1];
}
}
3.mybatis
mybatis是一个基于ORM(对象-关系映射,将数据库映射为对象)的半自动(半自动的个人理解:部分sql仍需自己编写和优化)轻量级持久框架。mybatis中的sql和java编码分开,功能边界清晰,一个专注业务一个专注db。

// 代码示例
// 客户端
public class javaTest {
public static void main(String[] args) {
try {
// 1、读配置文件
InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml");
// 2、构建SqlSessionFactory
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
// 3、打开SqlSession
SqlSession session = sqlSessionFactory.openSession();
// 4、获取Mapper对象
UcOperateLogMapper ucOperateLogMapper = session.getMapper(UcOperateLogMapper.class);
// 5、操作db
List<UcOperateLog> ucOperateLogs = ucOperateLogMapper.selectByCode("S67190");
} catch (IOException e) {
e.printStackTrace();
}
}
}
// model类
public class UcOperateLog {
private Integer id;
private String empCode;
private String module;
private String operate;
private String info;
private Byte result;
private Date createTime;
}
// mapper类
public interface UcOperateLogMapper {
List<UcOperateLog> selectByCode(String empcode);
}
// sql语句(xml)
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="mapper.UcOperateLogMapper" >
<resultMap id="BaseResultMap" type="model.UcOperateLog" >
<!--
WARNING - @mbg.generated
-->
<id column="id" property="id" jdbcType="INTEGER" />
<result column="emp_code" property="empCode" jdbcType="VARCHAR" />
<result column="module" property="module" jdbcType="VARCHAR" />
<result column="operate" property="operate" jdbcType="VARCHAR" />
<result column="info" property="info" jdbcType="VARCHAR" />
<result column="result" property="result" jdbcType="TINYINT" />
<result column="create_time" property="createTime" jdbcType="TIMESTAMP" />
</resultMap>
<select id="selectByCode" resultMap="BaseResultMap">
select * from uc_operate_log where emp_code = #{empcode, jdbcType=VARCHAR}
</select>
</mapper>
// 配置文件1(mybatis-config.xml)
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<properties resource = "db.properties"></properties>
<environments default = "development">
<environment id = "development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="UcOperateLogMapper.xml"/>
</mappers>
</configuration>
// 配置文件2(db.properties)
driver=com.mysql.jdbc.Driver
url=jdbc:mysql://{主机名/IP}:{端口}/softiptdb?characterEncoding=utf-8
username=admin
password=12345
二、mybatis三大核心流程

- 初始化阶段。读取xml和注解中的配置信息,创建配置对象并完成各模块初始化工作。
- 代理阶段。回想一下mybatis使用,在进行CRUD的时候,为什么可以直接使用Mapper接口,而不需要实现类?答案就是jdk的动态代理:我们将Mapper接口传给jdk的动态代理,然后动态代理会返回一个实例。
- 数据处理阶段。通过SqlSession完成sql解析、参数映射、sql执行和结果的反射解析。
三、mybatis关键源码解读
mybatis的关键步骤上面的例子已经给出了,下面就直接开始源码之旅。
1.mybatis源码编译
首先下载mybatis源码以及mybatis-parent:
https://github.com/mybatis/mybatis-3
https://github.com/mybatis/parent
其中mybatis-parent是mybatis的依赖项,因此要先编译mybatis-parent(成功后在本地maven目录生成可用jar),再编译mybatis。具体过程这里不费口舌了,网上有不少文章可以参考。可以直接在idea里maven build,也可以利用cmd的命令mvn clean build。这里墙裂建议下载相同版本的mybatis和mybatis-parent。否则的话,可能会遇到很多蛋疼问题。
然后我们就可以IDEA import project 打开mybatis工程,然后在IDEA里面进行编译、甚至运行main函数的操作了。
为了代码的调试,建立一个简单的main函数,以及一些基本的model、mapper和配置文件。项目机构和目录如下:
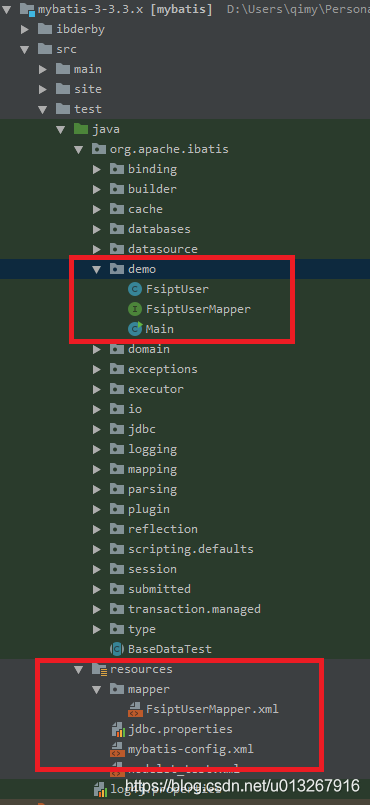
FsiptUserMapper.xml里是一个很简单的查询语句:

mybatis-config.xml文件:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<properties resource="jdbc.properties"></properties>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="mapper/FsiptUserMapper.xml"/>
</mappers>
</configuration>
jdbc.properties:
driver=com.mysql.cj.jdbc.Driver
url=jdbc:mysql://xxx.mysql.db.fat.qa.nt.xxx.com:55222/xxxdb
username=root
password=123456
由于我本地没有装mysql,用的是远端数据库,因此还要在pom中引入mysql-connector:
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.16</version>
</dependency>
至此,准备工作全部完成,源码debug我们来了!
2.mybatis中数据源和sql语句的获取
每个基于 MyBatis 的应用都是以一个 SqlSessionFactory 的实例为核心的。下面从XML 文件中构建 SqlSessionFactory ,并获取session进行一次最简单的查询:
public class Main {
public static void main(String[] args) {
try {
String resource = "resources/mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession session = sqlSessionFactory.openSession();
FsiptUserMapper mapper = session.getMapper(FsiptUserMapper.class);
FsiptUser fsiptUser = mapper.selectUser("S67190");
System.out.println(fsiptUser.toString());
}catch (Exception e){
}
}
}
首先,在获取session之后打个断点,看看session里都有些什么:
发现数据源dataSource:

发现sql信息:

这说明解析数据库和sql语句是在这里完成的:
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
啪的一下debug进去,很快啊,发现了用来解析mybatis-config文件的parseConfiguration方法:
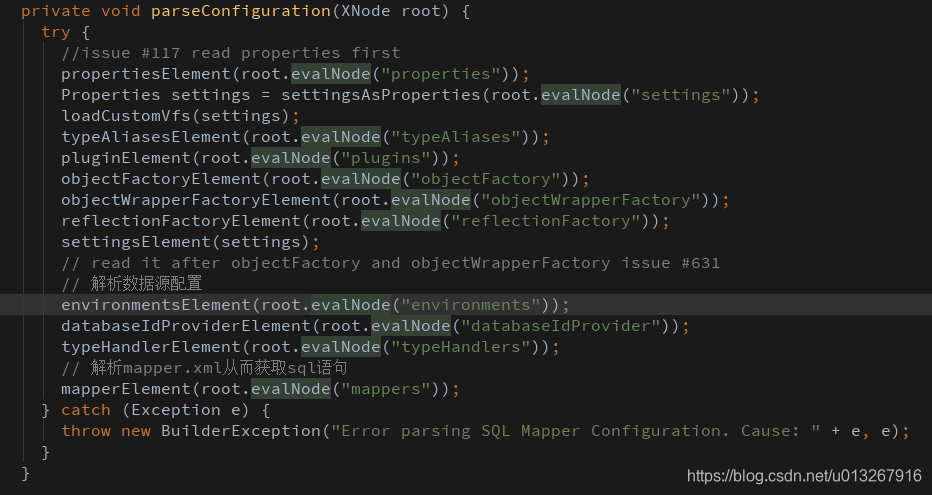
清楚地看到了mybatis-config.xml中<environment>和<mappers>标签是在哪里解析的。每一步的debug最好多留意一下变量,有助于对某行代码功能的理解。最后,不难整理出mybatis加载数据库配置文件和sql语句的大致路线:

3.获取mapper动态代理和sql语句的执行
首先是利用sqlSessionFactory获取session,这里没什么好说的,值得注意的是这里进行了mybatis执行器的选择,默认选择simple类型的执行器:

获取到session之后,就是sql语句的执行了:
FsiptUserMapper mapper = session.getMapper(FsiptUserMapper.class);
FsiptUser fsiptUser = mapper.selectUser("S12345");
可以看到,执行selectUser方法的是mapper。众所周知,只有类的实例可以执行方法,mapper只是一个接口:
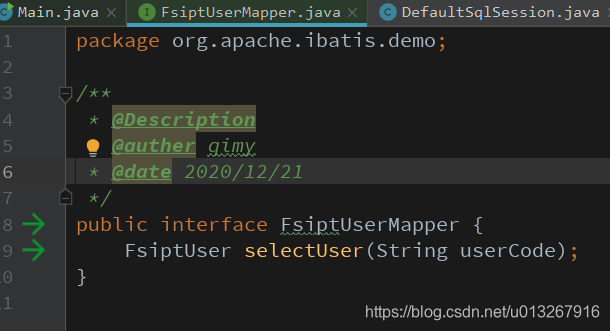
debug看一下mapper的类型就知道,这里的mapper是一个代理类:

mybatis使用了jdk动态代理来获取mapper代理类。关于jdk代理的知识这里不多说了,网上有很多写的很好的资料。下面详细探究下获取mapper代理类的过程:

debug进去,getMapper方法的实现类是DefaultSqlSession:

debug进入到了Configuration类,从mapperRegistry中继续getMapper:

这里会有疑问,为什么mapperRegistry能getMapper?注意到类名——Configuration,由此mapperRegistry中的mapper很可能是在最初加载db和sql资源的时候赋值进去的,再跑到new SqlSessionFactoryBuilder().build(inputStream)的过程里搜查一番,果然发现猫腻:
在
SqlSessionFactoryBuilder.build(java.io.InputStream) =》XMLConfigBuilder.parse =》XMLConfigBuilder.parseConfiguration =》XMLConfigBuilder.mapperElement =》mapperParser.parse() 的bindMapperForNamespace方法中:
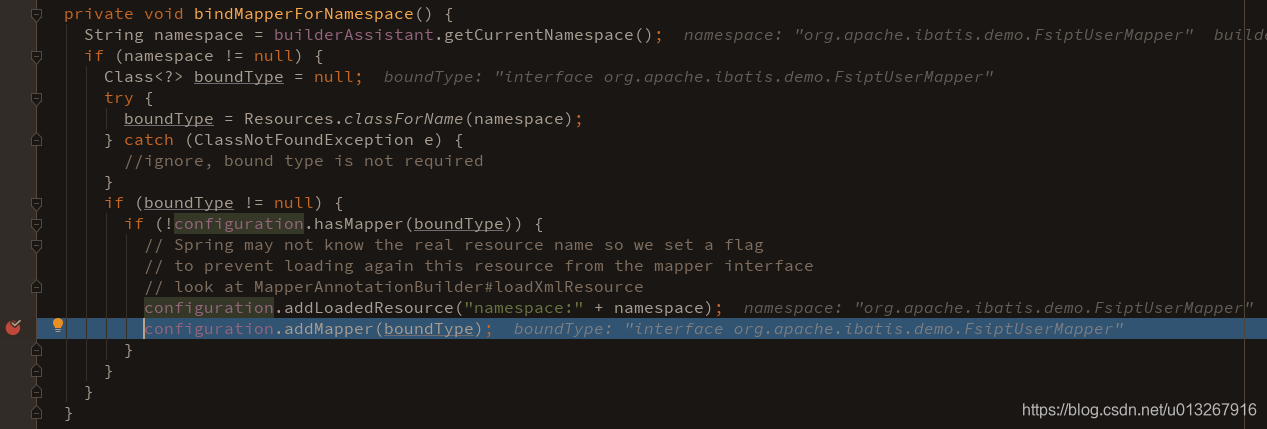
从图中的调试过程也可以看到,addMapper的参数是我们定义查询语句的mapper接口,再点进这个addMapper方法一看,正是给mapperRegistry.addMapper,而且就在紧挨着刚才mapperRegistry.getMapper:

接着回头继续看mapperRegistry.getMapper的过程:

显然,这里就是通过mapperProxyFactory生成代理类实例的地方了,debug进去就看到了jdk动态代理获取代理类实例的“案发现场”:

这里的mapperProxy就是mapper代理类的实例了,看一眼这个实例对应的类:
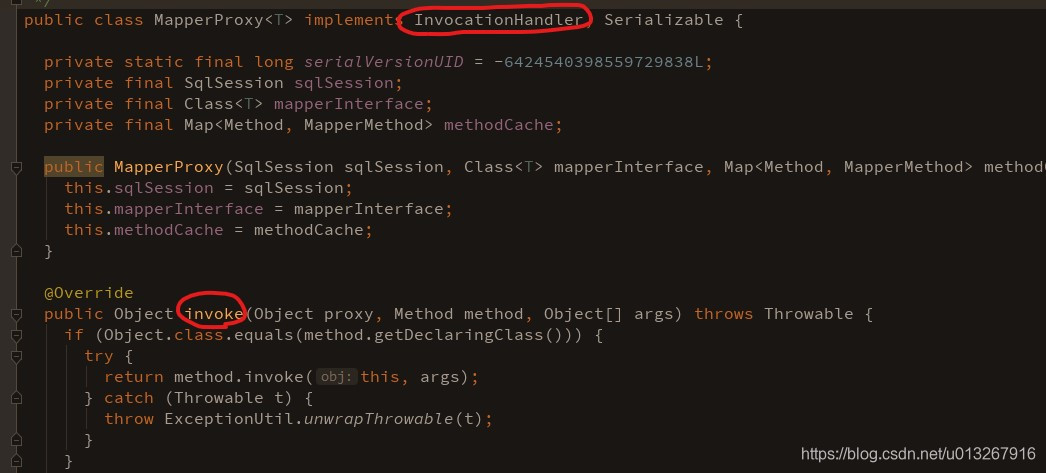
实现了InvocationHandler,重写了invoke,所以是代理类无疑啦。到此,获取代理类实例的过程就结束了。接下来要干什么路人皆知:调用代理类实例完成查询工作:

debug进去,不出意外正是上面那个invoke方法:

在这个方法里,sql语句终于被执行了:
mapperMethod.execute(sqlSession, args)
4.查询结果的映射(db对象->java对象)
接下来的execute方法就是重中之重了,debug进去看到了crud种类的判断,本文中查询的是单个对象,最终执行了sqlSession的selectOne方法:
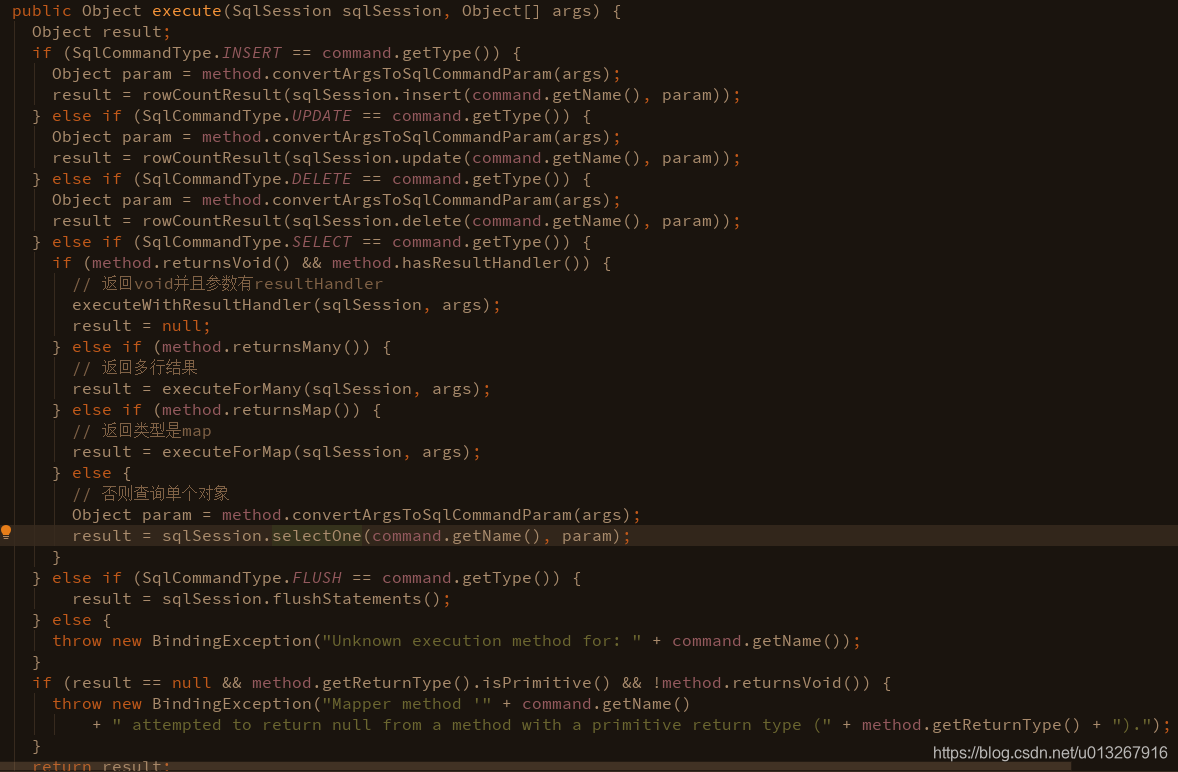 selectOne方法的详细过程这里不细说了,感兴趣的话可以自己亲自debug。这里想着重提一下的是查询结果的映射和包装:
selectOne方法的详细过程这里不细说了,感兴趣的话可以自己亲自debug。这里想着重提一下的是查询结果的映射和包装:
selectOne方法会执行到:

stmt是java.sql.Statement类的一个实例,可以认为这个stmt负责所有和数据库相关的操作,包括执行sql,包装和映射查询结果等等。继续debug:
进入handleResultSets后是DefaultResultSetHandler类,这里就是对查询结果的封装的地方了。看一下这个方法的实现:
public List<Object> handleResultSets(Statement stmt) throws SQLException {
ErrorContext.instance().activity("handling results").object(mappedStatement.getId());
final List<Object> multipleResults = new ArrayList<Object>();
int resultSetCount = 0;
// 调用getFirstResultSet获取第一个ResultSet,同时获取数据库的相关信息,包括表名、类型等等
ResultSetWrapper rsw = getFirstResultSet(stmt);
List<ResultMap> resultMaps = mappedStatement.getResultMaps();
int resultMapCount = resultMaps.size();
validateResultMapsCount(rsw, resultMapCount);
while (rsw != null && resultMapCount > resultSetCount) {
ResultMap resultMap = resultMaps.get(resultSetCount);
// 对结果集的封装
handleResultSet(rsw, resultMap, multipleResults, null);
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
String[] resultSets = mappedStatement.getResulSets();
if (resultSets != null) {
while (rsw != null && resultSetCount < resultSets.length) {
ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]);
if (parentMapping != null) {
String nestedResultMapId = parentMapping.getNestedResultMapId();
ResultMap resultMap = configuration.getResultMap(nestedResultMapId);
// 对结果集的封装
handleResultSet(rsw, resultMap, null, parentMapping);
}
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
}
return collapseSingleResultList(multipleResults);
}
其中ResultSetWrapper rsw = getFirstResultSet(stmt)方法的入参是一个Statement对象,这个对象包含了查询的结果。所以不仅获取了查询结果,还同时获取了db的各种信息:

这从ResultSetWrapper的构造方法中也可窥知一二:
public ResultSetWrapper(ResultSet rs, Configuration configuration) throws SQLException {
super();
// 类型转换的类
this.typeHandlerRegistry = configuration.getTypeHandlerRegistry();
this.resultSet = rs;
// 对应结果集的元数据
final ResultSetMetaData metaData = rs.getMetaData();
// 结果集的列数
final int columnCount = metaData.getColumnCount();
// 遍历每一列
for (int i = 1; i <= columnCount; i++) {
// 对应的列名添加到columnNames集合中
columnNames.add(configuration.isUseColumnLabel() ? metaData.getColumnLabel(i) : metaData.getColumnName(i));
// 对应的jdbctype添加到jdbctypes集合中
jdbcTypes.add(JdbcType.forCode(metaData.getColumnType(i)));
// 对应的列的类型添加到classNames集合中
classNames.add(metaData.getColumnClassName(i));
}
}
再往下,看到了封装结果集的方法:handleResultSet(rsw, resultMap, multipleResults, null); 进入这个方法,看到了查询结果(ResultSet)是如何转化为javabean的:
private void handleResultSet(ResultSetWrapper rsw, ResultMap resultMap, List<Object> multipleResults, ResultMapping parentMapping) throws SQLException {
try {
if (parentMapping != null) {
// 调用handleRowValues进行赋值
handleRowValues(rsw, resultMap, null, RowBounds.DEFAULT, parentMapping);
} else {
if (resultHandler == null) {
DefaultResultHandler defaultResultHandler = new DefaultResultHandler(objectFactory);
// 处理数据,并将结果存储在ResultHandler上,最终保存在multipleResults中
handleRowValues(rsw, resultMap, defaultResultHandler, rowBounds, null);
multipleResults.add(defaultResultHandler.getResultList());
} else {
handleRowValues(rsw, resultMap, resultHandler, rowBounds, null);
}
}
} finally {
// issue #228 (close resultsets)
closeResultSet(rsw.getResultSet());
}
}
进入handleRowValues(rsw, resultMap, defaultResultHandler, rowBounds, null); debug下去依次是:handleRowValues -> handleRowValuesForSimpleResultMap -> getRowValue,这个getRowValue方法就是对每一个字段进行解析的:
private Object getRowValue(ResultSetWrapper rsw, ResultMap resultMap) throws SQLException {
final ResultLoaderMap lazyLoader = new ResultLoaderMap();
// 创建简单Java bean
Object resultObject = createResultObject(rsw, resultMap, lazyLoader, null);
// 如果结果无直接的类型处理器,则进行字段映射
if (resultObject != null && !typeHandlerRegistry.hasTypeHandler(resultMap.getType())) {
final MetaObject metaObject = configuration.newMetaObject(resultObject);
boolean foundValues = !resultMap.getConstructorResultMappings().isEmpty();
// 是否使用自动映射
if (shouldApplyAutomaticMappings(resultMap, false)) {
foundValues = applyAutomaticMappings(rsw, resultMap, metaObject, null) || foundValues;
}
// 通过MetaObject,进行属性值反射设置
foundValues = applyPropertyMappings(rsw, resultMap, metaObject, lazyLoader, null) || foundValues;
foundValues = lazyLoader.size() > 0 || foundValues;
resultObject = foundValues ? resultObject : null;
return resultObject;
}
return resultObject;
}
这里面就不详细写过程了,其中涉及到变量“驼峰法则”的检测、对null值的处理等等:
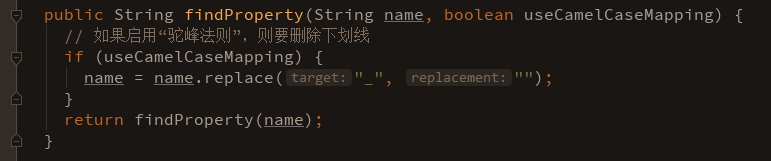
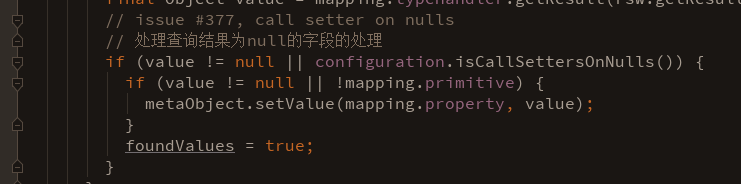
最终,mapper代理类的invoke方法执行完之后,成功获取到了已经包装成javabean的查询结果:

5.一次通过源码阅读解决问题的过程
在最初的源码编译和调试过程中,我的查询结果是这样的:

可以看到,一共18个字段,只有框出来的这5个字段是有值的,其余全部是null。why?下面我们抛弃百度自己动手,通过源码debug找到答案。
先简单分析一下,phone字段是查到值的,说明mybatis读取、解析db配置和sql是没有问题的,最有可能出问题的地方是对db查询结果的处理(映射)这一过程。从前文对源码的学习过程中我们知道,处理查询结果的地方是在handleResultSets(Statement stmt)方法中:

从db中查询到的结果(ResultSet)就包含在rsw对象中。接下来的流程上面也分析过了:
handleResultSet -> handleRowValues -> handleRowValuesForSimpleResultMap -> getRowValue。那我们到getRowValue方法中看一下。从下图中看到:getRowValue方法中首先初始化了一个javabean:resultObject,此时这个resultObject是全部为空的:

再往下debug,看一下映射完成后的resultObject,只有5个字段有值:
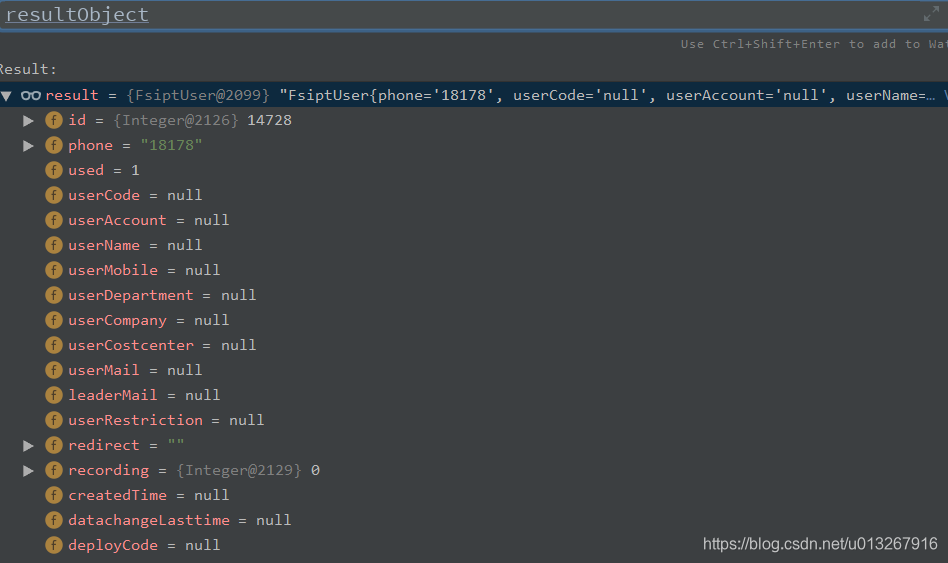
这证实了最初的猜测,正是映射过程发生了错误。接下来就容易了,对映射过程进行排查,发现只会对5个字段进行映射:

那当然是进入createAutomaticMappings方法看看咯,这时候确定问题的原因就非常简单了,最终我们发现是根据“驼峰法则”映射时出的问题:
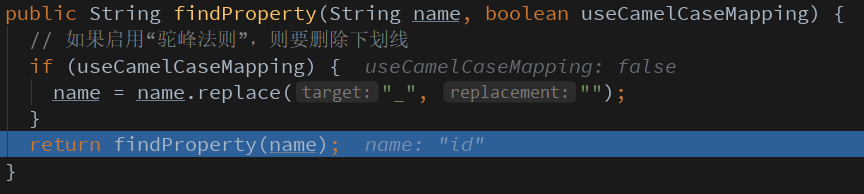
我们并没有配置开启驼峰法则,db中那些带下划线的字段就会映射失败,例如db中的“user_code”和javabean中的“userCode”无法对应。解决方法当然是开启驼峰配置:

然后看下查询结果是不是搞定了:
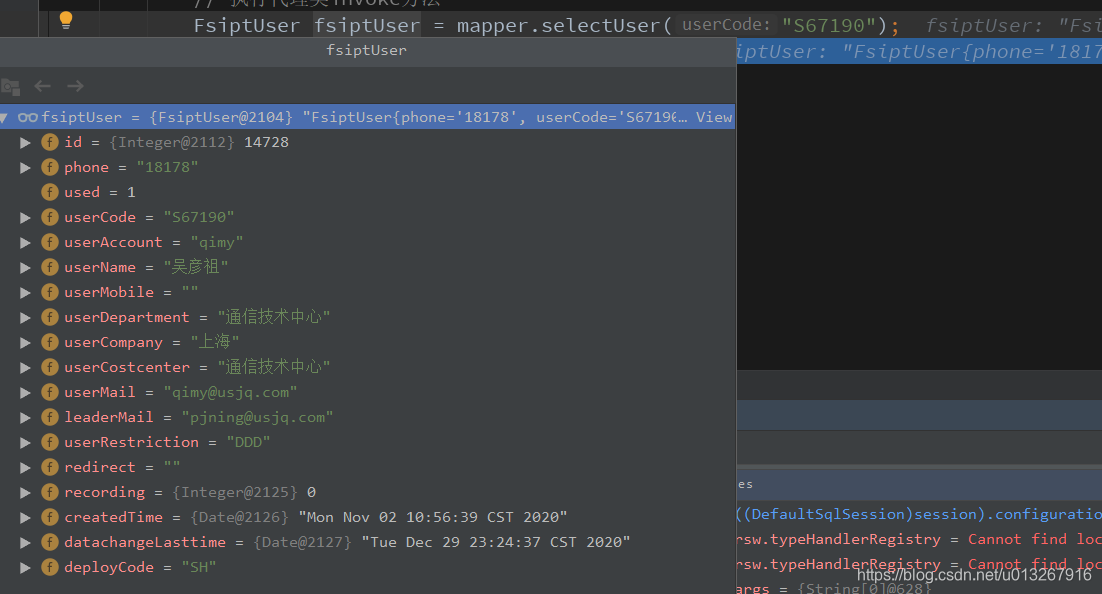
目的同样是解决问题,通过对源码debug可以做到,通过百度或者google可能也能做到,借用一下混元形意太极掌门马宝国的名言:劝诸位耗子尾汁!
下一篇mybatis源码分享见。














 315
315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









