







Hadoop
1. 什么是大数据 ?
- 在互联网时代,日常生的衣食住行,都会围绕网络进行展开,如,淘宝、拼多多、京东等知名电商。
- 脑补一下日常在电商中购买商品的流程,假设你要购买一台笔记本,或者衣服,你会怎么做? 试想一下,各大电商平台怎么收集这些 用户行为?
- 在大胆想象一下,与此 相同操作 有1000w同时发生人会怎么样 ?
-
由简入深来理解这句话: 大数据,就是对 海量数据 进行分析处理 的技术。
- 各大电商门户网站,如何收集 用户行为数据, 这些数据怎么样体现 ?
- 下列数据看起来是不是没有头绪?怎么从这些数据中提取 隐形价值。

-
数据量大和数据量不大时产生的效果:
- 在互联网工业2.0时代,各行各业中,有庞大的用户量,都会产生海量的数据 (用户行为数据) 而这些数据含有丰富的商业价值,所以,各行业都想对这些数据进行分析、挖掘。 这些数据过于庞大,种类多样,用传统的处理技术难以胜任,所以由需求就催生了一套处理海量数据的技术——大数据技术。
- 数据量大是大数据具有价值的前提。当数据量不够大时,它们只是离散的“碎片”,人们很难读懂其背后的故事。随着数据量不断增加,达到并超过某个临界值后,这些“碎片”就会在整体上呈现出规律性,并在一定程度上反映出数据背后的事物本质。这表明,数据量大是数据具有价值的前提,大数据具有大价值。大数据的“大”是相对的,与所关注的问题相关。通常来说,分析和解决的问题越宏观,所需要的数据量就越大。
-
简单的想一想: 互联网给我们带来了什么便利的地方!?
2. 啥是Hadoop ?
-
这个好理解,就是上面说得处理海量数据,大数据技术中的其中一种,且 Hadoop 包含一些核心组件。
- HDFS: 分布式文件系统,解决海量数据的分布式 存储问题;
- MapReduce: 分布式计算系统。 解决海量数据的分布式计算问题。
- Yarn: 分布式资源调度平台。 解决分布式计算系统(MapReduce),在各个集群中的启动,分配,提高了集群利用率,资源统一管理,共享带来好处。
-
扩展一下: 在Hadoop 核心之上,又开发了大量的相关组件,可以方便解决一些场景问题:
- Hive : 可以通过写sql 在hadoop平台上进行数据分析。
- Hbase: 基于hdfs底层存储的分布式数据库系统。
- Flume :日志采集系统。
- Sqoop: 数据迁移工具。
3. 文件存储的设计
3.1 纵向扩展
- 增加存储空间的操作。
- 局限性:硬件的扩展是有物理上限的。
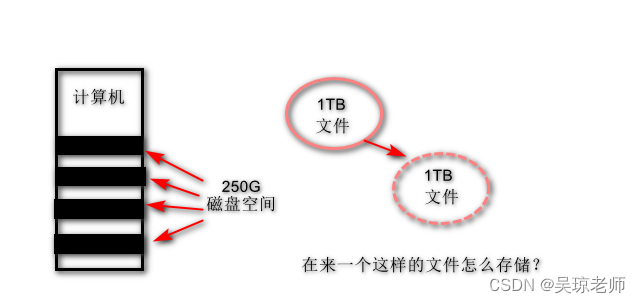
3.2 横向存储
- 增加磁盘空间不行,那就增加计算机的数量。
- 新问题产生:通过文件切块和横向存储的手段,可以解决大文件存储问题 ,但是,文件需要读写使用,怎么寻找这些 文件块具体的位置 !?
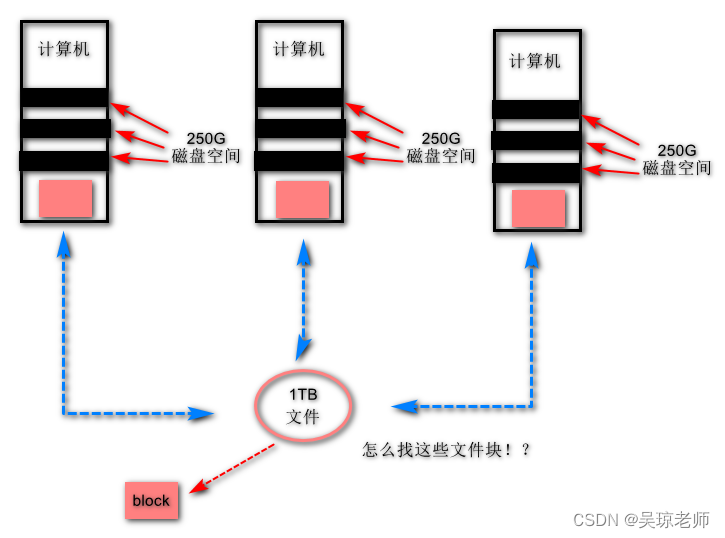
3.3 HDFS 简要设计思想
-
针对文件越来越多,涉及到的文件块也越多,怎么 管理文件存储 才是重中之重 。
- 假设 让你来设计,你会怎么解决 HDFS 出现这样的的问题 ?
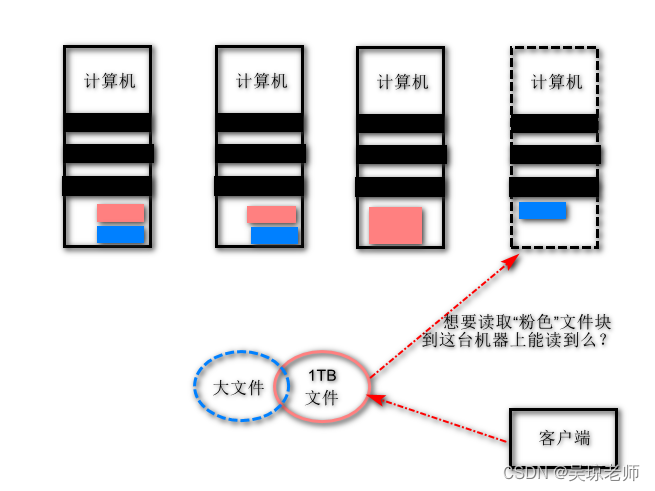
- 假设 让你来设计,你会怎么解决 HDFS 出现这样的的问题 ?
-
从而引出新的词汇 NameNode, DateNode。
- 新的管理者出现: 大家还记得小时候一般找东西找不到了,你会问谁 ?
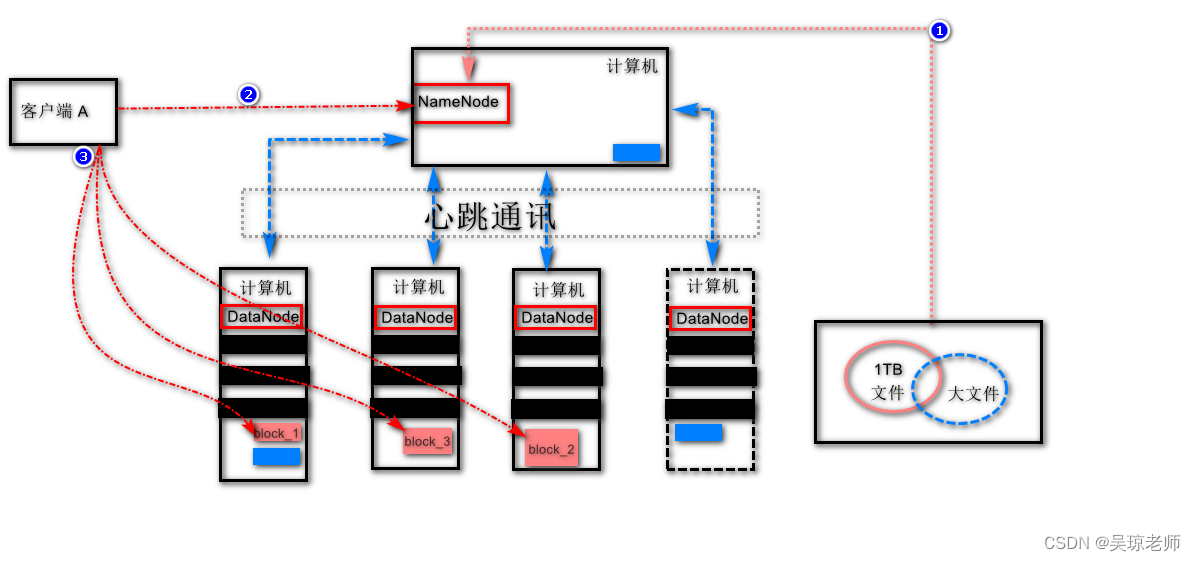
3. 解释说明:
- 文件切块时,存储先询问
NameNode这个管家,询问我的文件块存在哪个位置 !?,得到回复后才可以存储block文件块,到相对应得机器上。 - 客户端读取数据时,先询问
NameNode我要读的文件在哪些DataNode节点上存储?得到回复才能去读取。 NameNode给出准确的block_1,block_2...的存储路径位置,客户端根据位置去读取。
3.4 NameNode应该具备的职能
- 这样看来NameNode相当重要,你认为它该具备什么样的能力 !
- 结合上述,思考一下你认为的!
- 操作提示: 非正常编辑模式下退出 会生成
.swp文件 ls -a显示全部,删除文件即可。
4 安装虚拟机VMware
- 直接参考 VMware安装中第一步,只需要参考[准备安装即可]。
- 然后挂载已经安装好的CentOs即可使用。
5. Linux服务器的基本配置
5.1 关闭防火墙
- 关闭防火墙使用linux命令。
- 提示: 临时关闭防火墙可以和永久关闭防火墙 配合使用。
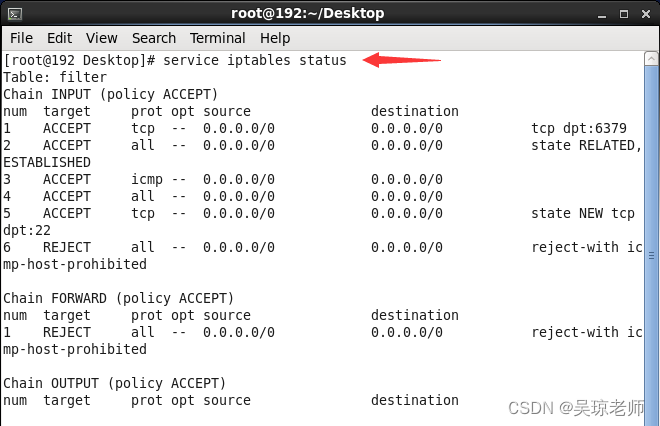
查看防火墙状态
service iptables status
临时关闭防火墙(重启失效)
service iptables stop // 关闭
service iptables satrt //启动
永久关闭防火墙(重启生效)
chkconfig iptables off //关闭
chkconfig iptables on //开启
5.2 配置主机名称 hostname
- 配置Linux主机名称,固定主机名称。
- 提示:为了避免重启,可以 配合使用。
1.vim 编辑器使用说明:
1.1 i 相当于进入编辑模式
1.2 退出 ESC
:wq 3个字符,按 Enter 表示保存退出。
:q 2个字符,按 Enter 表示不保存退出,
注意:前提是没有编辑任何内容,否则vim不会让退出。
:q! 3个字符,按 Enter 表示不保存强制退出。
1.查看当前主机名称
hostname
2.修改主机名文件(重启生效)
vim /etc/sysconfig/network
3.临时生效
hostname 新主机名称
5.3 配置host文件
-
配置主机域名映射,需要在配置之前把主机
ip固定。- 提示: 在挂载系统之后,虚拟机与本地机器 ping正常情况下,查看此状态,并将下面地址设置成为固定ip地址(以免每次重启ip发生改变,映射也会变)。
- 注意,要首先确保你虚拟机网络连接是NAT模式和主机共享网络。
- 直接参考 VMware安装,只需要参考第3步骤即可。
1. 修改主机域名映射 vim /etc/hosts 示例: 主机ip + 主机名称 192.168.150.130 hadoop01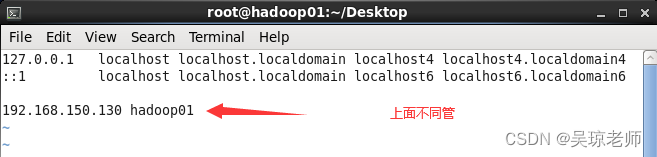
5.4 配置免密钥登录
-
在多台机器之间登录需要验证信息,所以需要配置免验证。
ssh-keygen一直回车- 发送密钥到机器(如果多台机器需要相互发送)
ssh-copy-id root@目标地址ip - 未配置免密钥如下:需要输入密码,比较麻烦。
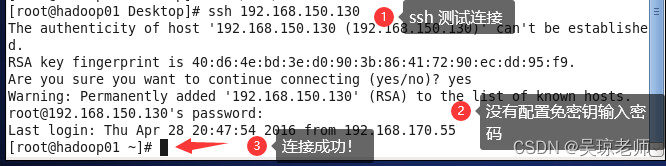
exit,退出连接操作,回到本机。 1. ssh-keygen 一直回车 1.1 ssh-copy-id root@ 192.168.150.130
5.5 配置JDK环境变量
-
hadoop也需要jdk的支持,所以在linux上需要配置jdk。
- 上传jdk文件包
jdk-8u121-linux-x64.tar.gz,linux下运行,一般会根目录/usr创建一个java文件夹存放上传文件。 - 可以有两种方式, 第一,直接拖拽过去,第二,使用
xshell连接工具。
1. 通过Xshell ftp 上传功能将jdk上传到指定目录, cd /usr/java 1.1 ls 或者 ll 显示所以文件 1.2 解压tar包, tar zxvf jdk-8u121-linux-x64.tar.gz 2. pwd 可以查看当前路径 目的: 记住路径好配置环境变量。/usr/java/jdk1.8.0_121 3. vim /etc/profile 编辑环境变量文件,在文件最底部加上如下内容: JAVA_HOME=/usr/java/jdk1.8.0_121 PATH=$JAVA_HOME/bin:$PATH CLASSPATH=$JAVA_HOME/jre/lib/ext:$JAVA_HOME/lib/tools.jar export PATH JAVA_HOME CLASSPATH
- 上传jdk文件包
-
然后使用
source /etc/profile可以使配置的文件生效,相当于家长配置文件。- 使用命令
javac或者java -version验证
- 使用命令
6. Hadoop伪分布式的基本配置
- 前期学习,采用伪分布式属于采用多个线程方式模拟hadoop环境,后期我们会按照HadoopHA模式即完全分布式。
- 注意,配置之前,上传
hadoop-2.8.1.tar.gz到/usr/java中,并解压。
- 注意,配置之前,上传
6.1 配置 hadoop-env.sh
-
hadoop-env.sh,主要是修改hadoop运行环境配置变量。- 目的,是让hadoop找到相关依赖的环境变量,如,
jdk1.8.0_121路径。
1. /usr/java/hadoop-2.8.1/etc/hadoop 需要进入此目录下修改。 1.1 主要修改两个配置 JAVA_HOME 和 HADOOP_CONF_DIR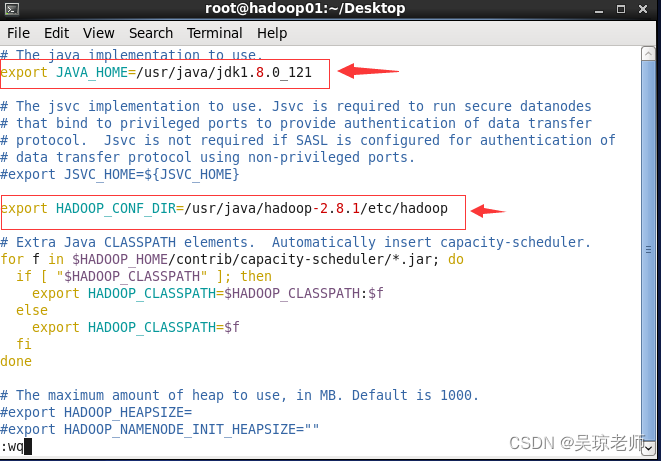
- 目的,是让hadoop找到相关依赖的环境变量,如,
6.2 配置 core-site.xml
core-site.xml,全局参数文件,用于定义系统级别的参数,如HDFS URL 、Hadoop的临时目录等。- 核心参数配置,HDFS的URI
fs.defaultFS参数值:hdfs://hd01:9000
- 核心参数配置,HDFS的URI
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/java/hadoop-2.8.1/tmp</value>
</property>
</configuration>
6.3 配置 hdfs-site.xml
hdfs-site.xml,配置hdfs的备份策略,和文件读取权限等。- 核心参数配置 备份策略:
dfs.replication现在伪分布式 1,如果完全模式是3。 - 还可以设置切块大小,一般默认128M,设置参数
dfs.blocksize值如268435456 (256M)。
- 核心参数配置 备份策略:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
6.4 配置 mapred-site.xml
mapred-site.xml,MapReduce的核心配置文件。- 注意:参数模板文件 将
mapred-site.xml.template文件模板修改为mapred-site.xml cp mapred-site.xml.template mapred-site.xml相当于拷贝命令。
- 注意:参数模板文件 将
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
6.5 配置 yarn-site.xml
yarn-site.xml,yarn的核心配置文件。- 配置目的:
ResourceManager ,nodeManager的通信端口。
- 配置目的:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
6.6 配置 slaves文件
slaves, 集群“小弟”机器,因为是伪分布式中。- 参数:当前就一台所有只配一个,后期完全分布有几个配几个。
- 参数:当前就一台所有只配一个,后期完全分布有几个配几个。
6.7 配置 Hadoop环境变量
- 目的是可以在任意目录下执行hadoop命令。
- 配置文件: 同jdk配置目录
vim /etc/profile
- 配置文件: 同jdk配置目录
1.vim /etc/profile 编辑环境变量文件,在文件最底部加上如下内容:
JAVA_HOME=/usr/java/jdk1.8.0_121
HADOOP_HOME=/usr/java/hadoop-2.8.1
PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
CLASSPATH=$JAVA_HOME/jre/lib/ext:$JAVA_HOME/lib/tools.jar
export PATH JAVA_HOME CLASSPATH HADOOP_HOME

6.8 格式化 NameNode
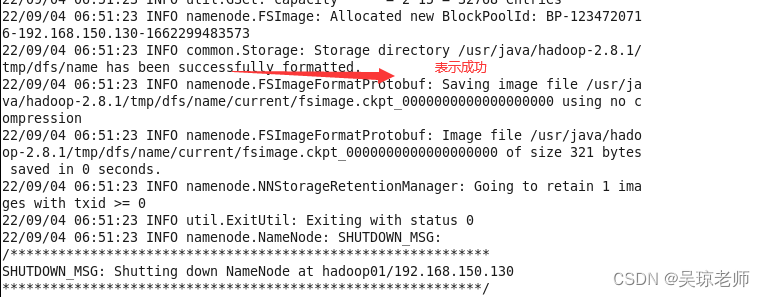
- 思考一个问题: 为什么要格式化
NameNode?- 格式化之前,重新启动一下系统,以免配置文件没有生效。
1.格式化命令
hadoop namenode -format
7. 启动Hadoop核心组件 hdfs
7.1 启动hdfs
- 注意:
etc/hadoop/sbin目录下是启动hadoop相关组件命令。- 第一次启动需要输入yes,以后则不需要。
1.启动命令 sh start-dfs.sh
- 执行
jps,查看进程命令。- 启动成功之后执行jps命令,如果发现以下进程则启动成功。

- 启动成功之后执行jps命令,如果发现以下进程则启动成功。
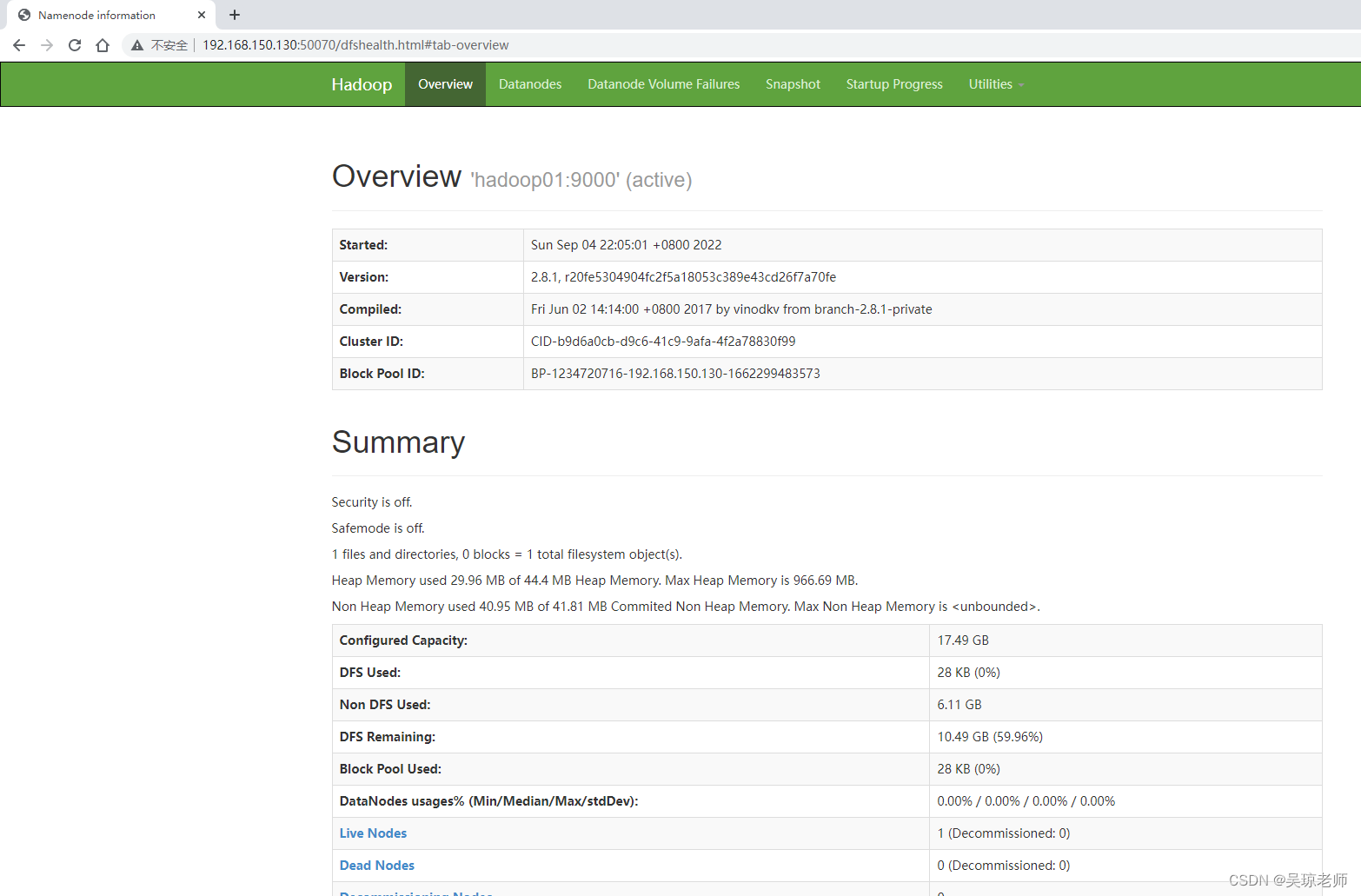
7.2 访问hadoop页面
- 访问地址,虚拟机主机ip地址+端口号
192.168.150.130:50070
7.3 hadoop版本
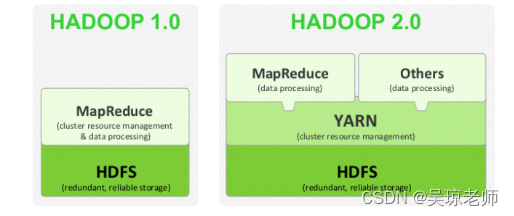
- 主要有三个版本 1.0 2.0 和 现在最新的3.0。其中1.0 到 2.0相当于一次整体提升。
- 1.0版本,hadoop两个核心模块: hdfs+MapReduce。
- 2.0版本, hadoop三个核心模块: hdfs+MapReduce+yarn。
8. Hdfs的基础指令
8.1 创建目录
- 使用hdfs 创建目录,语法格式:
hadoop fs -mkdir /目录名称- 扩展
hadoop fs -mkdir -p /a/b/c递归创建子目录。
- 扩展
1.逐级创建,单级目录:
hadoop fs -mkdir /aaa
hadoop fs -mkdir /aaa/bb
2. 递归创建多级目录:
hadoop fs -mkdir -p /a/b/c
8.2 查询目录下内容
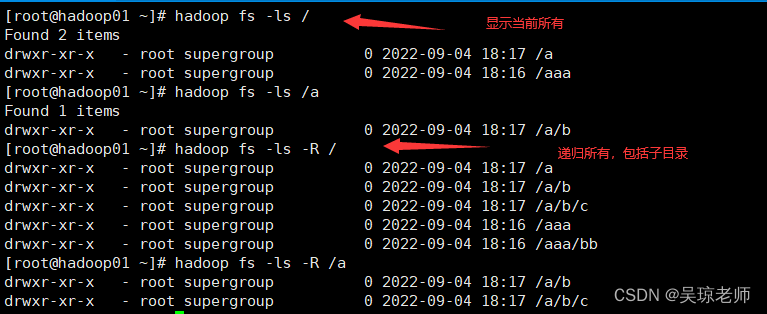
- 查看hdfs目录内容 语法格式 :
hadoop fs -ls /- 扩展
hadoop fs -ls -R /显示根目录下全部内容。
- 扩展
1.显示当前目录下文件:
hadoop fs -ls /
hadoop fs -ls /aaa
2.递归显示目录下所有文件,包含子目录:
hadoop fs -ls -R /
hadoop fs -ls -R /aaa
8.3 上传文件
- 从本地上传文件到hdfs上 语法格式 :
hadoop fs -put /文件目录/文件名 /hdfs目录- 扩展:
hadoop fs -copyFromLocal /文件目录/文件名 /hdfs目录,二者一样。
- 扩展:
1. 上传语法示例:
上传usr/1.txt 到 hdfs/aaa目录下
hadoop fs -put usr/1.txt /aaa
hadoop fs -copyFromLocal /usr/1.txt /aaa
2. 多文件上传示例:
上传usr/1.txt和2.txt 到 hdfs/a/b目录下
hadoop fs -put /usr/1.txt /usr/2.txt /a/b
hadoop fs -copyFromLocal /usr/1.txt /usr/2.txt /a
8.4 下载文件
- 从hdfs上指定目录下载到本地 语法格式 :
hadoop fs -get /hdfs目录/文件 /linux目录- 扩展:
hadoop fs -copyToLocal /hdfs目录/文件 /linux目录,二者一样。
- 扩展:
1. 下载语法示例:
下载从hdfs上下载1.txt 到usr/download/
hadoop fs -get /a/1.txt /usr/download/
hadoop fs -copyToLocal /a/1.txt /usr/download/
2. 多文件下载:
下载 hdfs /a 目录文件 1.txt 2.txt 到本地usr/download 目录下
hadoop fs -get /a/1.txt /a/2.txt /usr/download
hadoop fs -copyToLocal /a/1.txt /a/2.txt /usr/download
8.5 查看指定文件内容
- 查看hdfs上指定文件内容 语法格式 :
hadoop fs -cat /hdfs目录/文件- 扩展: 多文件查看
hadoop fs -cat /a/1.txt /a/2.txt
- 扩展: 多文件查看
1. 查看单个文件内容
hadoop fs -cat /a/1.txt
2. 查看多个文件内容
hadoop fs -cat /a/1.txt /a/2.txt
8.6 删除文件,文件目录
- 删除hdfs上指定,文件,文件目录(空),递归删除。
- 删除文件:
hadoop fs -rm /hdfs目录/文件 - 删除目录(空):
hadoop fs - rmdir /hdfs目录 - 递归删除: 有文件也删除。
hadoop fs -rmr /hdfs目录
- 删除文件:
1. 删除文件,根目录下的1.txt文件。
hadoop fs -rm /1.txt
2. 删除文件目录,前提,该目录为空。
如: 删除aaa目录下的空目录bb /aaa/bb
hadoop fs -rmdir /aaa/bb
3. 递归删除目录及文件
hadoop fs -rm -r /a
8.7 重命名和移动目录(文件)
- 在hdfs上,移动后只保留一份文件,
hadoop fs -mv用法有两种方向。- 重命名文件和文件目录:
hadoop fs -mv /源目标 /修改后目标 - 移动文件,到指定目录
hadoop fs -mv /源目录/文件 /移动后目标目录
- 重命名文件和文件目录:
1. 重命名文件名
hadoop fs -mv /1.txt /a.txt
2. 重命名目录
hadoop fs -mv /aaa /a
3. 移动文件并重命名文件,
如: /a.txt 移动到目录下 /aa 并修改文件名为aa.txt。
hadoop fs -mv /a.txt /aa/aa.txt
8.8 合并下载
- 将hdfs上得文件合并下载到本地磁盘。
- 语法格式:
hadoop fs -getmerge /hdfs目标目录/文件 ... ... /本地目录/合并命名新文件
- 语法格式:
1. 将hdfs 上不同目录的文件 合并下载到本地磁盘,并重写命名。
hadoop fs -getmerge /aa/2.txt /aa/3.txt /1.txt /usr/meger.txt
2. 将hdfs上/aa 目录下的 1.txt 和 2.txt 合并下载到 本地磁盘 /usr/ 并重名名 cola.txt
hadoop fs -getmerge /aa /usr/cola.txt
8.9 复制目录(文件)
- 在hdfs上,复制后相当于保留了源文件,
hadoop fs -cp用法有两种方向。- 复制目录(包含目录里文件):
hadoop fs -cp /源目录 /复制后目录 - 复制单个文件
hadoop fs -cp /目录/文件 /移动到目录/复制后文件名
- 复制目录(包含目录里文件):
1. 复制单个文件
hadoop fs -cp /1.txt /a.txt
2. 复制目录(包含目录下的文件)
hadoop fs -cp /aa /dd
8.10 检测文件块信息
- 检测hdfs上文件块信息。 这个文件块信息是谁保存的 ?
- 语法格式:
hadoop fsck /目录或者文件也可以省略
- 语法格式:
hadoop fsck /
hadoop fsck /aa
hadoop fsck /aa/1.txt
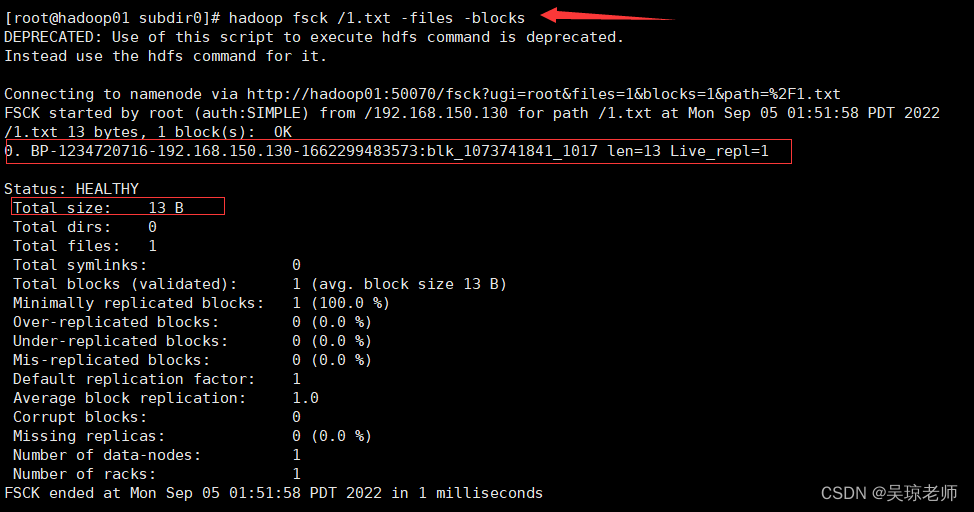
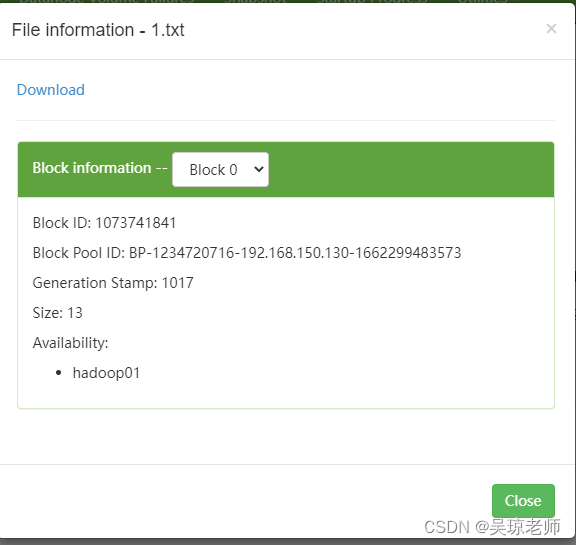
1.参数说明:
Total size: 代表/目录下文件总大小
Total dirs:代表检测的目录下总共有多少个目录
Total files:代表检测的目录下总共有多少文件
Total symlinks:代表检测的目录下有多少个符号连接
Total blocks(validated):代表检测的目录下有多少个block块是有效的
Minimally replicated blocks:代表拷贝的最小block块数
Over-replicated blocks:指的是副本数大于指定副本数的block数量
Under-replicated blocks:指的是副本数小于指定副本数的block数量
Mis-replicated blocks:指丢失的block块数量
Default replication factor: 3 指默认的副本数是3份(自身一份,需要拷贝两份)
Missing replicas:丢失的副本数
Number of data-nodes:有多少个节点
Number of racks:有多少个机架
















 1549
1549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











