









 本文揭秘如何解析律师执业诚信信息公示平台的DES加密跳转链接,并解决中文字体反爬问题,涉及JS逆向、字体识别与动态字典扩展策略。
本文揭秘如何解析律师执业诚信信息公示平台的DES加密跳转链接,并解决中文字体反爬问题,涉及JS逆向、字体识别与动态字典扩展策略。
某全国律师执业诚信信息公示平台 DES加密+中文字体反爬
目标网站:aHR0cHM6Ly9jcmVkaXQuYWNsYS5vcmcuY24v
该网站有跳转链接DES加密,中文字体反爬,滑块验证,点选验证,重点研究一下详情页跳转链接的DES加密和中文字体反爬,滑块和点选就不赘述了,网上一搜一大把。
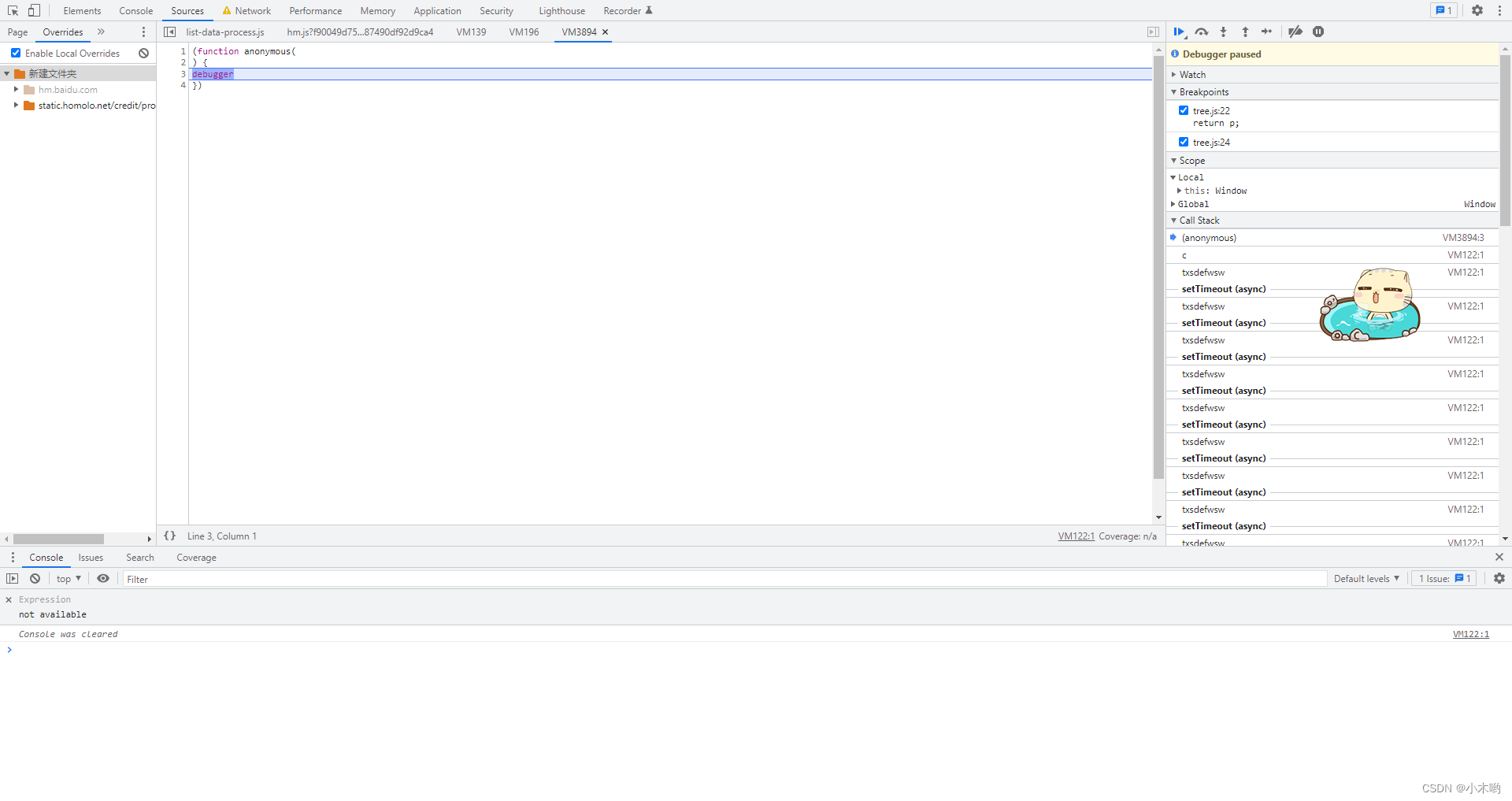
无限debugger
打开首页,输入关键词搜索,打开F12,来到反调试无限debugger,无限debugger怎么过也不赘述了,我选择重写JS文件。
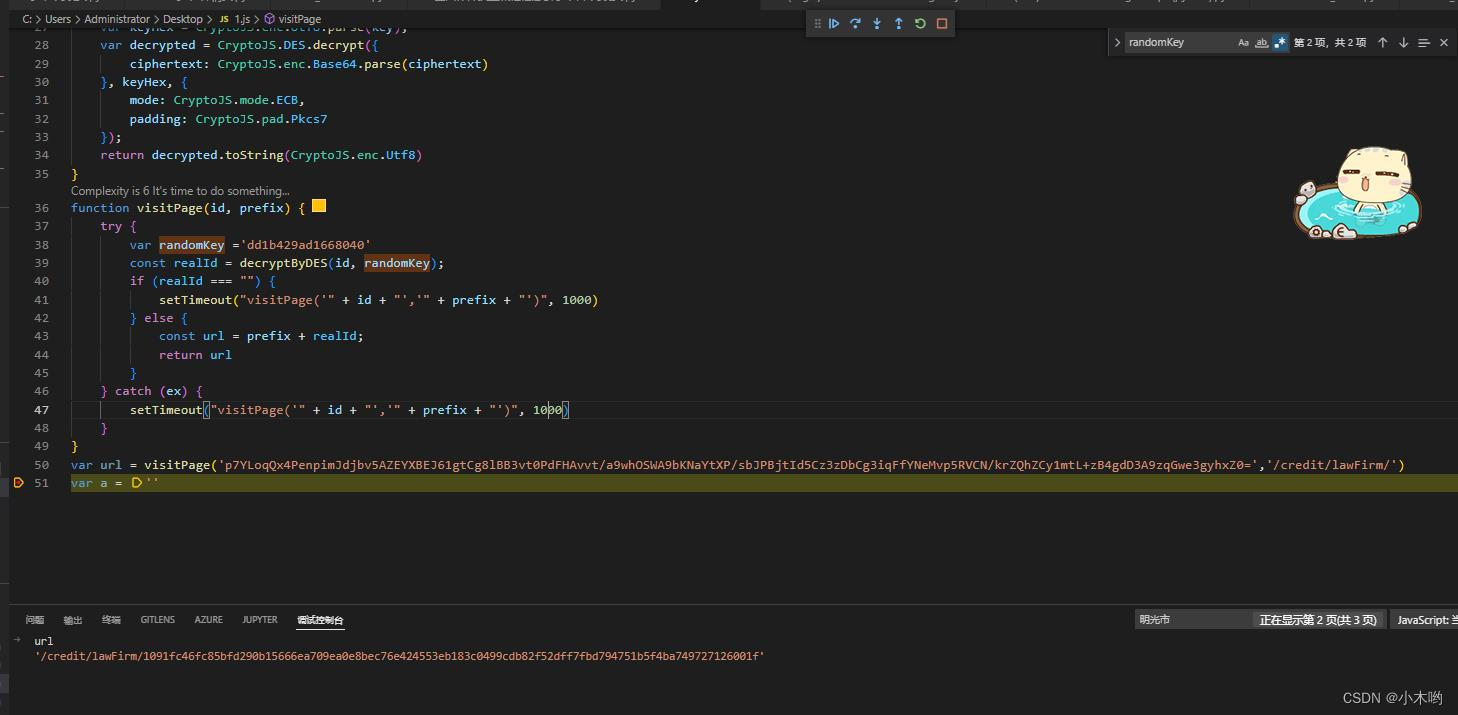
DES加密
这里的跳转链接被加密了,这里绑定了一个事件onclick,点击右侧Event Listeners,点击click,再点击js进去查看里面的js代码

跳到一个方法里面,我们打个断点,点击跳转链接调试一下,查看参数k,很显然这不是我们要的东西,我们往上调试
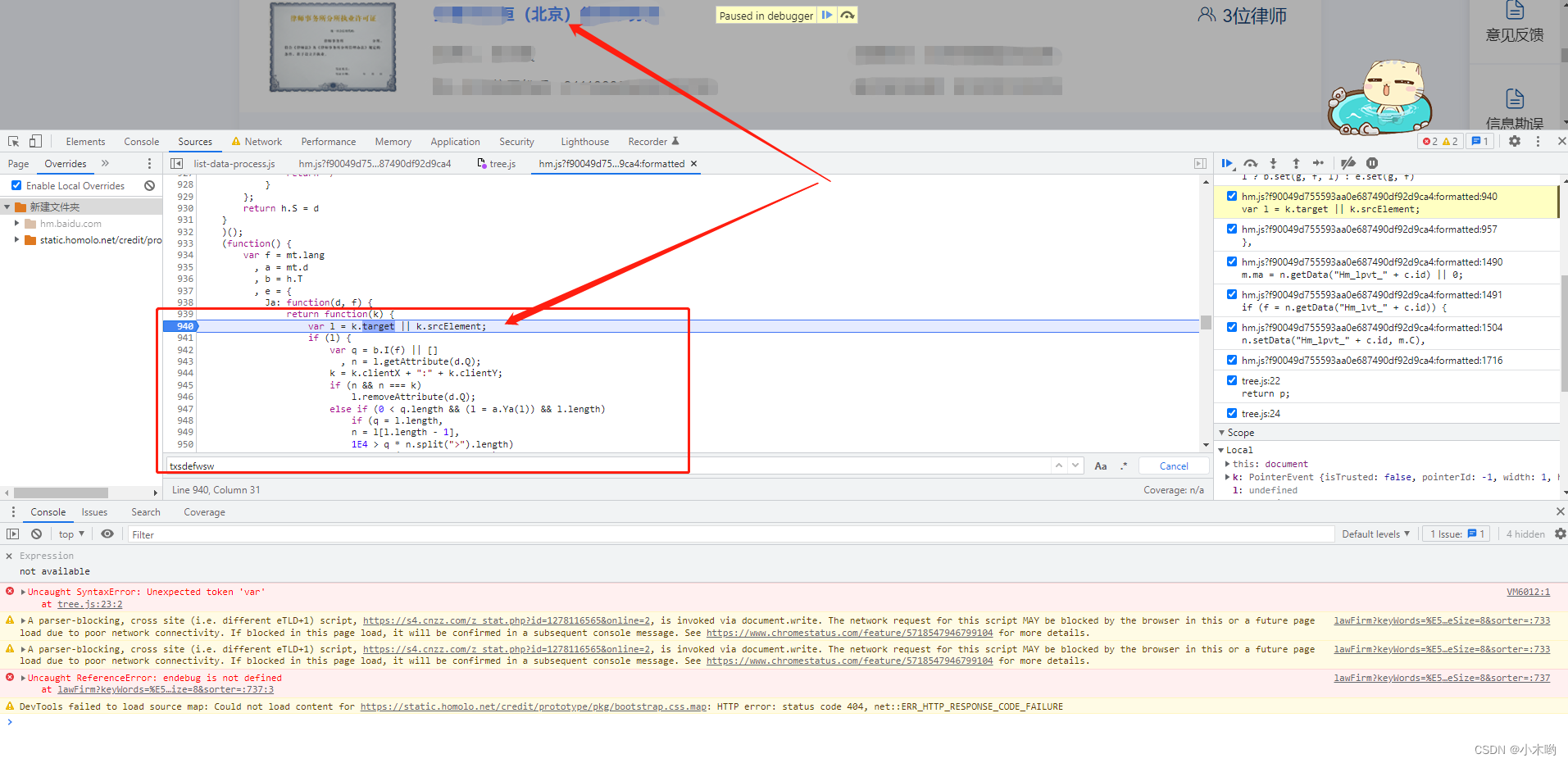
跳到了这里,我们看到decryptByDES方法和CryptoJS,randomKey等关键词,很显然这是一个DES加密
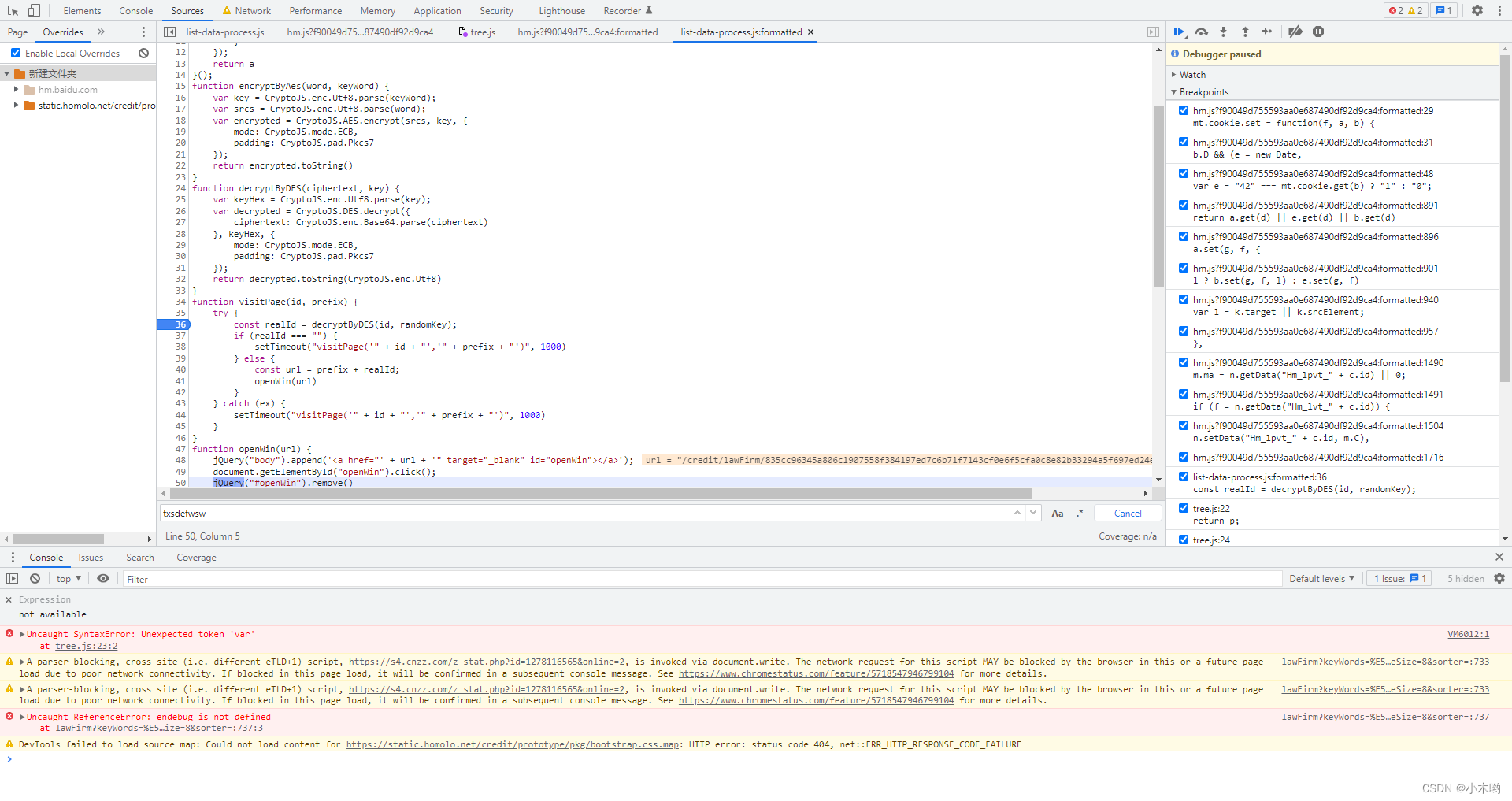
把js代码抠出来,导入crypto-js这个包,这里的randomKey是动态的,在网页源码上
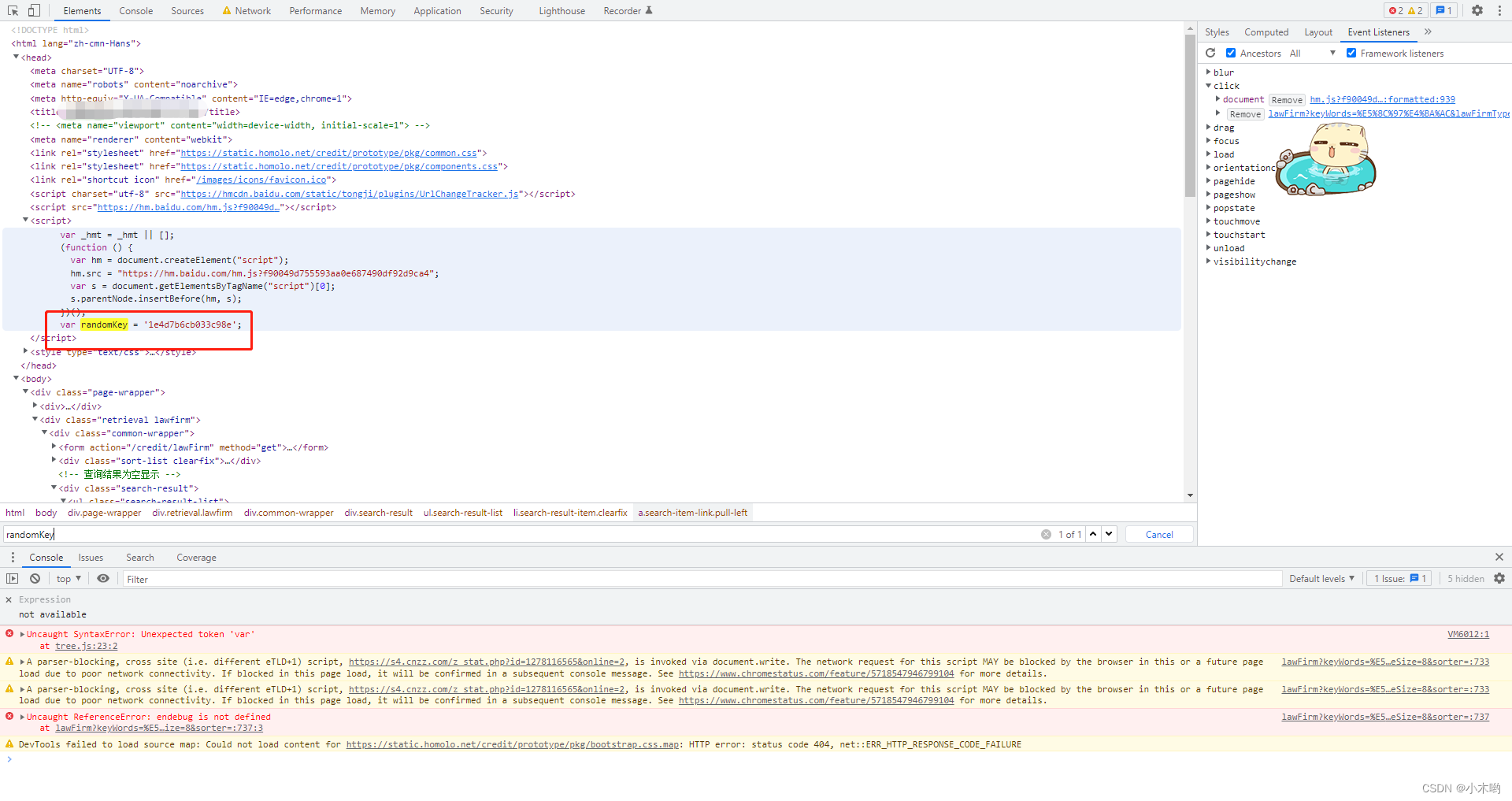
到这里也就解决了跳转链接被加密的问题了
中文字体反爬
来到字体反爬,一般字体反爬是0-9的字体反爬,比如58同城,大众点评等。这个站是中文字体反爬,也不确定有几套字体,是不是每天都变(已知DES加密的跳转链接每天一变),中文那么多,一个一个做成字典方法也不现实。
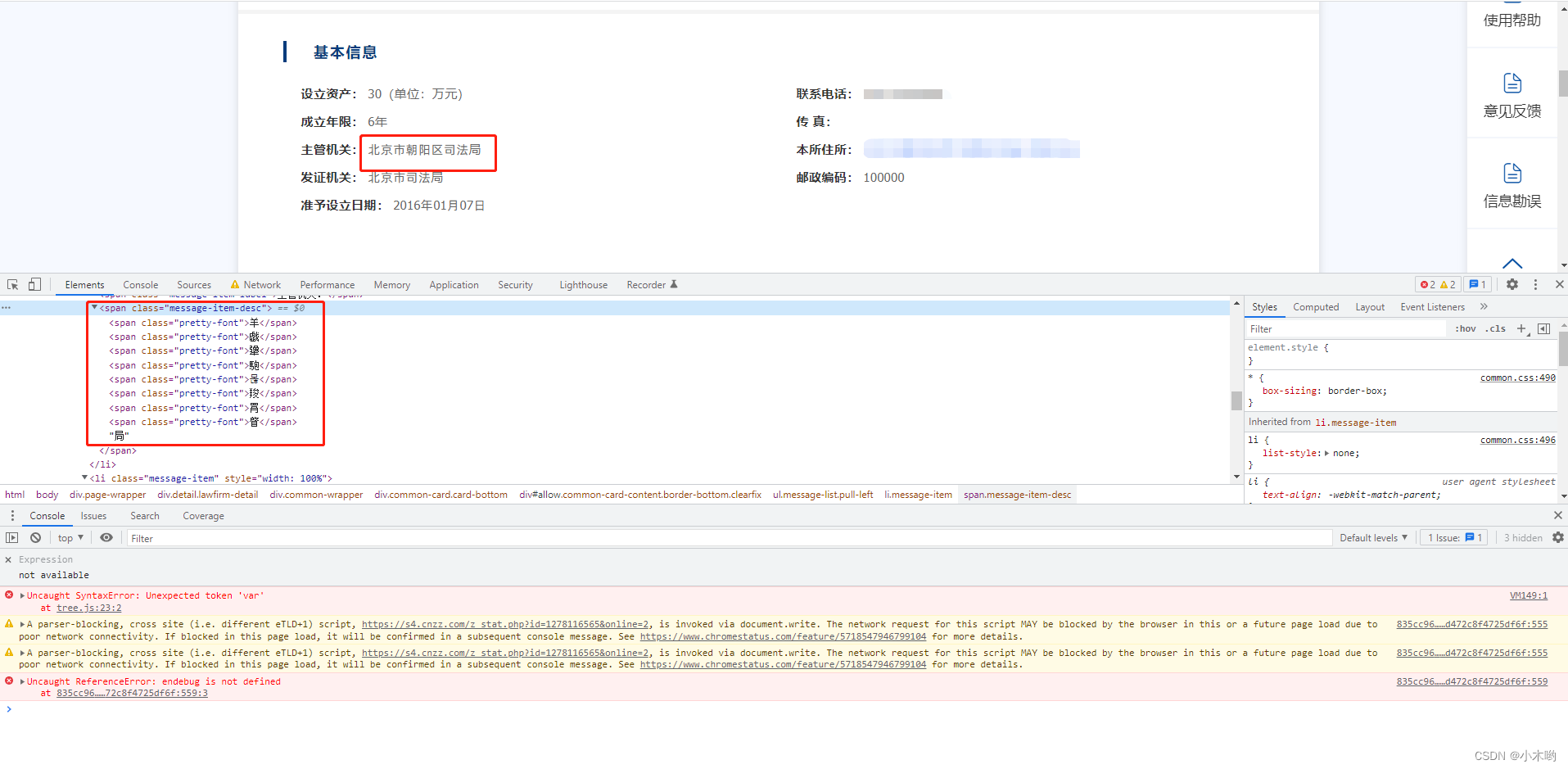
怎么拿字体文件url和写到本地也不赘述了
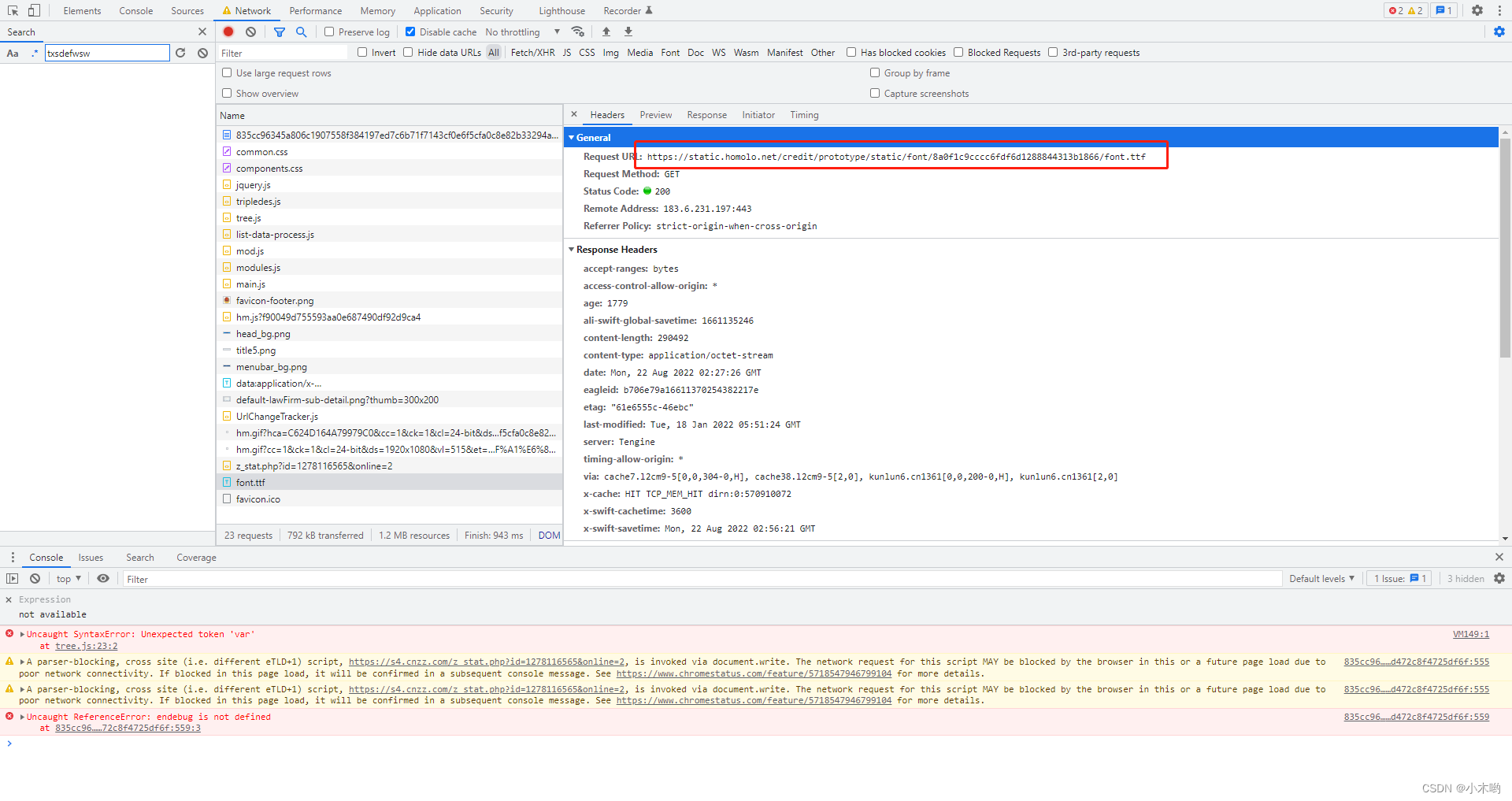
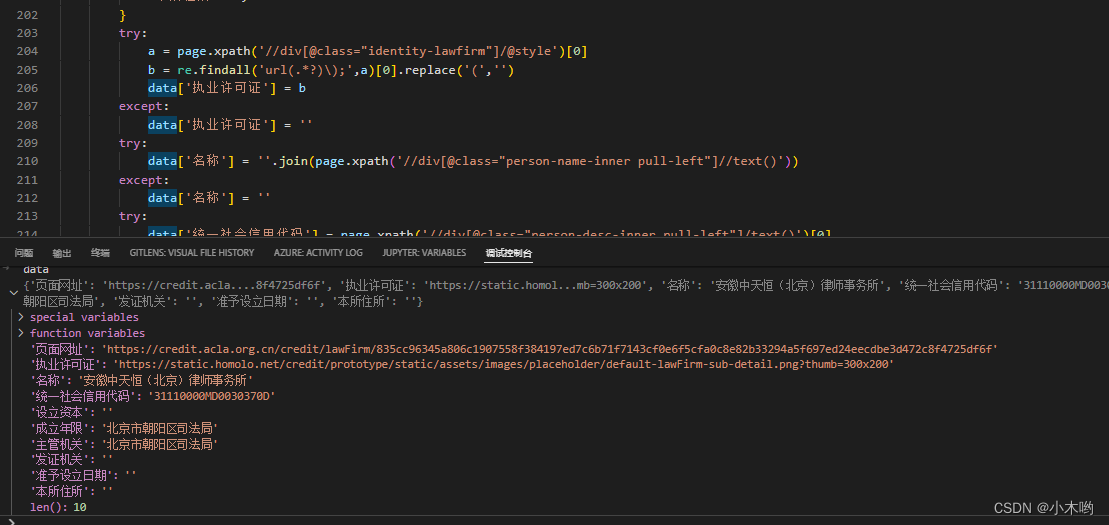
我的方案是用TTFont这个库读入字体文件,把未知字体写成图片然后利用第三方或者现成的库识别文字,再读data信息,用md5加密字体的data信息,把识别结果和md5做成字典写到本地文件或者通过api接口上传到线上(由于我做的是分布式爬虫,我用django做了个接口把文件upload到线上),每次运行脚本读取一次文件,遇到没有记录的字体添加到线上字典,这样我们的字典库就会不断壮大,也慢慢的不会再依赖文字识别,采集速度也会越来越快。
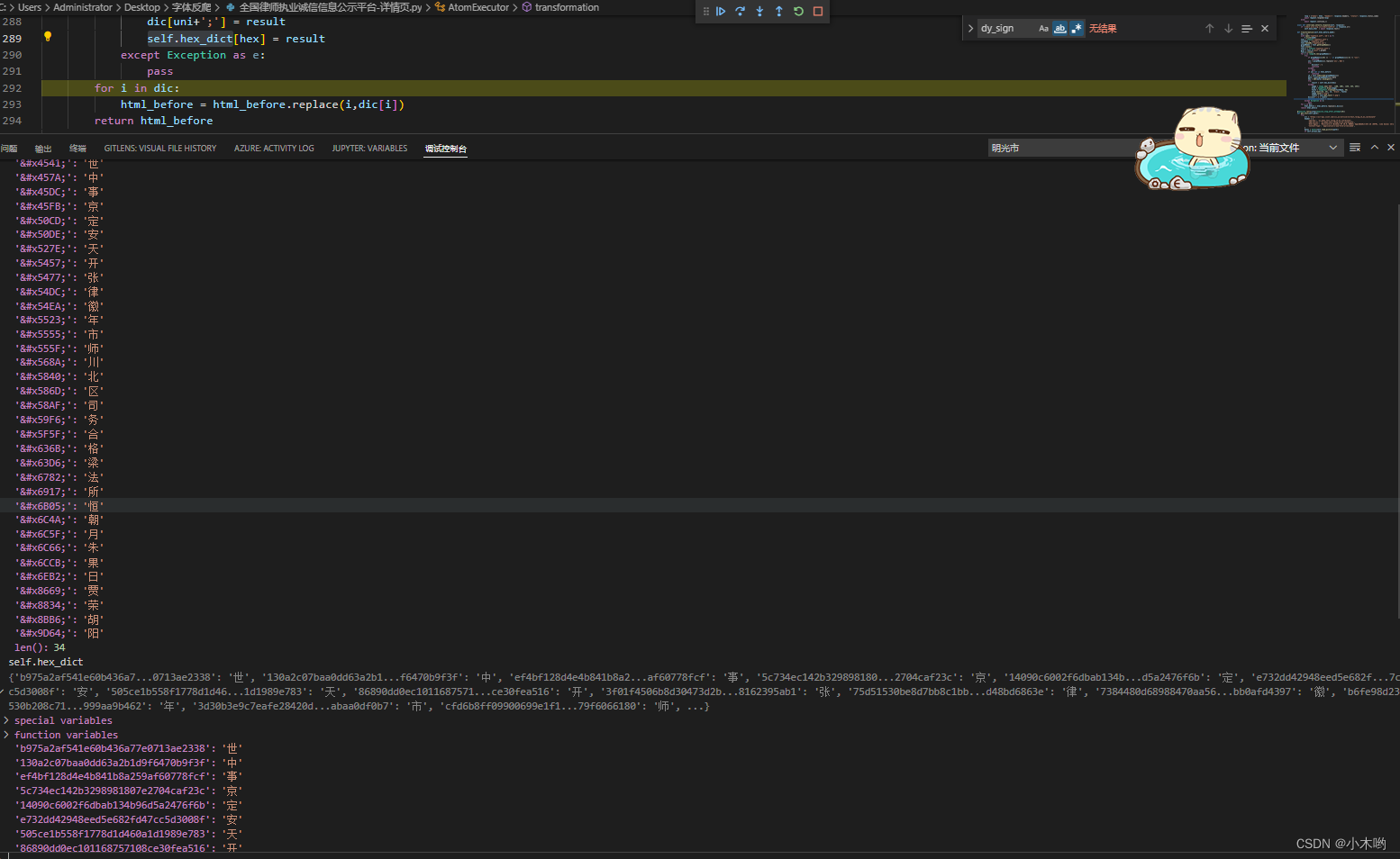
最后把把字典替换到网页源码就打完收工,开开心心当我的xpathBoy了


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









