







MySQL的比较运算和逻辑运算符:
| 比较运算符号 | 描述 |
|---|---|
| = | 等于 |
| <>, != | 不等于 |
| > | 大于 |
| < | 小于 |
| <= | 小于等于 |
| >= | 大于等于 |
| BETWEEN | 在两值之间 >=min&&<=max |
| NOT BETWEEN | 不在两值之间 |
| IN | 在集合中 |
| NOT IN | 不在集合中 |
| <=, >= | 严格比较两个NULL值是否相等 两个操作码均为NULL时,其所得值为1;而当一个操作码为NULL时,其所得值为0 |
| LIKE | 模糊匹配 |
| REGEXP 或 RLIKE | 正则式匹配 |
| IS NULL | 为空 |
| IS NOT NULL | 不为空 |
| 逻辑运算符号 | 作用 |
|---|---|
| NOT 或 ! | 逻辑非 |
| AND | 逻辑与 |
| OR | 逻辑或 |
| XOR | 逻辑异或 |
注意事项:
- and比or的优先级高,当表达式比较复杂时,习惯使用括号,避免出现歧义。
- in用法:in的后面跟着枚举,例如in (3,11)
- between通常和 and连用,例如 between 100 and 500
示例表数据如下:

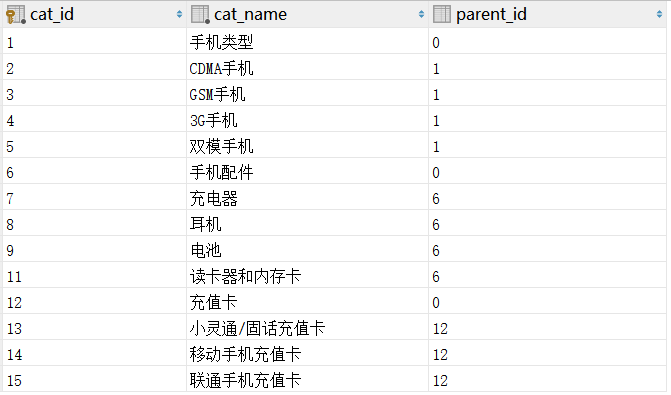
1. where 条件约束
where是针对磁盘数据文件,后面一般都是列变量的表达式。模糊查询时,百分号%表示匹配所有字符,下划线_表示匹配一个字符。
# ⑴ 主键为32的商品
SELECT goods_id,goods_name,shop_price FROM goods WHERE goods_id=32;
# ⑵ 不属第3栏目的所有商品
SELECT cat_id,goods_name,shop_price FROM goods WHERE cat_id!=3;
# ⑶ 本店价格高于3000元的商品
SELECT goods_id,goods_name,shop_price FROM goods WHERE shop_price>3000;
# ⑷ 本店价格低于或等于100元的商品
SELECT goods_id,goods_name,shop_price FROM goods WHERE shop_price<=100;
# ⑸ 取出第4栏目或第11栏目的商品(不用or)
SELECT cat_id,goods_name,shop_price FROM goods WHERE cat_id IN (4,11);
# ⑹ 取出100<=价格<=500的商品(不许用and)
SELECT goods_id,goods_name,shop_price FROM goods WHERE shop_price BETWEEN 100 AND 500;
# ⑺ 不属于第3栏目且不属于第11栏目的商品(and,或not in分别实现)
SELECT cat_id,goods_name,shop_price FROM goods WHERE (cat_id!=3) && (cat_id!=11);
SELECT cat_id,goods_name,shop_price FROM goods WHERE cat_id NOT IN (3,11);
# ⑻ 取出价格大于100且小于300,或者大于3000小于4000商品
SELECT goods_id,goods_name,shop_price FROM goods WHERE (shop_price>100 && shop_price<300) || (shop_price>3000 && shop_price<4000);
# ⑼ 取出第3个栏目下面价格<1000或>3000,并且点击量>5的系列商品
SELECT cat_id,goods_name,shop_price,click_count FROM goods WHERE (cat_id=3) && (shop_price<1000 || shop_price>3000) && (click_count>=5);
# ⑽ 取出第1个栏目下面的商品(注意:第1栏目下面没商品,但其子栏目下有)
SELECT cat_id,goods_name,shop_price FROM goods WHERE cat_id IN (2,3,4,5);# 手动查看第1栏目的子栏目有2 3 4 5
# ⑾ 取出名字以"诺基亚"开头的商品
SELECT cat_id,goods_name,shop_price FROM goods WHERE goods_name LIKE '诺基亚%';
# ⑿ 取出诺基亚N系列的手机
SELECT goods_id,goods_name,shop_price FROM goods WHERE goods_name LIKE '诺基亚N__';
# ⒀ 取出名字不以"诺基亚"开头的商品
SELECT goods_id,goods_name,shop_price FROM goods WHERE goods_name NOT LIKE '诺基亚%';
# ⒁ 取出第3个栏目下面价格在1000到3000之间,并且点击量>5 的"诺基亚"开头的商品
SELECT cat_id,goods_name,shop_price,click_count FROM goods WHERE (cat_id=3) && (shop_price>1000 && shop_price<3000) && (click_count>5) && (goods_name LIKE '诺基亚%');
# ⒂ 把num值处于[20,29]之间,改为20,num值处于[30,39]之间的,改为30
UPDATE mian SET num=floor(num/10)*10 WHERE num BETWEEN 20 AND 39;
# ⒃ 把good表中商品名为'诺基亚xxxx'的商品,改为'HTCxxxx'
UPDATE goods SET goods_name=INSERT(goods_name,1,3,'HTC') WHERE goods_name LIKE '诺基亚%'; # 注:字符串位置从1开始
2. group 数据分组
使用group时首先会对该列重新排序,再做统计,所以比较耗资源,尽量避免使用。
# ⑴ 查出最贵和最便宜的商品的价格
SELECT max(shop_price),min(shop_price) FROM goods;
# ⑵ 查出最新和最旧的商品编号
SELECT max(goods_id),min(goods_id) FROM goods;
# ⑶ 查询该店所有商品的库存总量
SELECT sum(goods_number) FROM goods;
# ⑷ 查询所有商品的平均价格
SELECT avg(shop_price) FROM goods;
# ⑸ 查询该店一共有多少种商品
SELECT count(*) FROM goods;
# ⑹ 查询每个栏目下面最贵商品价格、最便宜商品价格、商品平均价格、商品库存量、商品库存总价格、商品种类
SELECT max(shop_price),min(shop_price),avg(shop_price),sum(goods_number),count(*) FROM goods GROUP BY cat_id;
3. having 筛选数据
having是针对where条件结果进行筛选,是对内存数据操作,所以having必须用在where之后。
# ⑴ 查询该店的商品比市场价所节省的价格
SELECT goods_name,market_price-shop_price FROM goods;
# ⑵ 查询每个商品所积压的货款
SELECT goods_name,shop_price*goods_number FROM goods;
# ⑶ 查询该店积压的总货款
SELECT sum(shop_price*goods.goods_number) FROM goods;
# ⑷ 查询该店每个栏目下面积压的货款
SELECT cat_id,sum(shop_price*goods_number) FROM goods GROUP BY cat_id;
# ⑸ 查询比市场价省钱200元以上的商品及该商品所省的钱
SELECT goods_id,goods_name,(market_price-goods.shop_price) AS save FROM goods HAVING save>200;
# ⑹ 查询积压货款超过2W元的栏目,以及该栏目积压的货款
SELECT cat_id,sum(shop_price*goods.goods_number) AS catPrice FROM goods GROUP BY cat_id HAVING catPrice>20000;
# ⑺ 查询出2门及2门以上不及格者的平均成绩
成绩表result数据如下:
+------+---------+-------+
| name | subject | score |
| 张三 | 数学 | 90 |
| 张三 | 语文 | 50 |
| 张三 | 地理 | 40 |
| 李四 | 语文 | 55 |
| 李四 | 政治 | 45 |
| 王五 | 政治 | 30 |
+------+---------+-------+
SELECT name,avg(score),sum(score<60) AS fail FROM result GROUP BY name HAVING fail>=2;
4. order by 排序和limit限制取出条目
当按某列排序(默认asc升序,desc降序)无法满足要求时,可以在列的内部再继续排序。实际使用中oder by经常和limit配合一起使用。 limit有两个参数,分别是limit 偏移量,取出条目,可以使用在分页上。
# (1)按价格由高到低排序
SELECT goods_id,goods_name,shop_price FROM goods ORDER BY shop_price ASC;
# (2)按发布时间由早到晚排序
SELECT goods_id,goods_name,shop_price FROM goods ORDER BY goods_id DESC;
# (3)接栏目由低到高排序,栏目内部按价格由高到低排序
SELECT cat_id,goods_name,shop_price FROM goods ORDER BY cat_id ASC, shop_price DESC;
# (4)取出价格最高的前三名商品
SELECT goods_id,goods_name,shop_price FROM goods ORDER BY shop_price DESC LIMIT 0,3;
# (5)取出点击量前三名到前5名的商品
SELECT goods_name,shop_price,click_count FROM goods ORDER BY click_count DESC LIMIT 0,5;
5. 子查询
(1) where子查询
内层select查询的结果充当外层select的where条件的查询。
# 取出每个栏目下最新的商品
SELECT cat_id,goods_id,goods_name,shop_price FROM goods WHERE goods_id IN (SELECT max(goods_id) FROM goods GROUP BY cat_id);
(2) from子查询
内层select作为一张表(AS table),外层select从内层表取出数据。
# 取出每个栏目下最新的商品
SELECT cat_id,goods_id,goods_name,shop_price FROM (SELECT * FROM goods ORDER BY cat_id ASC,goods_id DESC) AS tmp GROUP BY cat_id;
(3) exists子查询
exists指定一个子查询,检测行的存在。该子查询实际上并不返回任何数据,而是返回值True或False。exists子查询能完成的where子查询 in也能完成。
# 取出没有商品的栏目
SELECT * FROM category WHERE NOT exists(SELECT * FROM goods WHERE category.cat_id=goods.cat_id);
子查询练习
# 查询出最新一行商品
SELECT goods_id,goods_name,shop_price FROM goods WHERE goods_id=(SELECT max(goods_id) FROM goods);
# 查询出编号为19的商品的栏目名称(where和连接查询)
where子查询:
SELECT cat_id,cat_name FROM category WHERE cat_id=(SELECT cat_id FROM goods WHERE goods_id=19);
连接查询:
SELECT category.cat_id,category.cat_name FROM
category INNER JOIN goods ON category.cat_id=goods.cat_id
WHERE goods.goods_id=19;
# 用where和from型子查询方式把每个栏目下面最新的商品取出来
where子查询:
SELECT goods_id,cat_id,goods_name FROM goods WHERE goods_id IN
(SELECT max(goods_id) FROM goods GROUP BY cat_id);
from子查询:
SELECT goods_id,cat_id,goods_name FROM
(SELECT * FROM goods ORDER BY cat_id ASC,goods_id DESC) AS tmp GROUP BY tmp.cat_id;
# 用exists型子查询,查出所有有商品的栏目
SELECT * FROM category WHERE exists(SELECT * FROM goods WHERE category.cat_id=goods.cat_id);
6. join连接查询
(1) INNER JOIN内连接查询
把两张独立代表拼接成一张大表,拼接时指定匹配条件。
# 语法:
表1 INNER JOIN 表2 ON 匹配条件
# 把boy表和girl表同一组的人取出来
SELECT * FROM boy INNER JOIN girl ON boy.hid=girl.hid;
(2) LEFT JOIN左连接查询
以左边的表为标准,有匹配条件取出值来,没有则填充默认值。
# 以boy表为标准,把boy表和girl表进行同组匹配
SELECT * FROM boy LEFT JOIN girl ON boy.hid=girl.hid;
(3) RIGHT JOIN右连接查询
以右边的表为标准,有匹配条件取出值来,没有则填充默认值。
# 以girl表为标准,把boy表和girl表进行同组匹配
SELECT * FROM boy RIGHT JOIN girl ON boy.hid=girl.hid;
连接查询练习
# 取出所有商品的商品名,栏目名,价格
SELECT goods.goods_id,goods.goods_name,category.cat_name,goods.shop_price FROM goods LEFT JOIN category ON goods.cat_id=category.cat_id;
# 取出第4个栏目下的商品的商品名,栏目名,价格
SELECT goods.goods_id,goods.goods_name,category.cat_name,goods.shop_price FROM goods LEFT JOIN category ON goods.cat_id=category.cat_id WHERE goods.cat_id=4;
# 查出 2006-6-1 到2006-7-1之间举行的所有比赛,并且用以下形式列出:主队名 比分 客队 比赛时间
表名:m
+-----+------+------+------+------------+
| mid | hid | gid | mres | matime |
+-----+------+------+------+------------+
| 1 | 1 | 2 | 2:0 | 2006-05-21 |
| 2 | 2 | 3 | 1:2 | 2006-06-21 |
| 3 | 3 | 1 | 2:5 | 2006-06-25 |
| 4 | 2 | 1 | 3:2 | 2006-07-21 |
+-----+------+------+------+------------+
队名:t
+------+----------+
| tid | tname |
+------+----------+
| 1 | 国安 |
| 2 | 申花 |
| 3 | 公益联队 |
+------+----------+
# 写法一:
SELECT ttb.tname,ttb.mres,t.tname,ttb.matime FROM (SELECT * FROM m LEFT JOIN t ON m.hid=t.tid)AS ttb LEFT JOIN t ON ttb.gid=t.tid WHERE ttb.matime BETWEEN '2006-06-01' AND '2006-07-01';
# 写法二:
SELECT t1.tname,mres,t2.tname,matime FROM m LEFT JOIN t AS t1 ON m.hid = t1.tid LEFT JOIN t AS t2 ON m.gid = t2.tid WHERE matime BETWEEN '2006-06-01' AND '2006-07-01';
7. union查询
把两条或多条sql查询的结果合并成一个结果集。主要用途:两张不同的表中有相同的列时,把结果集合并,或者简化两个复杂的where条件, 使用条件:两个表的列必须相同,但是例外的是列名称可以不相同。
注意事项:
- 完全相等的行将会合并,合并是耗时的操作,一般不让union合并,使用union all则不合并。
- union子句中一般不用order by,在union合并后可以再order by。
# (1) 合并表a和表b,不合并相同的行
SELECT * FROM a UNION ALL SELECT * FROM b;
# (2) 对两个表相同id的行进行num列求和。
SELECT tmp.id,sum(tmp.num) FROM
(SELECT * FROM a UNION ALL SELECT * FROM b) AS tmp
GROUP BY tmp.id;

















 988
988











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











