









一. 前言
本文为内存部分最后一篇,介绍内存映射。内存映射不仅是物理内存和虚拟内存间的映射,也包括将文件中的内容映射到虚拟内存空间。这个时候,访问内存空间就能够访问到文件里面的数据。而仅有物理内存和虚拟内存的映射,是一种特殊情况。本文首先分析用户态在堆中申请小块内存的brk和申请大块内存的mmap,之后会分析内核态的内存映射机制vmalloc,kmap_atomic,swapper_pg_dir以及内核态缺页异常。
二. 用户态内存映射
用户态调用malloc会分配堆内存空间,而实际上则是完成了一次用户态的内存映射,根据分配空间的大小,内存映射主要有brk和mmap,下面分别详细分析。
2.1 小块内存申请
brk系统调用为sys_brk()函数,其参数brk是新的堆顶位置,而mm->brk是原堆顶位置。该函数主要逻辑如下
- 将原来的堆顶和现在的堆顶按照页对齐地址比较大小,判断是否在同一页中
- 如果同一页则不需要分配新页,直接跳转至
set_brk,设置mm->brk为新的brk即可 - 如果不在同一页
- 如果新堆顶小于旧堆顶,则说明不是新分配内存而是释放内存,由此调用
__do_munmap()释放 - 如果是新分配内存,则调用
find_vma(),查找vm_area_struct红黑树中原堆顶所在vm_area_struct的下一个结构体,如果在二者之间有足够的空间分配一个页则调用do_brk_flags()分配堆空间。如果不可以则分配失败。
- 如果新堆顶小于旧堆顶,则说明不是新分配内存而是释放内存,由此调用
- 如果同一页则不需要分配新页,直接跳转至
SYSCALL_DEFINE1(brk, unsigned long, brk)
{
unsigned long retval;
unsigned long newbrk, oldbrk, origbrk;
struct mm_struct *mm = current->mm;
struct vm_area_struct *next;
......
newbrk = PAGE_ALIGN(brk);
oldbrk = PAGE_ALIGN(mm->brk);
if (oldbrk == newbrk) {
mm->brk = brk;
goto success;
}
/*
* Always allow shrinking brk.
* __do_munmap() may downgrade mmap_sem to read.
*/
if (brk <= mm->brk) {
int ret;
/*
* mm->brk must to be protected by write mmap_sem so update it
* before downgrading mmap_sem. When __do_munmap() fails,
* mm->brk will be restored from origbrk.
*/
mm->brk = brk;
ret = __do_munmap(mm, newbrk, oldbrk-newbrk, &uf, true);
if (ret < 0) {
mm->brk = origbrk;
goto out;
} else if (ret == 1) {
downgraded = true;
}
goto success;
}
/* Check against existing mmap mappings. */
next = find_vma(mm, oldbrk);
if (next && newbrk + PAGE_SIZE > vm_start_gap(next))
goto out;
/* Ok, looks good - let it rip. */
if (do_brk_flags(oldbrk, newbrk-oldbrk, 0, &uf) < 0)
goto out;
mm->brk = brk;
success:
populate = newbrk > oldbrk && (mm->def_flags & VM_LOCKED) != 0;
if (downgraded)
up_read(&mm->mmap_sem);
else
up_write(&mm->mmap_sem);
userfaultfd_unmap_complete(mm, &uf);
if (populate)
mm_populate(oldbrk, newbrk - oldbrk);
return brk;
out:
retval = origbrk;
up_write(&mm->mmap_sem);
return retval;
}
在 do_brk_flags() 中,调用 find_vma_links() 找到将来的 vm_area_struct 节点在红黑树的位置,找到它的父节点、前序节点。接下来调用 vma_merge(),看这个新节点是否能够和现有树中的节点合并。如果地址是连着的,能够合并,则不用创建新的 vm_area_struct 了,直接跳到 out,更新统计值即可;如果不能合并,则创建新的 vm_area_struct,既加到 anon_vma_chain 链表中,也加到红黑树中。
/*
* this is really a simplified "do_mmap". it only handles
* anonymous maps. eventually we may be able to do some
* brk-specific accounting here.
*/
static int do_brk_flags(unsigned long addr, unsigned long len, unsigned long flags, struct list_head *uf)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma, *prev;
struct rb_node **rb_link, *rb_parent;
......
/*
* Clear old maps. this also does some error checking for us
*/
while (find_vma_links(mm, addr, addr + len, &prev, &rb_link,
&rb_parent)) {
if (do_munmap(mm, addr, len, uf))
return -ENOMEM;
}
......
/* Can we just expand an old private anonymous mapping? */
vma = vma_merge(mm, prev, addr, addr + len, flags,
NULL, NULL, pgoff, NULL, NULL_VM_UFFD_CTX);
if (vma)
goto out;
/*
* create a vma struct for an anonymous mapping
*/
vma = vm_area_alloc(mm);
if (!vma) {
vm_unacct_memory(len >> PAGE_SHIFT);
return -ENOMEM;
}
vma_set_anonymous(vma);
vma->vm_start = addr;
vma->vm_end = addr + len;
vma->vm_pgoff = pgoff;
vma->vm_flags = flags;
vma->vm_page_prot = vm_get_page_prot(flags);
vma_link(mm, vma, prev, rb_link, rb_parent);
out:
perf_event_mmap(vma);
mm->total_vm += len >> PAGE_SHIFT;
mm->data_vm += len >> PAGE_SHIFT;
if (flags & VM_LOCKED)
mm->locked_vm += (len >> PAGE_SHIFT);
vma->vm_flags |= VM_SOFTDIRTY;
return 0;
}
2.2 大内存块申请
大块内存的申请通过mmap系统调用实现,mmap既可以实现虚拟内存向物理内存的映射,也可以映射文件到自己的虚拟内存空间。映射文件时,实际是映射虚拟内存到物理内存再到文件。
SYSCALL_DEFINE6(mmap, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags,
unsigned long, fd, unsigned long, off)
{
long error;
error = -EINVAL;
if (off & ~PAGE_MASK)
goto out;
error = ksys_mmap_pgoff(addr, len, prot, flags, fd, off >> PAGE_SHIFT);
out:
return error;
}
这里主要调用ksys_mmap_pgoff()函数,这里逻辑如下
- 判断类型是否为匿名映射,如果不是则为文件映射,调用
fget()获取文件描述符 - 如果是匿名映射,判断是否为大页,如果是则进行对齐处理并调用
hugetlb_file_setup()获取文件描述符 - 调用
vm_mmap_pgoff()函数找寻可以映射的区域并建立映射
unsigned long ksys_mmap_pgoff(unsigned long addr, unsigned long len,
unsigned long prot, unsigned long flags,
unsigned long fd, unsigned long pgoff)
{
struct file *file = NULL;
unsigned long retval;
if (!(flags & MAP_ANONYMOUS)) {
audit_mmap_fd(fd, flags);
file = fget(fd);
if (!file)
return -EBADF;
if (is_file_hugepages(file))
len = ALIGN(len, huge_page_size(hstate_file(file)));
retval = -EINVAL;
if (unlikely(flags & MAP_HUGETLB && !is_file_hugepages(file)))
goto out_fput;
} else if (flags & MAP_HUGETLB) {
struct user_struct *user = NULL;
struct hstate *hs;
hs = hstate_sizelog((flags >> MAP_HUGE_SHIFT) & MAP_HUGE_MASK);
if (!hs)
return -EINVAL;
len = ALIGN(len, huge_page_size(hs));
/*
* VM_NORESERVE is used because the reservations will be
* taken when vm_ops->mmap() is called
* A dummy user value is used because we are not locking
* memory so no accounting is necessary
*/
file = hugetlb_file_setup(HUGETLB_ANON_FILE, len,
VM_NORESERVE,
&user, HUGETLB_ANONHUGE_INODE,
(flags >> MAP_HUGE_SHIFT) & MAP_HUGE_MASK);
if (IS_ERR(file))
return PTR_ERR(file);
}
flags &= ~(MAP_EXECUTABLE | MAP_DENYWRITE);
retval = vm_mmap_pgoff(file, addr, len, prot, flags, pgoff);
out_fput:
if (file)
fput(file);
return retval;
}
vm_mmap_pgoff()函数调用do_mmap_pgoff(),实际调用do_mmap()函数。这里get_unmapped_area()函数负责寻找可映射的区域,mmap_region()负责映射该区域。
/*
* The caller must hold down_write(¤t->mm->mmap_sem).
*/
unsigned long do_mmap(struct file *file, unsigned long addr,
unsigned long len, unsigned long prot,
unsigned long flags, vm_flags_t vm_flags,
unsigned long pgoff, unsigned long *populate,
struct list_head *uf)
{
struct mm_struct *mm = current->mm;
int pkey = 0;
*populate = 0;
......
/* Obtain the address to map to. we verify (or select) it and ensure
* that it represents a valid section of the address space.
*/
addr = get_unmapped_area(file, addr, len, pgoff, flags);
......
addr = mmap_region(file, addr, len, vm_flags, pgoff, uf);
if (!IS_ERR_VALUE(addr) &&
((vm_flags & VM_LOCKED) ||
(flags & (MAP_POPULATE | MAP_NONBLOCK)) == MAP_POPULATE))
*populate = len;
return addr;
}
首先来看看寻找映射区的函数get_unmapped_area()。
- 如果是匿名映射,则调用
get_umapped_area函数指针,这个函数其实是arch_get_unmapped_area()。它会调用find_vma_prev(),在表示虚拟内存区域的vm_area_struct红黑树上找到相应的位置。之所以叫prev,是说这个时候虚拟内存区域还没有建立,找到前一个vm_area_struct。 - 如果是映射到一个文件,在 Linux 里面每个打开的文件都有一个
struct file结构,里面有一个file_operations用来表示和这个文件相关的操作。如果是我们熟知的ext4文件系统,调用的也是get_unmapped_area函数指针。
unsigned long
get_unmapped_area(struct file *file, unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags)
{
unsigned long (*get_area)(struct file *, unsigned long,
unsigned long, unsigned long, unsigned long);
unsigned long error = arch_mmap_check(addr, len, flags);
if (error)
return error;
/* Careful about overflows.. */
if (len > TASK_SIZE)
return -ENOMEM;
get_area = current->mm->get_unmapped_area;
if (file) {
if (file->f_op->get_unmapped_area)
get_area = file->f_op->get_unmapped_area;
} else if (flags & MAP_SHARED) {
/*
* mmap_region() will call shmem_zero_setup() to create a file,
* so use shmem's get_unmapped_area in case it can be huge.
* do_mmap_pgoff() will clear pgoff, so match alignment.
*/
pgoff = 0;
get_area = shmem_get_unmapped_area;
}
addr = get_area(file, addr, len, pgoff, flags);
if (IS_ERR_VALUE(addr))
return addr;
if (addr > TASK_SIZE - len)
return -ENOMEM;
if (offset_in_page(addr))
return -EINVAL;
error = security_mmap_addr(addr);
return error ? error : addr;
}
mmap_region()首先会再次检测地址空间是否满足要求,然后清除旧的映射,校验内存的可用性,在一切均满足的情况下调用vma_link()将新创建的vm_area_struct结构挂在mm_struct内的红黑树上。
unsigned long mmap_region(struct file *file, unsigned long addr,
unsigned long len, vm_flags_t vm_flags, unsigned long pgoff,
struct list_head *uf)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma, *prev;
int error;
struct rb_node **rb_link, *rb_parent;
unsigned long charged = 0;
......
vma_link(mm, vma, prev, rb_link, rb_parent);
/* Once vma denies write, undo our temporary denial count */
if (file) {
if (vm_flags & VM_SHARED)
mapping_unmap_writable(file->f_mapping);
if (vm_flags & VM_DENYWRITE)
allow_write_access(file);
}
file = vma->vm_file;
......
}
vma_link()本身是__vma_link()和__vma_link_file()的包裹函数
static void vma_link(struct mm_struct *mm, struct vm_area_struct *vma,
struct vm_area_struct *prev, struct rb_node **rb_link,
struct rb_node *rb_parent)
{
struct address_space *mapping = NULL;
if (vma->vm_file) {
mapping = vma->vm_file->f_mapping;
i_mmap_lock_write(mapping);
}
__vma_link(mm, vma, prev, rb_link, rb_parent);
__vma_link_file(vma);
if (mapping)
i_mmap_unlock_write(mapping);
mm->map_count++;
validate_mm(mm);
}
其中__vma_link()主要是链表和红黑表的插入,这属于基本数据结构操作,不展开讲解。
static void
__vma_link(struct mm_struct *mm, struct vm_area_struct *vma,
struct vm_area_struct *prev, struct rb_node **rb_link,
struct rb_node *rb_parent)
{
__vma_link_list(mm, vma, prev, rb_parent);
__vma_link_rb(mm, vma, rb_link, rb_parent);
}
而__vma_link_file()会对文件映射进行处理,在file结构体中成员f_mapping指向address_space结构体,该结构体中存储红黑树i_mmap挂载vm_area_struct。
static void __vma_link_file(struct vm_area_struct *vma)
{
struct file *file;
file = vma->vm_file;
if (file) {
struct address_space *mapping = file->f_mapping;
if (vma->vm_flags & VM_DENYWRITE)
atomic_dec(&file_inode(file)->i_writecount);
if (vma->vm_flags & VM_SHARED)
atomic_inc(&mapping->i_mmap_writable);
flush_dcache_mmap_lock(mapping);
vma_interval_tree_insert(vma, &mapping->i_mmap);
flush_dcache_mmap_unlock(mapping);
}
}
至此,我们完成了用户态内存的映射,但是此处仅在虚拟内存中建立了新的区域,尚未真正访问物理内存。物理内存的访问只有在调度到该进程时才会真正分配,即发生缺页异常时分配。
三. 用户态缺页异常
一旦开始访问虚拟内存的某个地址,如果我们发现,并没有对应的物理页,那就触发缺页中断,调用 do_page_fault()。这里的逻辑如下
- 判断是否为内核缺页中断
fault_in_kernel_space(),如果是则调用vmalloc_fault() - 如果是用户态缺页异常,则调用
find_vma()找到地址所在vm_area_struct区域 - 调用
handle_mm_fault()映射找到的区域
/*
* This routine handles page faults. It determines the address,
* and the problem, and then passes it off to one of the appropriate
* routines.
*/
asmlinkage void __kprobes do_page_fault(struct pt_regs *regs,
unsigned long error_code,
unsigned long address)
{
......
/*
* We fault-in kernel-space virtual memory on-demand. The
* 'reference' page table is init_mm.pgd.
*
* NOTE! We MUST NOT take any locks for this case. We may
* be in an interrupt or a critical region, and should
* only copy the information from the master page table,
* nothing more.
*/
if (unlikely(fault_in_kernel_space(address))) {
if (vmalloc_fault(address) >= 0)
return;
if (notify_page_fault(regs, vec))
return;
bad_area_nosemaphore(regs, error_code, address);
return;
}
......
vma = find_vma(mm, address);
......
/*
* If for any reason at all we couldn't handle the fault,
* make sure we exit gracefully rather than endlessly redo
* the fault.
*/
fault = handle_mm_fault(vma, address, flags);
......
}
find_vma()为红黑树查找操作,在此不做展开描述,下面重点看看handle_mm_fault()。这里经过一系列校验之后会根据是否是大页而选择调用hugetlb_fault()或者__handle_mm_fault()
vm_fault_t handle_mm_fault(struct vm_area_struct *vma, unsigned long address,
unsigned int flags)
{
......
if (unlikely(is_vm_hugetlb_page(vma)))
ret = hugetlb_fault(vma->vm_mm, vma, address, flags);
else
ret = __handle_mm_fault(vma, address, flags);
......
return ret;
}
__handle_mm_fault()完成实际上的映射操作。这里涉及到了由pgd, p4g, pud, pmd, pte组成的五级页表,页表索引填充完后调用handle_pte_fault()创建页表项。
static vm_fault_t __handle_mm_fault(struct vm_area_struct *vma,
unsigned long address, unsigned int flags)
{
struct vm_fault vmf = {
.vma = vma,
.address = address & PAGE_MASK,
.flags = flags,
.pgoff = linear_page_index(vma, address),
.gfp_mask = __get_fault_gfp_mask(vma),
};
unsigned int dirty = flags & FAULT_FLAG_WRITE;
struct mm_struct *mm = vma->vm_mm;
pgd_t *pgd;
p4d_t *p4d;
vm_fault_t ret;
pgd = pgd_offset(mm, address);
p4d = p4d_alloc(mm, pgd, address);
......
vmf.pud = pud_alloc(mm, p4d, address);
......
vmf.pmd = pmd_alloc(mm, vmf.pud, address);
......
return handle_pte_fault(&vmf);
}
handle_pte_fault()处理以下三种情况
- 页表项从未出现过,即新映射页表项
- 匿名页映射,则映射到物理内存页,调用
do_anonymous_page() - 文件映射,调用
do_fault()
- 匿名页映射,则映射到物理内存页,调用
- 页表项曾出现过,则为从物理内存换出的页,调用
do_swap_page()换回来
/*
* These routines also need to handle stuff like marking pages dirty
* and/or accessed for architectures that don't do it in hardware (most
* RISC architectures). The early dirtying is also good on the i386.
*
* There is also a hook called "update_mmu_cache()" that architectures
* with external mmu caches can use to update those (ie the Sparc or
* PowerPC hashed page tables that act as extended TLBs).
*
* We enter with non-exclusive mmap_sem (to exclude vma changes, but allow
* concurrent faults).
*
* The mmap_sem may have been released depending on flags and our return value.
* See filemap_fault() and __lock_page_or_retry().
*/
static vm_fault_t handle_pte_fault(struct vm_fault *vmf)
{
pte_t entry;
......
/*
* A regular pmd is established and it can't morph into a huge
* pmd from under us anymore at this point because we hold the
* mmap_sem read mode and khugepaged takes it in write mode.
* So now it's safe to run pte_offset_map().
*/
vmf->pte = pte_offset_map(vmf->pmd, vmf->address);
vmf->orig_pte = *vmf->pte;
......
if (!vmf->pte) {
if (vma_is_anonymous(vmf->vma))
return do_anonymous_page(vmf);
else
return do_fault(vmf);
}
if (!pte_present(vmf->orig_pte))
return do_swap_page(vmf);
......
}
3.1 匿名页映射
对于匿名页映射,流程如下
- 调用
pte_alloc()分配页表项 - 通过
alloc_zeroed_user_highpage_movable()分配一个页,该函数会调用alloc_pages_vma(),并最终调用__alloc_pages_nodemask()。该函数是伙伴系统的核心函数,用于分配物理页面,在上文中已经详细分析过了。 - 调用
mk_pte()将新分配的页表项指向分配的页 - 调用
set_pte_at()将页表项加入该页
/*
* We enter with non-exclusive mmap_sem (to exclude vma changes,
* but allow concurrent faults), and pte mapped but not yet locked.
* We return with mmap_sem still held, but pte unmapped and unlocked.
*/
static vm_fault_t do_anonymous_page(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
struct mem_cgroup *memcg;
struct page *page;
vm_fault_t ret = 0;
pte_t entry;
......
/*
* Use pte_alloc() instead of pte_alloc_map(). We can't run
* pte_offset_map() on pmds where a huge pmd might be created
* from a different thread.
*
* pte_alloc_map() is safe to use under down_write(mmap_sem) or when
* parallel threads are excluded by other means.
*
* Here we only have down_read(mmap_sem).
*/
if (pte_alloc(vma->vm_mm, vmf->pmd))
return VM_FAULT_OOM;
......
page = alloc_zeroed_user_highpage_movable(vma, vmf->address);
......
entry = mk_pte(page, vma->vm_page_prot);
if (vma->vm_flags & VM_WRITE)
entry = pte_mkwrite(pte_mkdirty(entry));
vmf->pte = pte_offset_map_lock(vma->vm_mm, vmf->pmd, vmf->address,
&vmf->ptl);
......
set_pte_at(vma->vm_mm, vmf->address, vmf->pte, entry);
......
}
#define __alloc_zeroed_user_highpage(movableflags, vma, vaddr) \
alloc_page_vma(GFP_HIGHUSER | __GFP_ZERO | movableflags, vma, vaddr)
3.2 文件映射
映射文件do_fault()函数调用了fault函数,该函数实际会根据不同的文件系统调用不同的函数,如ext4文件系统中vm_ops指向ext4_file_vm_ops,实际调用ext4_filemap_fault()函数,该函数会调用filemap_fault()完成实际的文件映射操作。
static vm_fault_t do_fault(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
struct mm_struct *vm_mm = vma->vm_mm;
vm_fault_t ret;
if (!vma->vm_ops->fault) {
......
}
vm_fault_t ext4_filemap_fault(struct vm_fault *vmf)
{
......
ret = filemap_fault(vmf);
......
}
file_map_fault()主要逻辑为
- 调用
find_ge_page()找到映射文件vm_file对应的物理内存缓存页面- 如果找到了,则调用
do_async_mmap_readahead(),预读一些数据到内存里面 - 否则调用
pagecache_get_page()分配一个缓存页,将该页加入LRU表中,并在address_space中调用
- 如果找到了,则调用
vm_fault_t filemap_fault(struct vm_fault *vmf)
{
int error;
struct file *file = vmf->vma->vm_file;
struct file *fpin = NULL;
struct address_space *mapping = file->f_mapping;
struct file_ra_state *ra = &file->f_ra;
struct inode *inode = mapping->host;
......
/*
* Do we have something in the page cache already?
*/
page = find_get_page(mapping, offset);
if (likely(page) && !(vmf->flags & FAULT_FLAG_TRIED)) {
/*
* We found the page, so try async readahead before
* waiting for the lock.
*/
fpin = do_async_mmap_readahead(vmf, page);
} else if (!page) {
/* No page in the page cache at all */
......
}
struct page *pagecache_get_page(struct address_space *mapping, pgoff_t offset,
int fgp_flags, gfp_t gfp_mask)
{
......
page = __page_cache_alloc(gfp_mask);
......
err = add_to_page_cache_lru(page, mapping, offset, gfp_mask);
......
}
3.3 页交换
前文提到了我们会通过主动回收或者被动回收的方式将物理内存已映射的页面回收至硬盘中,当数据再次访问时,我们又需要通过do_swap_page()将其从硬盘中读回来。do_swap_page() 函数逻辑流程如下:查找 swap 文件有没有缓存页。如果没有,就调用 swapin_readahead()将 swap 文件读到内存中来形成内存页,并通过 mk_pte() 生成页表项。set_pte_at 将页表项插入页表,swap_free 将 swap 文件清理。因为重新加载回内存了,不再需要 swap 文件了。
vm_fault_t do_swap_page(struct vm_fault *vmf)
{
......
entry = pte_to_swp_entry(vmf->orig_pte);
......
page = lookup_swap_cache(entry, vma, vmf->address);
swapcache = page;
if (!page) {
struct swap_info_struct *si = swp_swap_info(entry);
if (si->flags & SWP_SYNCHRONOUS_IO &&
__swap_count(si, entry) == 1) {
/* skip swapcache */
page = alloc_page_vma(GFP_HIGHUSER_MOVABLE, vma,
vmf->address);
......
} else {
page = swapin_readahead(entry, GFP_HIGHUSER_MOVABLE,
vmf);
swapcache = page;
}
......
pte = mk_pte(page, vma->vm_page_prot);
......
set_pte_at(vma->vm_mm, vmf->address, vmf->pte, pte);
arch_do_swap_page(vma->vm_mm, vma, vmf->address, pte, vmf->orig_pte);
vmf->orig_pte = pte;
......
swap_free(entry);
......
}
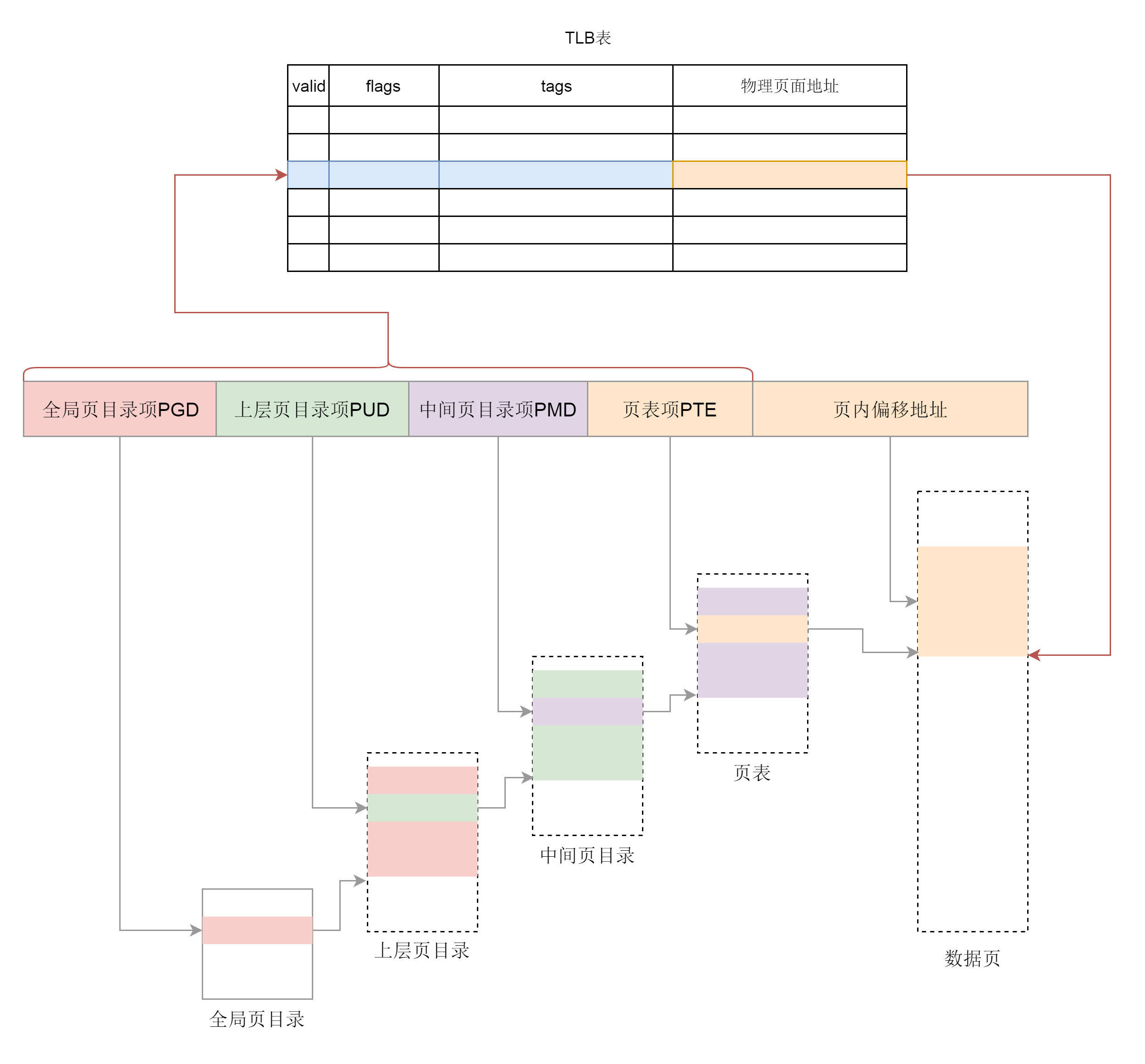
通过以上步骤,用户态的缺页异常就处理完毕了。物理内存中有了页面,页表也建立好了映射。接下来,用户程序在虚拟内存空间里面可以通过虚拟地址顺利经过页表映射的访问物理页面上的数据了。页表一般都很大,只能存放在内存中。操作系统每次访问内存都要折腾两步,先通过查询页表得到物理地址,然后访问该物理地址读取指令、数据。为了加快映射速度,我们引入了 [TLB](https://en.wikipedia.org/wiki/Translation_lookaside_buffer#:~:text=A%20translation%20lookaside%20buffer%20(TLB,called%20an%20address%2Dtranslation%20cache.)(Translation Lookaside Buffer),我们经常称为快表,专门用来做地址映射的硬件设备。它不在内存中,可存储的数据比较少,但是比内存要快。所以我们可以想象,TLB 就是页表的 Cache,其中存储了当前最可能被访问到的页表项,其内容是部分页表项的一个副本。有了 TLB 之后,我们先查块表,块表中有映射关系,然后直接转换为物理地址。如果在 TLB 查不到映射关系时,才会到内存中查询页表。
四. 内核态内存映射及缺页异常
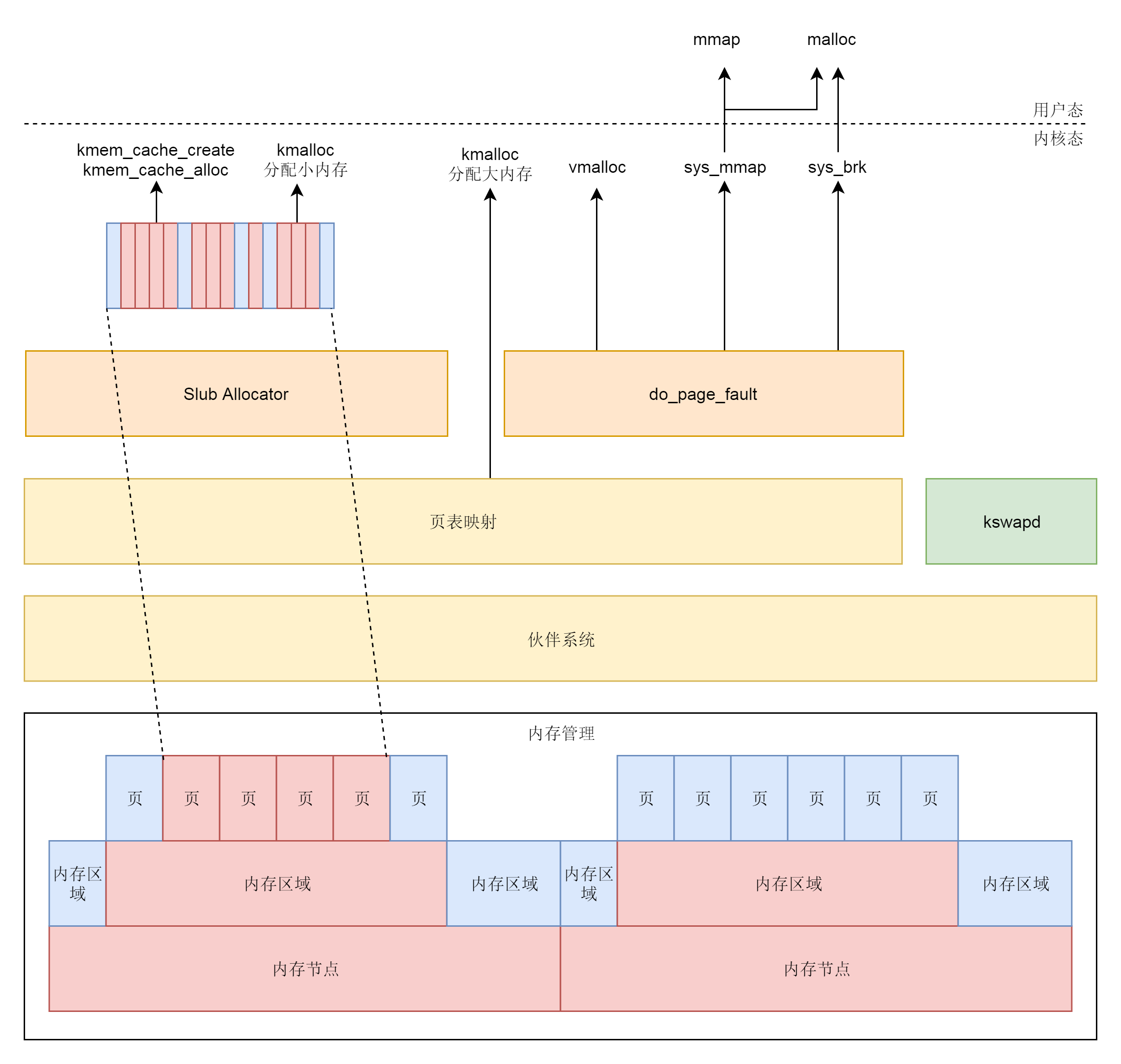
和用户态使用malloc()类似,内核态也有相应的内存映射函数:vmalloc()可用于分配不连续物理页(使用伙伴系统),kmem_cache_alloc()和kmem_cache_create()使用slub分配器分配小块内存,而kmalloc()类似于malloc(),在分配大内存的时候会使用伙伴系统,分配小内存则使用slub分配器。分配内存后会转换为虚拟地址,保存在内核页表中进行映射,有需要时直接访问。由于vmalloc()会带来虚拟连续页和物理不连续页的映射,因此一般速度较慢,使用较少,相比而言kmalloc()使用的更为频繁。而kmem_cache_alloc()和kmem_cache_create()会分配更为精准的小内存块用于特定任务,因此也比较常用。
相对于用户态,内核态还有一种特殊的映射:临时映射。内核态高端内存地区为了节省空间会选择临时映射,采用kmap_atomic()实现。如果是 32 位有高端地址的,就需要调用 set_pte 通过内核页表进行临时映射;如果是 64 位没有高端地址的,就调用 page_address,里面会调用 lowmem_page_address。其实低端内存的映射,会直接使用 __va 进行临时映射。
void *kmap_atomic_prot(struct page *page, pgprot_t prot)
{
......
if (!PageHighMem(page))
return page_address(page);
......
vaddr = __fix_to_virt(FIX_KMAP_BEGIN + idx);
set_pte(kmap_pte-idx, mk_pte(page, prot));
......
return (void *)vaddr;
}
void *kmap_atomic(struct page *page)
{
return kmap_atomic_prot(page, kmap_prot);
}
static __always_inline void *lowmem_page_address(const struct page *page)
{
return page_to_virt(page);
}
#define page_to_virt(x) __va(PFN_PHYS(page_to_pfn(x)
kmap_atomic ()发现没有页表的时候会直接创建页表进行映射。而 vmalloc ()只分配了内核的虚拟地址。所以访问它的时候,会产生缺页异常。内核态的缺页异常还是会调用 do_page_fault(),最终进入vmalloc_fault()。在这里会实现内核页表项的关联操作,从而完成分配,整体流程和用户态相似。
static noinline int vmalloc_fault(unsigned long address)
{
unsigned long pgd_paddr;
pmd_t *pmd_k;
pte_t *pte_k;
/* Make sure we are in vmalloc area: */
if (!(address >= VMALLOC_START && address < VMALLOC_END))
return -1;
/*
* Synchronize this task's top level page-table
* with the 'reference' page table.
*
* Do _not_ use "current" here. We might be inside
* an interrupt in the middle of a task switch..
*/
pgd_paddr = read_cr3_pa();
pmd_k = vmalloc_sync_one(__va(pgd_paddr), address);
if (!pmd_k)
return -1;
pte_k = pte_offset_kernel(pmd_k, address);
if (!pte_present(*pte_k))
return -1;
return 0
}
五. 总结
至此,我们分析了内存物理地址和虚拟地址的映射关系,结合前文页的分配和管理,内存部分的主要功能就算是大致分析清楚了,最后引用极客时间中的一幅图作为总结,算是全部知识点的汇总。
代码资料
[1] brk
[2] mmap
[3] page_fault
参考文献
[1] wiki
[3] woboq
[4] Linux-insides
[5] 深入理解Linux内核
[6] Linux内核设计的艺术
[7] 极客时间 趣谈Linux操作系统















 655
655











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











