






-
Spark Core
1.1 第一天介绍发展、特性。
1.2 安装了standalone模式:伪分布式
1.3 部署模式——local、standalone、yarn模式。 mesos、云…
1.4 编码:java、lambda、scala
1.5 底层执行流程 -
Scala
2.1 集合
Array : 长度可变。长度不可变
Set : 有序:TreeSet/无序
List/ListBuffer: 长度、元素值可变、元素值长度不可变
Tuple : 都是初始化之后就不可变了。元祖是只读的,作用传值。JavaBean
Map : key对应的value可变/不可变
2.2 函数式编程
2.2.1 将函数赋值给一个变量,也衍生出来一种新的定义函数方式
val method = (name:String) => println(name)
def func(name:String) = println(name)
2.2.2 匿名函数
2.2.3 将函数作为一个参数传递给另一个函数
def func(f:(String) => Unit):Unit = {}
2.2.4 类型推断
func(s => println(“”))
2.2.5 高阶函数
2.2.6 闭包和柯力化
2.3 隐式转换
2.3.1 隐式函数
作用:不修改源码就能添加一个新的功能
2.3.2 隐式参数
隐式参数可传可不传,不传使用它默认的参数
sorted(implicit Ordering)
# Spark cored第一天知识点回顾
```sh
##1. Spark整个生态 (记忆)
##1.1 Spark core 、 Spark Sql 、 Spark Streaming 、 Structured Streaming 、 Spark MLlib 、 Spark Graphx
##2. spark发展史(了解)
##3. 比较hadoop(mapreduce)和spark的优缺点 : 最快100倍,即使离线计算也块至少10倍以上
##3.1 spark比mr块的最主要的原因是什么?基于内存计算
##4. spark部署
##4.1 windows端的部署
##4.2 spark的standalone模式(这种模式不太用)
- spark-evn.sh
- 内网ip和公网ip的区别
##4.3 编程初体验 : wordcount
- java : 又臭又长
- lambda :java8之后才出现的新语法
- scala :简洁
##5. 打包,存放的服务器端运行
##5.1 maven中加入打包插件(将第三方的jar包也打包到jar中)
##5.2 使用spark-submit来提交我们的spark程序
一 Spark发展历史
2009年在伯克利大学研究型项目,2010年通过BSD许可协议正式对外发布(开源)。2012年Spark第一篇论文发布,发布了第一个正式版(Spark 0.6.0)。
2013年被纳入到apache的基金会中,随后发布了Spark Streaming、Spark Mllib(机器学习库)、Shark(Spark on Hadoop)。
2014年5月底发布Spark1.0.0发布。发布Spark Graphx(图计算)、Spark SQL代替Shark
2015年,推出DataFrame(spark第二代编程模型),Spark第一代编程模型使用的RDD。国内真正的开始普及Spark的就是这年。
2016年,推出DataSet(spark第三代编程模型)
2017年,推出Structured Streaming(结构流),spark streaming的升级版。
2018年,Spark 2.4.0将spark底层的通信框架akka替换成了netty。
…
2022年,Spark已经发展3.x.x版本
二 Spark学习什么
Spark Core : Spark核心API,提供DAG分布式内存计算框架
Spark SQL : 提供交互式查询API
Spark Streaming/Structured Streaming :实时流处理框架
Spark ML : 机器学习API(在项目中用到)
Spark Graphx : 图计算
三 Spark的由来
-
Hadoop缺点
-
不适合低延迟数据访问(Mapreduce的缺点)
-
无法高效存储大量小文件
-
不支持多用户写入以及任意修改文件
-
Hadoop与Spark的关系与区别
| Hadoop(Mapreduce) | Spark | |
|---|---|---|
| 起源 | 2005 | 2009 |
| 数据处理引擎 | Batch(批处理) | Batch(批处理) |
| 编程模型 | Mapreduce | RDD(弹性分布式数据集) |
| 内存管理 | Disk Based(基于磁盘) | JVM Managed |
| 延迟度 | High | Medium |
| 吞吐量 | Medium | High |
| 优化机制 | Manual | Manual |
| API | Low-Level(代码提供了底层功能) | High-Level(高级功能以及封装好了) |
| 流式处理支持 | NA(Storm) | Spark Streaming/Structured Streaming(spark的流式计算本质上还是批式计算) |
| SQL支持 | Hive、Impala | Spark SQL |
| Graph支持 | NA(pregel) | Graphx |
| 机器学习支持 | NA | SparkMllib |
- 处理流程比较
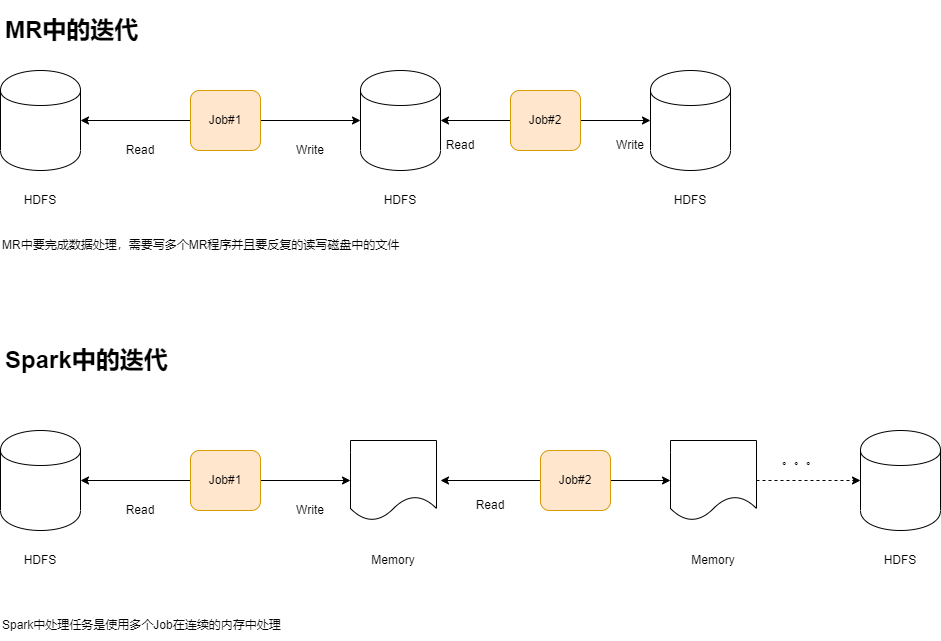
- 总结
- Spark把运算的中间数据存放在内存,迭代计算效率更高;Mapreduce的中间结果需要落地到磁盘,这样必然会有磁盘的io操作,非常的影响性能。
- Spark容错性更高,通过弹性式分布式数据集RDD来实现高效容错。所谓弹性:就是空间足够就在内存中计算,空间不够就在磁盘中计算。如果一旦出现数据丢失,她可以利用DAG的血缘来做数据恢复。
- Spark的通用性更好,Spark提供了非常多的算子来帮助我们进行数据分析,比如transformation和action算子API功能来完成大量的分析工作。除此之外它还包括流式计算、图计算、机器学习库中的功能,而Mapreduce只提供了map和reduce两种操作,对于流式计算也很匮乏。
- Spark框架和生态更为复杂。首先有RDD、血缘lineage、执行时产生DAG(有向无环图)、stage划分等。很多时候spark job都需要根据不同业务场景进行调优从而达到性能要求;Mapreduce框架和生态就相对简单,对性能要求也较弱,但是想的运行还是较为稳定,适合长期后台运行。
1 Spark Core
实现了Spark的基本功能、包含了任务调度、内存管理、错误恢复、与存储系统交互等等模块。Spark Core还包含了RDD(弹性式分布式数据集)的API的定义
2 Spark SQL
是Spark用来操作结构化数据的程序包。通过Spark SQL的SQL功能,换言之就是使用SQL或HQL来进行数据的查询。Spark SQL支持多种数据源:比如hive、parquet、json等等。
3 Spark Streaming
Spark提供对实时数据进行流式计算的组件。提供了操作流式计算的API,并且与Spark Core中RDD API高度对应。
4 Structured Streaming
结构流是构建在Spark SQL引擎上的可伸缩且容错的流式处理引擎(理解未spark streqaming的升级版)。可以实现低至100毫秒的低延迟流式处理。
四 Spark的部署
Spark : 3.1.2
Hadoop : 3.2.1
1 基于windows的spark体验
1.1 解压
1.2 配置环境变量并启动
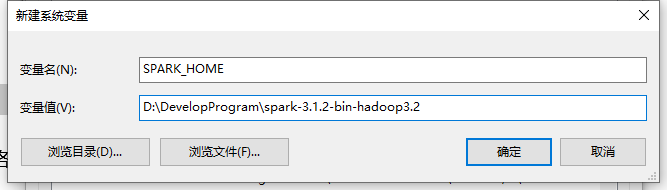
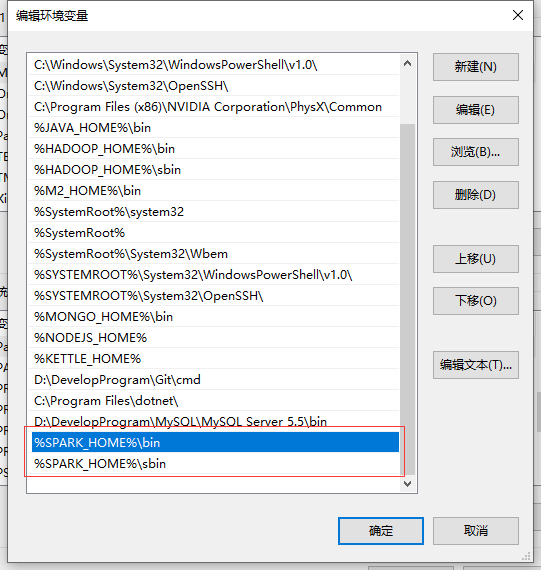
在配置好了环境变量之后
tip:
要求必须要配置SPARK_HOME这个变量,然后到其bin目录下启动spark-shell.cmd/spark-shell2.cmd
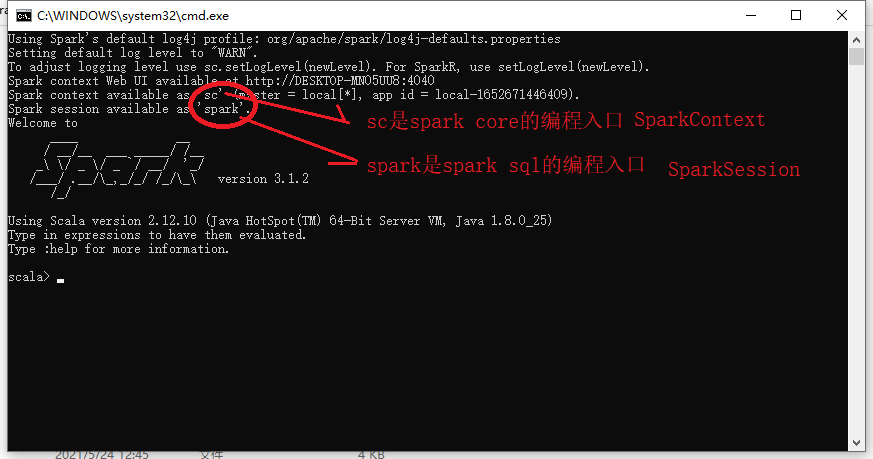
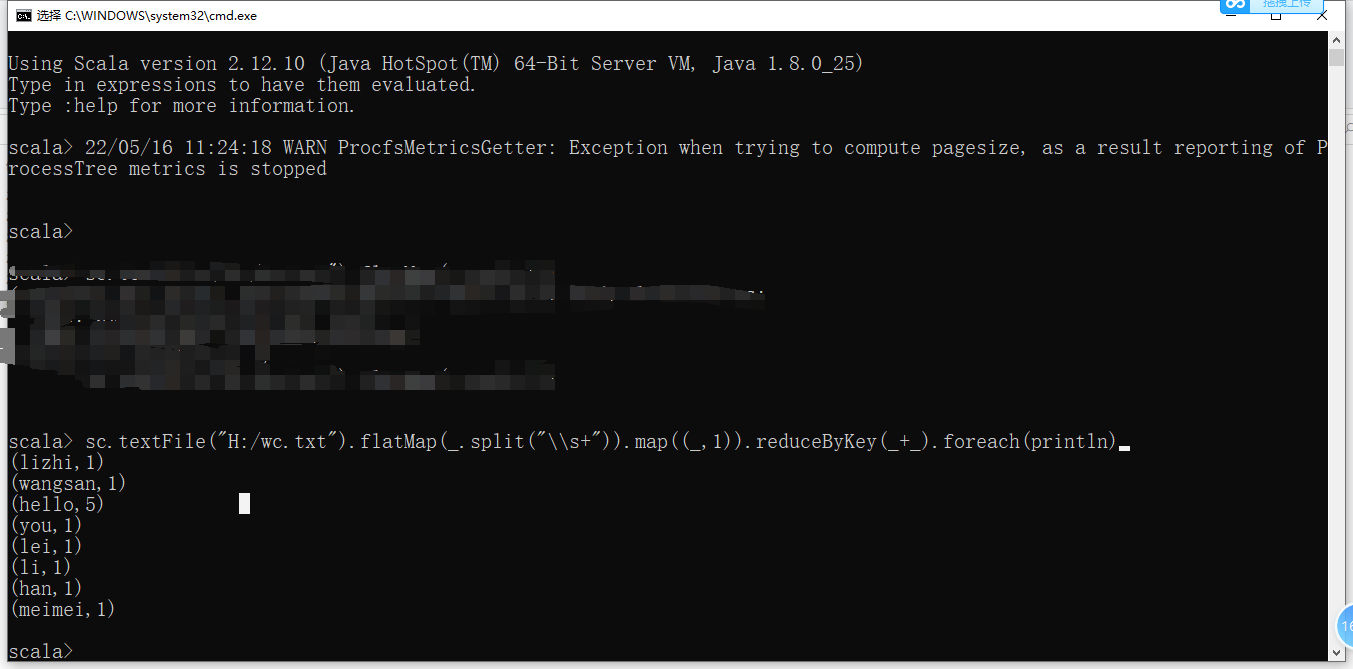
1.3 wordcount
scala> sc.textFile("H:/wc.txt")
.flatMap(_.split("\\s+"))
.map((_,1))
.reduceByKey(_+_)
.foreach(println)
(lizhi,1)
(wangsan,1)
(hello,5)
(you,1)
(lei,1)
(li,1)
(han,1)
(meimei,1)
2 基于Linux的Standalone模式的Spark安装
2.1 standalone模式安装
##1. 创建目录
[root@hadoop ~]# mkdir -p /opt/apps ## 用于存放安装软件的目录
[root@hadoop ~]# mkdir -p /opt/software ## 用于存放安装包的目录
##2. 解压
[root@hadoop software]# tar -zxvf spark-3.1.2-bin-hadoop3.2.tgz -C /opt/apps/
[root@hadoop software]# tar -zxvf scala-2.12.8.tgz -C /opt/apps/
[root@hadoop software]# tar -zxvf jdk-8u261-linux-x64.tar.gz -C /opt/apps/
##3. 配置环境变量
[root@hadoop scala-2.12.8]# vi /etc/profile
export JAVA_HOME=/opt/apps/jdk1.8.0_261
export SCALA_HOME=/opt/apps/scala-2.12.8
export SPARK_HOME=/opt/apps/spark-3.1.2-bin-hadoop3.2
export PATH=$PATH:$JAVA_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin
export CLASS_PATH=.:$JAVA_HOME/bin
[root@hadoop scala-2.12.8]# source /etc/profile
##4. 配置spark
[root@hadoop scala-2.12.8]# cd /opt/apps/spark-3.1.2-bin-hadoop3.2/conf/
##4.1 配置spark-env.sh
[root@hadoop conf]# mv spark-env.sh.template spark-env.sh
[root@hadoop conf]# vim spark-env.sh
export JAVA_HOME=/opt/apps/jdk1.8.0_261
##4.2 配置workers
[root@hadoop conf]# mv workers.template workers
[root@hadoop conf]# vim workers
hadoop
##5. 如果是全分布式,你还需要将conf目录中的所有的文件分发给其他的服务器节点
[root@hadoop conf]# scp -r /opt/apps/spark-3.1.2-bin-hadoop3.2/ root@hadoop01:$PWD
##6. 启动Spark集群
[root@hadoop sbin]# mv start-all.sh start-all-spark.sh
[root@hadoop sbin]# mv stop-all.sh stop-all-spark.sh
[root@hadoop sbin]# start-all-spark.sh ## 启动
[root@hadoop sbin]# stop-all-spark.sh ## 停止
##7. 查看webui
http://hadoop:8080
2.2 关于云服务器公网ip和内网ip的区别
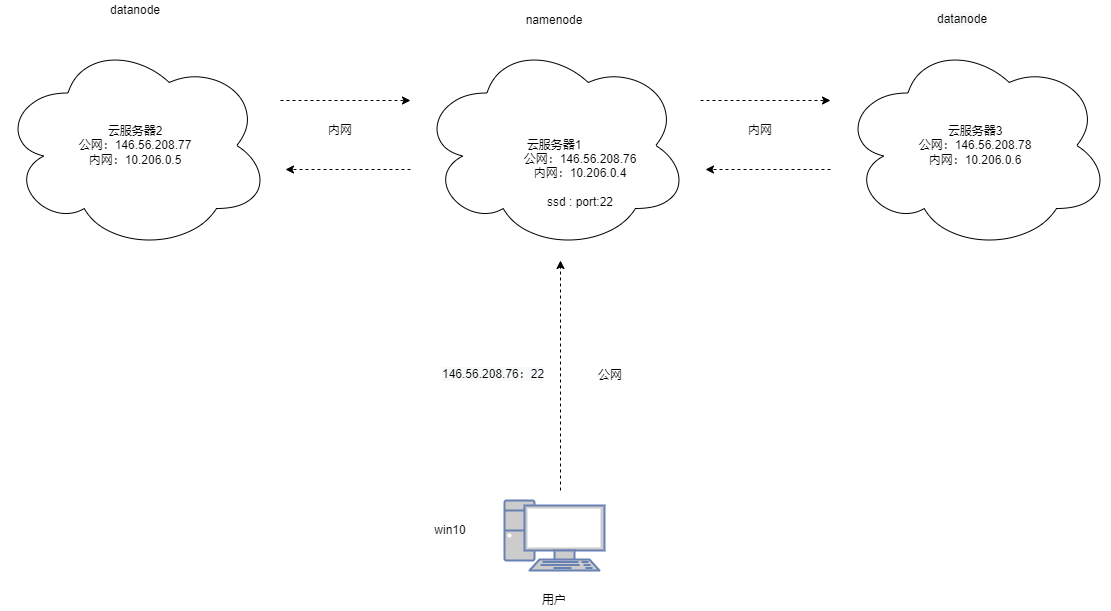
2.3 集群结构
2.4 spark-env.sh
# 使用spark-submit脚本的时候需要使用到以下的配置:
# ./bin/run-example or ./bin/spark-submit
# - HADOOP_CONF_DIR, to point Spark towards Hadoop configuration files
# - SPARK_LOCAL_IP, to set the IP address Spark binds to on this node
# - SPARK_PUBLIC_DNS, to set the public dns name of the driver program
# 配置执行器和驱动程序在服务器内部运行相关的配置
# - SPARK_LOCAL_IP, to set the IP address Spark binds to on this node
# - SPARK_PUBLIC_DNS, to set the public DNS name of the driver program
# - SPARK_LOCAL_DIRS, storage directories to use on this node for shuffle and RDD data
# - MESOS_NATIVE_JAVA_LIBRARY, to point to your libmesos.so if you use Mesos
# Spark使用Yarn模式的配置就在这个地方配置
# - SPARK_CONF_DIR, Alternate conf dir. (Default: ${SPARK_HOME}/conf)
# - HADOOP_CONF_DIR, to point Spark towards Hadoop configuration files
# - YARN_CONF_DIR, to point Spark towards YARN configuration files when you use YARN
# - SPARK_EXECUTOR_CORES, Number of cores for the executors (Default: 1).
# - SPARK_EXECUTOR_MEMORY, Memory per Executor (e.g. 1000M, 2G) (Default: 1G)
# - SPARK_DRIVER_MEMORY, Memory for Driver (e.g. 1000M, 2G) (Default: 1G)
export HADOOP_CONF_DIR=/opt/apps/hadoop-3.2.1/etc/hadoop
export YARN_CONF_DIR=/opt/apps/hadoop-3.2.1/etc/hadoop
# 配置使用standalone模式的spark集群的配置信息
# - SPARK_MASTER_HOST, to bind the master to a different IP address or hostname
# - SPARK_MASTER_PORT / SPARK_MASTER_WEBUI_PORT, to use non-default ports for the master
# - SPARK_MASTER_OPTS, to set config properties only for the master (e.g. "-Dx=y")
# - SPARK_WORKER_CORES, to set the number of cores to use on this machine
# - SPARK_WORKER_MEMORY, to set how much total memory workers have to give executors (e.g. 1000m, 2g)
# - SPARK_WORKER_PORT / SPARK_WORKER_WEBUI_PORT, to use non-default ports for the worker
# - SPARK_WORKER_DIR, to set the working directory of worker processes
# - SPARK_WORKER_OPTS, to set config properties only for the worker (e.g. "-Dx=y")
# - SPARK_DAEMON_MEMORY, to allocate to the master, worker and history server themselves (default: 1g).
# - SPARK_HISTORY_OPTS, to set config properties only for the history server (e.g. "-Dx=y")
# - SPARK_SHUFFLE_OPTS, to set config properties only for the external shuffle service (e.g. "-Dx=y")
# - SPARK_DAEMON_JAVA_OPTS, to set config properties for all daemons (e.g. "-Dx=y")
# - SPARK_DAEMON_CLASSPATH, to set the classpath for all daemons
# - SPARK_PUBLIC_DNS, to set the public dns name of the master or workers
export SPARK_MASTER_HOST=hadoop
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_CORES=2
export SPARK_WORKER_MEMORY=1g
# Options for launcher
# - SPARK_LAUNCHER_OPTS, to set config properties and Java options for the launcher (e.g. "-Dx=y")
# Generic options for the daemons used in the standalone deploy mode
# - SPARK_CONF_DIR Alternate conf dir. (Default: ${SPARK_HOME}/conf)
# - SPARK_LOG_DIR Where log files are stored. (Default: ${SPARK_HOME}/logs)
# - SPARK_LOG_MAX_FILES Max log files of Spark daemons can rotate to. Default is 5.
# - SPARK_PID_DIR Where the pid file is stored. (Default: /tmp)
# - SPARK_IDENT_STRING A string representing this instance of spark. (Default: $USER)
# - SPARK_NICENESS The scheduling priority for daemons. (Default: 0)
# - SPARK_NO_DAEMONIZE Run the proposed command in the foreground. It will not output a PID file.
# Options for native BLAS, like Intel MKL, OpenBLAS, and so on.
# You might get better performance to enable these options if using native BLAS (see SPARK-21305).
# - MKL_NUM_THREADS=1 Disable multi-threading of Intel MKL
# - OPENBLAS_NUM_THREADS=1 Disable multi-threading of OpenBLAS
export JAVA_HOME=/opt/apps/jdk1.8.0_261
export SCALA_HOME=/opt/apps/scala-2.12.8
3 Spark编程初体验
3.1 创建spark的maven工程
##1. 使用idea创建一个普通的maven工程,一直下一步即可
##2. 导入spark的依赖:pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.qf.bigdata</groupId>
<artifactId>spark</artifactId>
<version>1.0</version>
<properties>
<spark-version>3.1.2</spark-version>
<!-- 配置maven的编译器版本 -->
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<!-- spark core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>${spark-version}</version>
</dependency>
<!-- spark sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>${spark-version}</version>
</dependency>
<!-- spark streaming -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>${spark-version}</version>
</dependency>
</dependencies>
</project>
##3. 创建scala目录并设置scala目录为编码目录
##3.1 CTRL + Shift + Alt + S
##3.2 Modules -> 选中scala目录 -> Sources。保存即可
3.2 Java : WordCount
package com.qf.bigdata.spark.core.day1;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
/**
* 第一个Spark Core的WordCount程序
*/
public class Demo1_WordCount {
public static void main(String[] args) {
//1. 创建Spark的编程入口
//1.1 Spark的配置对象,主要作用是用于配置spark相关的配置信息
SparkConf conf = new SparkConf();
//1.2 使用本地的硬件配置信息配置spark
conf.setMaster("local[*]");
//1.3 配置本次spark的程序的程序名称
conf.setAppName(Demo1_WordCount.class.getSimpleName());
//1.4 通过配置对象获取到Spark Core的核心对象
JavaSparkContext sc = new JavaSparkContext(conf);
//2. 加载外部数据
JavaRDD<String> linesRDD = sc.textFile("H:/wc.txt");
//2.1 遍历读取文件的内容
linesRDD.foreach(new VoidFunction<String>() {
public void call(String line) throws Exception {
System.out.println(line);
}
});
//3. flatmap
JavaRDD<String> wordsRDD = linesRDD.flatMap(new FlatMapFunction<String, String>() {
public Iterator<String> call(String line) throws Exception {
return Arrays.asList(line.split("\\s+")).iterator();
}
});
//3.1 遍历读取文件的内容
wordsRDD.foreach(new VoidFunction<String>() {
public void call(String line) throws Exception {
System.out.println(line);
}
});
//4. map
JavaPairRDD<String, Integer> pairRDD = wordsRDD.mapToPair(new PairFunction<String, String, Integer>() {
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
});
//4.1 遍历读取文件的内容
pairRDD.foreach(new VoidFunction<Tuple2<String, Integer>>() {
public void call(Tuple2<String, Integer> t) throws Exception {
System.out.println(t._1 + "-->" + t._2);
}
});
//5. reducebykey
JavaPairRDD<String, Integer> resRDD = pairRDD.reduceByKey(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
resRDD.foreach(new VoidFunction<Tuple2<String, Integer>>() {
public void call(Tuple2<String, Integer> t) throws Exception {
System.out.println(t._1 + "-->" + t._2);
}
});
}
}
3.3 Java Lambda : WordCount
package com.qf.bigdata.spark.core.day1;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
/**
* Java Lambda
*/
public class Demo2_Lambda {
public static void main(String[] args) {
//1. 创建Spark的编程入口
//1.1 Spark的配置对象,主要作用是用于配置spark相关的配置信息
SparkConf conf = new SparkConf();
//1.2 使用本地的硬件配置信息配置spark
conf.setMaster("local[*]");
//1.3 配置本次spark的程序的程序名称
conf.setAppName(Demo1_WordCount.class.getSimpleName());
//1.4 通过配置对象获取到Spark Core的核心对象
JavaSparkContext sc = new JavaSparkContext(conf);
//2. 加载外部数据
JavaRDD<String> linesRDD = sc.textFile("H:/wc.txt");
//2.1 遍历读取文件的内容
linesRDD.foreach(line -> System.out.println(line));
//3. flatmap
JavaRDD<String> wordsRDD = linesRDD.flatMap(line -> Arrays.asList(line.split("\\s+")).iterator());
wordsRDD.foreach(line -> System.out.println(line));
//4. map
JavaPairRDD<String, Integer> pairRDD = wordsRDD.mapToPair(word -> new Tuple2<String, Integer>(word, 1));
pairRDD.foreach(t -> System.out.println(t._1 + "-->" +t._2));
//5. reducebykey
JavaPairRDD<String, Integer> resRDD = pairRDD.reduceByKey((v1, v2) -> v1 + v2);
resRDD.foreach(t -> System.out.println(t._1 + "-->" +t._2));
//6. 释放资源
sc.close();
}
}
3.4 Scala : WordCount
package com.qf.bigdata.spark.core.day1
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo1_Scala_Spark_WordCount {
def main(args: Array[String]):Unit = {
//1. 创建SparkContext对象
val conf = new SparkConf().setMaster("local[*]").setAppName("scala_wordcount")
val sc = new SparkContext(conf)
//2. 读取数据
val lineRDD:RDD[String] = sc.textFile("H:/wc.txt")
//3. 切割
val wordRDD:RDD[String] = lineRDD.flatMap(_.split("\\s+"))
//4. map将数组中的元素转换成一个一个的元组
val pairRDD:RDD[(String, Int)] = wordRDD.map((_, 1))
//5. 汇总
val res = pairRDD.reduceByKey((v1, v2) => v1 + v2)
//6. 打印
res.foreach(println)
//7. 释放资源
sc.stop()
}
}
3.5 进一步简化的scala程序
package com.qf.bigdata.spark.core.day1
import org.apache.spark.{SparkConf, SparkContext}
object Demo1_Scala_Spark_WordCount {
def main(args: Array[String]):Unit = {
//1. 创建SparkContext对象
val sc = new SparkContext(new SparkConf().setMaster("local[*]").setAppName("scala_wordcount"))
//2. 读取数据
sc.textFile("H:/wc.txt").flatMap(_.split("\\s+"))
.map((_, 1)).reduceByKey((v1, v2) => v1 + v2).reduceByKey((v1, v2) => v1 + v2).foreach(println)
//7. 释放资源
sc.stop()
}
}
3.6 将spark程序打包存放到服务器中执行
3.6.1 修改依赖配置文件:pom.xml
<!-- 第三方jar包的打包插件 -->
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<plugins>
<!-- 第三方jar包的打包插件:如果你这里爆红,是因为之前没有下载过依赖,请你先下载再使用 -->
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- scala打包插件 -->
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
3.6.2 操作步骤
##1. 在HDFS中创建目录:/input
##2. 将wc.txt上传到/input目录中
##3. 将我们的程序打包并上传到linux:/data/jar
##tip:
## 修改代码的路径:sc.textFile("/wc.txt")
##4. 使用spark提交spark的程序:local模式
spark-submit \
--class com.qf.bigdata.spark.core.day1.Demo1_Scala_Spark_WordCount \
--master local \
/data/jars/spark-1.0-jar-with-dependencies.jar
3.7 关于Spark的部署模式
3.7.1 部署模式说明
##1. Local : 本地模式,一般用于测试,比如eclipse、idea写程序测试的时候
##2. standalone : 是spark自带的资源调度框架,如果使用此模式,你需要先自行的安装spark的分布式集群
##3. yarn(国内) : hadoop自带的资源调度框架,spark也可以将自己的job提交给yarn进行计算
##4. mesos(欧美) :资源调度框架,类似yarn
## tip:
我们在执行spark程序的时候需要设置master,从而来设置spark的部署模式,
那么设置部署模式一共有3种途径:
1. 在代码中设置(最高的)
2. 在配置文件中设置(其次)
3. 脚本/命令中设置(最低的)
3.7.2 standalone模式
##1. 修改代码,将setMaster的代码注释
##2. 重新打包
##3. 提交脚本
spark-submit \
--class com.qf.bigdata.spark.core.day1.Demo1_Scala_Spark_WordCount \
--master spark://10.206.0.4:7077 \
/data/jars/spark-1.0-jar-with-dependencies.jar
##1. 检查结果路径:
$SPARK_HOME/work/job#id/partitionId/结果日志
3.7.3 yarn模式
3.7.3.1 使用步骤
##1. 开启yarn的集群
##2. 提交脚本
spark-submit \
--class com.qf.bigdata.spark.core.day1.Demo1_Scala_Spark_WordCount \
--master yarn \
--deploy-mode cluster \
--driver-memory 600M \
--executor-memory 800M \
/data/jars/spark-1.0-jar-with-dependencies.jar
tip:
client : 用于测试,一般jar包在哪里提交,就在那里运行
cluster : 用于生产,将jar包提交给rm,由rm负责分配给集群中的nm执行
##1. 查看结果:在hadoop的日志中查看
$HADOOP_HOME/logs/userlogs/#applicationid/#containerid/日志
3.7.3.2 Yarn Client的工作
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Uvqu8ou0-1653622391466)(011.png)]
- Spark Yarn Client向Yarn的ResourceManager申请启动ApplicationMaster。同时在SparkContext初始化将DAGSecheduler和TaskScheduler等组件,由于我们选择yarn-client模式,程序回选择YarnClientClustserSchelder和YarnClientSchedulerBackend。
- ResourceManager收到请求之后,在集群中选择某一个NodeManager作为该应用程序分配第一个Contaier,要求在这个Container启动一个ApplicationMaster。与Yarn-cluser模式区别是在ApplicationMaster中不运行SparkContext,只与SparkContext进行联系进行资源分配。
- Client中的SparkContext在初始化完毕之后,与ApplicationMaster只建立通讯。向ResurceManager注册,根据任务信息向ResourceManager申请资源。
- 一旦在ApplicationMaster中申请到了资源,便与对应NodeManager通信,要求它在活得的Container中启动CoarseGrainedExecutorBackend,这个组件在启动后向Client中的SparkContext注册并申请Task。
- client中的SparkContext分配Task给CoarseGrainedExecutorBackend执行并且向Driver汇报运行的状态和进度。
- 当整个应用程序完成之后,client的SparkContext向ResourceManager申请注销并关闭自己
3.7.3.3 Yarn Cluster
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IcR518re-1653622391467)(012.png)]
3.7.3.4 小结:cluster和client模式的区别
首先你要清楚一个概念:ApplicationMaster。在Yarn总,每个Application实例(Flink Application、Spark Application、Mapreduce Application…)都有ApplicationMaster进程,它是Application启动的时候产生的第一个容器。它负责和ResaurceManager打交道并请求资源,获取资源之后告诉NodeManager为其启动Container。从深层次将yarn-cluser和yarn-client模式的区别其实就是ApplicationMaster进程的区别。
Yarn-cluster模式下,Driver运行在ApplicationMaster中,它负责向Yarn申请资源,并监督job运行状况。用户提交job之后,client就可以关掉了,但是job会继续在yarn上运行。
yarn-client模式,ApplicationMaster仅仅向yarn请求executor,client会和请求的container通信来调度他们的工作,所以说client会不会关掉?答案肯定是不能。
得出一个结论:
- driver会和executor进行通信,所以yarn-cluster在提交app之后可以关闭client,但是yarn-client不可以
- yarn-cluster适合生产环境中使用,yarn-client适合在测试的交互环境中使用
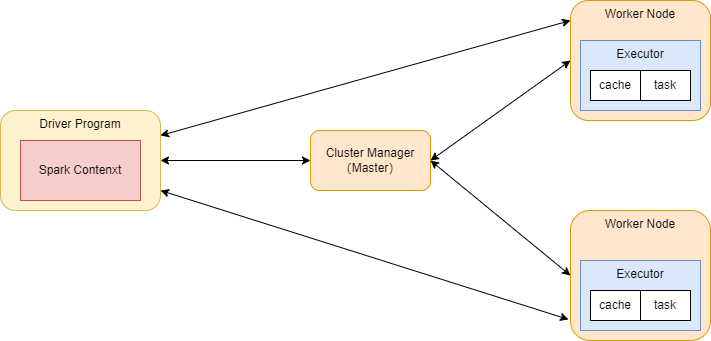
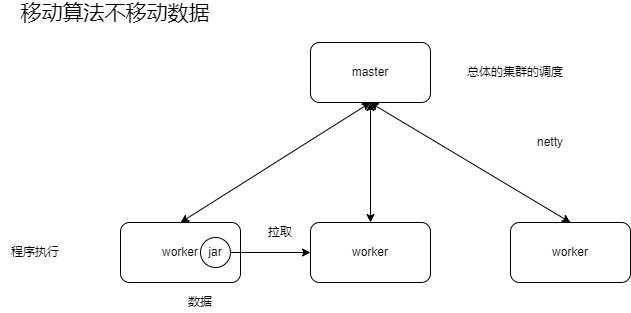
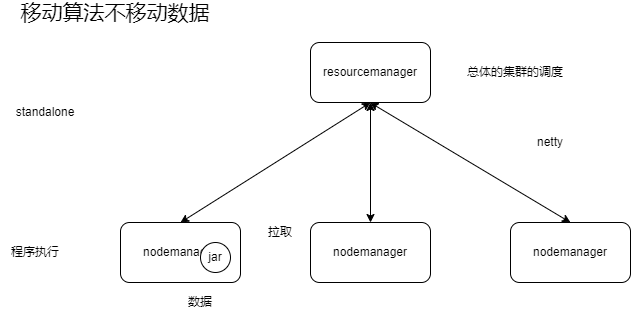
3.7.4 Spark Job提交原理
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5uTFbOk3-1653622391467)(013.png)]
Client : 客户端进程,负责提交作业到Master。在这里指的就是spark-submit
Master : Standalone模式中的主节点(在Yarn模式中就是ResourceManager),负责接受Client提交的job,管理Worker并命令Worker启动Driver和Executor。
Worker : Standalone模式中的从节点(在Yarn模式中就是NodeManager),负责管理本节点的资源,定期向Master汇报心跳,接受Master的命令,启动Executor
Driver : 一个Spark Job运行时包含一个Driver的进程,也是job的主进程,负责job的解析、生成Stage并调度Task到Executor上。包含了:DAGScheduler、TaskScheduler。
Executor:真正执行"spark job"的地方(spark job中的task),一个集群中包含了多个Executor,每个executor接受Driver的Launch Task,一个executor可以执行多个task。
stage : 一个spark job一般会包含1到多个stage
task : 一个stage包含了1到多个task,通过多个task实行并行运算的功能
DAGScheduler : 实现将Spark job分解成1到多个Stage的组件,每个Stage根据RDD的Partition个数决定Task的个数,然后生成相应的Taskset,放到TaskScheduler。
TaskScheduler :实现Task分配到Executor执行的组件
五 Spark 算子
1 什么是算子?
算子是数学中的一个概念。表示一个函数空间到另一个函数空间的映射:X -> Y。广义上讲算子可以推广到任何空间,比如内积空间。
对任何函数进行某一操作都可以认为是一个算子。对a函数进行b操作,那么这个b就是算子。
算子 == 函数
在spark中算子分为两类:
- Transformation : 转换算子
- Action : 行动算子
2 Transformation : 转换算子
2.1 介绍
RDD中所有转换算子都是延迟加载/懒加载的!!!也就是说他并不会直接进行计算。相反的,它值是记录了这些应用的基础数据集上的转换动作。
只有发生一个action的时候,这些转换算子才会真正的运行。
2.2 转换算子操作
2.2.1 map
他的作用几乎跟scala学习到的map的高阶函数一毛一样!!!
作用:就是对RDD中的数据进行一对一的处理。在spark中的所有的转换算子都只会产生一个处理数据之后的副本。
def map
[U: ClassTag](f: T => U): RDD[U]
package com.qf.bigdata.spark.core.day3
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo1_Map {
def main(args: Array[String]): Unit = {
//1. 获取到Spark的入口,SparkContext
val sc = new SparkContext("local[*]", "demo_map", new SparkConf())
//2. 集合
val list: Range.Inclusive = 1 to 7
//3. 加载内存中的数据
val listRDD: RDD[Int] = sc.parallelize(list)
//4. map
val mapRDD: RDD[Double] = listRDD.map(num => num * 10.0)
//5. foreach : action算子
mapRDD.foreach(println)
}
}
2.2.2 flatMap
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U]
package com.qf.bigdata.spark.core.day3
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo2_FlatMap {
def main(args: Array[String]): Unit = {
//1. 获取到Spark的入口,SparkContext
val sc = new SparkContext("local[*]", "demo_map", new SparkConf())
//2.
val lineRDD: RDD[String] = sc.parallelize(List(
"hello hello me"
))
//3.
val mapRDD: RDD[String] = lineRDD.flatMap(line => line.split("\\s+"))
mapRDD.foreach(println)
}
}
2.2.3 filter
def filter(f: T => Boolean): RDD[T]
package com.qf.bigdata.spark.core.day3
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo2_FlatMap {
def main(args: Array[String]): Unit = {
//1. 获取到Spark的入口,SparkContext
val sc = new SparkContext("local[*]", "demo_map", new SparkConf())
//2.
val lineRDD: RDD[String] = sc.parallelize(List(
"hello hello me"
))
//3.
val mapRDD: RDD[String] = lineRDD.flatMap(line => line.split("\\s+"))
mapRDD.filter(line => line.equals("hello")).foreach(println)
}
}
2.2.4 sample
类似于Hive中的TableSample。
作用:抽样查询。
def sample( withReplacement: Boolean, // 抽样方式,true返回抽样,false不反回抽样 fraction: Double, // 抽样比例,取值0~1(不准确) seed: Long = Utils.random.nextLong) // 抽样的种子 : RDD[T]
package com.qf.bigdata.spark.core.day3
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
object Demo3_Sample {
def main(args: Array[String]): Unit = {
//1. 获取到本地sparkContext对象
val sc: SparkContext = SparkUtils.getLocalSparkContext()
//2. 加载数据
val listRDD: RDD[Int] = sc.parallelize(1 to 10000)
//3. 抽样
var sampleRDD: RDD[Int] = listRDD.sample(true, 0.001)
Thread.sleep(100)
println("抽样空间 :" + sampleRDD.count())
sampleRDD.foreach(println)
println("-" * 100)
sampleRDD = listRDD.sample(true, 0.001)
Thread.sleep(100)
println("抽样空间 :" + sampleRDD.count())
sampleRDD.foreach(println)
// 释放资源
SparkUtils.close(sc)
}
}
2.2.5 union
def union(other: RDD[T]): RDD[T] // 将两个RDD进行合并的方法
package com.qf.bigdata.spark.core.day3
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
object Demo4_Union {
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtils.getLocalSparkContext()
//1. 加载数据
val list1RDD: RDD[Int] = sc.parallelize(List(
1, 2, 3, 4, 5
))
val list2RDD: RDD[Int] = sc.parallelize(List(
1, 2, 4, 6, 5
))
//2. union : 将连个rdd进行聚合
val unionRDD: RDD[Int] = list1RDD.union(list2RDD)
//3. 打印
unionRDD.foreach(println)
SparkUtils.close(sc)
}
}
2.2.6 distinct
去重
def distinct(): RDD[T]
package com.qf.bigdata.spark.core.day3
import org.apache.spark.rdd.RDD
object Demo5_Distinct {
def main(args: Array[String]): Unit = {
val sc = SparkUtils.getLocalSparkContext()
val listRDD: RDD[Int] = sc.parallelize(List(
1, 2, 2, 3, 3, 4, 5, 6
))
val disRDD: RDD[Int] = listRDD.distinct()
disRDD.foreach(println)
SparkUtils.close(sc)
}
}
2.2.7 join
join算子就是和sql的join查询一样的功能。但是这里如果想要 使用join算子,有一个前提:
你RDD中的元素必须得是一个二维元祖。
一 、回忆sql中的join
- 交叉查询
select * from A a accross Join B b; 因为产生笛卡儿积,所以一般都不用
- 内连接 : Inner Join
select * from A a [inner] Join B b [where|on a.xx = b.xx]
- 外连接
3.1 左外连接 : 以左表为主体,不管where条件是否成立,左边的表的数据都会显示
select * from A a left [outer] Join B b [where|on a.xx = b.xx]
3.2 右外连接 : 以右表为主体,不管where条件是否成立,右边的表的数据都会显示
select * from A a right [outer] Join B b [where|on a.xx = b.xx]
3.3 全外连接 : 以两边表为主体,不管where条件是否成立,两边边的表的数据都会显示
select * from A a full[outer] Join B b [where|on a.xx = b.xx]
3.4 左半连接
select * from A a left semi Join B b [where|on a.xx = b.xx]
二、 Spark中的Join
e.g.RDD[(K,V)] : K表示SQL中的on后面字段名称的值
RDD1[(K,V)], RDD2[(K,W)]
- 内链接
val rdd:RDD[(K, (V,W))] = rdd1.join(rdd2)
- 左连接
val rdd:RDD[(K, (V,Option[W]))] = rdd1.leftOuterJoin(rdd2)
- 右连接
val rdd:RDD[(K, (Option[V],W))] = rdd1.rightOuterJoin(rdd2)
- 全外
val rdd:RDD[(K, (Option[V],Option[W]))] = rdd1.fullOuterJoin(rdd2)
package com.qf.bigdata.spark.core.day3
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
object Demo6_Join {
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtils.getLocalSparkContext()
//1. 准备数据
//1.1 学生
val stuRDD: RDD[String] = sc.parallelize(List(
"1 刘诗诗 女 18",
"2 范冰冰 女 34",
"3 高圆圆 女 30",
"4 欧阳娜娜 女 19",
"5 李冰冰 女 40"
))
//1.2 成绩
val scoreRDD: RDD[String] = sc.parallelize(List(
"1 语文 59",
"2 数学 49",
"3 英语 39",
"4 体育 100",
"6 化学 0"
))
//2. 改造数据
val stuTupleRDD: RDD[(Int, String)] = stuRDD.map(line => {
val sid = line.substring(0, line.indexOf(" ")).toInt
val info = line.substring(line.indexOf(" ") + 1)
(sid, info)
})
val scoreTupleRDD: RDD[(Int, String)] = scoreRDD.map(line => {
val sid = line.substring(0, line.indexOf(" ")).toInt
val info = line.substring(line.indexOf(" ") + 1)
(sid, info)
})
println(stuTupleRDD.take(10).mkString(","))
println(scoreTupleRDD.take(10).mkString(","))
//3. join
//3.1 查询有成绩的学生
val stuInnerScoreRDD: RDD[(Int, (String, String))] = stuTupleRDD.join(scoreTupleRDD)
println(stuInnerScoreRDD.take(10).mkString(","))
//3.2 left
val stuLeftScoreRDD: RDD[(Int, (String, Option[String]))] = stuTupleRDD.leftOuterJoin(scoreTupleRDD)
println(stuLeftScoreRDD.take(10).mkString(","))
//3.3 right
val stuRightScoreRDD: RDD[(Int, (Option[String], String))] = stuTupleRDD.rightOuterJoin(scoreTupleRDD)
println(stuRightScoreRDD.take(10).mkString(","))
//3.4 full
val stuFullScoreRDD: RDD[(Int, (Option[String], Option[String]))] = stuTupleRDD.fullOuterJoin(scoreTupleRDD)
println(stuFullScoreRDD.take(10).mkString(","))
SparkUtils.close(sc)
}
}
2.2.8 groupByKey
groupBy —— 分组,由自己去指定字段分组
groupByKey —— 分组,他的分组字段就是这个key。所以要求RDD的元素必须得是一个二维的元组RDD[(K,V)]
这个算子在实际生产中使用不多,他不会进行局部聚合,就会导致分布式环境下这个算子性能不足
def groupByKey(): RDD[(K, Iterable[V])]
package com.qf.bigdata.spark.core.day3
import org.apache.spark.rdd.RDD
object Demo7 {
def main(args: Array[String]): Unit = {
val sc = SparkUtils.getLocalSparkContext()
//1. 加载数据
val stuRDD: RDD[String] = sc.parallelize(List(
"1,杨过,1,22,zzbigdata-2201",
"2,郭靖,1,42,zzbigdata-2202",
"3,张无忌,1,2,zzbigdata-2203",
"4,黄蓉,2,452,zzbigdata-2202",
"5,周芷若,2,12,zzbigdata-2203"
))
//2. 改造数据
val stuClassRDD: RDD[(String, String)] = stuRDD.map(line => {
val index: Int = line.lastIndexOf(",")
val className = line.substring(index + 1)
val info = line.substring(0, index)
(className, info)
})
//3. 分组:[(zzbigdata-2202, [(2,郭靖,1,42), (4,黄蓉,2,452)]), (...)]
val gbkRDD: RDD[(String, Iterable[String])] = stuClassRDD.groupByKey()
//4. 打印结果
println(gbkRDD.take(10).mkString(","))
SparkUtils.close(sc)
}
}
2.2.9 groupBy
def groupBy[K](f: T => K)(implicit kt: ClassTag[K]): RDD[(K, Iterable[T])]
e.g.
package com.qf.bigdata.spark.core.day3
import org.apache.spark.rdd.RDD
object Demo7 {
def main(args: Array[String]): Unit = {
val sc = SparkUtils.getLocalSparkContext()
//1. 加载数据
val stuRDD: RDD[String] = sc.parallelize(List(
"1,杨过,1,22,zzbigdata-2201",
"2,郭靖,1,42,zzbigdata-2202",
"3,张无忌,1,2,zzbigdata-2203",
"4,黄蓉,2,452,zzbigdata-2202",
"5,周芷若,2,12,zzbigdata-2203"
))
//3. 分组:[(zzbigdata-2202, [(2,郭靖,1,42), (4,黄蓉,2,452)]), (...)]
val classRDD: RDD[(String, Iterable[String])] = stuRDD.groupBy(line => {
val index: Int = line.lastIndexOf(",")
val className = line.substring(index + 1)
className
})
//4. 打印结果
println(classRDD.take(10).mkString(","))
SparkUtils.close(sc)
}
}
2.2.10 reduceByKey
和GroupByKey一样,需要先将这个RDD中的元素造成一个二维元祖。
作用:作用和GroupByKey类似,也是先通过Key来进行分组。不同之处,reduceByKey会再获取到每次的前一个元素和后一个元素。分组聚合求和的场景使用得比较多。
def reduceByKey(func: (V, V) => V): RDD[(K, V)] e.g. val sum = 0 for(i <- 1 to 10) { sum = sum + i } 第一个V : sum 第二个V : i
package com.qf.bigdata.spark.core.day3
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
object Demo8_ReduceByKey {
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtils.getLocalSparkContext()
val lineRDD: RDD[String] = sc.textFile("C:\\ftp\\pom.xml")
//wordcount
val resRDD: RDD[(String, Int)] = lineRDD.flatMap(_.split(",")).map((_, 1)).reduceByKey(_ + _)
println(resRDD.take(10).mkString(","))
SparkUtils.close(sc)
}
}
Spark中也有reduce算子,但是它不是转换算子,他是action算子
def reduce(f: (T, T) => T): T
2.2.11 sortByKey
RDD中的元素必须是二维元祖。无论是sortBy还是sortByKey也好,他们都只能保证分区内有序。
package com.qf.bigdata.spark.core.day3
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
object Demo9_SortByKey {
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtils.getLocalSparkContext()
//1. 准备数据
//1.1 学生
val stuRDD: RDD[String] = sc.parallelize(List(
"1 刘诗诗 女 18",
"2 范冰冰 女 34",
"3 高圆圆 女 30",
"4 欧阳娜娜 女 19",
"5 李冰冰 女 40"
),3)
//1.2 成绩
val scoreRDD: RDD[String] = sc.parallelize(List(
"1 语文 59",
"2 数学 49",
"3 英语 39",
"4 体育 100",
"6 化学 0"
),3)
//2. 改造数据
val stuTupleRDD: RDD[(Int, String)] = stuRDD.map(line => {
val sid = line.substring(0, line.indexOf(" ")).toInt
val info = line.substring(line.indexOf(" ") + 1)
(sid, info)
})
val scoreTupleRDD: RDD[(Int, String)] = scoreRDD.map(line => {
val sid = line.substring(0, line.indexOf(" ")).toInt
val info = line.substring(line.indexOf(" ") + 1)
(sid, info)
})
// 默认升序,设置为降序
// println(stuTupleRDD.sortByKey(false).take(10).mkString(","))
stuTupleRDD.sortByKey(false).foreach(println)
SparkUtils.close(sc)
}
}
2.2.12 mapPartitions
map算子的升级版。map算子的批处理版。此算子,一个分区作为一个批次来进行数据处理。
def mapPartitions[U: ClassTag]( f: Iterator[T] => Iterator[U], preservesPartitioning: Boolean = false): RDD[U
2.2.13 mapPartitionsWithIndex
是mapPartitions的升级版,他比前者多一个index(分区的索引)
def mapPartitionsWithIndex[U: ClassTag]( f: (Int, Iterator[T]) => Iterator[U], preservesPartitioning: Boolean = false): RDD[U]
package com.qf.bigdata.spark.core.day3
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
object Demo10_MapPartitions {
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtils.getLocalSparkContext()
val listRDD: RDD[Int] = sc.parallelize(1 to 10, 3)
listRDD.map(num => num * 10).foreach(println)
println("-" * 10)
listRDD.mapPartitions(partitions => partitions.map(_ * 10)).foreach(println)
println("-" * 10)
listRDD.mapPartitionsWithIndex {
case (index, partitions) => {
println(s"partition's id is ${index}, partitions 's data is ${partitions.mkString(",")}")
partitions.map(_ * 10)
}
}.foreach(println)
SparkUtils.close(sc)
}
}
2.2.14 repatition和coalesce
重分区。其实repatition是coalesce实现的。coalesce默认使用的是窄依赖,repatition是宽依赖的。一般使用的时候对于分区的情况我们都用coalesce;分区增加使用的是repatition。
- coalesce&repatition
def coalesce(numPartitions: Int, shuffle: Boolean = false, partitionCoalescer: Option[PartitionCoalescer] = Option.empty) (implicit ord: Ordering[T] = null) : RDD[T]
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]
package com.qf.bigdata.spark.core.day3
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
object Demo11_Repatition {
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtils.getLocalSparkContext()
val listRDD: RDD[Int] = sc.parallelize(1 to 10000)
println(listRDD.getNumPartitions)
//重分区
val colRDD: RDD[Int] = listRDD.coalesce(10, true)
println(colRDD.getNumPartitions)
val reRDD: RDD[Int] = listRDD.repartition(10)
val colRDD2: RDD[Int] = reRDD.coalesce(1)
println(colRDD2.getNumPartitions)
SparkUtils.close(sc)
}
}
2.2.15 CombineByKey
通过观察底层(ReduceByKey、GroupByKey)源码,发现他们的底层源码都是通过CombineByKeyWithClassTag这个函数来实现的。
CombineByKey其实就是CombineByKeyWithClassTag的简化版。
CombineByKey是Spark底层的聚合算子之一,按照key进行聚合,spark提供的很多的高阶算子都是基于这个算子实现的。
一般使用spark用不到这个算子,但是一旦你发现spark自带的算子不够用的,你需要自定义聚合算子的时候,就需要利用这个算子来自定义聚合算子。
def combineByKey[C]( createCombiner: V => C, // 初始化方法,每个key第一次出现的自动的调用这个方法 mergeValue: (C, V) => C, // 分区内聚合的方法,相同的key,对用了不同的value,在相同的区中的时候会调用此方法 mergeCombiners: (C, C) => C, // 全局聚合方法,所有的相同key的分区的数据会调用此方法进行聚合 ): RDD[(K, C)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1AW3BAMj-1653622391468)(014.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vDhSuGnF-1653622391468)(015.png)]
2.2.15.1 重写GroupByKey
package com.qf.bigdata.spark.core.day3
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import scala.collection.mutable.ArrayBuffer
object Demo12_CombineByKey_GBK {
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtils.getLocalSparkContext()
//1. 加载数据
val stuRDD: RDD[String] = sc.parallelize(List(
"王东阳,zzbigdata2201",
"徐明伟,zzbigdata2201",
"毕帆,zzbigdata2201",
"徐娟娟,hzbigdata2102",
"乌力吉,hzbigdata2102"
), 3)
//2. 查看哪些数据在哪些区
val class2InfoRDD: RDD[(String, String)] = stuRDD.mapPartitionsWithIndex {
case (partitionId, partitions) => {
// println(s"${partitionId} : ${partitions.mkString(",")}")
partitions.map(line => {
val index = line.lastIndexOf(",")
val className = line.substring(index + 1)
val info = line.substring(0, index)
(className, info)
}).toIterator
}
}
println("gbk ================================================")
val gbkRDD: RDD[(String, Iterable[String])] = class2InfoRDD.groupByKey()
gbkRDD.foreach(println)
println("combineByKey ---> GBK ================================================")
val cbk2GBK: RDD[(String, ArrayBuffer[String])] = class2InfoRDD.combineByKey(createCombiner, mergeValue, mergeCombiners)
cbk2GBK.foreach(println)
SparkUtils.close(sc)
}
/**
* 在同一个分区中,出现第一次key的时候调用一次
* 0 : 王东阳,zzbigdata2201
* 1 : 徐明伟,zzbigdata2201,毕帆,zzbigdata2201
* 2 : 徐娟娟,hzbigdata2102,乌力吉,hzbigdata2102
*
* 调用3次
*/
def createCombiner(stu:String):ArrayBuffer[String] = {
println(s"==============createCombiner<${stu}>===============================")
val ab: ArrayBuffer[String] = ArrayBuffer[String]()
ab.append(stu)
ab
}
/**
* 分区内的局部聚合(相同的key会调用一次此函数)
* 0 : 王东阳,zzbigdata2201
* 1 : 徐明伟,zzbigdata2201,毕帆,zzbigdata2201
* 2 : 徐娟娟,hzbigdata2102,乌力吉,hzbigdata2102
*
* 调用2次
*/
def mergeValue(ab:ArrayBuffer[String], stu:String):ArrayBuffer[String] = {
println(s"==============mergeValue局部聚合<${ab}>, 被聚合:${stu} ===============================")
ab.append(stu)
ab
}
/**
* 所有的分区中的相同的key的数据都回调用此方法进行全局聚合
* 0 : 王东阳,zzbigdata2201
* 1 : 徐明伟,zzbigdata2201,毕帆,zzbigdata220
* 2 : 徐娟娟,hzbigdata2102,乌力吉,hzbigdata2102
*
* 调用1次
*
* sum += i
*/
def mergeCombiners(sum:ArrayBuffer[String], i:ArrayBuffer[String]):ArrayBuffer[String] = {
println(s"==============mergeCombiners全局聚合<${sum}>, 被聚合:${i} ===============================")
sum .++:(i)
}
}
2.2.15.2 重写ReduceByKey
package com.qf.bigdata.spark.core.day3
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
object Demo13_CombineByKey {
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtils.getLocalSparkContext()
val lineRDD: RDD[String] = sc.parallelize(List(
"hello hello hello",
"me you him"
))
val mapRDD: RDD[(String, Int)] = lineRDD.flatMap(_.split("\\s+")).map((_, 1))
// reduceByKey
println("reduceByKey===============================")
mapRDD.reduceByKey(_+_).foreach(println)
println("combineByKey ========================= reduceByKey ==================================")
mapRDD.combineByKey[Int](
(num:Int) => num,
(sum:Int, num:Int) => sum + num,
(total:Int, sum:Int) => total + sum).foreach(println)
SparkUtils.close(sc)
}
}
2.2.16 aggregateByKey
他的底层也是通过CombineByKeyWithClassTag实现的。他也是自定义算子,用来模拟其他算子的。
aggregateByKey[U: ClassTag] (zeroValue: U) // 初始化值 (seqOp: (U, V) => U, // 局部聚合 combOp: (U, U) => U) // 全局聚合 : RDD[(K, U)]
2.2.16.1 重写GroupByKey
package com.qf.bigdata.spark.core.day4
import com.qf.bigdata.spark.core.day3.SparkUtils
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import scala.collection.mutable.ArrayBuffer
object Demo1_AggregateByKey_GBK {
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtils.getLocalSparkContext()
//1. 加载数据
val stuRDD: RDD[String] = sc.parallelize(List(
"王东阳,zzbigdata2201",
"徐明伟,zzbigdata2201",
"毕帆,zzbigdata2201",
"徐娟娟,hzbigdata2102",
"乌力吉,hzbigdata2102"
), 3)
//2. 查看哪些数据在哪些区
val class2InfoRDD: RDD[(String, String)] = stuRDD.mapPartitionsWithIndex {
case (partitionId, partitions) => {
// println(s"${partitionId} : ${partitions.mkString(",")}")
partitions.map(line => {
val index = line.lastIndexOf(",")
val className = line.substring(index + 1)
val info = line.substring(0, index)
(className, info)
}).toIterator
}
}
println("gbk ================================================")
val gbkRDD: RDD[(String, Iterable[String])] = class2InfoRDD.groupByKey()
gbkRDD.foreach(println)
println("aggregateByKey ---> GBK ================================================")
val abkGBK: RDD[(String, ArrayBuffer[String])] = class2InfoRDD.aggregateByKey(ArrayBuffer[String]())(
seqOp, combOp
)
abkGBK.foreach(println)
SparkUtils.close(sc)
}
/**
* 局部聚合
*/
def seqOp(ab:ArrayBuffer[String], stu:String):ArrayBuffer[String] = {
ab.append(stu)
ab
}
/**
* 全局聚合
* @param ab1 : sum
* @param ab2 : i
*/
def combOp(ab1:ArrayBuffer[String], ab2:ArrayBuffer[String]):ArrayBuffer[String] = ab1.++:(ab2)
}
2.2.16.2 重写ReduceByKey
package com.qf.bigdata.spark.core.day4
import com.qf.bigdata.spark.core.day3.SparkUtils
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
object Demo2_AggregateByKey_RBK {
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtils.getLocalSparkContext()
val lineRDD: RDD[String] = sc.parallelize(List(
"hello hello hello",
"me you him"
))
val mapRDD: RDD[(String, Int)] = lineRDD.flatMap(_.split("\\s+")).map((_, 1))
// reduceByKey
println("reduceByKey===============================")
mapRDD.reduceByKey(_+_).foreach(println)
println("aggregateByKey ========================= reduceByKey ==================================")
mapRDD.aggregateByKey(0)(_+_, _+_).foreach(println)
SparkUtils.close(sc)
}
}
3 Action算子
3.1 介绍
action算子的作用是用来驱动转换算子的,说白了就是,转换算子是延迟加载,没有action算子的驱动,转换算子是不执行的!!!所以一个spark程序中至少得有一个action算子。
如果RDD中有多个分区,所有的算子都是在RDD上的分区中执行的,而不是在本地Driver中执行
3.2 操作
3.2.1 foreach
3.2.2 count
作用:统计RDD中的元素的个数
def count(): Long
package com.qf.bigdata.spark.core.day4
import com.qf.bigdata.spark.core.day3.SparkUtils
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
object Demo3_Count {
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtils.getLocalSparkContext()
val listRDD: RDD[Int] = sc.parallelize(1 to 100)
println(listRDD.count())
SparkUtils.close(sc)
}
}
3.2.3 take(n)
作用:返回RDD中的前n个元素。多用于求去topn的业务
def take(num: Int): Array[T]
package com.qf.bigdata.spark.core.day4
import com.qf.bigdata.spark.core.day3.SparkUtils
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
object Demo3_Take {
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtils.getLocalSparkContext()
val listRDD: RDD[Int] = sc.parallelize(1 to 100)
println(listRDD.take(3).mkString(","))
SparkUtils.close(sc)
}
}
3.2.4 first
取RDD中的第一个元素
package com.qf.bigdata.spark.core.day4
import com.qf.bigdata.spark.core.day3.SparkUtils
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
object Demo3_First {
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtils.getLocalSparkContext()
val listRDD: RDD[Int] = sc.parallelize(1 to 100)
val first: Int = listRDD.first()
println(first)
SparkUtils.close(sc)
}
}
3.2.5 collect
字面解释,收集,这里表示拉取。这个算子的作用就是将不同分区的数据拉取到本地处理,但是这个算子有很大的风险,第一,他会导致driver所在的服务器的内存压力大;第二,在网络中进行大规模的数据传入本身存在巨大的风险;第三,大规模在网络中的传输数据速度很慢。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pVwq9aWv-1653622391469)(016.png)]
3.2.6 reduce
在spark中reduce是一个action算子。reduce不分组,只是对RDD专用的所有的元素进行聚合
def reduce(f: (T, T) => T): T
package com.qf.bigdata.spark.core.day4
import com.qf.bigdata.spark.core.day3.SparkUtils
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
object Demo4_Reduce {
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtils.getLocalSparkContext()
val userRDD: RDD[(String, String)] = sc.parallelize(List(
("name", "lixi"),
("age", "36"),
("gender", "male")
))
//1. 匿名函数
/*
* ((String, String), (String, String)) => (String, String)
*/
// val res1: (String, String) = userRDD.reduce(kv:Tuple2[String, String] => kv._1 + "_" + kv._2)
// println(res1)
println("----")
//2. 匹配模式
val res2: (String, String) = userRDD.reduce {
case ((k1, v1), (k2, v2)) => (k1 + "_" + k2, v1 + "_" + v2)
}
println(res2)
SparkUtils.close(sc)
}
}
3.2.7 countByKey
长得比较像转换算子,但是其实他是action算子。
作用:统计key的次数
package com.qf.bigdata.spark.core.day4
import com.qf.bigdata.spark.core.day3.SparkUtils
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
object Demo5_CountByKey {
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtils.getLocalSparkContext()
val userRDD: RDD[(String, String)] = sc.parallelize(List(
("name", "lixi"),
("age", "36"),
("gender", "male"),
("name", "rocklee")
))
val map: collection.Map[String, Long] = userRDD.countByKey()
println(map)
SparkUtils.close(sc)
}
}
3.2.8 saveAsTextFile
作用:以文本文件的形式保存数据(本地文件系统、HDFS)
def saveAsTextFile(path: String): Unit
package com.qf.bigdata.spark.core.day4
import com.qf.bigdata.spark.core.day3.SparkUtils
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
object Demo5_CountByKey {
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtils.getLocalSparkContext()
val userRDD: RDD[(String, String)] = sc.parallelize(List(
("name", "lixi"),
("age", "36"),
("gender", "male"),
("name", "rocklee")
))
userRDD.saveAsTextFile("src/main/resources/1")
SparkUtils.close(sc)
}
}
六 RDD编程模型介绍
1 什么是RDD
弹性式分布式数据集。Spark中计算的基本单元。分布式存储提升了RDD的读写性能,弹性表示内存充足数据就存储在内存中,内存不足,就存储在磁盘中。
一组RDD可以形成DAG(有向(方向)无环图)
RDD是Spark的第一代编程模型。
2 Spark的持久化设置
一般来说将数据从内存中保存到磁盘中就叫做持久化。从某些场景下,将数据从内存中溢出到缓存中也叫做持久化。
在RDD中有一个方法persist或cache,他们的作用就是标记RDD持久化。
persist是持久化数据到磁盘中,可以选择不同的持久化策略
| 持久化策略 | 含义 |
|---|---|
| MEMORY_ONLY(默认) | RDD中的数据以未经过序列化的Java对象的形式保存在内存中。如果内存不足,剩余的部分不会持久化,使用的时候, 没有持久化的部分重新加载。这种效率还可以。 |
| MEMORY_ONLY_SER | 相比较MEMORY_ONLY,多了一个序列化功能。他会对内存中的数据经过序列化为一个字节数组。 |
| MEMORY_AND_DISK | 弹性表示内存充足数据就存储在内存中(在内存中的时候没有经过序列化),内存不足,就存储在磁盘中 |
| MEMORY_AND_DISK_SER | 弹性表示内存充足数据就存储在内存中(在内存经过序列化),内存不足,就存储在磁盘中 |
| DISK_ONLY | 只存储在磁盘中 |
| xxx_2 | 上述的策略后面加上_2。比如:MEMORY_ONLY_2。_2表示的副本。性能肯定下降,但是安全性能提升。一般不用 |
| HEAP_OFF | 使用堆外内存(非spark内存),可以spark数据存储到:Redis、HBase、ClickHouse。。。 |
package com.qf.bigdata.spark.core.day4
import com.qf.bigdata.spark.core.day3.SparkUtils
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
object Demo6_Persist {
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtils.getLocalSparkContext()
var start = System.currentTimeMillis()
val textRDD: RDD[String] = sc.textFile("C:\\ftp\\SZBIGDATA-2103\\day3-flink旅游\\resource\\QParameterTool.java")
var count: Long = textRDD.count()
println(s"没有持久化 lines count : ${count}, cost time : ${System.currentTimeMillis() - start} ms")
textRDD.persist(StorageLevel.MEMORY_AND_DISK) // 开启持久化
start = System.currentTimeMillis()
count = textRDD.count()
println(s"持久化 lines count : ${count}, cost time : ${System.currentTimeMillis() - start} ms")
textRDD.unpersist() // 卸载持久化
SparkUtils.close(sc)
}
}
3 DAG :有向无环图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qPRDEFNg-1653622391470)(017.png)]
4 共享变量
所谓的共享变量就是大家都能使用的变量。那这个“大家”指什么东西?指的是执行器(executor)
4.1 广播变量
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t2nmvabd-1653622391470)(018.png)]
package com.qf.bigdata.spark.core.day4
import com.qf.bigdata.spark.core.day3.SparkUtils
import org.apache.spark.SparkContext
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
object Demo7_Broadcast {
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtils.getLocalSparkContext()
//1. 加载数据
val stuRDD = sc.parallelize(List(
Student("1", "令狐冲", "1", 11),
Student("2", "任盈盈", "0", 12),
Student("3", "岳灵珊", "0", 13),
Student("4", "东方姑娘", "2", 14),
))
val genderMap = Map(
"0" -> "小姐姐",
"1" -> "小哥哥"
)
//2. 经过分析,我们stuRDD在执行的时候会被分成多个task执行,需要genderMap多次,这样增大了传输,所以我们需要对他进行广播
val genderBC: Broadcast[Map[String, String]] = sc.broadcast(genderMap)
//3. 处理数据
val resRDD: RDD[Student] = stuRDD.map(stu => {
//3.1 从广播变量中获取到性别的值
val gender: String = genderBC.value.getOrElse(stu.gender, "人妖")
Student(stu.id, stu.name, gender, stu.age)
})
resRDD.foreach(println)
SparkUtils.close(sc)
}
}
case class Student(id:String, name:String, gender:String, age:Int)
4.2 累加器:类似于Mapreduce学习计数器(accumulator)
package com.qf.bigdata.spark.core.day4
import com.qf.bigdata.spark.core.day3.SparkUtils
import org.apache.spark.SparkContext
import org.apache.spark.util.LongAccumulator
object Demo8_Accumulator {
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtils.getLocalSparkContext()
val stuRDD = sc.parallelize(List(
"Our materialistic society to led us to believe that to cannot be obtained without having money."
))
// 统计to这个单词出现了几次
val count: Long = stuRDD.flatMap(_.split("\\s+")).filter(word => word == "to").count()
println(count)
// 利用累加器来统计
// 获取到累加器
val accumulator: LongAccumulator = sc.longAccumulator
stuRDD.flatMap(_.split("\\s+")).filter(word => {
val isok = word == "to"
if (isok) accumulator.add(1)
isok
}).foreach(println)
println(accumulator.value)
SparkUtils.close(sc)
}
}
5 分区
为了保证RDD中的并行读写,从而保证数据处理的速度,我们在RDD中有分区的概念,一个完整的数据RDD中被分为了多个分区存储。
对于数据分拆之后究竟存储于哪一个分区,是由分区器(Partitioner)决定。在Spark中默认提供了集中分区器,我们也可以自定义分区器。
Spark中目前支持的分区器:Hash分区和Range分区。
5.1 Partitioner
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KJYpB5yi-1653622391471)(019.png)]
5.1.1 HashPartitioner
90%以上RDD的相关分区默认都是使用的这个分区器。
作用:依据RDD中的key值进行hashcode,然后对整个分区数取模,得到paritionId值。同时支持key为null的情况,如果key为null将把这条数据存储到0分区中。
5.1.2 自定义Partitioner
根据自己的需求,量身定制的数据应该存储到哪一个分区中。
5.1.2.1 CustomerPartitioner
package com.qf.bigdata.spark.core.day5
import org.apache.spark.Partitioner
import scala.util.Random
/**
* 随机分区器
*/
class CustomerPartitioner(partitions: Int) extends Partitioner{
private val random = new Random()
/**
* 表示自定义分区器的分区数总共是多少
*/
override def numPartitions: Int = partitions
/**
* 根据key值分配数据到哪个分区中
*/
override def getPartition(key: Any): Int = random.nextInt(numPartitions)
}
5.1.2.2 Demo1_Partitioner
package com.qf.bigdata.spark.core.day5
import com.qf.bigdata.spark.core.day3.SparkUtils
import org.apache.spark.rdd.RDD
import org.apache.spark.{Partitioner, SparkContext}
object Demo1_Partitioner {
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtils.getLocalSparkContext()
//1. 加载数据,并处理数据为一个二维的元祖
val listRDD: RDD[(Int, Long)] = sc.parallelize(1 to 10, 4)
.zipWithIndex() // [(1,0),(2,1),(3,2),...,(10,9)]
//2. 如果我们不设置自定义分区器,默认使用的是hash分区
println("默认使用hashpartitioner ------------------------------------")
val func = (partitionId:Int, iterator:Iterator[(Int, Long)]) => iterator.map(t => {
s"[partition : ${partitionId}, value : ${t}]"
})
var arrays: Array[String] = listRDD.mapPartitionsWithIndex(func).collect()
arrays.foreach(println)
println("自定义分区器 ------------------------------------")
//3. 注册自定义分区器
val rdd2: RDD[(Int, Long)] = listRDD.partitionBy(new CustomerPartitioner(4))
arrays = rdd2.mapPartitionsWithIndex(func).collect()
arrays.foreach(println)
SparkUtils.close(sc)
}
}
布置作业:2个分区,1to10000,要求奇数分一个区,偶数分一个区
ftp://10.8.157.15/ZZBIGDATA-2201
七 综合练习
0 处理每次运行的时候日志问题
package com.qf.bigdata.spark.core.day5
import com.qf.bigdata.spark.core.day3.SparkUtils
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{Partitioner, SparkContext}
import org.slf4j.LoggerFactory
object Demo1_Partitioner {
//1. 获取到一个叫做Demo1_Partitioner的日志处理器
private val logger = LoggerFactory.getLogger(Demo1_Partitioner.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN) // 设置org包下的所有的日志打印都是WARN级别
val sc: SparkContext = SparkUtils.getLocalSparkContext()
//1. 加载数据,并处理数据为一个二维的元祖
val listRDD: RDD[(Int, Long)] = sc.parallelize(1 to 10, 4)
.zipWithIndex() // [(1,0),(2,1),(3,2),...,(10,9)]
//2. 如果我们不设置自定义分区器,默认使用的是hash分区
println("默认使用hashpartitioner ------------------------------------")
val func = (partitionId:Int, iterator:Iterator[(Int, Long)]) => iterator.map(t => {
s"[partition : ${partitionId}, value : ${t}]"
})
var arrays: Array[String] = listRDD.mapPartitionsWithIndex(func).collect()
arrays.foreach(println)
println("自定义分区器 ------------------------------------")
//3. 注册自定义分区器
val rdd2: RDD[(Int, Long)] = listRDD.partitionBy(new CustomerPartitioner(4))
arrays = rdd2.mapPartitionsWithIndex(func).collect()
arrays.foreach(println)
SparkUtils.close(sc)
}
}
1 案例1
有数据格式如下:
timestamp province city userid adid
时间点 省份 城市 用户 广告
用户ID范围:0-99
省份,城市,ID相同:0-9
adid:0-19需求:
1.统计每一个省份点击TOP3的广告ID
2.统计每一个省份每一个小时的TOP3广告ID
package com.qf.bigdata.spark.core.day5
import com.qf.bigdata.spark.core.day3.SparkUtils
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.slf4j.LoggerFactory
/**
* 案例1
*/
object Demo2 {
private val logger = LoggerFactory.getLogger(Demo2.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc: SparkContext = SparkUtils.getLocalSparkContext()
//1. 读取文件
val logRDD: RDD[String] = sc.textFile("C:\\ftp\\ZZBIGDATA-2201\\day008-spark core\\resource\\Advert.txt")
//2. 切割日志:并统计省份和广告对应的点击次数之和
val resRDD: RDD[(String, Int)] = logRDD.map(_.split("\\s+"))
.map(arr => (arr(1) + "_" + arr(4), 1)) // 先统计这个省份的广告被点击了多少次,所以我要先以省份和广告作为key来统计次数
.reduceByKey(_ + _) // 对省份和广告为key进行求点击次数之和
//3. 以点击次数降序排序然后取top3
val res: collection.Map[String, List[(String, Int)]] = resRDD.map {
case (pa, cnt) => {
val param: Array[String] = pa.split("_") // 省份和广告的字符串数组
(param(0), (param(1), cnt)) // (province, adid, cnt)
}
}.groupByKey() // [(province, [(adid1, cnt1), (adid2,cnt2), ...])]
.mapValues(values => values.toList.sortWith((previous, next) => previous._2 > next._2) // 按照点击次数降序排序
.take(3)).collectAsMap() // 取前3名
//4. 打印
println(res)
SparkUtils.close(sc)
}
}
2 案例2
- 数据格式
- 19735E1C66.log 这个文件中存储着日志信息
手机号,时间戳,基站ID,连接状态(1连接 0断开)
- lac_info.txt 这个文件中存储基站信息
基站ID, 经, 纬度
- 需求
根据用户产生日志的信息,在那个基站停留时间最长
求所用户经过的所有基站的范围内(经纬度)所停留时间最长的Top2翻译:求每个用户停留时长最长的两个基站的经纬度是多少
2.1 DateUtils
package com.qf.bigdata.spark.core.day5
import java.text.SimpleDateFormat
import java.util.Date
/**
* 日期工具类
*/
object DateUtils {
private val DATE_FORMAT:String = "yyyyMMddHHmmss"
/**
* 将date的字符串转换为Date类型
*/
def dateStr2Date(dateStr: String, DATE_FORMAT: String): Date = {
//1. 获取到日期格式化对象
val format = new SimpleDateFormat(DATE_FORMAT)
//2. 转换
format.parse(dateStr)
}
/**
* 将一个日期格式的字符串,转换为一个Long类型时间戳
*/
def dateStr2Timestamep(dateStr: String): Long = {
//1. 将date的字符串转换为Date类型
val date:Date = dateStr2Date(dateStr, DATE_FORMAT)
//2. 获取到date对应的时间戳
date.getTime
}
}
2.2 Demo3
package com.qf.bigdata.spark.core.day5
import com.qf.bigdata.spark.core.day3.SparkUtils
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.slf4j.LoggerFactory
/**
* 案例2
*/
object Demo3 {
private val logger = LoggerFactory.getLogger(Demo3.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc: SparkContext = SparkUtils.getLocalSparkContext()
//1. 加载数据
val logRDD: RDD[String] = sc.textFile("C:\\ftp\\ZZBIGDATA-2201\\day008-spark core\\resource\\lacduration\\19735E1C66.log")
//2. 处理原始日志数据,将其转换为一个二维的元素((phone,lac), ts_long)
val userInfoRDD: RDD[((String, String), Long)] = logRDD.map(line => {
//2.1 切日志
val fields: Array[String] = line.split(",")
//2.2 获取到关键的字段
val phone: String = fields(0) //手机号码
val ts: Long = DateUtils.dateStr2Timestamep(fields(1)) // 时间戳
val lac: String = fields(2) // 基站id
val eventType: Int = fields(3).toInt // 连接或者断开的状态
//3. 计算停留时间
val ts_long = if (eventType == 1) -ts else ts
//4. 封装数据为元祖
((phone, lac), ts_long)
})
//3. 计算每个用户在每个基站停留的总时长
val lacAndPTRDD: RDD[(String, (String, Long))] = userInfoRDD.reduceByKey(_ + _)
.map {
case ((phone, lac), ts_long) => (lac, (phone, ts_long))
}
//4. 加载基站信息数据
val lacInfoRDD: RDD[String] = sc.textFile("C:\\ftp\\ZZBIGDATA-2201\\day008-spark core\\resource\\lacduration\\lac_info.txt")
val lacAndXYRDD: RDD[(String, (String, String))] = lacInfoRDD.map(line => {
val fields: Array[String] = line.split(",")
val lac: String = fields(0)
val x: String = fields(1)
val y: String = fields(2)
(lac, (x, y))
})
//5. join : [(lac, [(phone, ts_long),(x, y)]),...]
val joinRDD: RDD[(String, ((String, Long), (String, String)))] = lacAndPTRDD join lacAndXYRDD
val phoneAndTXYRDD: RDD[(String, Long, String, String)] = joinRDD.map {
case (lac, ((phone, ts), (x, y))) => (phone, ts, x, y)
}
//6. 转换 : 按照phone分组
val groupRDD: RDD[(String, Iterable[(String, Long, String, String)])] = phoneAndTXYRDD.groupBy(_._1)
//7. 降序排序
val sortRDD: RDD[(String, List[(String, Long, String, String)])] = groupRDD.mapValues(_.toList.sortBy(_._2).reverse)
//8. 处理一下,value中的phone数据和时长数据,只保留xy
val resRDD: RDD[(String, List[(String, String)])] = sortRDD.map(t => {
val phone = t._1
val filterList: List[(String, String)] = t._2.map(tp => {
val x: String = tp._3
val y: String = tp._4
(x, y)
})
(phone, filterList)
})
//9 top2
val resultRDD: RDD[(String, List[(String, String)])] = resRDD.mapValues(_.take(2))
println(resultRDD.collect().toList)
SparkUtils.close(sc)
}
}














 356
356











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









