







OK,接着上篇说,前文有提到,通过负载均衡增加web节点的方式来,提高网站的并发性能,其实在一个大型网站中,在高并发的情况下,最先达到瓶颈的应该是数据库。
这么说吧,如果把整个系统比喻成一个木桶的话,那么数据库就是木桶上最短的那块木板,所以要提高网站的并发性能,首先要提高的就是数据库的能力,也就是说,当系统的并发达到一定的程度的时候,数据库会首先达到瓶颈,数据库出现了瓶颈并不是程序存在逻辑性错误,数据库瓶颈的表现就是数据库因为承受了太多的访问后,数据库无法迅速的做出响应,严重时候数据库会拒绝进一步操作死锁在哪里不能做出任何反应。数据库犹如一把巨型的大锁,很多人争抢这个锁时候会导致这个大锁完全被锁死,最终请求的处理就停留在这个大锁上最终导致网站提示出503错误,503错误最终会传递到所有的客户端上,最终的现象就是全站不可用了,记得早期的12306就是这么挂掉的。
那么,这个时候我们就要来考虑,如何提升数据库的性能了,常用的一个解决方案就是对数据库进行读写分离,我们的DB将不只是一台而是多台,一台作为主库只用于写操作,其他的从库用作读。
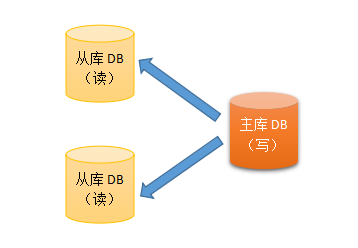
当用户请求过来之后,我们会先判定他是读的操作还是写,如果是写,ok让他走主库,如果是读的话,就分配其他的从数据库给他访问,当然读写分离也是有缺陷的,用户看到的数据往往都会有一定的延迟时间,这个时间是无法避免的,因为变更的数据在主库,而用户读的是从库,从主库同步数据到从库也是需要时间的,因此用于读操作的DB数量不宜过多。
单纯使用读写分离就可以解决12306的问题了吗?答案是否定的,对于12306这种高并发大访问量的网站来讲,只用读写分离是远远不够的,这里又要用到缓存技术了,因为缓存是存放在内存中的因此他的读取速度远超DB读取的无数倍,所以我们可以将一些很长时间不会变更的而且频繁被访问的数据放到缓存中,redis和memcache都能够为我们所使用。
针对淘宝这样的网站来讲,用户想要访问一个商品,他会选择用一个关键字来查询,而这个关键字对于我没呢数据库中海量的商品数据来讲无异于大海捞针,因为是模糊查询也就是会用到like这样的操作,效率更是低的无下限,在结果返回之前用户就要奔溃掉了。
所以为了应对这种需求,就要引入一个搜索技术,像百度、谷歌这样的公司,他们掌握着整个互联网的数据,然而我们都可以通过关键字去进行搜索找到我们需要的内容,当然他们的技术肯定很复杂,但我们的需求显然简单很多。
我们可以将数据库的数据导出到文件里,对文件建立索引,使用倒排索引技术来检索信息,关于这一块,可以参考下solr,这块的技术,数据库中需要频繁查询的表都可以缓存到solr中,因为solr的查询效率比数据库的快的多,详细的我就不多说了,大家看一下就可以明白了。
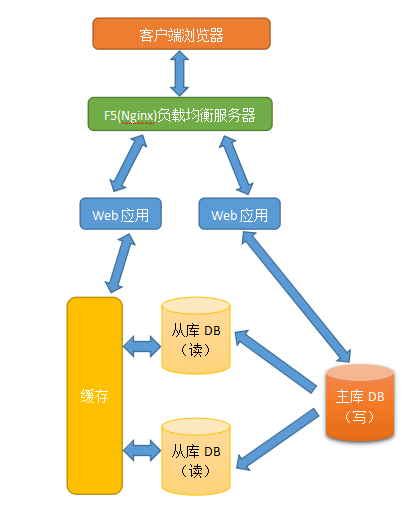
ok,现在我们的系统架构图大概是这样了,真的不是太会画图….大概是这个意思,好的今天就先这么多~~















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









